







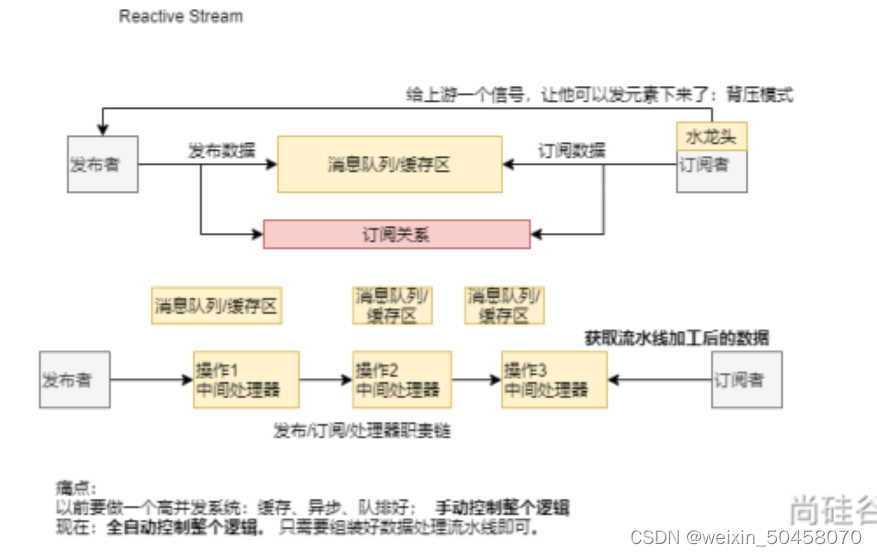
Reactive-Stream
Reactive Streams是JVM面向流的库的标准和规范
1、处理可能无限数量的元素
2、有序
3、在组件之间异步传递元素
4、强制性非阻塞,背压模式
在Java中,常用的背压机制是响应式流编程中的反压(Reactive Streams Backpressure)。反压是一种生产者-消费者模型,其中消费者可以向生产者发出信号,告知其需要的数据量和承受的压力,生产者则据此进行相应的数据生产和传输。这种机制可以防止消费者被超过其处理能力的数据压倒,保持数据流的平衡。

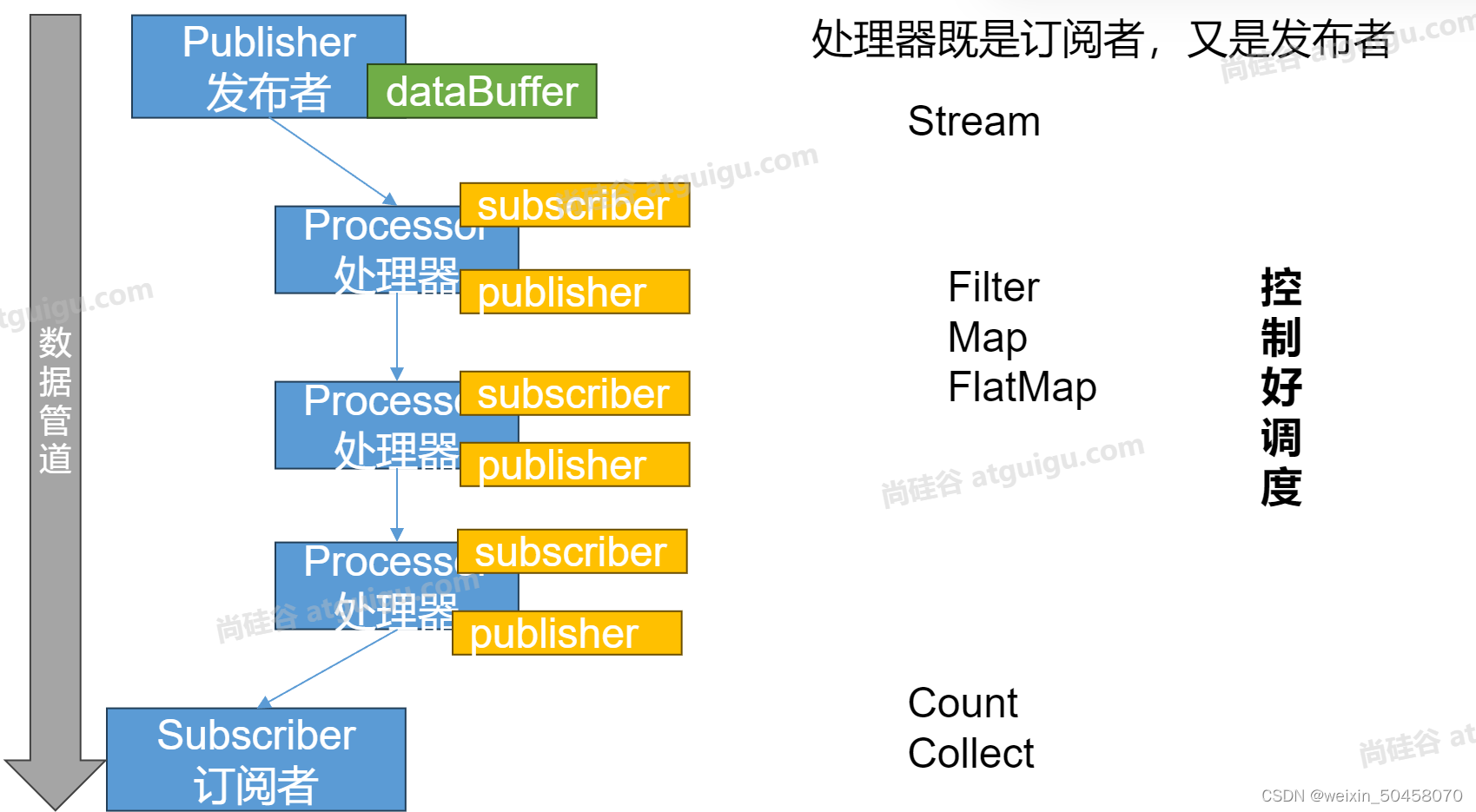
API Components:
- Publisher:发布者;产生数据流
- Subscriber:订阅者; 消费数据流
- Subscription:订阅关系; 订阅关系是发布者和订阅者之间的关键接口。订阅者通过订阅来表示对发布者产生的数据的兴趣。订阅者可以请求一定数量的元素,也可以取消订阅。
- Processor:处理器; 处理器是同时实现了发布者和订阅者接口的组件。它可以接收来自一个发布者的数据,进行处理,并将结果发布给下一个订阅者。处理器在Reactor中充当中间环节,代表一个处理阶段,允许你在数据流中进行转换、过滤和其他操作。

public class FlowDemo {
// 发布订阅模型
public static void main(String[] args) throws InterruptedException {
//1.定义一个发布者,发布数据
SubmissionPublisher<String> publisher = new SubmissionPublisher<>();
for (int i = 0; i < 10; i++) {
publisher.submit("p-" + i);
}
//2.定义一个订阅者,订阅者感兴趣发布者的数据
Flow.Subscriber<String> subscriber = new Flow.Subscriber<String>() {
private Flow.Subscription subscription;
@Override //在订阅时,执行这个回调
public void onSubscribe(Flow.Subscription subscription) {
System.out.println(Thread.currentThread() + "订阅开始了:" + subscription);
this.subscription = subscription;
//从上游请求一个数据,根据数据处理能力自设置
subscription.request(1);
//请求所有数据
// subscription.request(Integer.MAX_VALUE);
}
@Override//在下一个元素到达时
public void onNext(String item) {
if (item.equals("p-6")) {
subscription.cancel();
}
