






参考资料:12.循环神经网络(基础篇)_哔哩哔哩_bilibili
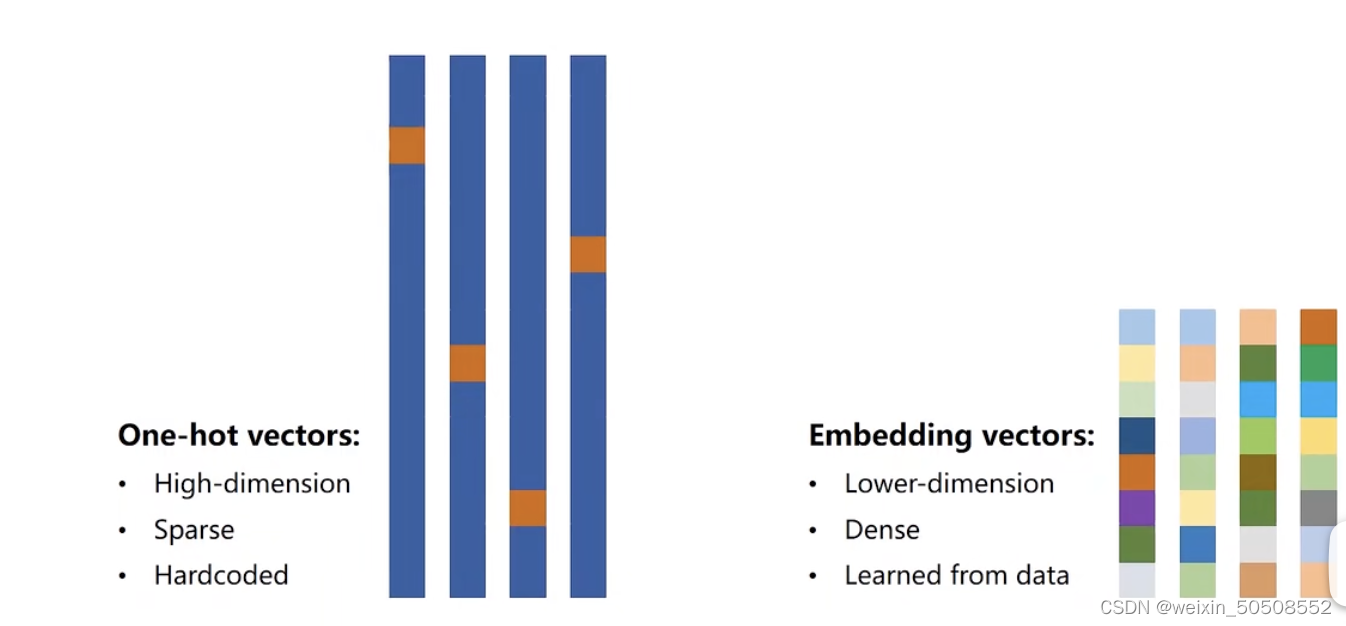
1. 什么是one-hot编码?
One-hot编码是一种将分类变量转换为二进制向量的方法,其中只有一个元素是1,其他都是0。
2. one-hot编码的缺点:
- 维度太高。比如字母级就26个,词级的就更高了。有可能映射完毕后是几万维的,这是灾难性的。
- 向量过于稀疏。
- 硬编码。
所以希望能找到一个 低维、稠密、能从数据中学习的编码方式。embedding应运而生。
3. 什么是embedding?
