







JavaSE
Collection集合
集合概述
- 集合:集合是java中提供的一种容器,可以用来存储多个引用数据类型的数据。
- 集合和数组既然都是容器,它们有什么区别呢?
- 数组的长度是固定的。集合的长度是可变的。
- 数组中存储的是同一类型的元素,集合中可以存储任意类型数据。
- 集合存储的都是引用数据类型。如果想存储基本类型数据需要存储对应的包装类型。
单列集合常用类的继承体系
Collection:是单列集合类的根接口,用于存储一系列符合某种规则的元素,它有两个重要的子接口,分别是
java.util.List:List的特点是元素有序、元素可重复 ;List接口的主要实现类有java.util.ArrayList和java.util.LinkedList,
java.util.Set:Set的特点是元素不可重复。Set接口的主要实现类有java.util.HashSet和java.util.LinkedHashSet,java.util.TreeSet。
描述集合常用类的继承体系:

注意:上面这张图只是我们常用的集合有这些,不是说就只有这些集合。
Collection 常用功能
Collection是所有单列集合的父接口,因此在Collection中定义了单列集合(List和Set)通用的一些方法,这些方法可用于操作所有的单列集合。方法如下:
public boolean add(E e):把给定的对象添加到当前集合中 。public void clear():清空集合中所有的元素。public boolean remove(E e):把给定的对象在当前集合中删除。public boolean contains(Object obj):判断当前集合中是否包含给定的对象。public boolean isEmpty():判断当前集合是否为空。public int size():返回集合中元素的个数。public Object[] toArray():把集合中的元素,存储到数组中
tips: 有关Collection中的方法可不止上面这些,其他方法可以自行查看API学习。
Iterator迭代器
Iterator接口
迭代的概念
迭代:即Collection集合元素的通用获取方式。在取元素之前先要判断集合中有没有元素,如果有,就把这个元素取出来,继续再判断,如果还有就再取出来。一直把集合中的所有元素全部取出。这种取出方式专业术语称为迭代。
获取迭代器对象
Collection集合提供了一个获取迭代器的方法:
public Iterator iterator(): 获取集合对应的迭代器,用来遍历集合中的元素的。
Iterator接口的常用方法
public E next():返回迭代的下一个元素。public boolean hasNext():如果仍有元素可以迭代,则返回 true。
示例代码:
public class Demo {
public static void main(String[] args) {
// 创建一个Collection集合对象,指定集合中元素的类型为String
Collection<String> coll = new ArrayList<>();
// 往集合中添加元素: public boolean add(E e)
coll.add("小明");
coll.add("小红");
coll.add("小白");
coll.add("小黑");
// 遍历coll集合中的元素:使用Collection集合中的迭代器
// 获取coll集合对应的迭代器
Iterator<String> it = coll.iterator();
// 循环使用迭代器进行判断
while (it.hasNext()) {
// 使用迭代器取出元素
String next = it.next();
System.out.println("取出来的元素:"+next);
}
System.out.println("源集合:"+coll);// 源集合:[小明, 小红, 小白, 小黑]
}
}
迭代器的常见问题
常见问题一
- 在进行集合元素获取时,如果集合中已经没有元素可以迭代了,还继续使用迭代器的next方法,将会抛出java.util.NoSuchElementException没有集合元素异常。
public static void main(String[] args) throws Exception{ Collection<String> coll = new ArrayList<>(); coll.add("小明"); coll.add("小红"); coll.add("小白"); coll.add("小黑"); Iterator<String> it = coll.iterator(); while (it.hasNext()) { String s = it.next(); System.out.println(s);//正确 } System.out.println("====================="); System.out.println(it.next());//集合中已经没有元素可以迭代了 报异常 } - 解决办法: 如果还需要重新迭代,那么就重新获取一个新的迭代器对象进行操作
常见问题二
在进行集合元素迭代时,如果添加或移除集合中的元素 , 将无法继续迭代 , 将会抛出ConcurrentModificationException并发修改异常.
public static void main(String[] args) throws Exception{
Collection<String> coll = new ArrayList<>();
coll.add("小明");
coll.add("小红");
coll.add("小白");
coll.add("小黑");
Iterator<String> it = coll.iterator();
while (it.hasNext()) {
String s = it.next();
System.out.println(s);
//coll.add("小刚");// 报异常
//coll.remove(s);// 报异常
it.remove();
}
System.out.println("====================="+coll);
}
迭代器的实现原理
上面的案例已经完成了Iterator遍历集合的整个过程。当遍历集合时,首先通过调用t集合的iterator()方法获得迭代器对象,然后使用hashNext()方法判断集合中是否存在下一个元素,如果存在,则调用next()方法将元素取出,否则说明已到达了集合末尾,停止遍历元素。
Iterator迭代器对象在遍历集合时,内部采用指针的方式来跟踪集合中的元素。在调用Iterator的next方法之前,迭代器的索引位于第一个元素之前,不指向任何元素,当第一次调用迭代器的next方法后,迭代器的索引会向后移动一位,指向第一个元素并将该元素返回,当再次调用next方法时,迭代器的索引会指向第二个元素并将该元素返回,依此类推,直到hasNext方法返回false,表示到达了集合的末尾,终止对元素的遍历。