System.out.println(Thread.currentThread() + "订阅者,接收到信息:" + item);
//进行执行下一条,根据数据处理能力自设置
subscription.request(1);
}
@Override
public void onError(Throwable throwable) {
System.out.println(Thread.currentThread() + "订阅者,接收到错误信号:" + subscription);
}
@Override
public void onComplete() {
System.out.println(Thread.currentThread() + "订阅者,接收到完成信号:" + subscription);
}
};
//绑定发布者和订阅者
publisher.subscribe(subscriber);
for (int i = 0; i < 10; i++) {
publisher.submit("p-" + i);
}
//不让主线程停止执行
Thread.sleep(20000);
}
}
订阅数据的线程与发布数据的线程不一致,jvm对于整个发布订阅关系已经做好了异步+缓存区处理=响应式系统
在代码内添加中间操作如下:
public class FlowDemo {
//定义流中间处理操作,只用写订阅者的接口
static class MyProcessor extends SubmissionPublisher<String> implements Flow.Processor<String, String> {
private Flow.Subscription subscription;
@Override
public void onSubscribe(Flow.Subscription subscription) {
System.out.println("processor订阅绑定完成");
this.subscription = subscription;
subscription.request(1);
}
@Override
public void onNext(String item) {
System.out.println("processor拿到数据:" + item);
item += ":haha";
submit(item);
subscription.request(1);
}
@Override
public void onError(Throwable throwable) {
}
@Override
public void onComplete() {
}
}
// 发布订阅模型
public static void main(String[] args) throws InterruptedException {
//1.定义一个发布者,发布数据
SubmissionPublisher<String> publisher = new SubmissionPublisher<>();
for (int i = 0; i < 10; i++) {
publisher.submit("p-" + i);
}
//定义一个中间操作,给每个元素添加哈哈元素
