







1 概述
英文名称Collection,是用来存放对象的数据结构。其中长度可变,而且集合中可以存放不同类型的对象。并提供了一组操作成批对象的方法。
数组的缺点:长度是固定不可变的,访问方式单一,插入、删除等操作繁琐。
2 集合的继承结构

Collection接口
– List接口 : 数据有序,可以重复。
– ArrayList子类
– LinkedList子类
– Set接口 : 数据无序,不可以存重复值
– HashSet子类
– Map接口 : 键值对存数据
– HashMap
Collections工具类
3 常用方法
boolean add(E e):添加元素。
boolean addAll(Collection c):把小集合添加到大集合中 。
boolean contains(Object o) : 如果此 collection 包含指定的元素,则返回 true。
boolean isEmpty() :如果此 collection 没有元素,则返回 true。
Iterator iterator():返回在此 collection 的元素上进行迭代的迭代器。
boolean remove(Object o) :从此 collection 中移除指定元素的单个实例。
int size() :返回此 collection 中的元素数。
Objec[] toArray():返回对象数组
4 demo1:测试常用方法
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class Test_301_Collection {
public static void main(String[] args) {
Collection c = new ArrayList();//接口无法直接创建对象
c.add("hello");//添加元素
c.add("java");//添加元素
c.add("~");//添加元素
c.add(10);//jdk5后有自动装箱功能,相当于把10包装Integer.valueOf(10)
System.out.println(c.remove("~"));//移除元素
System.out.println(c.contains("a"));//判断包含关系
System.out.println(c.size());//集合的长度
System.out.println(c);
//for遍历集合
for(int i =0 ;i<c.size();i++) {
System.out.println(c.toArray()[i]);
}
//iterator迭代器遍历
Iterator it = c.iterator();//对 collection 进行迭代的迭代器
while (it.hasNext()) {//如果仍有元素,则返回 true
System.out.println(it.next());//返回迭代获取到的下一个元素
} } }
5 List接口
5.1 概述
有序的 collection(也称为序列)。此接口的用户可以对列表中每个元素的插入位置进行精确地控制。用户可以根据元素的整数索引(在列表中的位置)访问元素,并搜索列表中的元素。
5.2 特点
1、 数据有序
2、 允许存放重复元素
3、 元素都有索引
5.3 常用方法
ListIterator listIterator()
返回此列表元素的列表迭代器(按适当顺序)。
ListIterator listIterator(int index)
返回列表中元素的列表迭代器(按适当顺序),从列表的指定位置开始。
void add(int index, E element)
在列表的指定位置插入指定元素(可选操作)。
boolean addAll(int index, Collection<? extends E> c)
将指定 collection 中的所有元素都插入到列表中的指定位置(可选操作)。
List subList(int fromIndex, int toIndex)
返回列表中指定的 fromIndex(包括 )和 toIndex(不包括)之间的部分视图。
E get(int index)
返回列表中指定位置的元素。
int indexOf(Object o)
返回此列表中第一次出现的指定元素的索引;如果此列表不包含该元素,则返回 -1。
5.4 demo1:测试常用方法
package cn.tedu.list;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.ListIterator;
//这类用来测试List接口的常用方法
public class Test1_List {
public static void main(String[] args) {
//1、创建List对象
//特点1:List集合元素都有索引,可以根据索引直接定位元素
List list = new ArrayList();
//2、常用方法
list.add(111);
list.add(222);
list.add(333);
list.add(444);
list.add('a');
list.add("abc");
list.add(3,666);//在3的索引处添加指定元素
//特点2:元素有序, 怎么存就怎么放
System.out.println(list);//[111, 222, 333, 666, 444, a, abc]
Object obj = list.get(4);//get(m)-m是索引值,获取指定索引位置的元素
System.out.println(obj);
//3、迭代/遍历集合中的元素
//使用Collection接口提供的iterator()
Iterator it = list.iterator();
while(it.hasNext()) {//判断集合里有没有下个元素
Object o = it.next();
// System.out.println(o);
}
//使用List接口提供的listIterator()
//interfaceListIterator extends Iterator
//区别:可以使用父接口的功能,同时拥有自己的特有功能,不仅顺序向后迭代还可以逆向迭代
ListIterator it2 = list.listIterator();
while(it2.hasNext()) {
Object o = it2.next();
// System.out.println(o);
}
System.out.println();
List list2 = list.subList(1, 3);//subList(m,n)-m是开始索引,n是结束索引,其中含头不含尾类似于String.subString(m,n)
System.out.println(list2);
}
}
5.5 ArrayList
5.5.1 概述
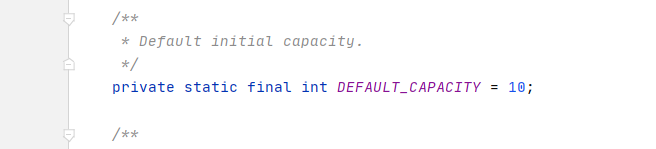
存在于java.util包中。内部用数组存放数据,封装了数组的操作,每个对象都有下标。内部数组默认初始容量是10。如果不够会以1.5倍容量增长。

