







系列文章目录
Hadoop第一章:环境搭建
Hadoop第二章:集群搭建(上)
Hadoop第二章:集群搭建(中)
Hadoop第二章:集群搭建(下)
Hadoop第三章:Shell命令
Hadoop第四章:Client客户端
Hadoop第四章:Client客户端2.0
Hadoop第五章:词频统计
Hadoop第五章:序列化
前言
项目案例
在企业开发中往往常用的基本序列化类型不能满足所有需求,比如在Hadoop框架内部传递一个bean对象,那么该对象就需要实现序列化接口。
案例分析

一、环境创建
1.新建一个包
2.创建需要的类
二、编写函数
1.FlowBean
package com.atguigu.mapreduce.writable;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
//编写一个Bean,继承Writable接口
public class FlowBean implements Writable {
private long upFlow;
private long downFlow;
private long sumFlow;
//提供无参构造
public FlowBean() {
}
//编写get/set方法
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
public void setSumFlow() {
this.sumFlow = this.upFlow + this.downFlow;
}
//实现序列化和反序列化
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeLong(upFlow);
dataOutput.writeLong(downFlow);
dataOutput.writeLong(sumFlow);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
this.upFlow=dataInput.readLong();
this.downFlow=dataInput.readLong();
this.sumFlow=dataInput.readLong();
}
//重写ToString
@Override
public String toString() {
return upFlow + "\t" + downFlow + "\t" + sumFlow;
}
}
2.FlowMapper
package com.atguigu.mapreduce.writable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class FlowMapper extends Mapper<LongWritable, Text, Text, FlowBean> {
private Text outK = new Text();
private FlowBean outV = new FlowBean();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, FlowBean>.Context context) throws IOException, InterruptedException {
//1.获取一行数据,转成字符串
String line = value.toString();
//2.切割数据
String[] split = line.split("\t");
//3.抓取需要的数据:手机号,上行流量,下行流量
String phone = split[1];
String up = split[split.length - 3];
String down = split[split.length - 2];
//4.封装outK,outV
outK.set(phone);
outV.setUpFlow(Long.parseLong(up));
outV.setDownFlow(Long.parseLong(down));
outV.setSumFlow();
//5.写出outK outV
context.write(outK, outV);
}
}
3.FlowReducer
package com.atguigu.mapreduce.writable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class FlowReducer extends Reducer<Text, FlowBean, Text, FlowBean> {
private FlowBean ontV = new FlowBean();
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Reducer<Text, FlowBean, Text, FlowBean>.Context context) throws IOException, InterruptedException {
long toatlUp = 0;
long toatlDown = 0;
//1.遍历values,将其中的上行流量,下行流量分别累加
for (FlowBean value : values) {
toatlUp += value.getUpFlow();
toatlDown += value.getDownFlow();
}
//2.封装outV
ontV.setUpFlow(toatlUp);
ontV.setDownFlow(toatlDown);
ontV.setSumFlow();
//3.写出outK outV
context.write(key, ontV);
}
}
4.FlowDriver
package com.atguigu.mapreduce.writable;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class FlowDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//1.获取job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//2.设置jar
job.setJarByClass(FlowDriver.class);
//3.关联mapper和Reducer
job.setMapperClass(FlowMapper.class);
job.setReducerClass(FlowReducer.class);
//4.设置mapper 输出key和value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
//5.设置最终数据输出的key和value类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
//6.设置数据的输入路径和输出路径
FileInputFormat.setInputPaths(job, new Path("D:\\learn\\hadoop\\writable\\input"));
FileOutputFormat.setOutputPath(job, new Path("D:\\learn\\hadoop\\writable\\output"));
//7.提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
三、函数运行
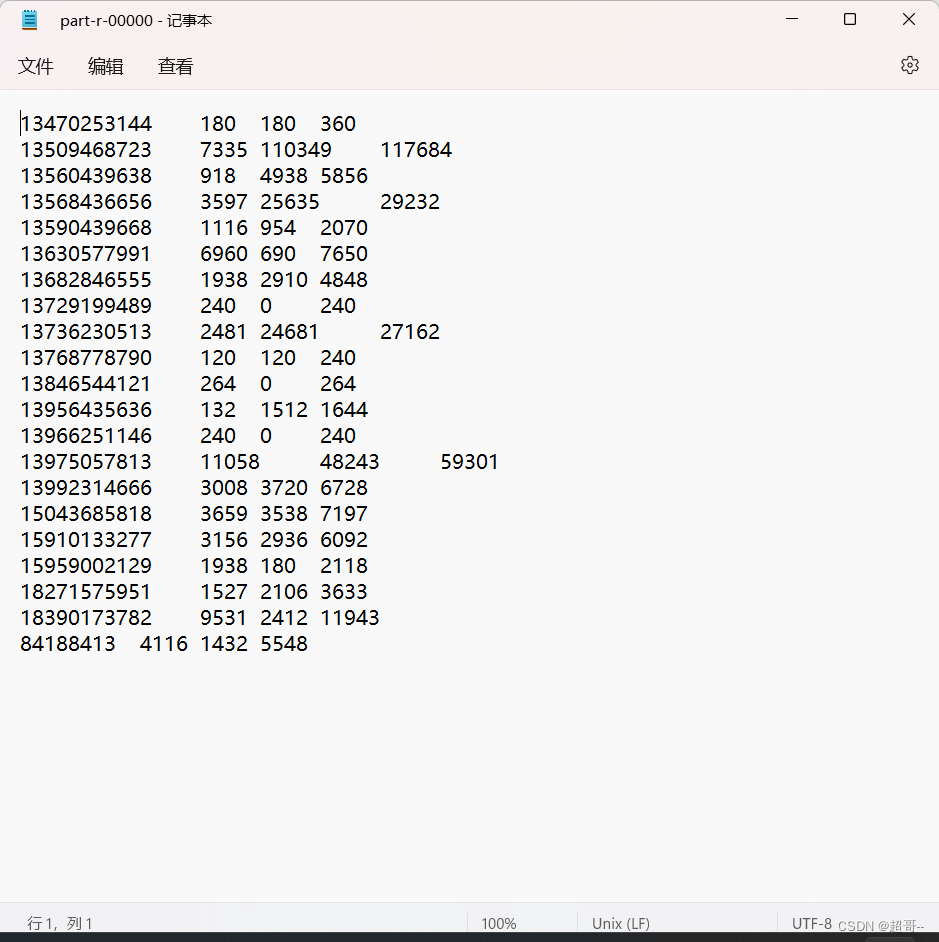
运行成功
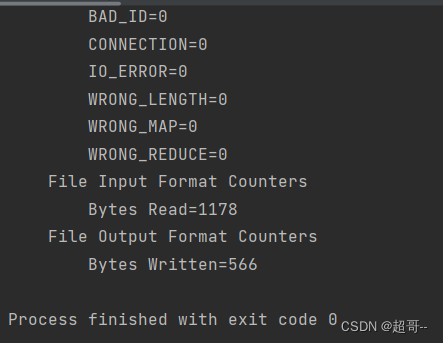
运行结果
总结
序列化的内容到此就基本结束了。hadoop学习,任重而道远啊。















 1746
1746











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









