









Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。使用这种方法可以降低被反爬虫概率,面对一些特殊的情况也可以很轻松的应对,这个爬虫并不像原来的爬虫,更像是明面上在工作,就是一个自动化罢了。
那么我们的流程思想主要是先进入总的列表页面,获取每个图片盒子的图片url,将其保存至一个列表,后期通过循环访问这个鞋url来获取图片信息,
直接看代码:
虽然,但是还是要先看好是否安装了selenium模块的,毕竟这个就是重点了,文章内容不丰富,审核老是不过,真是难受,后期更新一次可能又会审核不过了。
安装的部分,不用全部安装,实验的时候多装了几个,没有删除而已
#有些包使用不到的,如有缺失请先尝试注释掉继续运行,如果需要请先安装
#重点!!!先安装pip install selenium
import requests
from bs4 import BeautifulSoup
import re
import ssl
import lxml
# import urllib2
import urllib
import time
from selenium import webdriver
from lxml import etree
#导入库:
# from collections import Counter#没用到
#导入pandas库
import re
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# from snownlp import SnowNLP
# import jieba.posseg as psg#没用到
#解决方法
from selenium.webdriver.common.keys import Keys
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
import zipfile
# #下载工程浏览器:
# try:
# f =open('edgedriver_win64.zip')
# f.close()
# print("文件已存在,请运行下一步程序")
# except IOError:
# print("找不到该文件,正在进行下载")
# edgeurl='https://msedgedriver.azureedge.net/103.0.1264.37/edgedriver_win64.zip'
# response =requests.get(edgeurl, stream=False)
# with open('edgedriver_win64.zip', mode='wb') as f:
# f.write(response.content)
# print("下载完成!请运行下一步程序")
# #解压文件
# try:
# f =open("path/Driver_Notes/EULA")
# f.close()
# print("文件已存在,请运行下一步程序")
# except IOError:
# print("找不到该文件,正在进行解压----")
# f = zipfile.ZipFile('edgedriver_win64.zip','r')
# for file in f.namelist(): #f.namelist()返回列表,列表中的元素为压缩文件中的每个文件
# f.extract(file,"path/")
# print("解压完成!请运行下一步程序")如果没有存在微软浏览器开发工具,就会下载,如果已经有了,就直接跳过,接下来是输入我们所需要搜索的图片或图片类型:
#获取url