MyProcessor myProcessor = new MyProcessor();
//2.定义一个订阅者,订阅者感兴趣发布者的数据
Flow.Subscriber<String> subscriber = new Flow.Subscriber<String>() {
private Flow.Subscription subscription;
@Override //在订阅时,执行这个回调
public void onSubscribe(Flow.Subscription subscription) {
System.out.println(Thread.currentThread() + "订阅开始了:" + subscription);
this.subscription = subscription;
//从上游请求一个数据,根据数据处理能力自设置
subscription.request(1);
//请求所有数据
// subscription.request(Integer.MAX_VALUE);
}
@Override//在下一个元素到达时
public void onNext(String item) {
if (item.equals("p-6")) {
subscription.cancel();
}
System.out.println(Thread.currentThread() + "订阅者,接收到信息:" + item);
//进行执行下一条,根据数据处理能力自设置
subscription.request(1);
}
@Override
public void onError(Throwable throwable) {
System.out.println(Thread.currentThread() + "订阅者,接收到错误信号:" + subscription);
}
@Override
public void onComplete() {
System.out.println(Thread.currentThread() + "订阅者,接收到完成信号:" + subscription);
}
};
//绑定发布者和订阅者
publisher.subscribe(myProcessor);
myProcessor.subscribe(subscriber);
for (int i = 0; i < 10; i++) {
publisher.submit("p-" + i);
}
//不让主线程停止执行
Thread.sleep(20000);
}
}
响应式编程:
1、底层:基于数据缓冲队列 + 消息驱动模型 + 异步回调机制
2、编码:流式编程 + 链式调用 + 声明式API
3、效果:优雅全异步 + 消息实时处理 + 高吞吐量 + 占用少量资源
Reactor
1、快速上手
介绍
Reactor 是一个用于JVM的完全非阻塞的响应式编程框架,具备高效的需求管理(即对 “背压(backpressure)”的控制)能力。它提供了异步序列 API Flux(用于[N]个元素)和 Mono(用于 [0|1]个元素),并完全遵循和实现了“响应式扩展规范”。
