







数据库入门
1.数据库和应用程序

2.什么是数据库
数据库由表、关系以及操作对象组成
3.数据库的作用
- 存储大量数据,方便检索和访问
- 降低存储数据的冗余度
- 保持数据的一致性、完整性
- 存储的数据可以共享
- 便于实现数据的安全性
6.流行的数据库
- Oracle:Oracle公司的产品,“关系-对象”型数据库,产品免费但服务收费
- MySQL:Oracle公司的产品,关系型数据库,体积小、速度快、成本低,而且开放源代码
- SQL Server:针对不同用户群体的多个版本,易用性好,微软公司的产品
- DB2:IBM公司的产品,支持多操作系统、多种类型的硬件和设备
7.存储引擎
数据库对同样的数据有着不同的存储方式和管理方式,在MySQL中就称为存储引擎

8.表
- 主键:表中每行数据的唯一标识
- 外键:用于联系不同表中数据的标识
9.MySQL支持SQL语句
- 数据定义语句(DDL)
- 数据操纵语句(DML)
- 事务控制语句(TCL)
- 数据控制语句(DCL)
10.DDL
用于改变数据库结构,包括创建、更改和删除数据库对象
用于操作表结构的DDL语句有:
CREATE DATABASE:创建数据库DROP DATABASE:删除数据库CREATE TABLE:创建表ALTER TABLE:修改表DROP TABLE:删除表- …
11.数据完整性
数据的可靠性和准确性就是数据完整性
数据完整性的问题大多是由于设计引起的,建表的时候就应当保证以后数据输入是正确的,错误的、不合法的数据不允许输入
实体完整性:主键约束,不允许重复、不允许为空
域完整性:域约束(约束普通字段),限制数据类型、检查约束、默认值、非空约束
引用完整性:外键约束,外键值必须在引用的表中存在,否则不允许添加
12.常用数据类型

