







Discounted Return
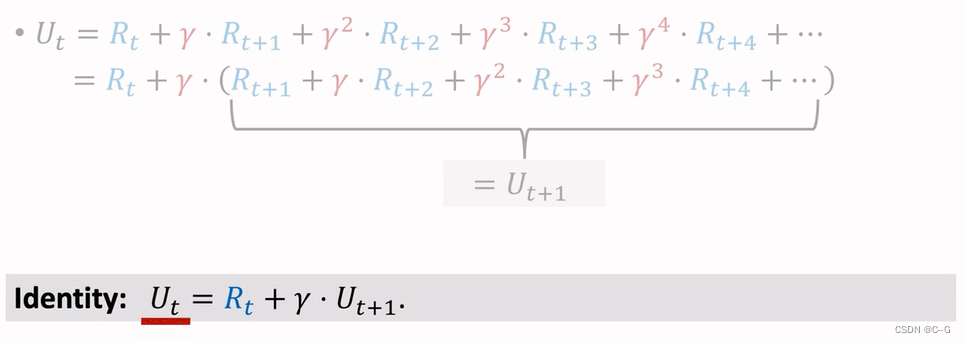


Sarsa
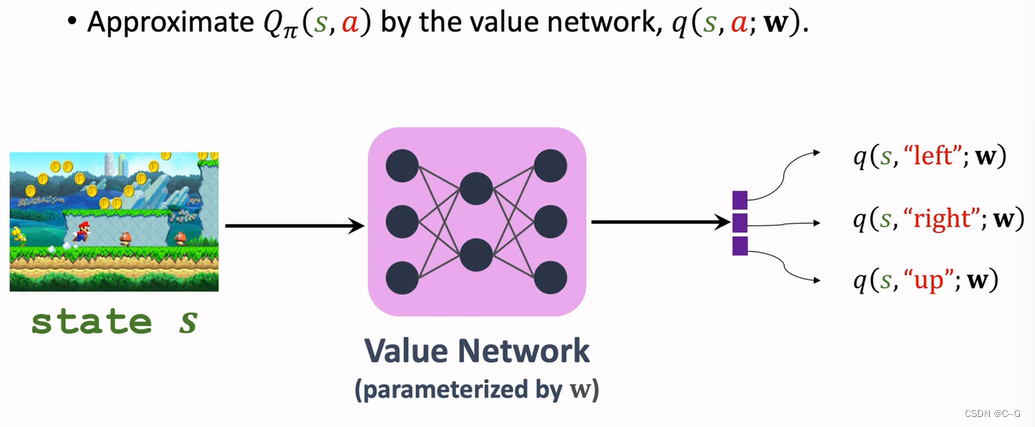
TD算法,用来学习动作价值函数QΠ
Sarsa:Tabular Version