Embedding是一种将分类变量映射到低维空间的方法,常用于自然语言处理中的词嵌入。
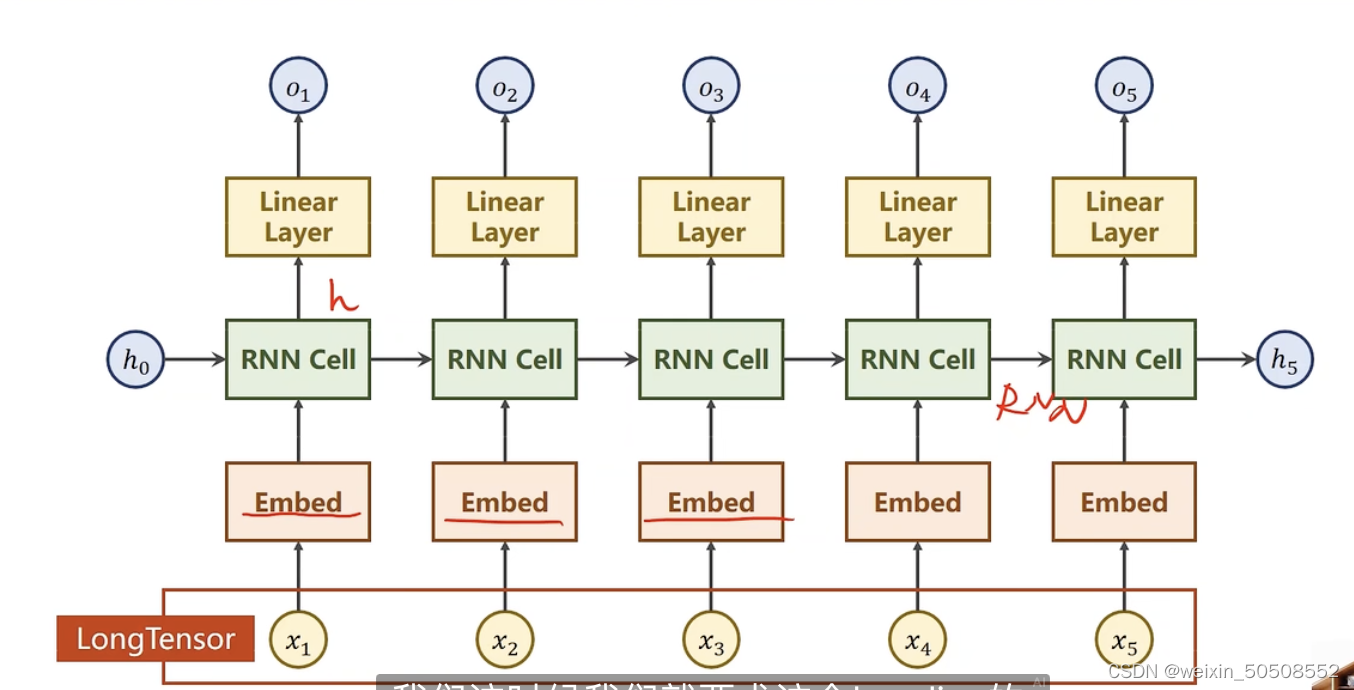
针对上一篇文章中的Seq2Seq示例,将one-hot编码修改为embedding的形式:
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
import matplotlib.pyplot as plt
#加了embedding版本的
batch_size = 1 #我们现在是1个字符1个字符训练的
input_size = 4 #输入维度 这边ehlo四个字母就是4
hidden_size = 8 #假设从hidden 层输出的维度是8,而我们需要的最终分类数为4,那么需要再经过一个全连接层
seq_len = 5 #字符串长度是5,就相当于是输入的序列是5
num_layers = 2 #设置的rnn层数
embedding_size = 10 #嵌入层的维度
num_class = 4 #最终的分类数
#我们希望一个序列hello-》ohlol
idx2char = ['e','h','l','o']
x_data = [[1,0,2,2,3]] #(batch_size,seq_len)
y_data = [3,1,2,3,2] #(batch_size* seq_len)
inputs = torch.LongTensor(x_data) #shape:[1,5]
labels = torch.LongTensor(y_data) #shape:[5]
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__()
#embedding层
self.emb = torch.nn.Embedding(input_size,embedding_size)
self.rnn = torch.nn.RNN(input_size=embedding_size,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True)
self.fc = torch.nn.Linear(hidden_size,num_class)
def forward(self,x):
#第一个hidden初始化放到forward里了
hidden = torch.zeros(num_layers,
batch_size,
hidden_size)
x = self.emb(x)
x,_ = self.rnn(x,hidden)
x = self.fc(x)
return x.view(-1,num_class)
net = Model()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(),lr=0.05)
for epoch in range(15):
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs,labels)
loss.backward()
optimizer.step()
_, idx = outputs.max(dim = 1)
idx = idx.data.numpy()
print("predicted string: ", "".join([idx2char[x] for x in idx]),end='')
print(',epoch [%d/15] loss = %.4f' %(epoch+1,loss.item()))运行结果:
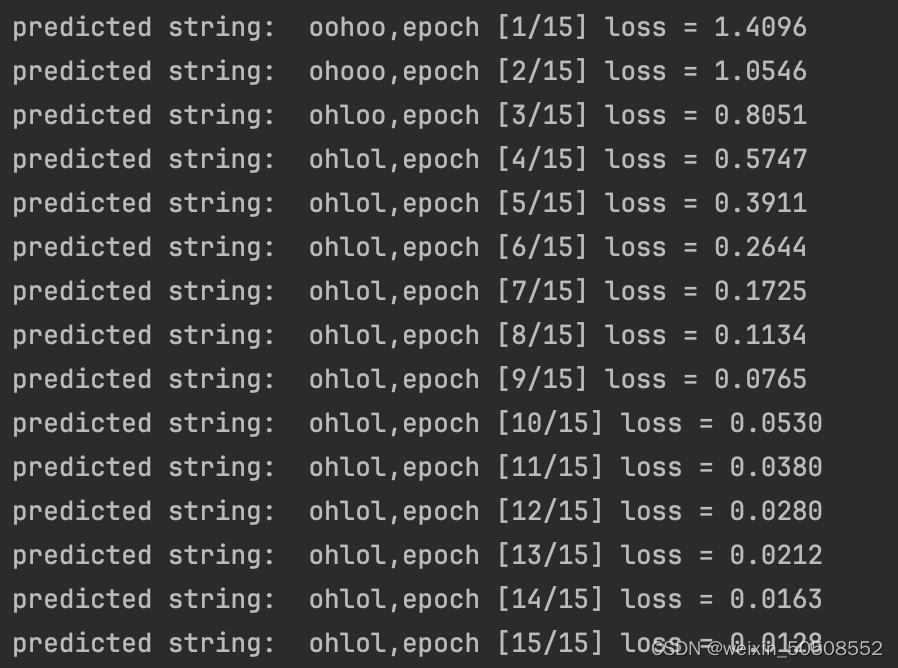
运用了embedding,可以看到得到预期结果的训练轮数减少了,说明效果更好了。
另:
torch.nn.Embedding用法详解:【python函数】torch.nn.Embedding函数用法图解-CSDN博客
torch.nn.Embedding(num_embeddings, embedding_dim, padding_idx=None, max_norm=None, norm_type=2.0, scale_grad_by_freq=False, sparse=False, _weight=None, _freeze=False, device=None, dtype=None)