MySQL管理数据
1.SQL
结构化查询语言
2.运算符
比较运算符:=、>、<、>=、<=、<>(不等于)、!
表示范围时>= AND <=可以用BETWEEN AND代替
逻辑运算符:AND、OR、NOT
OR一般建议用IN代替
通配符:_(一个任意字符)、%(任意长度的字符串)、[](指定范围内的一个字符串)、[^](不在指定范围内的一个字符串)
使用通配符查询时要使用LIKE
3.增删改查
插入数据:
INSERT INTO 表名(字段名...) VALUES(值...);
如果插入所有列的数据时,字段名可以省略,但是自动增长的主键要用null代替
修改数据:
UPDATE 表名 SET 字段名 = 新值 [WHERE 条件];
删除数据:
DELETE FROM 表名 [WHERE 条件];
查询数据:
SELECT 字段名 FROM 表名 [WHERE 条件];
SQL查询
1.去重复
SELECT DISTINCT 字段名 FROM 表名 [WHERE 条件];
加了DISTINCT就可以去除重复项
2.排序
SELECT 字段名 FROM 表名 [WHERE 条件] ORDER BY 字段名 ASC; -- 升序排列
SELECT 字段名 FROM 表名 [WHERE 条件] ORDER BY 字段名 DESC; -- 降序排列
可以按多个字段排序,但后面字段的排序不能影响前面字段的排序
3.别名
SELECT 字段名 [AS] 别名 FROM 表名 [WHERE 条件];
4.聚合函数
MAX(); -- 最大值
MIN(); -- 最小值
AVG(); -- 平均值
SUM(); -- 求总和
COUNT(); -- 求个数
5.分组
当查询结果中同时包括普通字段和聚合函数时必须使用GROUP BY
SELECT 字段名, 聚合函数 FROM 表名 [WHERE 条件] GROUP BY 字段名 [HAVING 条件];
6.分页
SELECT 字段名 FROM 表名 LIMIT 起始下标, 查询数量;
MySQL高级查询(一)
1.子查询
子查询就是嵌套在另一个查询中的SELECT语句
当查询条件不明确时,可以利用子查询在另一张表中查询需要的条件
SELECT 字段名
FROM 表名
WHERE (SELECT 字段名
FROM 表名
WHERE 条件);
利用EXISTS可判断有没有某个数据
SELECT 字段名
FROM 表名
WHERE [NOT] EXISTS(SELECT 1
FROM 表名
WHERE 条件);
2.自连接查询
当只需要在一张表中查询数据但又无法直接查询出目标数据时,就可以使用自查询,将同一张表取两个别名,当做两张表来使用
SELECT 别名2.字段名
FROM 表名 别名1, 表名 别名2
WHERE 别名1.字段名 = 别名2.字段名 -- 主外键关系
条件;
3.分支判断
SELECT 字段1, (CASE WHEN 判断条件A THEN 执行语句A
WHEN 判断条件B THEN 执行语句B
ELSE 执行语句C END) [AS] 字段2
FROM 表名
[WHERE 条件];
MySQL高级查询(二)
1.多表连接查询
- 内连接:列出与连接条件匹配的数据行,它使用比较运算符比较被连接列的列值,结果集中仅包含符合查询条件和连接条件的数据行
- 外连接:左外连接、右外连接、完全外连接
- 交叉连接:返回左表中的所有行,左表中的每一行与右表中的所有行组合。交叉连接也称笛卡尔积。
内连接与外连接都是连接主外键关联的数据行
2.内连接
第一种语法:
SELECT 字段
FROM 表1 INNER JOIN 表2 INNER JOIN 表3
ON 连接条件1 AND 连接条件2
[WHERE 条件];
第二种语法:
SELECT 字段
FROM 表1, 表2, 表3
WHERE 连接条件1 AND 连接条件2 AND 条件;
内连接只查询匹配关系的数据行
3.左外连接
使用LEFT JOIN或LEFT OUTER JOIN
左外连接的结果集包括LEFT JOIN子句中指定的左表的所有行,而不仅仅是连接列所匹配的行。如果左表的某行在右表中没有匹配行,则在相关联的结果集行中右表的所有选择列表列均为空值NULL
SELECT 字段
FROM 左表 LEFT JOIN 右表
ON 连接条件
[WHERE 条件];
4.右外连接
使用RIGHT JOIN或RIGHT OUTER JOIN
右外连接的结果集包括RIGHT JOIN子句中指定的右表的所有行,而不仅仅是连接列所匹配的行。如果右表的某行在左表中没有匹配行,则在相关联的结果集行中左表的所有选择列表列均为空值NULL
SELECT 字段
FROM 左表 RIGHT JOIN 右表
ON 连接条件
[WHERE 条件];
5.完全外连接
MySQL不支持完全外连接
使用FULL JOIN或FULL OUTER JOIN
完全外连接返回左表和右表的所有行。当某行在另一个表中没有匹配行时,则另一个表的选择列表列均为空值NULL
在MySQL中要想实现完全外连接,可以使用关键字UNION连接一个左外连接和一个右外连接
UNION可以合并两个结果集,但不会显示重复的数据行;UNION ALL也可以合并两个结果集,重复的数据行也会显示
6.交叉连接
使用CROSS JOIN
交叉连接返回左表中的所有行,左表中的每一行与右表中的所有行组合。交叉连接也叫笛卡尔积