Sarsa’s Name

表格状态的Sarsa适用于状态和动作较少,随着状态和动作的增大,表格增大就很难学习
Sarsa:Neural Network Version



Q-Learning
TD算法,学习最优动作算法
Sarsa与Q-Learning


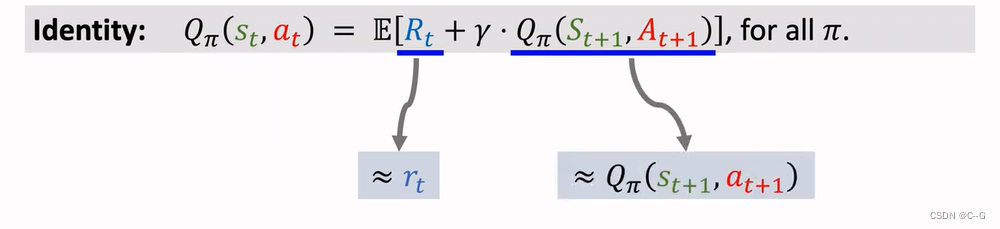
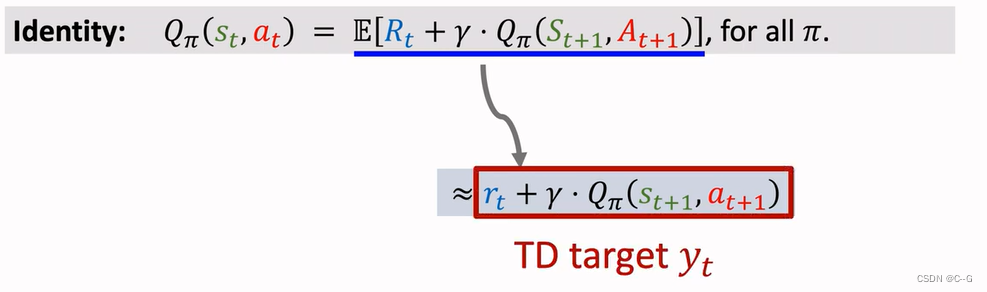
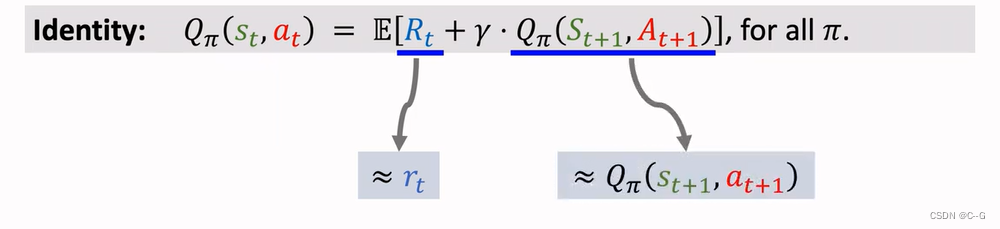
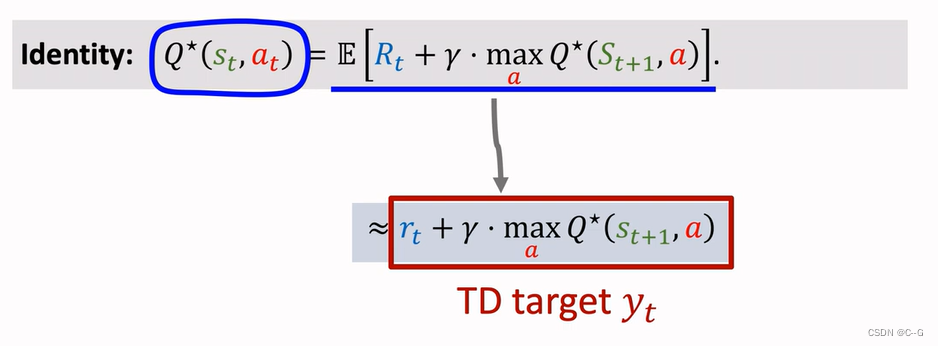
Derive TD Target


Q-Learning(tabular version)
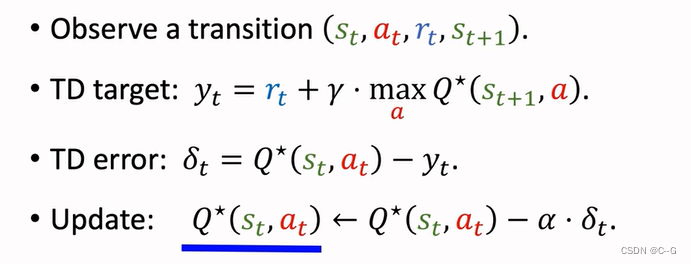
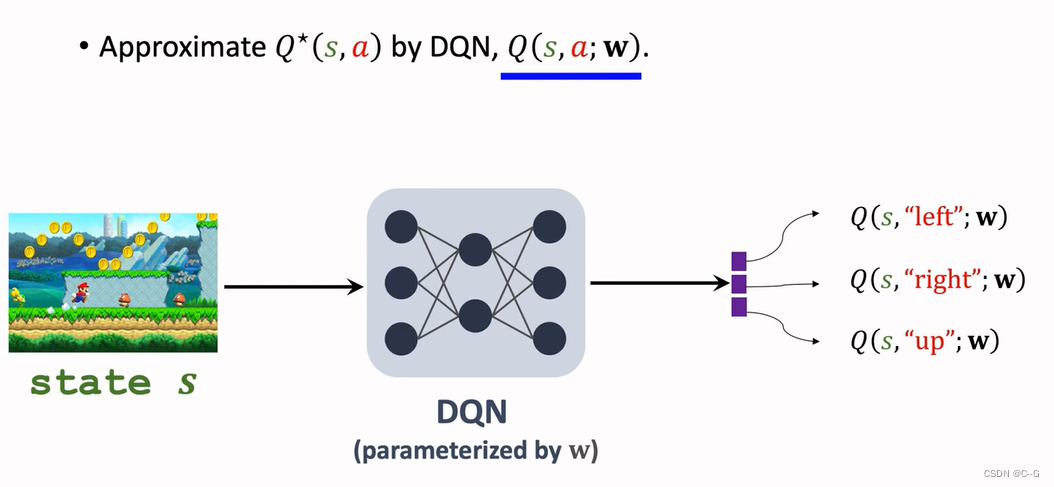
Q-Learning(DQN Version)