增强for
增强for循环(也称for each循环)是JDK1.5以后出来的一个高级for循环,专门用来遍历数组和集合的。它的内部原理其实是个Iterator迭代器,所以在遍历的过程中,不能对集合中的元素进行增删操作。
格式:
for(元素的数据类型 变量 : Collection集合or数组){
//写操作代码
}
它用于遍历Collection和数组。通常只进行遍历元素,不要在遍历的过程中对集合元素进行增删操作。
tips:
增强for循环必须有被遍历的目标,目标只能是Collection或者是数组;
增强for(迭代器)仅仅作为遍历操作出现,不能对集合进行增删元素操作,否则抛出ConcurrentModificationException并发修改异常
Collection是所有单列集合的根接口,如果要对单列集合进行遍历,通用的遍历方式是迭代器遍历或增强for遍历。
泛型
泛型的概述
可以在类或方法中预知地使用未知的类型。
泛型的作用
泛型的作用是在创建对象时,将未知的类型确定具体的类型。当没有指定泛型时,默认类型为Object类型。
定义和使用含有泛型的类
定义含有泛型的类
定义格式:
修饰符 class 类名<代表泛型的变量> { }
代表泛型的变量: 可以是任意字母 例如: T,E...
泛型在定义的时候不具体类型,使用的时候才具体类型。在使用的时候确定泛型的具体数据类型。
class ArrayList<E>{
public boolean add(E e){ }
public E get(int index){ }
....
}
确定泛型具体类型
在创建对象的时候确定泛型
例如,ArrayList<String> list = new ArrayList<String>();
此时,变量E的值就是String类型,那么我们的类型就可以理解为:
class ArrayList<String>{
public boolean add(String e){ }
public String get(int index){ }
...
}
定义和使用含有泛型的方法
定义含有泛型的方法
定义格式:
修饰符 <代表泛型的变量> 返回值类型 方法名(参数){ }
例如,
public class MyGenericMethod {
public <MVP> void show(MVP mvp) {
System.out.println(mvp.getClass());
}
public <MVP> MVP show2(MVP mvp) {
return mvp;
}
}
确定泛型具体类型
调用方法时,确定泛型的类型
public class GenericMethodDemo {
public static void main(String[] args) {
// 创建对象
MyGenericMethod mm = new MyGenericMethod();
// 演示看方法提示
mm.show("aaa");
mm.show(123);
mm.show(12.45);
}
}
定义和使用含有泛型的接口
定义含有泛型的接口
定义格式:
修饰符 interface接口名<代表泛型的变量> { }
例如,
public interface MyGenericInterface<E>{
public abstract void add(E e);
public abstract E getE();
}
确定泛型具体类型
使用格式:
1、定义实现类时确定泛型的类型
例如
public class MyImp1 implements MyGenericInterface<String> {
@Override
public void add(String e) {
// 省略...
}
@Override
public String getE() {
return null;
}
}
此时,泛型E的值就是String类型。
2、始终不确定泛型的类型,直到创建对象时,确定泛型的类型
例如
public class MyImp2<E> implements MyGenericInterface<E> {
@Override
public void add(E e) {
// 省略...
}
@Override
public E getE() {
