







最近工作中呢,频频用到消息中心,包括异步转同步的功能,分布式收集日志信息等功能,在面试中也常会问到候选人关于消息中心的知识点,但大多数程序员,尤其是工作两三年的,虽然平时工作中都有用到消息中心,但都总是不能够说明白其中的原理,于是觉得有必要把消息中心作为一个篇章,专门进行总结梳理一番看的时候,建议大家**不妨先看看问题,自己先尝试回答一下,再看答案**。看看自己掌握得如何了那准备好了的话,我们就要**开始啦**啊

01.为什么要使用消息中心?
消息中心,有以下几大作用:
- 消息通讯:可以作为基本的消息通讯,比如聊天室等工具的使用
- 异步处理 : 将一些实时性要求不是很强的业务异步处理,起到缓冲的作用,一定程度上也会避免因为有些消费者处理的太慢或者网络问题导致的通讯等待太久,因而导致的单个服务崩溃,甚至产生多个服务间的雪崩效应;
- 应用解耦 : 消息队列将消息生产者和消费者分离开来,可以实现应用解耦
- 流量削峰: 可以通过在应用前端采用消息队列来接收请求,可以达到削峰的目的:请求超过队列长度直接不处理,重定向至错误页面。类似于网关限流的作用冗余存储:消息队列把数据进行持久化,直到它们已经被完全处理,通过这一方式规避了数据丢失风险
02.聊聊Kafka的特点
- 可靠性:Kafka是分布式的、可分区的、数据可备份的、高度容错的
- 可扩展性:在无需停机的情况下实现轻松扩展
- 消息持久性:Kafka支持将消息持久化到本地磁盘
- 高性能:Kafka的消息发布订阅具有很高的吞吐量,即便存储了TB级的消息,它依然能保持稳定的性能
03.你会在哪些场景选择使用Kafka?
1)日志信息收集记录我个人接触的项目中,Kafka使用最多的场景,就是用它与FileBeats和ELK组成典型的日志收集、分析处理以及展示的框架
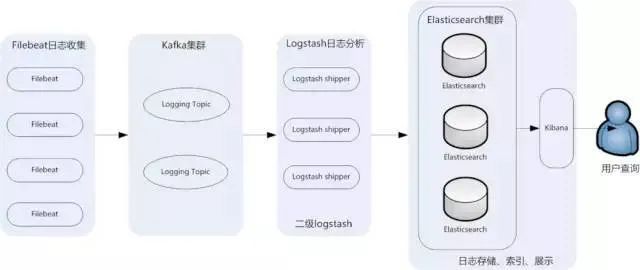
该图为**FileBeats+Kafka+ELK集群架构。**Kafka在框架中,作为消息缓冲队列
FileBeats先将数据传递给消息队列,Logstash server(二级Logstash)拉取消息队列中的数据,进行过滤和分析,然后将数据传递给Elasticsearch进行存储,最后,再由Kibana将日志和数据呈现给用户
由于引入了Kafka缓冲机制,即使远端Logstash server因故障停止运行
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4580
4580











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









