






CSV
所谓的 CSV(逗号分隔值)格式是电子表格和数据库最常见的导入和导出格式。
导入
import csv
常用函数
csv.writer(f) # 写入到文件f中
writerow(data) # 每次写入一行data
writerow(data) # 每次写入多行data
csv.reader(f) # 读取文件f
# 如果newline=''未指定,则嵌入在引用字段中的换行符将不会被正确解释.例如下面代码执行后并不会多加一行:
with open('eggs.csv', 'w', newline='') as csvfile:
举例代码
下面的代码是我自己做的,繁多冗余,作为runoob,还请读者见谅!!!
举例一
import random
import csv
# 写入表头,初始文件包括四列:学号、语文、数学、英语
f = open('../data/学生成绩.csv', 'w', encoding='utf-8', newline='')
mywrite = csv.writer(f)
data = ['学号', '语文', '数学', '英语']
mywrite.writerow(data)
# 随机生成一个有100人班级的语数外三科成绩的文件(csv文件)
for j in range(1, 101):
j_1 = 'python' + '{:0>3}'.format(j)
for i in range(100):
a = random.randrange(100)
b = random.randrange(100)
c = random.randrange(100)
d = [j_1, a, b, c]
mywrite.writerow(d)
f.close()
| 学号 | 语文 | 数学 | 英语 |
|---|---|---|---|
| python001 | 60 | 96 | 36 |
| python002 | 0 | 8 | 79 |
| …… | …… | …… | …… |
| python099 | 64 | 85 | 60 |
| python100 | 47 | 47 | 29 |
# 读取表格的所有数据
f_1 = open('../data/学生成绩.csv', 'r', encoding='utf-8')
read_data = csv.reader(f_1)
data_1 = list(read_data)
f_1.close()
# 提取各科成绩名单
chinese = [int(i1[1]) for i1 in data_1[1:]]
math = [int(i1[2]) for i1 in data_1[1:]]
english = [int(i1[3]) for i1 in data_1[1:]]
max_chinese, min_c = max(chinese), min(chinese)
max_math, min_m = max(math), min(math)
max_english, min_e = max(english), min(english)
# 打印各科的最高分和最低分
f = open('../data/学生成绩.csv', 'a', encoding='utf-8', newline='')
mywrite = csv.writer(f)
for j in range(100):
if max_chinese == int(data_1[1:][j][1]):
print('语文最好的是{}同学,成绩为{}'.format(data_1[1:][j][0], max_chinese))
# mywrite.writerow('语文最好的是{}同学,成绩为{}'.format(data_1[1:][j][0], max_chinese))
for j in range(100):
if min_c == int(data_1[1:][j][1]):
print('\t最低的是{},成绩为{}'.format(data_1[1:][j][0], min_c))
# mywrite.writerow('\t最低的是{},成绩为{}'.format(data_1[1:][j][0], min_c))
print('\r')
for k in range(100):
if max_math == int(data_1[1:][k][2]):
print('数学最好的是{}同学,成绩为{}'.format(data_1[1:][k][0], max_math))