查询快,增删数据效率会降低。
5.5.2 创建对象
new ArrayList():初始容量是10
5.5.3 demo1:测试常用方法
常用API,包括下标遍历,迭代器遍历
import java.util.ArrayList;
public class Test3_AL {
public static void main(String[] args) {
ArrayList list = new ArrayList();
list.add("aaa");//存入数据
list.add("123");
list.add("ccc");
list.add("ddd");
System.out.println(list);//list中内容
System.out.println(list.size());//集合长度
System.out.println(list.get(1));//根据下标获取元素
System.out.println();
System.out.println(list.remove(2));//移除下标对应的元素
System.out.println(list);
//下标遍历
for (int i = 0; i < list.size(); i++) {
System.out.print(list.get(i));
}
//Iterator迭代遍历,封装了下标
Iterator<String> it = list.iterator();
while (it.hasNext()) {//如果有数据
String s = it.next();//一个一个向后遍历
System.out.println(s);
}
}
}
5.2 LinkedList
5.2.1 概述
双向链表,两端效率高。底层就是数组和链表实现的。

5.2.3 常用方法
add()
get()
size()
remove(i)
remove(数据)
iterator()
addFirst() addLast()
getFirst() getLast()
removeFirst() removeLast()
5.2.4 demo1:测试迭代器遍历
双向链表:下标遍历效率低,迭代器遍历效率高
> import java.util.ArrayList;
>
> import java.util.Iterator;
>
> import java.util.LinkedList;
>
>
>
> public class tt {
>
> public static void main(String[] args) throws Exception {
>
> LinkedList ll = new LinkedList ();
>
> for (int i = 0; i < 100000; i++) {
>
> ll.add(100);
>
> }
>
> f1(ll);
>
> f2(ll);
>
> }
>
>
>
> private static void f2(LinkedList<Integer> ll) {
>
> long t = System.currentTimeMillis();
>
> Iterator it = ll.iterator();
>
> while(it.hasNext()) {
>
> it.next();
>
> }
>
> t = System.currentTimeMillis()-t;
>
> System.out.println("=====iterator========="+t);//16
>
> }
>
>
>
> private static void f1(LinkedList<Integer> ll) {
>
> long t = System.currentTimeMillis();
>
> for (int i = 0; i < ll.size(); i++) {
>
> ll.get(i);
>
> }
>
> long t1 = System.currentTimeMillis();
>
> System.out.println("~~~~for~~~~~~~"+(t1-t));//9078
>
> }
>
> }
5.3 ArrayList扩容
ArrayList相当于在没指定initialCapacity时就是会使用延迟分配对象数组空间,当第一次插入元素时才分配10(默认)个对象空间。假如有20个数据需要添加,那么会分别在第一次的时候,将ArrayList的容量变为10 (如下图一);之后扩容会按照1.5倍增长。也就是当添加第11个数据的时候,Arraylist继续扩容变为10*1.5=15(如下图二);当添加第16个数据时,继续扩容变为15 * 1.5 =22个

ArrayList没有对外暴露其容量个数,查看源码我们可以知道,实际其值存放在elementData对象数组中,那我们只需拿到这个数组的长度,观察其值变化了几次就知道其扩容了多少次。怎么获取呢?只能用反射技术了。
5.4 HashMap扩容
成长因子:
static final float DEFAULT_LOAD_FACTOR = 0.75f;
前面的讲述已经发现,当你空间只有仅仅为10的时候是很容易造成2个对象的hashcode 所对应的地址是一个位置的情况。这样就造成 2个 对象会形成散列桶(链表)。这时就有一个加载因子的参数,值默认为0.75 ,如果你hashmap的 空间有 100那么当你插入了75个元素的时候 hashmap就需要扩容了,不然的话会形成很长的散列桶结构,对于查询和插入都会增加时间,因为它要一个一个的equals比较。但又不能让加载因子很小,如0.01,这样显然是不合适的,频繁扩容会大大消耗你的内存。这时就存在着一个平衡,jdk中默认是0.75,当然负载因子可以根据自己的实际情况进行调整。
5.5 数组和链表区别
List是一个接口,它有两个常用的子类,ArrayList和LinkedList,看名字就可以看得出一种是基于数组实现另一个是基于链表实现的。
数组ArrayList遍历快,因为存储空间连续;链表LinkedList遍历慢,因为存储空间不连续,要去通过指针定位下一个元素,所以链表遍历慢。
数组插入元素和删除元素需要重新申请内存,然后将拼接结果保存进去,成本很高。例如有100个值,中间插入一个元素,需要数组重新拷贝。而这个动作对链表来说,太轻松了,改变一下相邻两个元素的指针即可。所以链表的插入和修改元素时性能非常高。
实际开发就根据它们各自不同的特点来匹配对应业务的特点。业务一次赋值,不会改变,顺序遍历,就采用数组;业务频繁变化,有新增,有删除,则链表更加适合。















 463
463











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