return null;
}
}
确定泛型:
/*
* 使用
*/
public class GenericInterface {
public static void main(String[] args) {
MyImp2<String> my = new MyImp2<String>();
my.add("aa");
}
}
tips:泛型是一种未知的数据类型,定义在类上的泛型,使用类的时候会确定泛型的类型,定义在方法上的泛型,会在使用方法的时候确定泛型,定义在接口上的泛型,需要使用接口的时候确定泛型。
泛型通配符
通配符基本使用
泛型的通配符:不知道使用什么类型来接收的时候,此时可以使用?,?表示未知通配符。
此时只能接受数据,不能往该集合中存储数据。
例如:
public static void main(String[] args) {
Collection<Intger> list1 = new ArrayList<Integer>();
getElement(list1);
Collection<String> list2 = new ArrayList<String>();
getElement(list2);
}
public static void getElement(Collection<?> coll){}
//?代表可以接收任意类型
//泛型不存在继承关系 Collection<Object> list = new ArrayList<String>();这种是错误的。
通配符高级使用----受限泛型
之前设置泛型的时候,实际上是可以任意设置的,只要是类就可以设置。但是在JAVA的泛型中可以指定一个泛型的上限和下限。
泛型的上限:
- 格式:
类型名称 <? extends 类 > 对象名称 - 意义:
只能接收该类型及其子类
泛型的下限:
- 格式:
类型名称 <? super 类 > 对象名称 - 意义:
只能接收该类型及其父类型
比如:现已知Object类,String 类,Number类,Integer类,其中Number是Integer的父类
public static void main(String[] args) {
Collection<Integer> list1 = new ArrayList<Integer>();
Collection<String> list2 = new ArrayList<String>();
Collection<Number> list3 = new ArrayList<Number>();
Collection<Object> list4 = new ArrayList<Object>();
getElement1(list1);
getElement1(list2);//报错
getElement1(list3);
getElement1(list4);//报错
getElement2(list1);//报错
getElement2(list2);//报错
getElement2(list3);
getElement2(list4);
}
// 泛型的上限:此时的泛型?,必须是Number类型或者Number类型的子类
public static void getElement1(Collection<? extends Number> coll){}
// 泛型的下限:此时的泛型?,必须是Number类型或者Number类型的父类
public static void getElement2(Collection<? super Number> coll){}
数据结构
数据结构介绍
数据结构 : 其实就是存储数据和表示数据的方式。数据结构内容比较多,常见的数据结构:堆栈、队列、数组、链表和红黑树
常见数据结构
栈
- 栈:stack,又称堆栈,它是运算受限的线性表,其限制是仅允许在表的一端进行插入和删除操作,不允许在其他任何位置进行添加、查找、删除等操作。
简单的说:采用该结构的集合,对元素的存取有如下的特点
-
先进后出(即,存进去的元素,要在后它后面的元素依次取出后,才能取出该元素)。例如,子弹压进弹夹,先压进去的子弹在下面,后压进去的子弹在上面,当开枪时,先弹出上面的子弹,然后才能弹出下面的子弹。
-
栈的入口、出口的都是栈的顶端位置。