nr=str(input("请输入需要找的图片或图片类型:"))
baidu_url='http:########'
url=baidu_url+nr
path='D:/ch明蹄/jupyter/爬虫/qiye/path/msedgedriver.exe'
wd = webdriver.Edge(executable_path=path)#启动浏览器输入需要搜索的内容后,程序会打开我们刚刚的微软浏览器开发工具,下边是自定义的函数(现在更新的时候已经换电脑了,也没有原来的包,没法尝试运行,我记得这写代码好像被我改来爬取一些不营养的东西了,后面有没有改回来我就不记得了)
def openimg(n):#翻页滚动n为滚动次数
wd.get(url)#访问网页url
time.sleep(0.5)
js = "var q = document.documentElement.scrollTop="
ii=8000
for i in range(n):#滚动次数
time.sleep(0.5)
ii+=500
i1=str(ii)
pp=js+i1
i+=1
wd.execute_script(pp)
#计算图片个数
count_ul=wd.find_elements(By.XPATH,"//div[@class ='imgpage']/ul")#根据元素定位来确定位置
p=0
for i in count_ul:
count=i.find_elements(By.XPATH,"li")
p+=len(count)
print('预计图片的个数为',p,'左右')
#查找预览图片的位置
# imgdw=wd.find_elements(By.CSS_SELECTOR,"[class='imgitem normal']")#.click()#点击
imgdw=wd.find_elements(By.XPATH,"//div[@class ='imgpage']/ul/li")
#定位图片的连接
zimgurl=[]#创建一个url空间
zimgname=[]#创建一个名称空间
for imged in imgdw:
try:
imgurl=imged.get_attribute('data-objurl')
#判断连接是否为空
if len(imgurl) == 0:
print("数据为空")
continue
else:
#索取图片名称
try:
imgname=imged.text
zimgname.append(re.sub('[^\u4e00-\u9fa5]+', '',imgname[0:10]))
zimgurl.append(imgurl)
except:
print('读取错误')
except:
print('读取错误')
return zimgname,zimgurl
# break#使用函数滚动获取url函数,传入的参数是向下滚动多少次
zimgname,zimgurl=openimg(30) 判别图片的类型。根据网页后缀来判定图片的格式,并对其后缀进行更改(这里似乎存在一些问题,后面我好像解决了,但是不确定现在是否可行。我很不负责的)
def get_img(zimgurl,zimgname):#输入总的url列表
