






列式存储的优势一方面体现在存储上能节约空间、减少 IO,另一方面依靠列式数据结构做计算上的优化。
简单来说两者的区别就是如何组织表

行式存储对于 OLTP 场景是很自然的:大多数操作都以实体(entity)为单位,即大多为增删改查一整行记录,显然把一行数据存在物理上相邻的位置是个很好的选择。

但是对于 OLAP 场景,一个典型的查询需要遍历整个表,进行分组、排序、聚合等操作,分析型 SQL 常常不会用到所有的列,而仅仅对其中某些感兴趣的列做运算,那一行中那些无关的列也不得不参与扫描。同一列的数据被一个接一个紧挨着存放在一起,表的每列构成一个长数组。

列存储的优势
因此,列存储对于OLAP 场景优势有:
- 当查询语句只涉及部分列时,只需要扫描相关的列
- 每一列的数据都是相同类型的,彼此间相关性更大,对列数据压缩的效率较高(有大量重复的数据,并且利于数据结构填充的优化和压缩,对于数字列这种数据类型可以采取更多有利的算法去压缩存储。)
对比总结一下: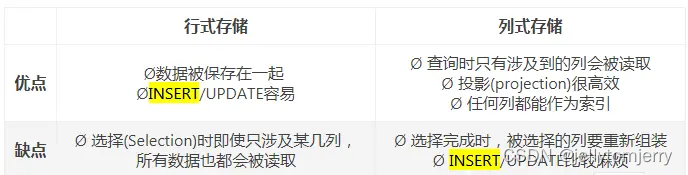
列式存储读取数据更快的其他原因
- 列式存储把相同类型的数据归在一起,压缩比可以很高,通常能到10%~25%。数据库的瓶颈通常在IO,很高的压缩比,可以大大减轻数据读取的压力,提高响应速度。
- 除去字符串类型,其他类型的字段通常是固定长度的,而且在磁盘和内存的字节顺序通常是一致的,可以直接映射,省去了解析的过程。而在行存储中,只要有变长的字段存在,需要逐行逐字段的解析。
- 列式存储可以向量化的处理一个字段。可以将一个列的一整块连续数据读入CPU cache,效率非常高。而且,可以利用CPU的向量化处理指令并行处理一些常用计算,譬如求和,比较大小等等。而这一切在行存储中都做不到。
- 因为数据表中的数据类型都是用户定义的,开发数据库的各种算子的时候,通常都是虚拟函数。在行存储中,意味着在每一行evaluate这个算子(譬如加法算子)的时候,我们都需要一个很大的case语句,对不同的数据类型分别处理,效率很低。而在列式存储中,极端情况下,对整个列只要做一次case处理就可以了,效率就会很高。当然近几年,很多数据库引擎都引入了JIT,行存储这方面的劣势在缩小。
行存储和列存储优缺点对比
显而易见,两种存储格式都有各自的优缺点:
1)行存储的写入是一次性完成,消耗的时间比列存储少,并且能够保证数据的完整性,缺点是数据读取过程中会产生冗余数据,如果只有少量数据,此影响可以忽略;数量大可能会影响到数据的处理效率。
2)列存储在写入效率、保证数据完整性上都不如行存储,它的优势是在读取过程,不会产生冗余数据,这对数据完整性要求不高的大数据处理领域,比如互联网,犹为重要。














 3374
3374











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