这里两个名词需要注意: -
压栈:就是存元素。即,把元素存储到栈的顶端位置,栈中已有元素依次向栈底方向移动一个位置。
-
弹栈:就是取元素。即,把栈的顶端位置元素取出,栈中已有元素依次向栈顶方向移动一个位置。
队列
队列:queue,简称队,它同堆栈一样,也是一种运算受限的线性表,其限制是仅允许在表的一端进行插入,而在表的另一端进行取出并删除。
简单的说,采用该结构的集合,对元素的存取有如下的特点:
- 先进先出(即,存进去的元素,要在后它前面的元素依次取出后,才能取出该元素)。例如,小火车过山洞,车头先进去,车尾后进去;车头先出来,车尾后出来。
- 队列的入口、出口各占一侧。例如,下图中的左侧为入口,右侧为出口。

数组
- 数组:Array,是有序的元素序列,数组是在内存中开辟一段连续的空间,并在此空间存放元素。就像是一排出租屋,有100个房间,从001到100每个房间都有固定编号,通过编号就可以快速找到租房子的人。
简单的说,采用该结构的集合,对元素的存取有如下的特点:
-
查找元素快:通过索引,可以快速访问指定位置的元素

-
增删元素慢
-
指定索引位置增加元素:需要创建一个新数组,将指定新元素存储在指定索引位置,再把原数组元素根据索引,复制到新数组对应索引的位置。如下图

指定索引位置删除元素:需要创建一个新数组,把原数组元素根据索引,复制到新数组对应索引的位置,原数组中指定索引位置元素不复制到新数组中。如下图

链表
链表:linked list,由一系列结点node(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。我们常说的链表结构有单向链表与双向链表,那么这里给大家介绍的是单向链表。
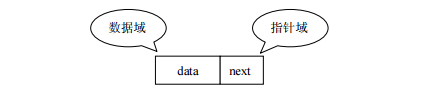
简单的说,采用该结构的集合,对元素的存取有如下的特点:
-
多个结点之间,通过地址进行连接。例如,多个人手拉手,每个人使用自己的右手拉住下个人的左手,依次类推,这样多个人就连在一起了。
-
查找元素慢:想查找某个元素,需要通过连接的节点,依次向后查找指定元素。
-
增删元素快:只需要修改链接下一个元素的地址值即可

树基本结构介绍
树具有的特点
- 每一个节点有零个或者多个子节点
- 没有父节点的节点称之为根节点,一个树最多有一个根节点。
- 每一个非根节点有且只有一个父节点

| 名词 | 含义 |
|---|---|
| 节点 | 指树中的一个元素 |
| 节点的度 | 节点拥有的子树的个数,二叉树的度不大于2 |
| 叶子节点 | 度为0的节点,也称之为终端结点 |
| 高度 | 叶子结点的高度为1,叶子结点的父节点高度为2,以此类推,根节点的高度最高 |
| 层 | 根节点在第一层,以此类推 |
| 父节点 | 若一个节点含有子节点,则这个节点称之为其子节点的父节点 |
| 子节点 | 子节点是父节点的下一层节点 |
| 兄弟节点 | 拥有共同父节点的节点互称为兄弟节点 |
二叉树
如果树中的每个节点的子节点的个数不超过2,那么该树就是一个二叉树。

二叉查找树
二叉查找树的特点:
- 左子树上所有的节点的值均小于等于他的根节点的值
- 右子树上所有的节点值均大于或者等于他的根节点的值
- 每一个子节点最多有两个子树
案例演示(20,18,23,22,17,24,19)数据的存储过程:

遍历获取元素的时候可以按照"左中右"的顺序进行遍历;
注意:二叉查找树存在的问题:会出现"瘸子"的现象,影响查询效率

平衡二叉树
概述
为了避免出现"瘸子"的现象,减少树的高度,提高我们的搜素效率,又存在一种树的结构:“平衡二叉树”
规则:它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树
如下图所示:

如上图所示,左图是一棵平衡二叉树,根节点10,左右两子树的高度差是1,而右图,虽然根节点左右两子树高度差是0,但是右子树15的左右子树高度差为2,不符合定义,所以右图不是一棵平衡二叉树。
旋转
在构建一棵平衡二叉树的过程中,当有新的节点要插入时,检查是否因插入后而破坏了树的平衡,如果是,则需要做旋转去改变树的结构。
左旋
左旋就是将节点的右支往左拉,右子节点变成父节点,并把晋升之后多余的左子节点出让给降级节点的右子节点;

右旋
将节点的左支往右拉,左子节点变成了父节点,并把晋升之后多余的右子节点出让给降级节点的左子节点

举个例子,像上图是否平衡二叉树的图里面,左图在没插入前"19"节点前,该树还是平衡二叉树,但是在插入"19"后,导致了"15"的左右子树失去了"平衡",所以此时可以将"15"节点进行左旋,让"15"自身把节点出让给"17"作为"17"的左树,使得"17"节点左右子树平衡,而"15"节点没有子树,左右也平衡了。如下图:

新节点插入
由于在构建平衡二叉树的时候,当有新节点插入时,都会判断插入后时候平衡,这说明了插入新节点前,都是平衡的,也即高度差绝对值不会超过1。当新节点插入后,有可能会有导致树不平衡,这时候就需要进行调整,而可能出现的情况就有4种,分别称作左左,左右,右左,右右。
左左:只需要做一次右旋就变成了平衡二叉树。
右右:只需要做一次左旋就变成了平衡二叉树。
左右:先做一次分支的左旋,再做一次树的右旋,才能变成平衡二叉树。
右左:先做一次分支的右旋,再做一次数的左旋,才能变成平衡二叉树。
- 左左
左左:只需要做一次右旋就变成了平衡二叉树。
左左即为在原来平衡的二叉树上,在节点的左子树的左子树下,有新节点插入,导致节点的左右子树的高度差为2,如下即为"10"节点的左子树"7",的左子树"4",插入了节点"5"或"3"导致失衡。

左左调整其实比较简单,只需要对节点进行右旋即可,如下图,对节点"10"进行右旋。
- 左右
左右:先做一次分支的左旋,再做一次树的右旋,才能变成平衡二叉树。
左右即为在原来平衡的二叉树上,在节点的左子树的右子树下,有新节点插入,导致节点的左右子树的高度差为2,如上即为"11"节点的左子树"7",的右子树"9",插入了节点"10"或"8"导致失衡。

左右的调整就不能像左左一样,进行一次旋转就完成调整。我们不妨先试着让左右像左左一样对"11"节点进行右旋,结果如下图,右图的二叉树依然不平衡,而右图就是右左,即左右跟右左互为镜像,左左跟右右也互为镜像。

左右这种情况,进行一次旋转是不能满足条件的,正确的调整方式是,将左右进行第一次旋转,将左右先调整成左左,然后再对左左进行调整,从而使得二叉树平衡。即先对上图的节点"7"进行左旋,使得二叉树变成了左左,之后再对"11"节点进行右旋,此时二叉树就调整完成,如下图:

- 右左
右左:先做一次分支的右旋,再做一次数的左旋,才能变成平衡二叉树。
右左即为在原来平衡的二叉树上,在节点的右子树的左子树下,有新节点插入,导致节点的左右子树的高度差为2,如上即为"11"节点的右子树"15",的左子树"13",插入了节点"12"或"14"导致失衡。

右左跟左右其实互为镜像,所以调整过程就反过来,先对节点"15"进行右旋,使得二叉树变成右右,之后再对"11"节点进行左旋,此时二叉树就调整完成,如下图:

- 右右
右右:只需要做一次左旋就变成了平衡二叉树。
右右即为在原来平衡的二叉树上,在节点的右子树的右子树下,有新节点插入,导致节点的左右子树的高度差为2,如下即为"11"节点的右子树"13",的左子树"15",插入了节点"14"或"19"导致失衡。

右右只需对节点进行一次左旋即可调整平衡,如下图,对"11"节点进行左旋。

红黑树
红黑树是一种自平衡的二叉查找树,是计算机科学中用到的一种数据结构,它是在1972年由Rudolf Bayer发明的,当时被称之为平衡二叉B树,后来,在1978年被Leoj.Guibas和Robert Sedgewick修改为如今的"红黑树"。它是一种特殊的二叉查找树,红黑树的每一个节点上都有存储位表示节点的颜色,可以是红或者黑;红黑树不是高度平衡的,它的平衡是通过"红黑树的特性"进行实现的;
- 红黑树的特性:
1.每一个节点或是红色的,或者是黑色的
2.根节点必须是黑色
3.每个叶节点(Nil)是黑色的;(如果一个节点没有子节点或者父节点,则该节点相应的指针属性值为Nil,这些Nil视为叶节点)
4.如果某一个节点是红色,那么它的子节点必须是黑色(不能出现两个红色节点相连的情况)
5.对每一个节点,从该节点到其所有后代叶节点的简单路径上,均包含相同数目的黑色节点
如下图所示就是一个

在进行元素插入的时候,和之前一样; 每一次插入完毕以后,使用黑色规则进行校验,如果不满足红黑规则,就需要通过变色,左旋和右旋来调整树,使其满足红黑规则。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