Reactor 的 reactor-ipc 组件还支持非阻塞的进程间通信(inter-process communication, IPC)。 Reactor IPC 为 HTTP(包括 Websockets)、TCP 和 UDP 提供了支持背压的网络引擎,从而适合 应用于微服务架构。并且完整支持响应式编解码。
依赖
<dependencyManagement>
<dependencies>
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-bom</artifactId>
<version>2023.0.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement><dependencies>
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-core</artifactId>
</dependency>
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>2、响应式编程
响应式编程是一种关注于数据流(data streams)和变化传递(propagation of change)的异步编程方式。 这意味着它可以用既有的编程语言表达静态(如数组)或动态(如事件源)的数据流。
onNext x 0..N [onError | onComplete]2.1. 阻塞是对资源的浪费
现代应用需要应对大量的并发用户,而且即使现代硬件的处理能力飞速发展,软件性能仍然是关键因素。
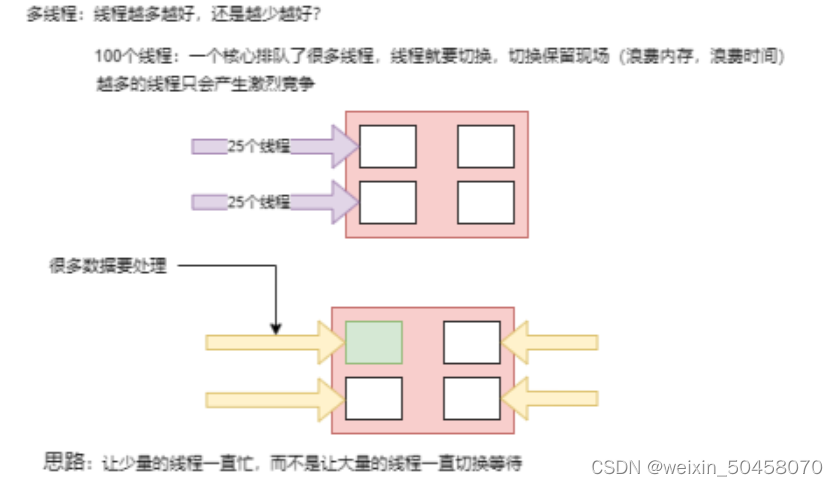
广义来说我们有两种思路来提升程序性能:
- 并行化(parallelize) :使用更多的线程和硬件资源。[异步]
- 基于现有的资源来 提高执行效率 。
Java开发者使用阻塞式(blocking)编写代码,在出现性能瓶颈后, 我们可以增加处理线程,线程中同样是阻塞的代码。但是这种使用资源的方式会迅速面临 资源竞争和并发问题。
更糟糕的是,阻塞会浪费资源。具体来说,比如当一个程序面临延迟(通常是I/O方面, 比如数据库读写请求或网络调用),所在线程需要进入 idle 状态(也就是空闲状态,是指线程正在等待,暂时没有执行任何任务)等待数据,从而浪费资源。(数据请求到接收数据这个过程通常是由操作系统内核来完成的。当应用程序发起I/O请求时,操作系统内核会将请求传递给相应的设备驱动程序,并负责管理数据的传输和处理过程。)
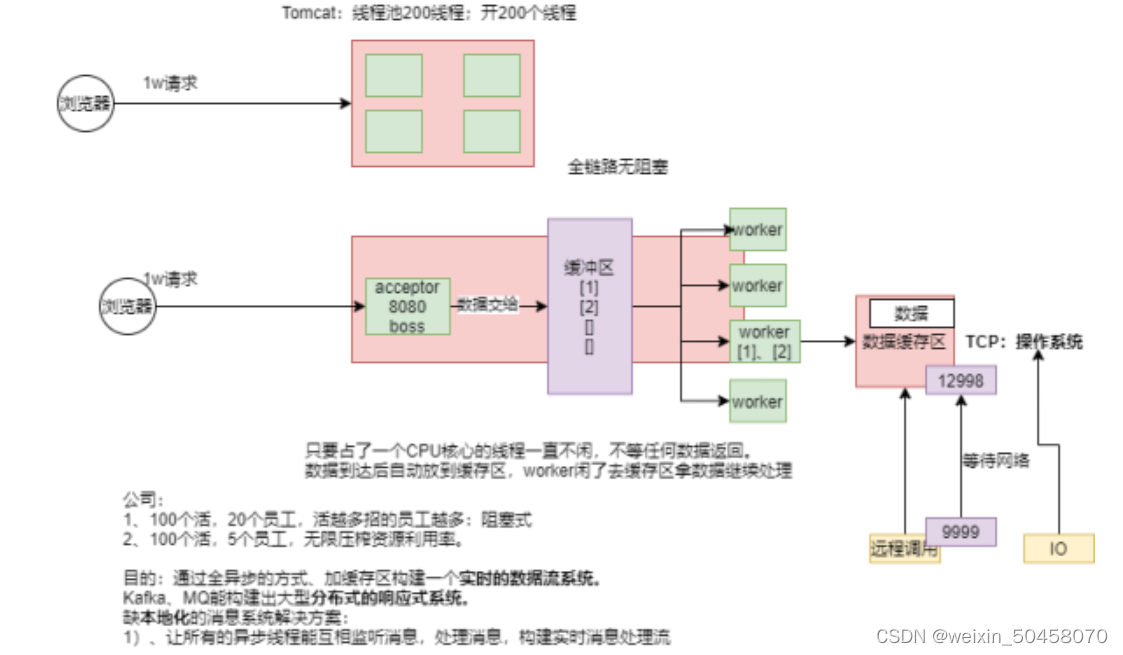
2.2. 异步可以解决问题吗?
通过编写 异步非阻塞 的代码, (任务发起异步调用后)执行过程会切换到另一个 使用同样底层资源 的活跃任务,然后等异步调用返回结果再去处理。
但是在 JVM 上如何编写异步代码呢?Java 提供了两种异步编程方式:
- 回调(Callbacks) :异步方法没有返回值,而是采用一个 callback 作为参数(lambda 或匿名类),当结果出来后回调这个 callback。常见的例子比如 Swings 的 EventListener。
- Futures :异步方法 立即 返回一个 Future<T>,该异步方法要返回结果的是 T 类型,通过 Future封装。这个结果并不是 立刻 可以拿到,而是等实际处理结束才可用。比如, ExecutorService 执行 Callable<T> 任务时会返回 Future 对象。
