







前言
许多基础设施和性能监控软件工具都提供内置异常检测。但它们经常产生太多误报。异常检测也可以表述为预测问题。异常是意外事件,因此难以预测。如果您构建的系统可以很好地预测下一次测量的值,则可以将该预测与实际测量进行比较。如果您的预测与测量之间存在较大差异,则可能发生异常。经过本人多次尝试发现了一些好的检测异常数据的方法和理论在这里分享给大家
统计阈值估计
时间序列值的预测有很多种机器学习方法。其中一些方法还自带了估计置信边界的工具,比如 ARIMA 或高斯过程。输出通常是高斯分布,它会告诉你实际测量值落在某些边界之间的可能性有多大。
一种常用的方法是 3 Sigma 规则规则。如果你的测量值与平均值相差超过 3 倍的标准差,那就认为这个测量值是异常的。但是就像下图展示的,你的预测仍然有 0.1% 的概率是错的;而且测量值实际上是期望值。使用这种方法,你实际上可以建立异常值检测,但是统计上的异常值未必是异常的。
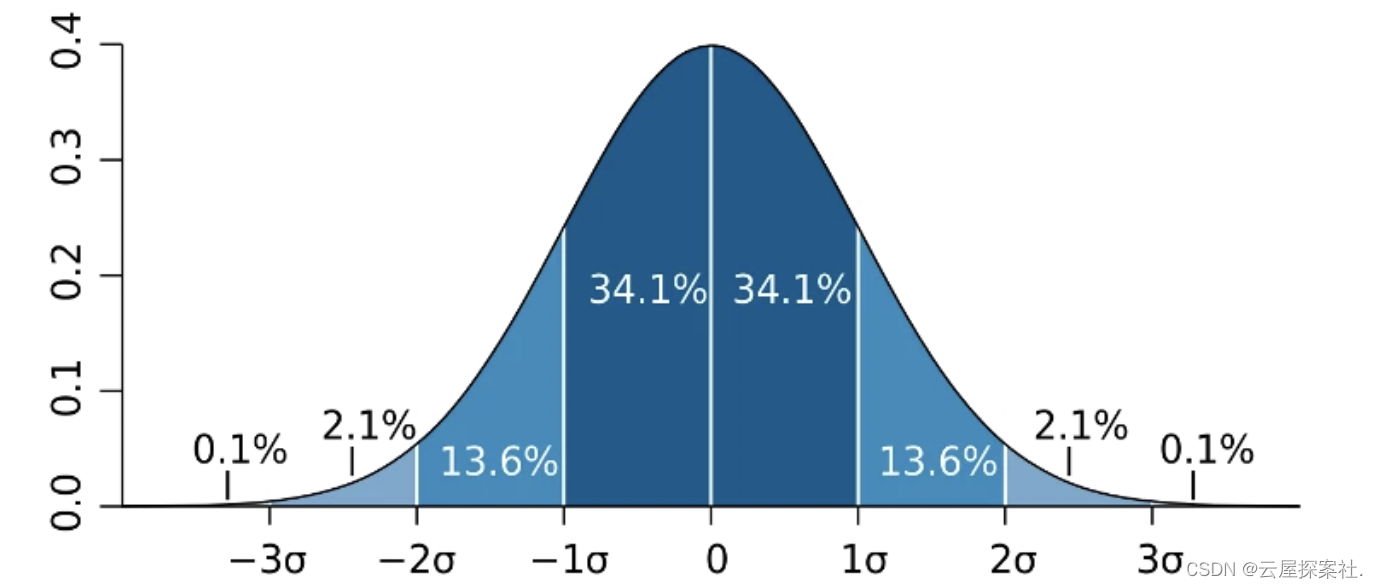
假设你有 100 个企业客户,活跃在 100 个国家。如果你想每分钟实时监测每个国家的呼叫,那你每分钟将有 10000 个数据点让异常检测算法监测。如果应用 3 个西格玛规则,你的模型仍然有 0.1% 的概率出错。对于这个例子来说,这意味着平均每分钟会有 10 个误报,或者每天有 36000 个误报,这是不希望出现的结果。
当然,你可以把置信区间改成 4 个标准差,这样每天的误报率就只有 1000 多个。但是改变可以接受的标准差就等同于设定了假阳性率。它并没有捕捉测量值(在这个例子中是响应时间)是否异常。
尽管在大多数情况下高斯分布非常适合这个预期输出,但是你可以选择不同的概率分布。但是即使你的新概率分布更适合数据,你基本上仍然在用相同的方法来解决问题并设定异常检测模型的误报率。
异常分数
鲁棒随机切割森林(RRCF)是一种用于检测异常情况的方法,它主要基于树的构建。它的工作原理是对数据进行建模,当新的数据点输入模型时,它会检查树的结构,并确定是否需要调整以更好地拟合数据。如果模型对数据的预测准确,则无需进行任何更改,但如果预测出现明显偏差,则需要对树进行调整以更好地适应数据。
RRCF 返回一个称为异常分数的指标,用于衡量模型为拟合数据所必须进行的更改程度。如果模型中的树的大小为256(默认值),则异常分数可以在0到256之间的任何位置。较小的变化会导致较低的分数,而较大的变化则可能使分数达到最大值256。如果您希望将分数范围控制在0到100%之间,您可以简单地将输出除以树的大小。
一般来说,您可以设定一个阈值,例如树的变化为50%。在实验中&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