# mywrite.writerow('数学最好的是{}同学,成绩为{}'.format(data_1[1:][k][0], max_math))
for k in range(100):
if min_m == int(data_1[1:][k][2]):
print('\t最低的是{},成绩为{}'.format(data_1[1:][k][0], min_m))
# mywrite.writerow('\t最低的是{},成绩为{}'.format(data_1[1:][k][0], min_m))
print('\r')
for p in range(100):
if max_english == int(data_1[1:][p][3]):
print('英语最好的是{}同学,成绩为{}'.format(data_1[1:][p][0], max_english))
# mywrite.writerow('英语最好的是{}同学,成绩为{}'.format(data_1[1:][p][0], max_english))
for p in range(100):
if min_e == int(data_1[1:][p][3]):
print('\t最低的是{},成绩为{}'.format(data_1[1:][p][0], min_e))
# mywrite.writerow('\t最低的是{},成绩为{}'.format(data_1[1:][p][0], min_e))
f.close()
运行结果如下:
D:\python3.9\python.exe D:/pycharm/myDjango/proj7/code/homework.py
语文最好的是python024同学,成绩为99
语文最好的是python088同学,成绩为99
最低的是python002,成绩为0
数学最好的是python041同学,成绩为99
最低的是python078,成绩为4
英语最好的是python068同学,成绩为98
最低的是python006,成绩为2
最低的是python076,成绩为2
最低的是python090,成绩为2
# 新增一列:总分
f_1 = open('../data/学生成绩.csv', 'r', encoding='utf-8')
read_data = csv.reader(f_1)
data = list(read_data)
f_1.close()
f2 = open('../data/学生成绩.csv', 'w', encoding='utf-8', newline='')
mya = csv.writer(f2)
data1 = [i for i in data[0]]
data1.append('总分')
mya.writerow(data1)
tot = []
for info in data[1:]:
tot.append(info[1:4])
total = []
for i in range(100):
num = int(tot[i][1]) + int(tot[i][2]) + int(tot[i][0])
total.append(num)
tot = []
for info in data[1:]:
tot.append(info)
tot1 = []
for i in range(100):
tot[i].append(total[i])
tot1.append(tot[i])
for i in tot1:
mya.writerow(i)
f2.close()
运行结果:
| 学号 | 语文 | 数学 | 英语 | 总分 |
|---|---|---|---|---|
| python001 | 60 | 96 | 36 | 192 |
| python002 | 0 | 8 | 79 | 87 |
| …… | …… | …… | …… | …… |
| python099 | 64 | 85 | 60 | 209 |
| python100 | 47 | 47 | 29 | 123 |
# 打印总分的最高和最低
f_2 = open('../data/学生成绩.csv', 'r', encoding='utf-8')
read_data = csv.reader(f_2)
data_1 = list(read_data)
f_2.close()
f3 = open('../data/学生成绩.csv', 'a', encoding='utf-8', newline='')
mywer = csv.writer(f3)
score = [int(i1[-1]) for i1 in data_1[1:]]
max_s, min_s = max(score), min(score)