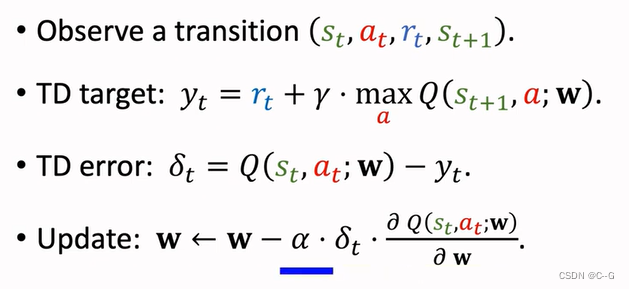

Multi-Setp TD Target
- Using One Reward

- Using Multiple Rewards

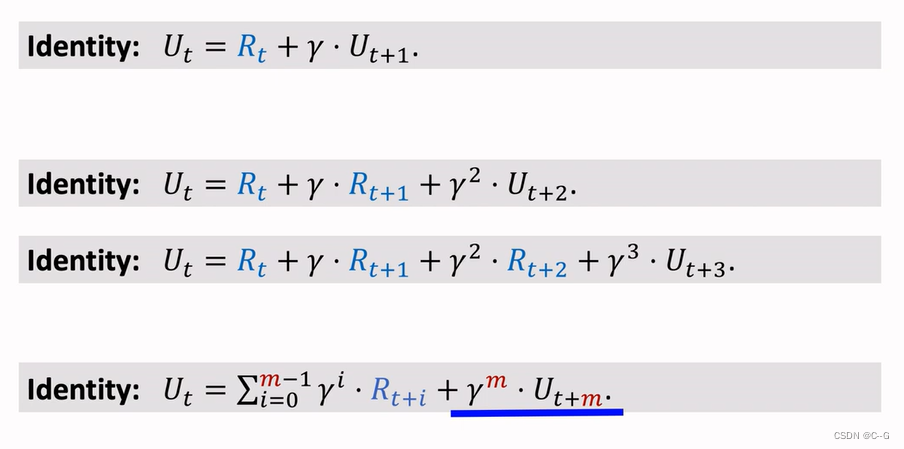



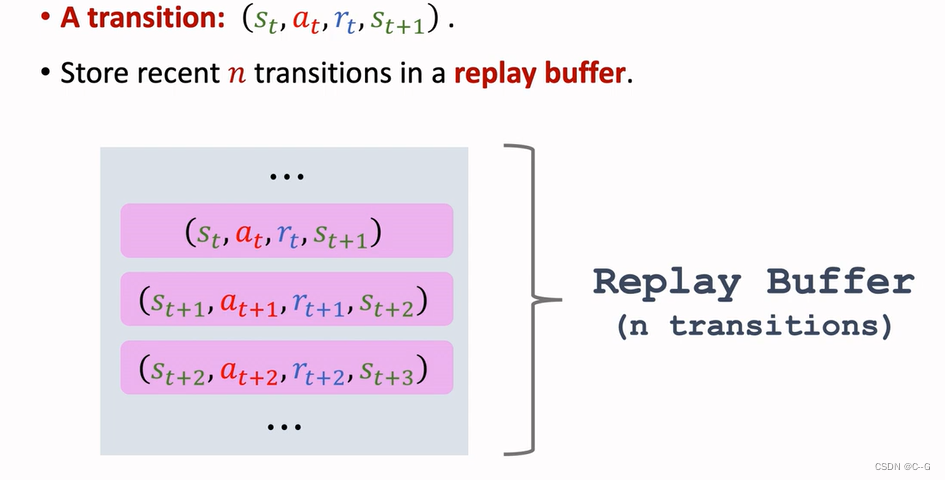
价值回放(Revisiting DQN and TD Learning)
- Shortcoming 1:Waste of Experience

