







Unicode发展历史
1.iso8859编码(字母转化成ascall码)
起初的“iso8859“编码方式,只是编码了英语字母,将每一个字母对应一个数字(将字母编码后得到的数字则称为ascall码)。A->Z(65->90),a->z(97->122).这种编码方式只用1个字节存储编码。
使用iso8859编码方式将”ABCabc”编码,代码展示如下:
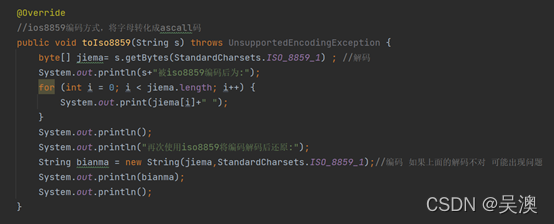
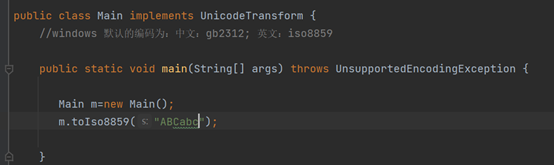
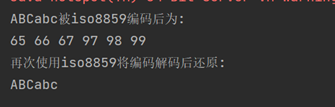
代码运行结果:
2.gb2312编码方式
Gb2312编码方式是在iso8859编码方式的基础上,增加了对汉字的编码。并且,增加了一个字节存储汉字的编码(即使用两个字节)。这里为了区别字母和汉字的编码,将汉字得到的编码的每一个字节最高位设置为1,所以汉字编码后每一个字节都为负数。
使用gb2312编码方式将“ABC通信原理”编码,代码展示如下:
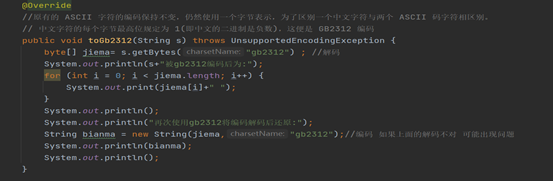
代码运行结果:
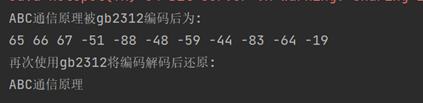
可以看到,“ABC”得到的编码(ascll码)为正值,”通信原理”得到的编码为负值。
3.gbk编码方式
由于汉字太多了,并且在不断增加。人们在使用过程中发现之前的gb2312编码方式很多汉字都无法适用。所以,增加了gbk编码。
GBK编码,是对GB2312编码的扩展,因此完全兼容GB2312-80标准。GBK编码依然采用双字节编码方案,其编码范围:8140-FEFE(高字节从81到FE,低字节从40到FE),剔除xx7F码位,共23940个码位。
使用gbk编码方式将“ABC通信原理”编码,代码展示如下:

代码运行结果如下:
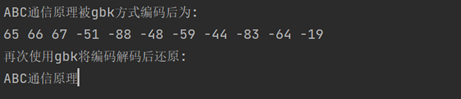
可以看到,使用gbk与使用gb2312对”ABC通信原理”进行编码后得到的结果完全一致。因为gbk完全继承了gb2312,只是收录了更多的汉字。
使用gb2312对“ABC通信原理”进行编码得到的结果如下:

3.unicode编码
除了字母和汉字,世界上所有的国家的语言同样需要编码。所以出现了unicode编码,Unicode编码是适合所有国家文字的一种编码方式,比如朝鲜语、韩文、日文、乌克兰语等。。
使用代码对中文版、韩文版、日文版、俄文版的“通信原理“进行unicode编码代码展示如下。
(”通信原理”、”의사 소통의 원칙”、“通信の原理”、” Принципы коммуникации“)
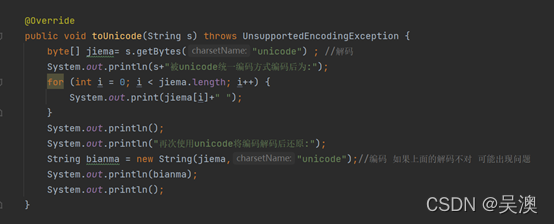
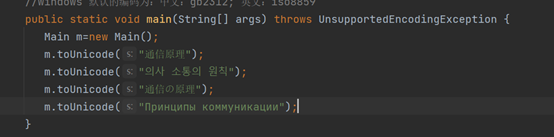
运行结果如下:
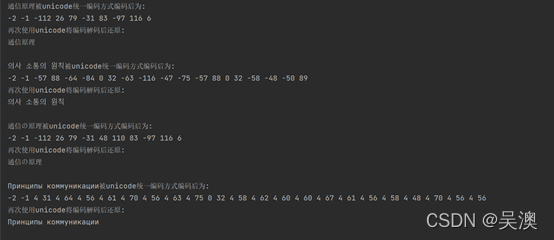
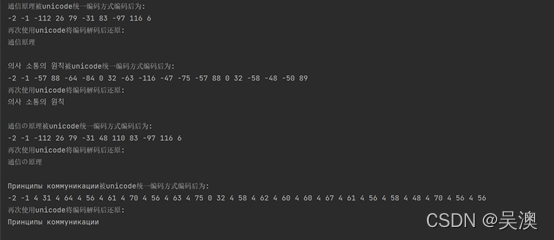
可以看到,同样都是“通信原理“,不同的语言经过unicode编码后得到的编码是不一样的。所以,实际上在unicode编码中,每一个国家的文字都有唯一对应的编码。
4.utf-8编码(万国码)
Utf-8编码是一种针对 Unicode 的可变长度字符编码,又称 为“万国码“,是 Unicode 的实现方式之一。编码中的第一个字节仍与 ASCII 兼容,这使得原来处理 ASCII 字符的软件无须或只需做少部分修改,即可继续使用。因此,它逐渐成为电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码。互联网工程工作小组(IETF)要求所有互联网协议都必须支持 UTF-8 编码。
utf-8是我们现在通信主要采用的Unicode编码方式,其“可变长“、”兼容iso8859“的特性使得它极其全面和方便。
使用代码对中文版、韩文版、日文版、俄文版的“通信原理“进行utf-8编码代码展示如下。
(”通信原理”、”의사 소통의 원칙”、“通信の原理”、” Принципы коммуникации“)
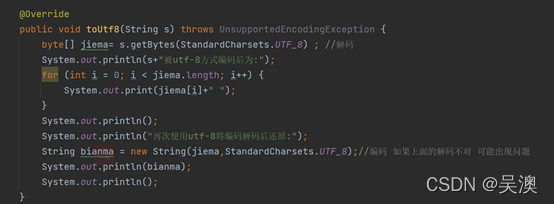
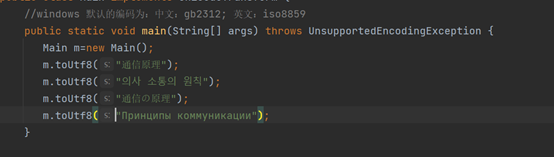
运行结果如下:
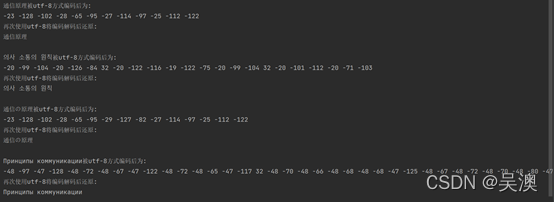
Utf-8编码方式编码和普通的unicode编码方式编码得到的结果还是不一致的,其明显区别在于“编码更长”.
使用普通unicode编码的到的结果如下:
总结
以上,是unicode编码的发展历史。通过对编码方式的学习我们可以了解到,在计算机中所有的字符的识别都需要参照一个映射表,计算机实际上只能识别这些二进制编码,通过这张参照表再映射人们所能看到的文字。编码方式的发展,实际上是这映射表的完善历史。


















 1005
1005

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