SELECT 字段
FROM 左表 CROSS JOIN 右表
交叉连接可以把两张没有关联关系的表合在一起
MySQL事务和索引
1.日期时间函数
/*获取语句开始执行时的日期和时间*/
NOW()
CURRENT_TIMESTAMP()
LOCALTIME()
/*获取动态的实时日期和时间*/
SYSDATE()
/*获取当前日期*/
CURDATE()
CURRENT_DATE()
/*获取当前时间*/
CURTIME()
CURRENT_TIME()
/*获取日期中的年份*/
YEAR()
/*获取日期中的月份*/
MONTH()
/*获取日期中的日*/
DAY()
/*获取日期中的小时*/
HOUR()
/*获取日期中的分钟*/
MINUTE()
/*获取日期中的秒*/
SECOND()
/*获取日期属于当月的第几个星期*/
WEEK()
/*获取日期属于第几个季度*/
QUARTER()
/*获取日期属于当月的第几天*/
DAYOFMONTH()
/*返回日期参数d加上一段时间后的日期,参数expr决定时间的长度,参数type决定所操作的对象*/
ADDDATE(d, interval expr type)
/*返回日期参数减去一段时间后的日期,参数expr决定时间的长度,参数type决定所操作的对象*/
SUBDATE(d,interval expr type)
/*返回两个日期的整数差*/
TIMESTAMPDIFF(unit, datetime_expr1, datetime_expr2)
2.字符串函数
/*拼接字符串*/
CONCAT(s1, s2, ...)
/*获取字符串长度*/
LENGTH(str)
/*字母大小写转换*/
UPPER(str)
LOWER(str)
/*返回字符串str中的前length长度的字符串*/
LEFT(str, length)
/*返回字符串str中的后length长度的字符串*/
RIGHT(str, lenght)
/*从字符串str中pos开始截取length长度的字符串*/
SUBSTRING()
/*去除字符串首尾空格*/
TRIM(str)
/*将字符串中的子字符串old_str替换为new_str*/
REPLACE(str, old_str, new_str)
3.数学函数
/*返回0~1之间的随机浮点数*/
RAND()
/*返回大于或等于x的最小整数*/
CEIL(x)
/*返回小于或等于x的最大整数*/
FLOOR(x)
/*返回数值x,保留小数点后y位(去尾)*/
TRUNCATE(x, y)
/*返回数值x,保留小数点后y位(四舍五入)*/
ROUND(x, y)
4.事务
事务是作为单个逻辑工作单元执行的一系列操作,这些操作作为一个整体一起向系统提交,要么都执行,要么都不执行,事务是一个不可分割的逻辑工作单元
5.事务的特性
事务必须具备ACID属性:
- 原子性(Atomicity):事务是一个完整的操作,事务的各步操作是不可分割的(原子的),要么都执行,要么都不执行
- 一致性(Consistency):当事务完成时数据必须保持一致状态
- 隔离性(Isolation):对数据进行修改的所有并发事务是彼此隔离的,这表明事务必须是独立的,它不应以任何方式依赖于或影响其他事务
- 永久性(Durability):事务完成后,它对数据库的修改被永久保存,事务日志能够保持事务的永久性
6.事务操作
MySQL中事务操作包括四个:
START TRANSACTION -- 开始一个新的事务
COMMIT -- 提交当前事务,做出永久改变
ROLLBACK -- 回滚当前事务,放弃之前的操作
SET autocommit = {} -- 对当前会话禁用{0}或启用{1}自动提交模式
7.索引
数据库中的数据是按页存放的
索引是数据库编排数据的内部方法,它为数据库提供一种方法来编排查询数据
索引页是数据库中存储索引的数据页
使用索引可以大大提高数据库的检索速度,改善数据库性能
8.索引的分类
- 唯一索引:索引列的值必须唯一,但允许有空值
- 主键索引:为表定义一个主键将自动创建一个主键索引,主键索引是唯一索引的特殊类型。主键索引要求主键中的每个值是唯一的,而且不能为空
- 普通索引:允许在定义索引的列中插入重复值和空值,只是为了查询数据可以更快
- 组合索引:在表中的多个字段组合上创建的索引
- 全文索引:一堆文字中,通过其中某个关键字等,就能找到该字段所属的记录行
9.索引的创建语法
/*创建*/
CREATE [UNIQUE] INDEX indexName ON mytable(columnname(length));
ALTER mytable ADD [UNIQUE] INDEX [indexName] ON (columnname(length));
/*删除*/
DROP INDEX [indexName] ON mytable;
/*查看*/
SHOW INDEX FROM table_name\G
10.索引的优缺点
优点:
- 加快访问速度
- 加强行的唯一性
缺点:
- 带索引的表在数据库中需要更多的存储空间
- 操纵数据的命令需要更长的处理时间,因为它们需要对索引进行更新
JDBC操作MySQL(一)
1.JDBC
JDBC是Java数据库连接技术的简称提供连接各种常用数据库的能力