- Shortcoming2:Correlated Updates

- 经验回放



- History

Prioritized Experience Replay



左边是马里奥常见场景,右边是boos关场景,相对于左边而言,右边更少见,因此要加大右边场景的权重,TD error越大,那么该场景就越重要


随机梯度下降的学习率应该根据抽样的重要性进行调整



一条样本的TD越大,那么抽样权重就越大,学习率就越小
高估问题
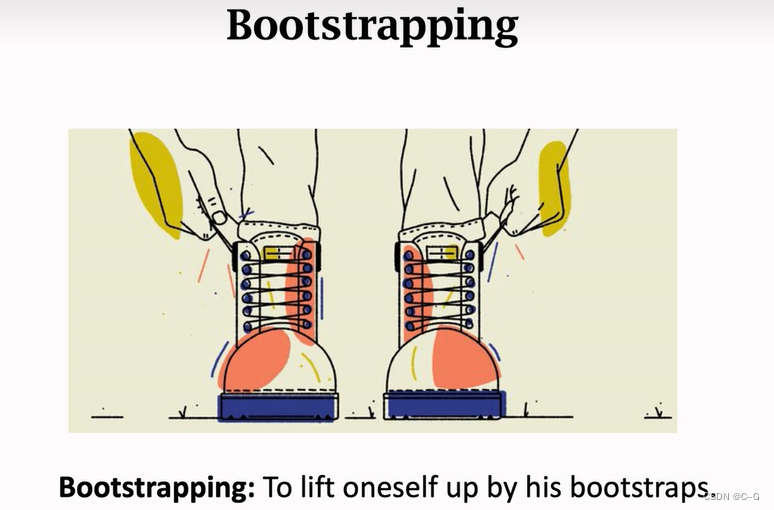
Bootstrapping:自举问题,拽自己的鞋子将自己提起来
类似左脚踩右脚上天方法,现实中是不存在,强化学习中存在