其实最常用的就是前两个参数:
- num_embeddings: 词的数量
- embedding_dim: 定义的嵌入的维度
从one-hot变成embedding的一个好处就是,编码的长度和总的词数没有关系了。所以针对比较长的序列,会大大节省编码空间。
- one-hot: 编码需要的张量大小 [length,word_total_count]
- embedding:编码需要的张量大小 [length,embedding_size]
import torch
import torch.nn as nn
embedding = nn.Embedding(3, 4)
x = torch.LongTensor([[1, 2, 1], [0, 1, 1]])
y = embedding(x)
print('权重:\n', embedding.weight)
print('输出:')
print(y.shape)
- 输入的x的shape为[2,3]
- 输出的y的shape为[2,3,4]
embedding相当于一个词典,用来查找映射关系
相当于是把输入的每一项扩展了一个维度,映射到了embedding size大小的维度上。这里的embedding size是4。
一个注意的点是:这里的输入x里的每一项不能超过embedding里面的最大容量,即词索引是不能超出词典的最大容量,本例子中是nn.Embedding()的第一个参数3,超过了就相当于在词典中找不到对应的映射关系里。
同样的大小,如果我们还是用one-hot编码的话:
import torch
import torch.nn as nn
batch_size = 1 #我们现在是1个字符1个字符训练的
input_size = 10 #针对每个字符,用one-hot编码之后,每个字符的长度是4
hidden_size = 10 #针对每个字符,用one-hot编码之后,每个字符的长度是4
seq_len = 12 #字符串长度是5,就相当于是输入的序列是5
num_layers = 1
#-------------one-hot-------------------
x_data = [1,0,2,2,3,9,8,2,3,5,6,4]
#one-hot编码对照查表
one_hot_lookup = [
[1,0,0,0,0,0,0,0,0,0],
[0,1,0,0,0,0,0,0,0,0],
[0,0,1,0,0,0,0,0,0,0],
[0,0,0,1,0,0,0,0,0,0],
[0,0,0,0,1,0,0,0,0,0],
[0,0,0,0,0,1,0,0,0,0],
[0,0,0,0,0,0,1,0,0,0],
[0,0,0,0,0,0,0,1,0,0],
[0,0,0,0,0,0,0,0,1,0],
[0,0,0,0,0,0,0,0,0,1]
]
#将输入数据转换为onehot编码
x_one_hot = [one_hot_lookup[x] for x in x_data]
inputs = torch.Tensor(x_one_hot).view(batch_size,seq_len,input_size)
print(inputs.shape)
#torch.Size([1, 12, 10])
#-------------embedding-------------------
embedding = nn.Embedding(10, 3)
x = torch.LongTensor([[1,0,2,2,3,9,8,2,3,5,6,4]])
y = embedding(x)
print(y.shape)
#torch.Size([1, 12, 3])
可以看到one-hot输出的shape为:torch.Size([1, 12, 10])
embedding的为 torch.Size([1, 12, 3])
而这个10是由输入的总词数决定的,所以当总词数很多时,张量会很大很大,而embedding的3是我们人为自定义的,当总词数比较多的时候会比较有优势。















 2478
2478

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









