







终极目标: inode 和 软硬连接
文件系统 :Ext2
之前谈论的是一个被打开的文件!
如果一个文件没有被打开呢??磁盘中进行存储的。
我们会关心如下问题
1、路径问题
2、存储问题
3、获取的问题(属性 +文件内容)
4、效率
如何讲解?
1、认识硬件 --- 磁盘
磁盘在冯诺依曼体系结构中是一个外设,同时也是唯一个机械设备
a.磁盘的物理构成

磁头是一面一个
盘面是双面的
磁头不和盘面接触
把盘面想象成一个一个的吸铁石,对吸铁石充放电该变NS级就相当于改变二进制01
b.磁盘的存储构成
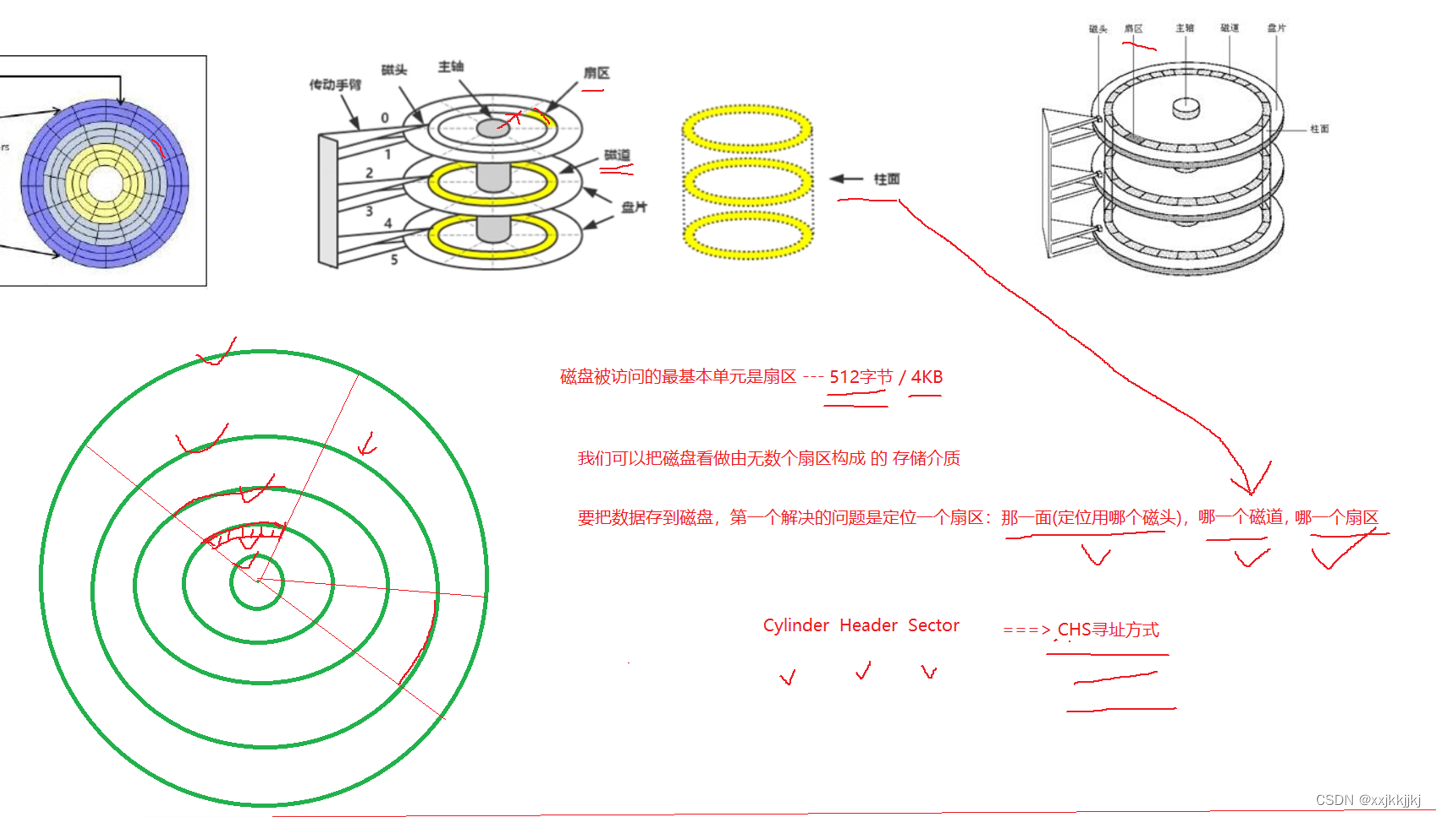
磁盘被访问的最基本单元是扇区 — 512字节/4KB
我们可以把磁盘看做由无数个扇区构成的存储介质