Problem of Overestimation

- Reason 1:Maximization


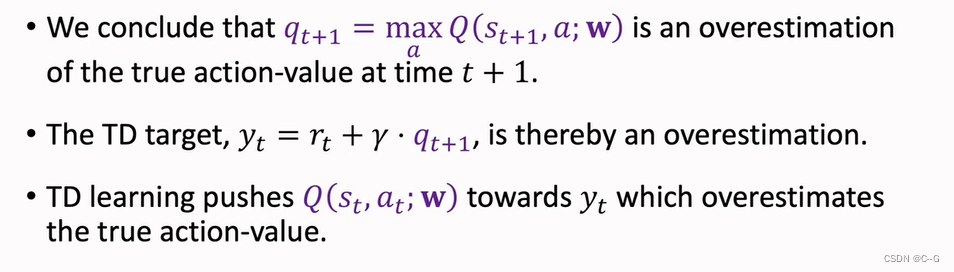
- Reason 2:Bootstrapping

- Why does overestimation happen
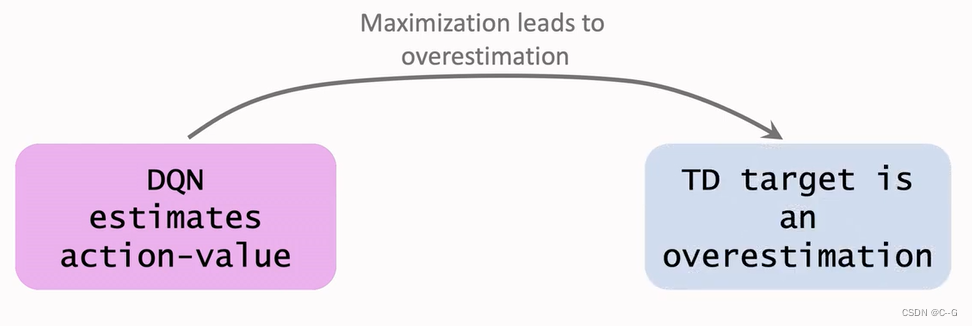

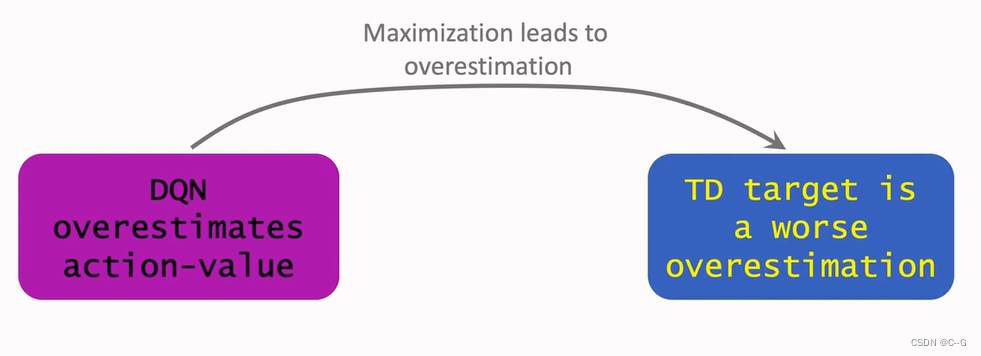

- Why overestimation is a shortcoming
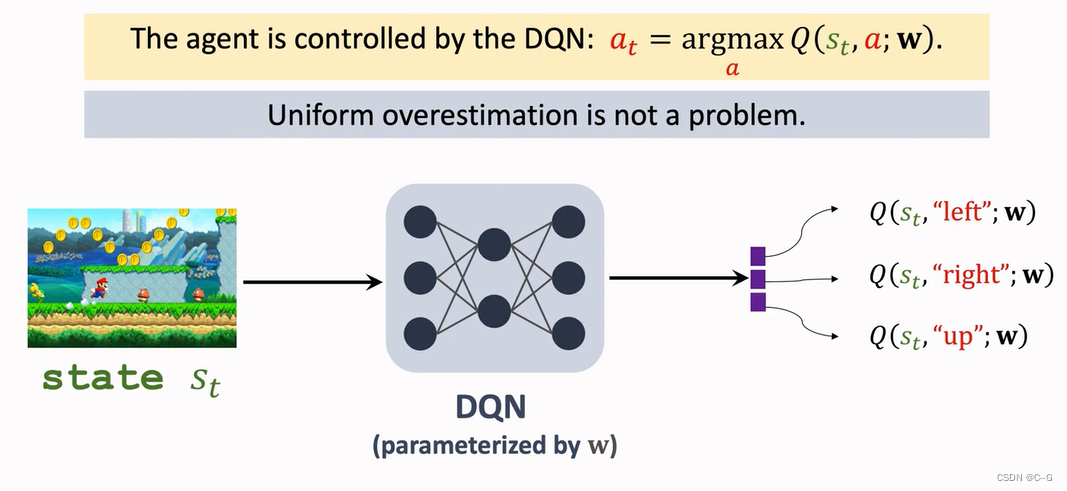



- Solutions

Target Network

TD Learning with Target Network
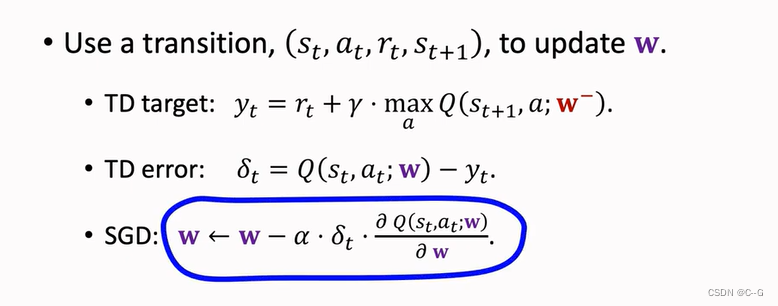
Update Target Network
Comparisons