i=0
l=0
for img_url in zimgurl:
reimg = requests.get(img_url,headers=headers).content
time.sleep(1)
zp=img_url.lower()
a='jpg'
b='gif'
c='jpeg'
d='png'
if b in zp:
lastname='.gif'
elif d in zp:
lastname='.png'
elif c in zp:
lastname='.jpeg'
elif a in zp:
lastname='.jpg'
else:
lastname='.png'#!!根据实际需求来修改,比如搜索表情包时可以改为gif,搜索照片时可以更改为png或者jpg,以免照片信息丢失。
# print(reimg)
fileurl = "D:\\PACHONG\\find2\\" +str(l)+ zimgname[i] + lastname#填写自己所需要存放的路径,str(l)是为了防名称相同导致覆盖。
i+=1
with open(fileurl, 'wb') as f:
l+=1
time.sleep(0.5) # 每隔0.5秒下载一张图片放入D:
f.write(reimg)
print("{}->-{}".format(l,len(zimgurl)))
return 也可以先看一下所获得的图片名称大致情况:
获取图片:
get_img(zimgurl,zimgname)下载过程,等待就好
#制作列表
data=[]
data=pd.DataFrame(data)
data["name"]=zimgname
data["url"]=zimgurl
data.to_excel('Baidutuku.xlsx', encoding='utf-8', index=False)
data#关闭浏览器 wd.close() #爬虫慎用,虽没有任何作用,这只是爬虫的基础流程罢了,不用考虑本次项目是否存在任何意义。 #注意身体,早点休息! #后续还可以接入更多的端口,实现更多自动化,大数据就是从小数据出发,多了就变成了大数据,所以不要放过身边的这些小数据。
 结果展示
结果展示
如存在问题请留言,虽然博主不负责,但是也会尽力解决的,这也可以互相学习嘛,东西还是常用才会记得住,我已经很久没有接触了。
更新补充:下载到第五张就给我不干活了,气死我了,待我看看什么原因
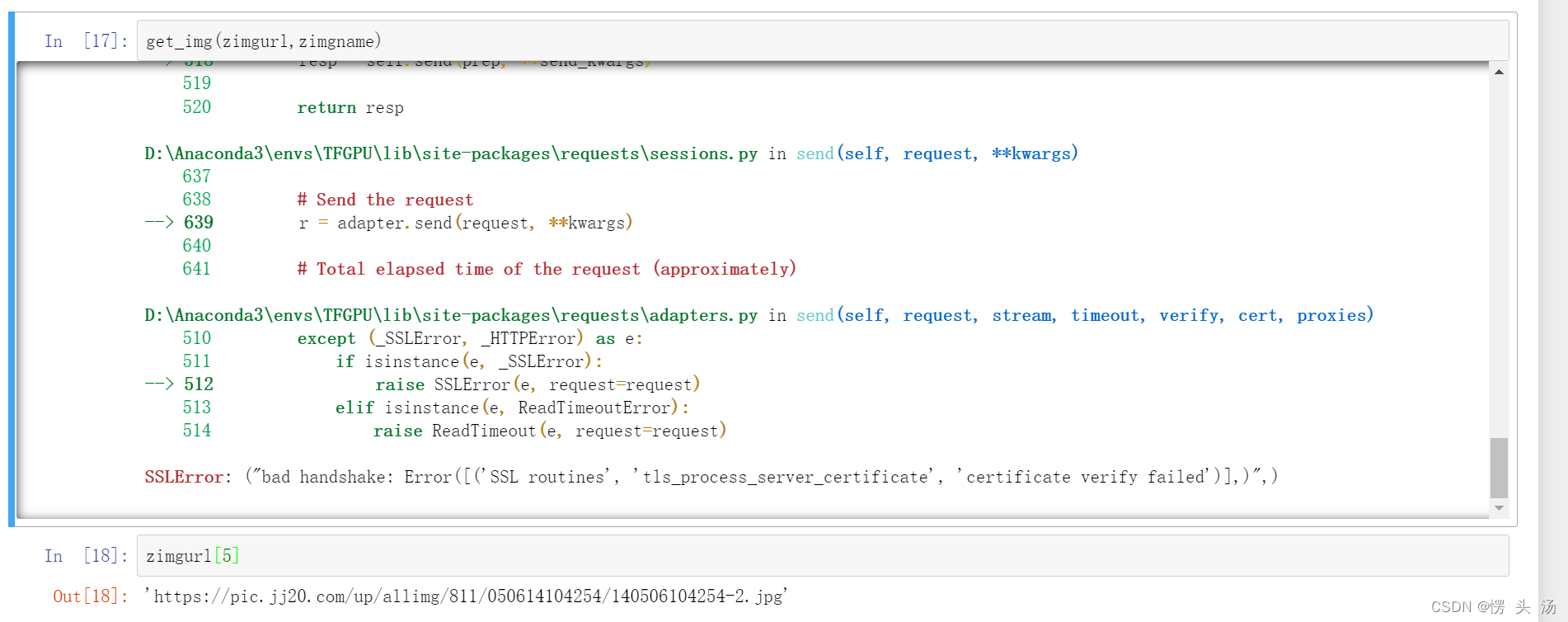
跟据我的调查发现,可以添加一个参数:verify=False,原因就是原来的证书过期了,这个代码是很久之前写的了,现在过期也是可以理解的。
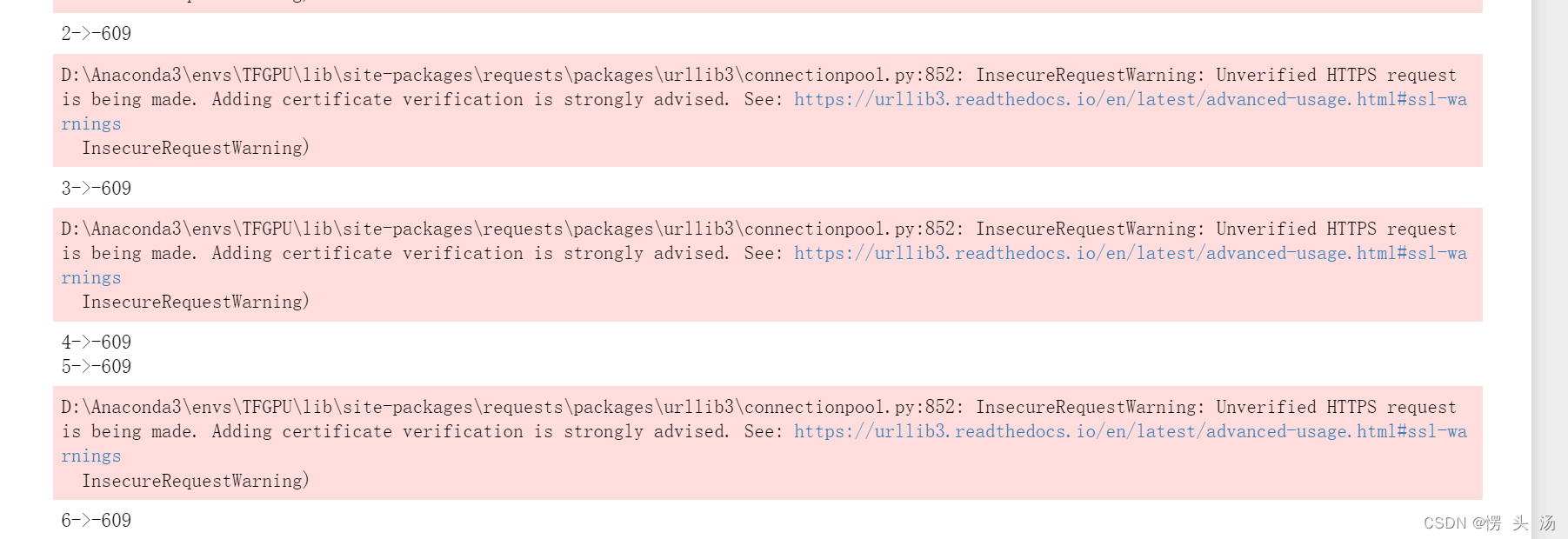
实在运行不了或者是出现了访问失败的网址,最简单的方法就是使用try,当然出现着的问题大概率是由于网址有问题,可以调整一下前边获取网址的代码,使其索引到正确的位置。

之前我可以下载到很多张的,现在好像不可以了,不晓得是不是我升级了浏览器开发工具版本的问题,也可能是我的python版本问题,如大伙有解决请告知我,我也学习学习。十分感谢,无偿奉献
















 935
935











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