要把数据存到磁盘,第一个解决的问题是定位哪一个扇区︰哪一面(定位用哪个磁头),哪一个磁道,哪一个扇区
因为6个磁头大家一起动,所以定位到一个磁道后,竖下来看类似一个柱面,其实也是在说明哪个磁道。
磁盘在盘面上左右摆动 :定位磁道和柱面的过程
盘片快速转动 :定位扇区的过程

硬件级别找到任意一个扇区
所以要找到任意一个扇区,只需要告诉磁盘这三个数据
cylinder 磁道 header 磁头 Sector 扇区 CHS寻址方式
影响磁盘效率的主要因素
首先排除 定位哪个磁头/盘面 这个损耗并不高,因为10个盘也就20个磁头,很快就能找到
磁头在左右摆动时确定磁道时 这是一个消耗
确定磁道后,盘面自转到某个扇区,这个自转转速又是一个消耗
所以:

2、对磁盘进行逻辑结构
首先确定盘面有编号:第几面,磁道也有编号:一个面几个磁道,扇区也有编号:一个磁道几个扇区
并且虽然同心圆的周长不同但是利用扇区的分布疏密程度来控制每一个磁道分布着相同数量的扇区

磁盘是一个双面盘,它和磁带形状差不多,我们可以把磁盘想象成磁带读磁带的那一条长带,这个长带就是一个线性结构
操作系统用LBA地址,磁盘中使用CHS地址
此时好处就是 操作系统看待磁盘结构就是线性的,不用再关心CHS地址了,直接使用LBA地址用算法转换CHS就能找到任意扇区
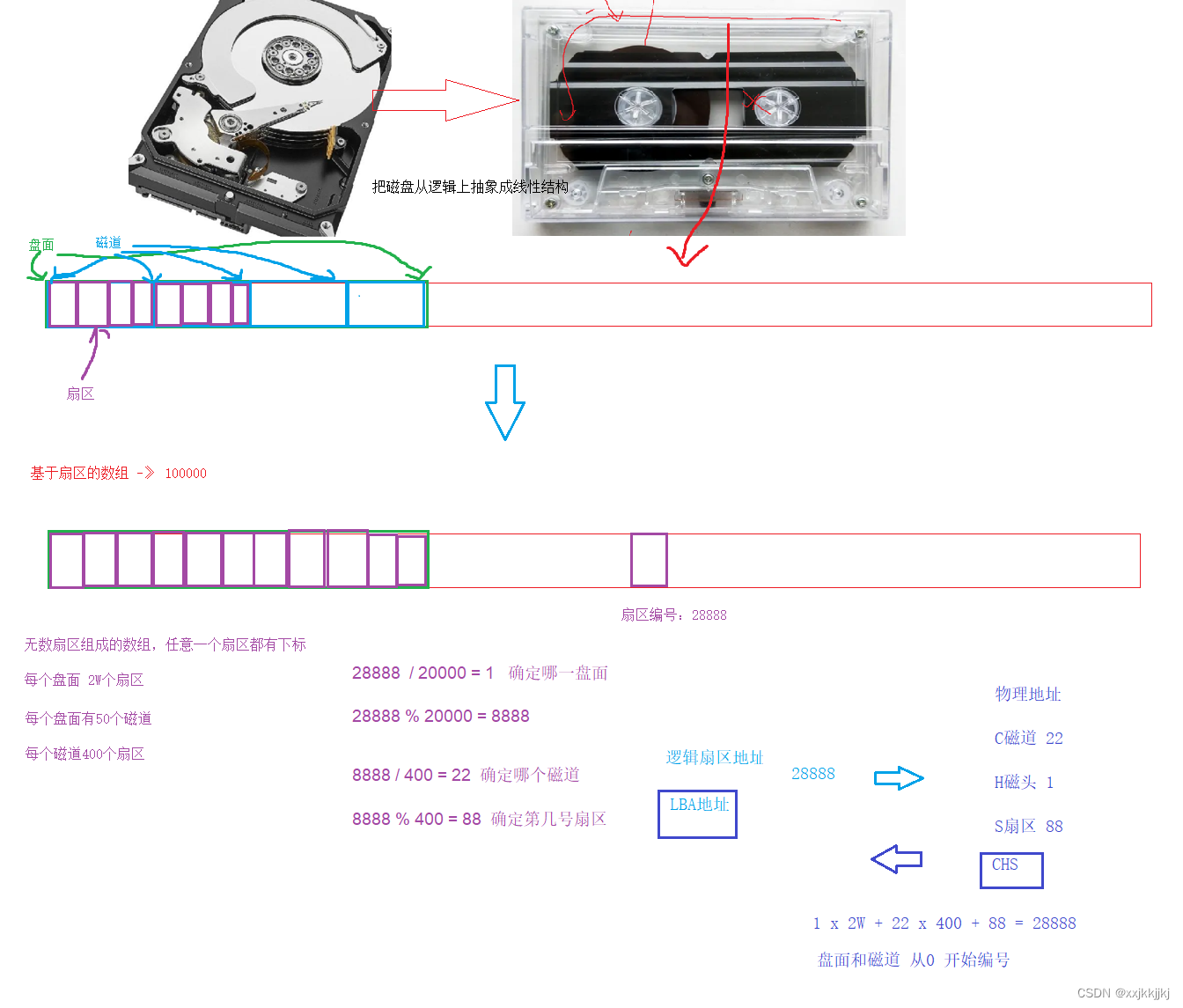
实际上操作系统用不用定义这个数组呢?根本不需要,只要描述磁盘容量是多大 单个扇区是多少,计算出总共多少个扇区,每个地址他就清楚了(盲猜是编号)。
3、文件系统
对这个无数扇区组成的大数组再继续分区,分组,利用分治的思想管理好最终分组的10GB空间,也就管理好了分区的大空间,整个数组也就管理好了。
格式化