Target Network虽然好了一点,但仍然无法摆脱高估问题
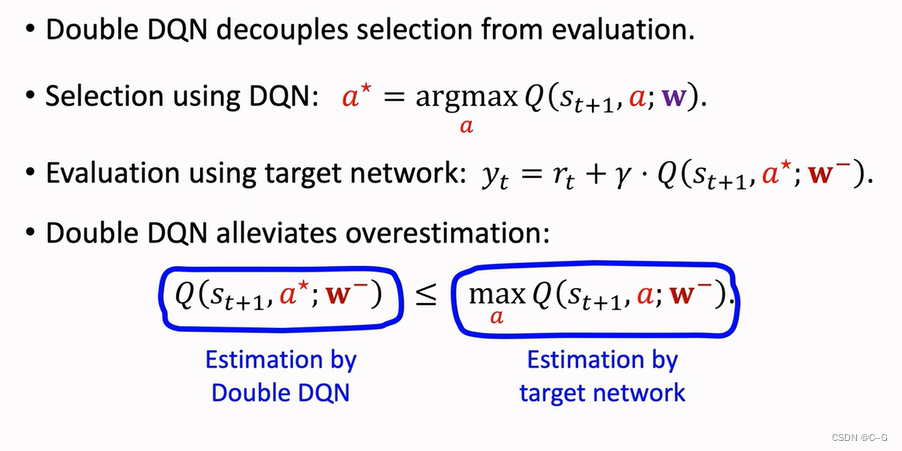
Double DQN
-
Naive Update

-
Using Target Network

-
Double DQN

-
Why does Double DQN work better
Dueling Network
Advantage Function(优势函数)
-
Value Functions

-
Optimal Value Functions

Properties of Advantage Function


Dueling Network

Revisiting DQN
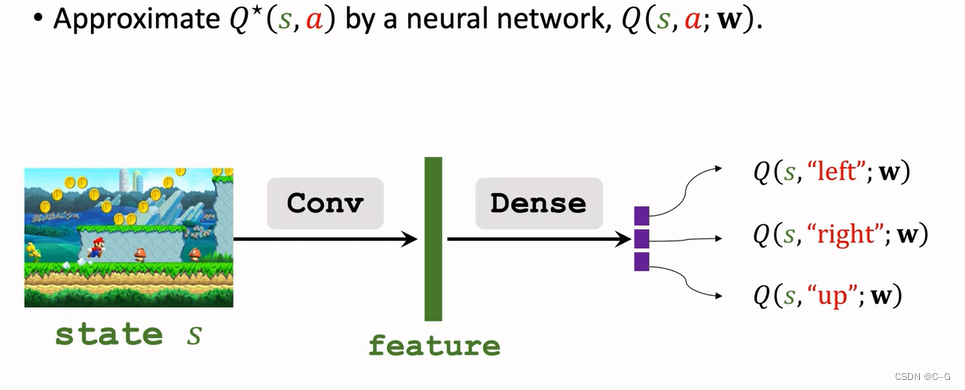
Approximating Advantage Function

Approximating State-Value Function
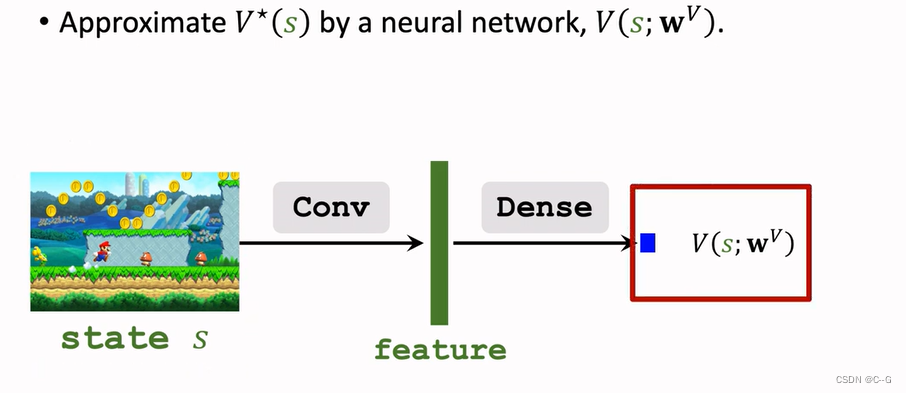
Dueling Network:Formulation