2.JDBC API
与数据库建立连接、执行SQL语句、处理结果
DriverManager:依据数据库的不同,管理JDBC驱动Connection:负责连接数据库并担任传送数据的任务Statement:由Connection产生,负责执行SQL语句ResultSet:负责保存Statement执行后所产生的查询结果

3.Statement常用方法
| 方法名 | 说明 |
|---|---|
| ResultSet executeQuery(String sql) | 执行SQL查询并获取到ResultSet对象 |
| int executeUpdate(String sql) | 可以执行插入、删除、修改等操作,返回执行该操作所影响的行数 |
| boolean execute(String sql) | 可以执行任意SQL语句,然后获得一个布尔值,表示是否返回ResultSet |
4.ResultSet常用方法
| 方法名 | 说明 |
|---|---|
| boolean next() | 将光标从当前位置向下移动一行 |
| void close() | 关闭ResultSet对象 |
| int getInt(int colIndex) | 以int形式获取结果集当前行指定列号值 |
| int getInt(String colLabel) | 以int形式获取结果集当前行指定列名值 |
| float getFloat(int colIndex) | 以float形式获取结果集当前行指定列号值 |
| float getFloat(String colLabel) | 以float形式获取结果集当前行指定列名值 |
| String getString(int colIndex) | 以String形式获取结果集当前指定列号值 |
| String getString(String colLabel) | 以String形式获取结果集当前指定列名值 |
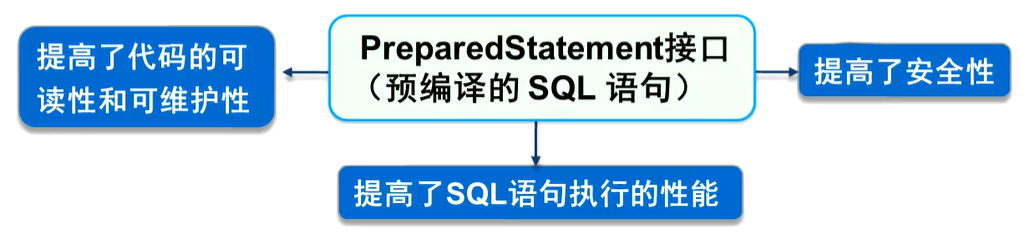
5.PreparedStatement
PreparedStatement接口继承了Statement接口,比Statement对象使用起来更加灵活,效率更高,并且可以防止SQL注入
分层架构
1.分层特点
每一层都有自己的职责
上一层不用关心下一层的实现细节,只需要通过调用下一层对外提供的接口来实现特定功能
上一层可以调用下一层的功能,下一层不能调用上一层功能
2.分层的好处
各层专注于自己功能的实现,便于提高质量
便于分工协作,提高开发效率
便于代码复用
便于程序扩展
3.分层原则
封装性原则:每个层向外提供接口,但是隐藏内部实现
顺序访问原则:下一层为上一层服务,但不使用上层的服务
4.数据传递
在分层结构中,不同层之间通过实体类传递数据
5.持久化
持久化是将程序中的数据在瞬时状态和持久状态间转换的机制
6.DAO
Data Access Object(数据存取对象)
位于业务逻辑和持久化数据之间
实现对持久化数据的访问
DAO起着转换器的作用,把实体类转换为数据库中的记录
7.DAO模式的作用
- 隔离业务逻辑代码和数据访问代码
- 隔离不同数据库的实现
8.DAO模式的组成部分
DAO接口,DAO实现类,实体类,数据库连接和关闭工具类

数据库设计和MySQL优化
1.数据库设计步骤
- 收集信息
- 标识对象(实体):标识数据库要管理的关键对象或实体
- 标识每个实体的属性
- 标识对象之间的关系
2.E-R(Entity-Relationship)实体关系图

3.数据库三大范式
- 第一范式(1NF):确保每列的原子性,每一列都是不可再分的最小数据单元
- 第二范式(2NF):确保每个表只描述一件事情,在满足第一范式的基础上,除了主键以外的所有列都依赖与该主键
- 第三范式(3NF):在满足第二范式的基础上,非主键字段之间不能有依赖关系
4.MySQL慢查询
开启慢查询日志,可以让MySQL记录下查询超过指定时间的语句,通过定位分析性能的瓶颈,才能更好的优化数据库系统的性能
slow_query_log慢查询开启状态
slow_query_log_file慢查询日志存放的位置
long_query_time查询超过多少秒才记录
-- 将slow_query_log全局变量设置为“ON”状态
set global slow_query_log = 'ON';
-- 查询超过一秒就记录
show global long_query_time = 1;
-- 查看慢查询相关参数
show variables like 'slow_query%';
-- 设置记录所有未使用索引的查询SQL到慢查询日志
set global log_queries_not_using_indexes = ON;
5.MySQL优化
- 对查询进行优化,应尽量避免全表扫描,首先应考虑在
WHERE及ORDER BY涉及的列上建立索引 EXPLAIN你的SELECT查询- 应尽量避免在
WHERE子句中使用!=或<>或OR操作符,否则引擎将放弃使用索引而进行全表扫描 - 避免
SELECT * - 永远为每张表设置一个ID
- 使用
ENUM而不是VARCHAR - 应尽量避免在
WHERE子句中对字段进行NULL值判断,否则将导致引擎放弃使用索引而进行全表扫描 - 使用连接(
JOIN)来代替子查询
6.EXPLAIN 你的SELECT查询
使用EXPLAIN关键字可以让你知道MySQL是如何处理你的SQL语句的,这可以帮你分析你的查询语句或是表结构的性能瓶颈。
EXPLAIN的查询结果还会告诉你你的索引主键是被如何利用的,你的数据表是如何被搜索和排序的等等
EXPLAIN
SELECT * FROM index_data WHERE dnaem = '457';
- table:显示这一行的数据是关于哪张表的
- type:显示连接使用了哪种类型,从最好到最差的连接类型为
const,eq_reg,ref,range,indexhe,ALL - possible_keys:表示查询时可能使用的索引
- key:实际使用的索引
- ref:显示索引的哪一列被使用了,如果可能的话,是一个常数
- rows:扫描的行数
- Extra:查询使用的方式
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