每一个分区再被使用之前,都必须提前先将部分文件系统的属性信息提前设置进对应的分区中,方便我们后续使用这个分区或者分组
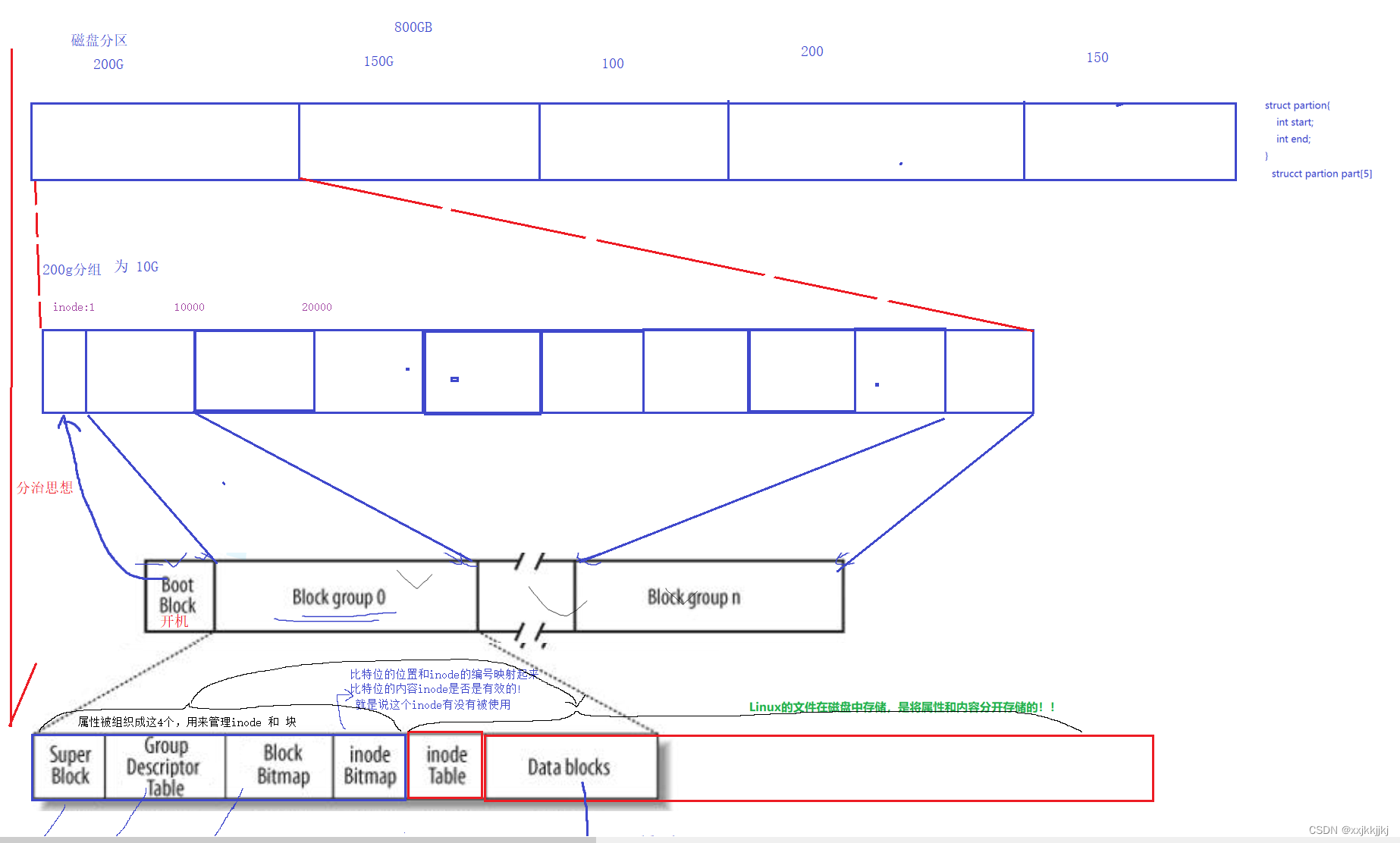
data blocks:整个分组block group 中 ,存文件内容的区域,以块的形式呈现–4KB 称之为文件系统的块大小。
data blocks具有唯一编号
inode:单个文件的所有属性,128字节 是一个结构体
Linux系统中,一个文件,一个inode。
每一个inode都有自己的inode编号(inode的设置,是以分区为单位的,不能跨分区),对你没看错就是分区200g和150g里面各自从0开始而不是分组中
inode table : 所有inode的集合,inode具有唯一编号
整个分组的Inode编号如下:

block bitmap 和块号映射,表示该块是否被使用
inode bitmap 和inode 的编号映射,表示该inode号是否被使用
GDT 整个分组的基本使用情况,也就是这10g
Super block 是整个分区,也就是这一个200g的使用情况
一共有多少个组,每个组的大小…
但不会每个组都存在,只会零星点缀进几个分组中,super bolck丢失后可以通过备份找回
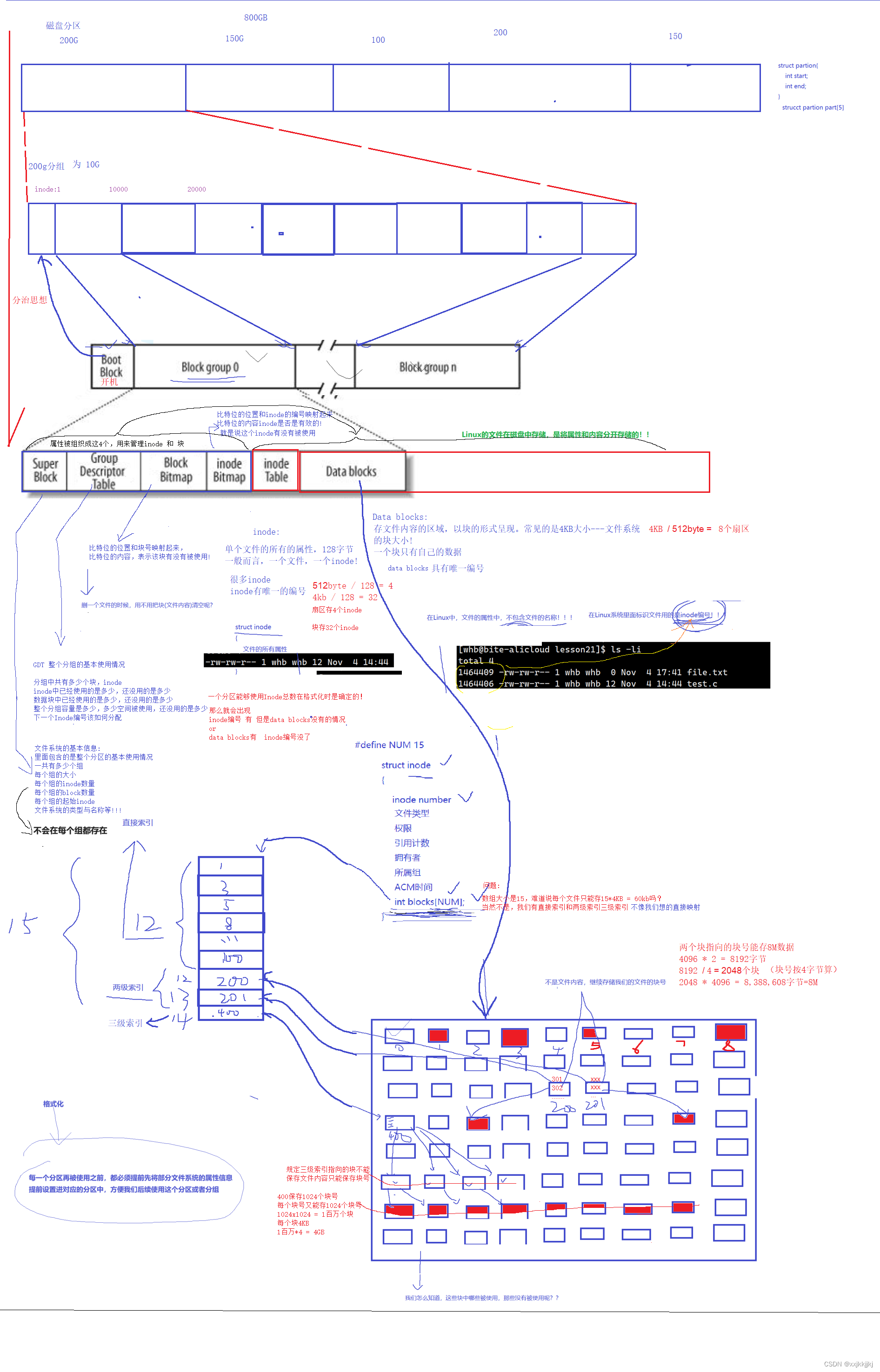
解决如下问题的前置知识:
每一个inode都有自己的inode编号(inode的设置,是以分区为单位的,不能跨分区),对你没看错就是分区200g和150g里面各自从0开始而不是分组中
inode表示文件的所有属性,文件名,并不属于inode内的属性!
新建一个文件,系统要做什么?