for j in range(100):
if max_s == int(data_1[1:][j][-1]):
print('\n总分最高的是{}同学,总分{}\n'.format(data_1[1:][j][0], max_s))
for j in range(100):
if min_s == int(data_1[1:][j][-1]):
print('总分最低的是{}同学,总分{}'.format(data_1[1:][j][0], min_s))
f3.close()
运行结果
D:\python3.9\python.exe D:/pycharm/myDjango/proj7/code/homework.py
总分最高的是python003同学,总分259
总分最低的是python043同学,总分46
举例二
计算拉钩数据中,各个城市数据分析岗位的平均薪资,例如: 北京: 20 k
lagou.csv总共有52列, 3142行数据。
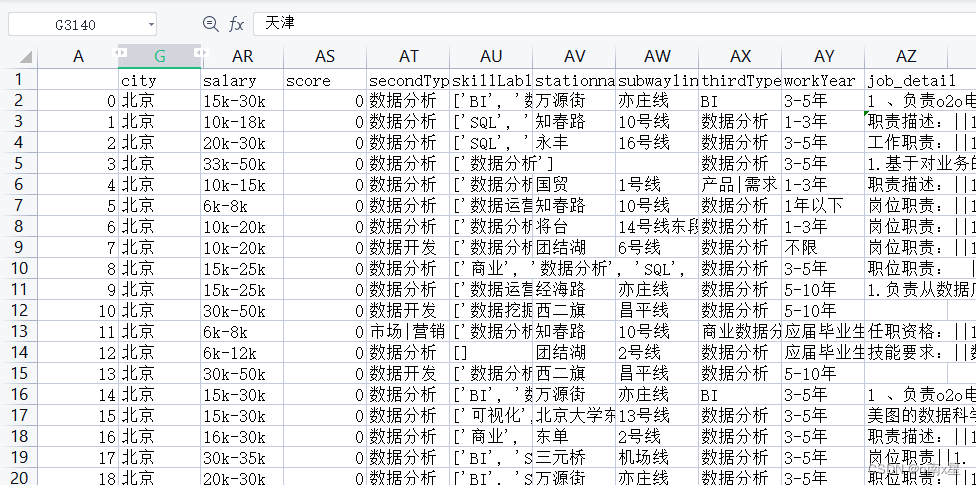
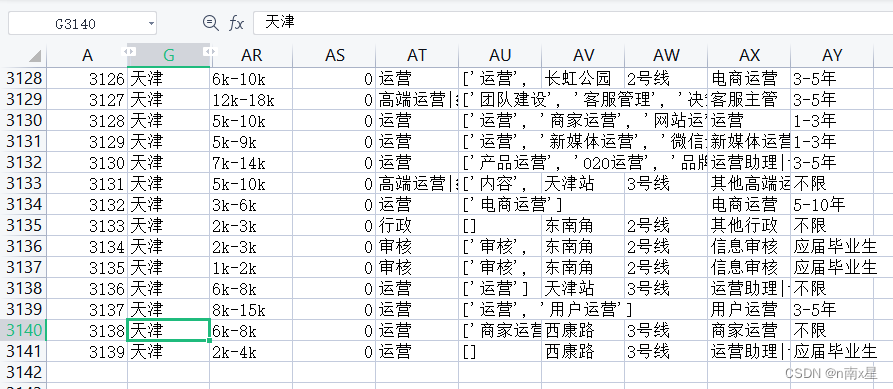
方法一
import csv
with open('./static/lagou.csv', 'r', encoding='utf-8') as f:
lis = list(csv.reader(f))
lis_1 = [i[6] for i in lis[1:]]
lis_2 = list(set(lis_1))
for j in lis_2:
sum_1, sum_2, count = 0, 0, 0
for k in lis[1:]:
if k[6] == j:
result = findall(r'(\d+)k-(\d+)k', k[-9])
if not result:
continue
sum_1 += int(result[0][0])
sum_2 += int(result[0][1])
count += 1
print(j, ':', '%.2f' % ((sum_1 + sum_2) / count / 2), 'k')
运行结果为:
D:\pycharm\myDjango\proj8\venv\Scripts\python.exe E:/1_Q-F/用户学生/CSV和Excel文件操作.py
成都 : 12.57 k
苏州 : 13.83 k
上海 : 20.26 k
西安 : 9.34 k
深圳 : 19.47 k
南京 : 13.41 k
北京 : 21.02 k
天津 : 10.40 k
武汉 : 12.40 k
广州 : 14.80 k
杭州 : 19.95 k
厦门 : 12.14 k
长沙 : 9.39 k
进程已结束,退出代码0
方法二
from re import findall
import csv
with open('static/lagou.csv', encoding='utf-8') as f:
reader = csv.DictReader(f)
# 处理数据
cities = {}
for job in reader:
c = job['city']
m = job['salary']
result = findall(r'(\d+)k-(\d+)k', m)
if not result:
continue
start, end = result[0]
moneys = cities.get(c, [])
moneys.append((int(start) + int(end)) / 2)
cities[c] = moneys
for key in cities:
print(key, ':', round(sum(cities[key]) / len(cities[key]), 2), 'k')
运行结果为:
D:\pycharm\myDjango\proj8\venv\Scripts\python.exe E:/1_Q-F/用户学生/CSV和Excel文件操作.py
北京 : 21.02 k
上海 : 20.26 k
深圳 : 19.47 k
广州 : 14.8 k
杭州 : 19.95 k
成都 : 12.57 k
南京 : 13.41 k
武汉 : 12.4 k
西安 : 9.34 k
厦门 : 12.14 k
长沙 : 9.39 k
苏州 : 13.83 k
天津 : 10.4 k
进程已结束,退出代码0
Excel
虽然 Excel 在日常生活中没有太过过硬的操作,但在实际的工作中难免会遇到成千上万条数据,这时用 python 来操作数据,就可以有事半功倍的效果。