这些技术够用吗?并非对于每个用例都是如此,两种方式都有局限性。
回调很难组合起来,因为很快就会导致代码难以理解和维护(即所谓的“回调地狱(callback hell)”)。
考虑这样一种情景:
- 在用户界面上显示用户的5个收藏,或者如果没有任何收藏提供5个建议。
- 这需要3个 服务(一个提供收藏的ID列表,第二个服务获取收藏内容,第三个提供建议内容):
回调地狱(Callback Hell)的例子:
userService.getFavorites(userId, new Callback<List<String>>() {
public void onSuccess(List<String> list) {
if (list.isEmpty()) {
suggestionService.getSuggestions(new Callback<List<Favorite>>() {
public void onSuccess(List<Favorite> list) {
UiUtils.submitOnUiThread(() -> {
list.stream()
.limit(5)
.forEach(uiList::show);
});
}
public void onError(Throwable error) {
UiUtils.errorPopup(error);
}
});
} else {
list.stream()
.limit(5)
.forEach(favId -> favoriteService.getDetails(favId,
new Callback<Favorite>() {
public void onSuccess(Favorite details) {
UiUtils.submitOnUiThread(() -> uiList.show(details));
}
public void onError(Throwable error) {
UiUtils.errorPopup(error);
}
}
));
}
}
public void onError(Throwable error) {
UiUtils.errorPopup(error);
}
});
Reactor改造后为:
userService.getFavorites(userId)
.flatMap(favoriteService::getDetails)
.switchIfEmpty(suggestionService.getSuggestions())
.take(5)
.publishOn(UiUtils.uiThreadScheduler())
.subscribe(uiList::show, UiUtils::errorPopup); 如果你想确保“收藏的ID”的数据在800ms内获得(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2842
2842











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