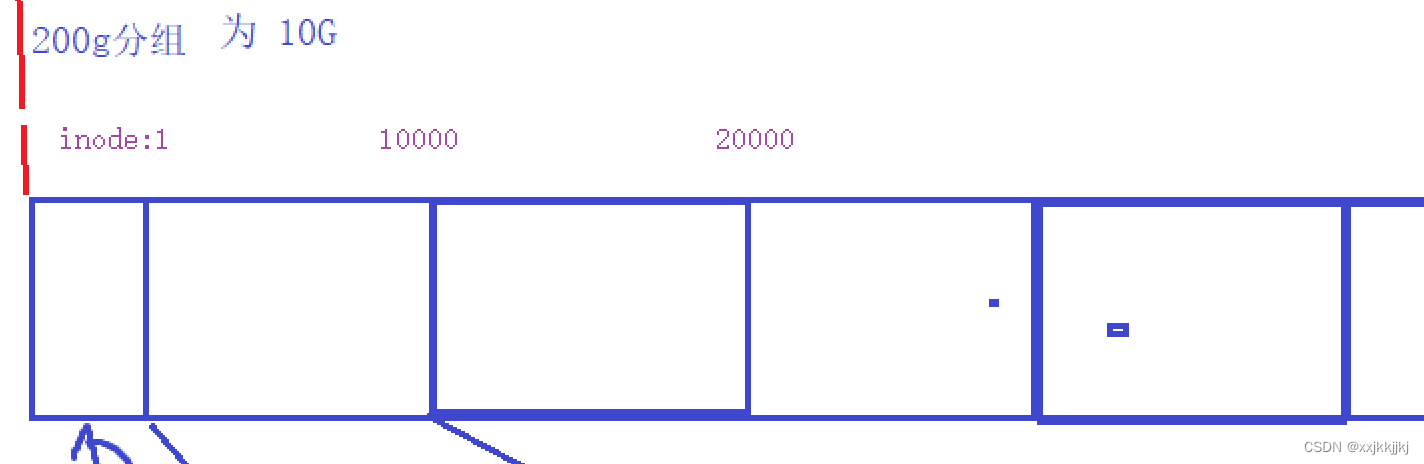
新建文件一定是在系统某一个路径去新建,路径可以帮我们确定哪一个分区那里面,在分区中找到还有inode剩余的某一个分组,查GDT看看Inode使用率如果还有,再查Inode bitmap扫描位图结构找到最近一个没有被使用的编号,位图都是从0开始,假设第5个bit位被分配了,这个5还需要加上分组中Inode的起始编号才是真正分配的inode编号,假设此时是第一个分组中,则分配5号Inode,把对应5号inode 位图由0置1,然后再inode table中找到5号inode把属性往里面一填,文件就算新建成功了
如果文件中有内容,我们拿着Inode号找到该分组,先确认数据量的大小后再Block bitmap找到没有使用的块号,把块号填入到Inode属性中数组中,然后直接跳转过去把数据写入到块中。更新块位图,则内容写入完毕。
删除一个文件,系统要做什么?
需要找到这个文件的inode,根据文件所处的目录确定哪一分区,根据inode编号范围确定在哪一个分组,读取inode table有inode编号找到文件属性中的块号表,拿着块号去修改块号位图由1置0,则所有内容被干掉了
把对应inode编号减去分组的起始Inode编号,比如说10005,则10005-10000 = 5 ; 此时就可以去Inode位图中5号比特位由1置0,此时属性被干掉了
只需要修改位图是否有效,而不需要真的去清除数据,下次直接覆盖就可以,这样所以删除文件效率高。
查找一个文件,系统要做什么?
如果文件存在,找到文件的inode , 在inode bitmap中查看inode属性有效,此时读取Inode table把属性全拿出来,通过属性找到所有的块,内容也就出来了。然后再加载到内容中。
修改一个文件,系统要做什么?
修改文件内容or属性,你要改就得找到Inode,在找到它的属性和内容,进行修改。
上述所有操作的前提都是找到inode,我怎么知道一个文件的Inode编号???
使用者从来没关心过inode,用的是文件名!
如何理解“目录”?
目录也是文件,也有自己的inode。目录也要有自己的属性
目录有内容吗??
文件=内容+属性
要不要数据块? ? ?
目录也有数据块!!
里面放什么呢??
该目录下,文件的文件名和对应文件的inode的映射关系!!
通过目录下的文件名和文件Inode映射 就能拿到文件的Inode,就可以对接上面 新建等对文件的操作了
但是目录是文件,它也有inode编号,那我怎么知道目录的inode呢?我只知道目录名啊
我要找到当前目录的Inode,我需要找上一级目录的Inode然后读出我的Inode,一路向上找绝对会找到根目录,根目录的文件名是确定的,他有Inode,它的子目录都能找到了,总体流程就是一路递归到根目录,再从根目录返回每一个路径上的目录数据块,最终找到目标目录。
递归是我们从内部讲起的,就说要一路找上去,实际拿着文件路径从左到右解析就行
因为我们的任何一个文件,在进程内部都有路径,按照路径,应用层是知道文件和路径的
剩下的就是从左向右解析就成
结论
访问任何文件都需要路径来访问
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