python 中常用的Excel操作相关的库有:
- openpyxl
- xlrd
- xlwt
- xlwings
- xlsxwriter
几个的区别为:
| xls | xlsx | 读 | 写 | 修改 | 设置单元格样式 | |
|---|---|---|---|---|---|---|
| xlrd | √ | √ | √ | × | × | × |
| xlwt | √ | × | × | √ | × | √ |
| openpyxl | × | √ | √ | √ | √ | √ |
| xlwings | √ | √ | √ | √ | √ | √ |
| xlsxwriter | √ | √ | × | √ | × | √ |
本文一 openpyxl 为例简要说明用法。
导入
import openpyxl
常用函数
file = openpyxl.Workbook() - 新建
openpyxl.load_workbook(文件路径) - 读取已有文件
file.create_sheet('Sheet1', 1) - 创建工作表
file.sheetnames - 所有工作表的名字
file.active - 获取活跃表(选中的表)
file.remove(file['Sheet1']) - 移除工作表
cell(行号, 列号) - 定位单元格
cell(1, 1).value - 获取单元格内容
file.save('./student.xlsx') - 保存
sheet2.max_row - 最大行号
sheet2.max_column - 最大列号
举例代码
举例一
获取三国人物数据.xlsx中,‘三国武将数据’表的1~3列所有数据
import openpyxl
workbook = openpyxl.load_workbook('files/三国人物数据.xlsx')
sheet2 = workbook['三国武将数据']
# 获取第1列到第3列所有的数据
for col in range(1, 4):
column = []
for row in range(1, sheet2.max_row+1):
cell = sheet2.cell(row, col)
column.append(cell.value)
print(column)
运行结果为:
D:\pycharm\myDjango\proj8\venv\Scripts\python.exe E:/1_Q-F/用户学生/CSV和Excel文件操作.py
['姓名', '阿会喃', '鲍隆', '鲍信', '卑衍', '卞喜', '蔡和', '蔡瑁', '蔡中', '曹昂', '曹豹', '曹操', '曹纯', '曹洪', '曹仁', '曹性', '曹休', '曹彰', '曹真', '车冑', '陈到', '陈兰', '陈式', '陈泰', '陈武', '成宜', '程普', '程银', '程远志', '淳于琼', '带来洞主', '戴陵', '鄧艾', '鄧贤', '典满', '典韦', '丁奉', '丁原', '董旻', '董荼那', '董袭', '董卓', '朵思大王', '鄂焕', '樊稠', '方悦', '费耀', '冯习', '傅佥', '傅彤', '甘宁', '高定', '高幹', '高览', '高沛', '高顺', '高翔', '公孙度', '公孙範', '公孙康', '公孙続', '公孙淵', '公孙越', '公孙瓒', '龚都', '関平', '関索', '関统', '関兴', '関羽', '管亥', '毌丘俭', '毌丘秀', '郭淮', '郭汜', '郭援', '韩当', '韩德', '韩浩', '韩莒子', '韩遂', '韩暹', '韩忠', '郝萌', '郝昭', '何进', '何仪', '贺齐', '侯选', '胡车児', '胡轸', '胡遵', '华雄', '皇甫嵩', '黄蓋', '黄権', '黄忠', '黄祖', '霍峻', '纪霊', '贾华', '贾逵', '姜维', '蒋钦', '蒋义渠', '焦触', '金环三结', '金旋', '雷薄', '雷铜', '冷苞', '李典', '李恢', '李傕', '李粛', '李通', '李厳', '李异', '梁兴', '廖化', '凌操', '凌统', '刘备', '刘丞', '刘岱', '刘封', '刘磐', '刘辟', '刘繇', '陆抗', '伦直', '骆统', '吕布', '吕旷', '吕蒙', '吕虔', '吕威璜', '吕翔', '马超', '马岱', '马腾', '马铁', '马玩', '马休', '马忠', '满宠', '忙牙长', '孟达', '孟获', '孟优', '糜芳', '木鹿大王', '牛辅', '牛金', '潘璋', '庞德', '牵招', '秦朗', '麴义', '全琮', '沙摩柯', '沈莹', '司马师', '司马望', '宋谦', '宋宪', '眭元进', '孙策', '孙桓', '孙坚', '孙皎', '孙峻', '孙礼', '孙権', '孙韶', '孙歆', '孙异', '孙翊', '孙瑜', '孙仲', '太史慈', '谭雄', '王昶', '王惇', '王基', '王经', '王伉', '王匡', '王淩', '王门', '王平', '王双', '王威', '王忠', '魏続', '魏延', '文醜', '文聘', '文鸯', '吴班', '吴景', '吴巨', '吴兰', '吴懿', '兀突骨', '夏侯覇', '夏侯德', '夏侯惇', '夏侯恩', '夏侯尚', '夏侯威', '夏侯淵', '向宠', '谢旌', '邢道栄', '徐晃', '徐栄', '徐盛', '徐质', '许褚', '许仪', '阎行', '阎柔', '颜良', '厳白虎', '厳纲', '厳颜', '厳舆', '杨醜', '杨锋', '杨奉', '杨怀', '杨祚', '于禁', '于诠', '袁尚', '袁绍', '袁谭', '袁煕', '楽綝', '楽进', '楽就', '臧覇', '张苞', '张宝', '张承', '张飞', '张横', '张虎', '张梁', '张辽', '张南', '张任', '张卫', '张郃', '张燕', '张杨', '张嶷', '张翼', '张英', '张允', '赵弘', '赵统', '赵雲', '周昂', '周仓', '周泰', '朱褒', '朱桓', '朱儁', '朱霊', '朱然', '朱异', '朱治', '诸葛诞', '邹靖', '祖茂']
['性别', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男', '男']
['统御', 65, 59, 78, 60, 57, 47, 77, 47, 73, 55, 90, 75, 81, 87, 56, 73, 82, 85, 50, 76, 67, 70, 83, 73, 74, 83, 69, 69, 72, 52, 70, 94, 61, 60, 57, 81, 70, 51, 68, 71, 74, 62, 60, 67, 69, 70, 71, 73, 66, 84, 56, 74, 76, 66, 84, 68, 68, 73, 72, 64, 65, 74, 84, 60, 77, 73, 62, 76, 95, 70, 78, 59, 85, 65, 66, 76, 62, 69, 51, 89, 69, 65, 62, 88, 42, 58, 82, 64, 40, 65, 70, 82, 86, 82, 75, 85, 74, 80, 79, 50, 78, 89, 78, 71, 66, 65, 53, 62, 69, 71, 78, 79, 69, 49, 73, 82, 59, 61, 73, 75, 83, 75, 54, 55, 75, 70, 70, 62, 90, 49, 57, 86, 58, 90, 58, 59, 64, 86, 81, 82, 70, 71, 69, 67, 83, 47, 75, 76, 51, 56, 66, 42, 71, 76, 80, 71, 59, 82, 71, 60, 70, 63, 58, 66, 68, 54, 92, 71, 93, 70, 64, 78, 77, 80, 66, 69, 67, 72, 62, 82, 59, 64, 60, 77, 67, 66, 65, 73, 65, 82, 64, 60, 52, 67, 81, 79, 85, 77, 74, 69, 51, 61, 82, 72, 79, 69, 89, 63, 79, 70, 85, 77, 64, 61, 87, 80, 85, 68, 65, 52, 72, 71, 80, 67, 68, 79, 61, 52, 56, 67, 62, 55, 84, 64, 64, 81, 60, 66, 73, 80, 54, 74, 75, 83, 77, 84, 60, 76, 79, 93, 58, 87, 74, 89, 82, 72, 80, 76, 76, 72, 67, 68, 90, 74, 61, 77, 68, 84, 79, 71, 80, 70, 68, 81, 70, 70]
进程已结束,退出代码0
举例二
根据csv的数据,统计各城市的岗位有多少.将结果保存在excel中。