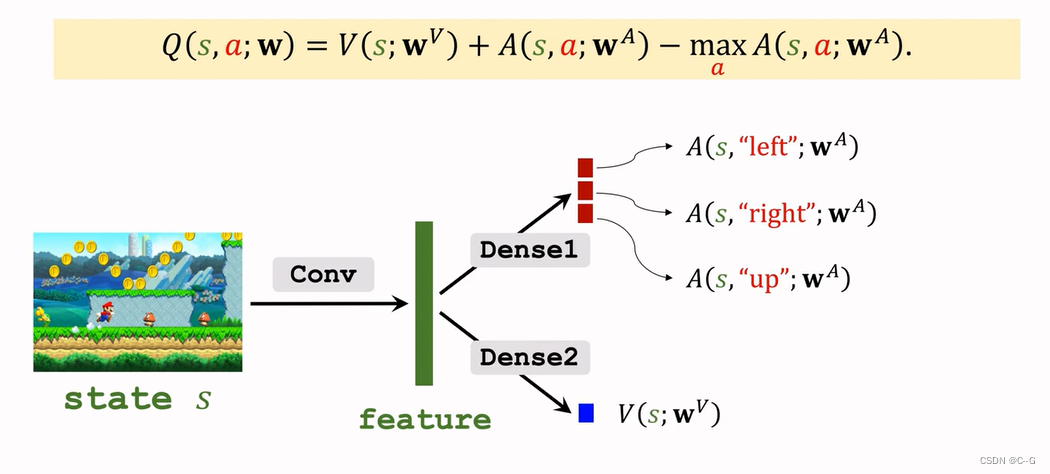
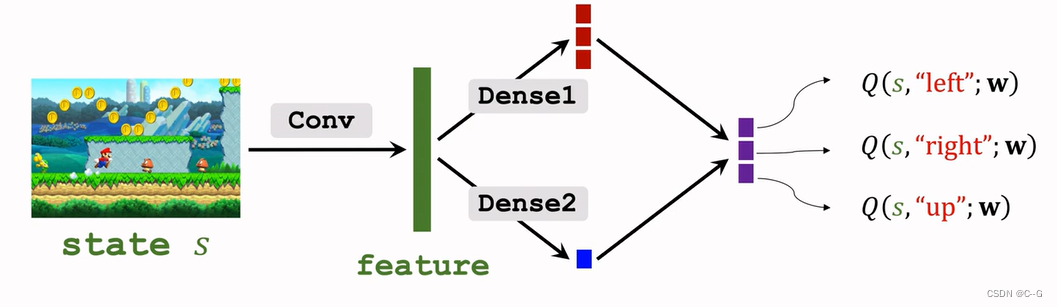
蓝色加上红色再减去红色的最大值就得到紫色最后Dueling Network输出

Problem of Non-identifiability



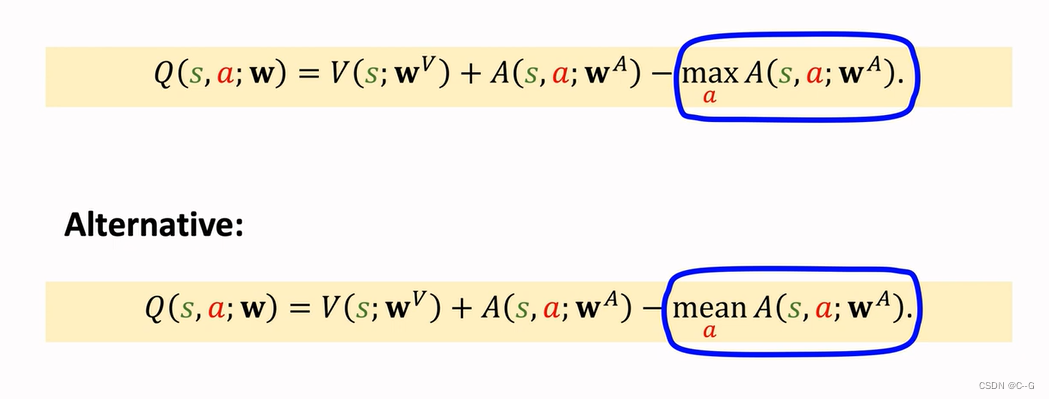














 2556
2556











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