import openpyxl
import csv
workbook = openpyxl.Workbook('./static/岗位统计表.xlsx')
sheet1 = workbook.create_sheet('岗位数据分析')
workbook.save('./static/岗位统计表.xlsx')
workbook = openpyxl.open('static/岗位统计表.xlsx')
sheet1 = workbook['岗位数据分析']
sheet1.cell(1, 1).value = '城市'
sheet1.cell(1, 2).value = '岗位数量'
workbook.save('./static/岗位统计表.xlsx')
with open('./static/lagou.csv', 'r', encoding='utf-8') as f:
lis = list(csv.reader(f))
lis_1 = [i[6] for i in lis[1:]]
count = 0
lis_2 = []
for x in lis_1:
if x not in lis_2:
lis_2.append(x)
for i in range(len(lis_2)):
count = 0
for j in lis_1:
if lis_2[i] == j:
count += 1
sheet1.cell(i + 2, 1).value = lis_2[i]
sheet1.cell(i + 2, 2).value = count
workbook.save('./static/岗位统计表.xlsx')
运行结果为:
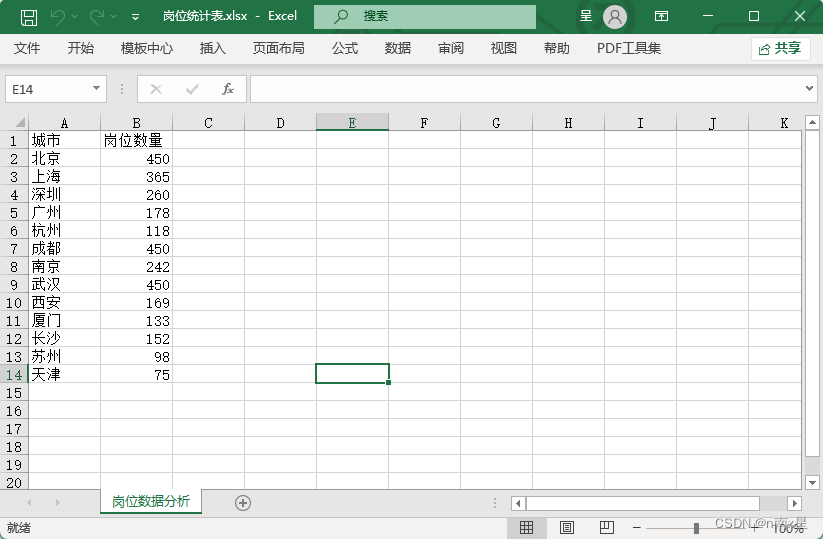
举例三
根据成都租房信息, 用正则表达式取出第一页中房屋的名字和价格,并保存在excel文件中。
import requests
from re import *
import openpyxl
response = requests.get('https://cd.zu.ke.com/zufang')
if response.status_code == 200:
pass
result = findall(r'title="[\u4e00-\u9fa5]租·\w+', response.text)
result1 = findall(r'[\u4e00-\u9fa5]租·\w+', str(result))
new_result = list(result1)
print(new_result, len(new_result))
fir_price = findall(r'\d+</em>\s元/月', response.text)
print(fir_price, len(fir_price))
price = findall(r'\d+', str(fir_price))
print(price, len(price))
try:
workbook = openpyxl.open('static/house_price.xlsx')
except FileNotFoundError:
workbook = openpyxl.Workbook()
workbook.save('static/house_price.xlsx')
if 'house_price' in workbook.sheetnames:
sheet = workbook['house_price']
else:
sheet = workbook.create_sheet('house_price')
workbook.save('static/house_price.xlsx')
sheet.cell(1, 1).value = '房子'
sheet.cell(1, 2).value = '价格'
for row in range(2, len(new_result) + 2):
sheet.cell(row, 1).value = new_result[row - 2]
sheet.cell(row, 2).value = price[row - 2] + '元/月'
workbook.save('static/house_price.xlsx')
运行结果为:
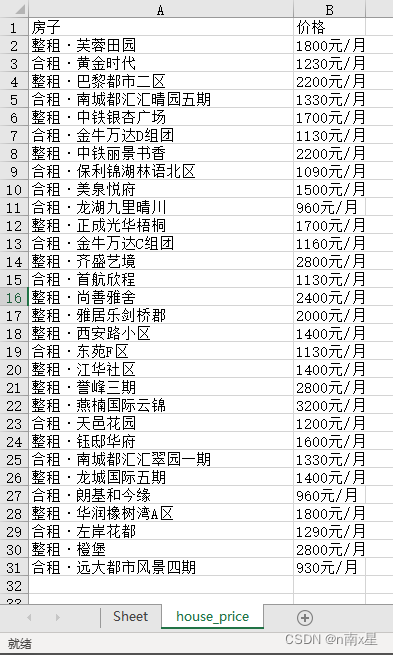















 3595
3595











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









