







 Huffman编码是一种基于概率的数据压缩方法,通过构建优先级树来为符号分配变长编码。平均码长计算涉及字符概率和编码长度的乘积。然而,Huffman编码存在局限,如编码长度为整数,输入符号数限制,译码复杂度,需预先知道概率分布且无错误保护功能。
Huffman编码是一种基于概率的数据压缩方法,通过构建优先级树来为符号分配变长编码。平均码长计算涉及字符概率和编码长度的乘积。然而,Huffman编码存在局限,如编码长度为整数,输入符号数限制,译码复杂度,需预先知道概率分布且无错误保护功能。
计算:已知信源符号及其概率,试求其
Huffman
编码及平均码长。
首先,需要知道Huffman
编码及平均码长的概念。
在讲数据压缩的时候会提到一种编码方式,
Huffman
编码。
Huffman
编码
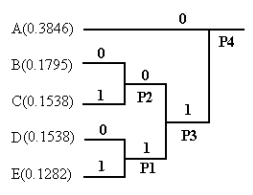
1、初始化,根据符号概率的大小按
由大到小
顺序对符号进行排序。
2、把
概率最小
的两个符号组成一个节点,如下图中的D和E 组成节点P1。
3、重复步骤2,得到节点P2、P3和P4,形成一棵“树”,其中的P4称为根节点。
注意:为了统一编码,通常当两节点的概率大小不相同时,编码概率大的为0,概率小的为1;当两节点的概率相同时,编码上0下1.
平均码长计算公式:
如果采用单字符二进制编码方式,设字
符aj的编码长度为Lj,则信源字母表的
平均码长为:
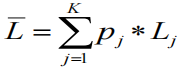 也就是字符概率和字符编码长度的乘积和
也就是字符概率和字符编码长度的乘积和
例题:
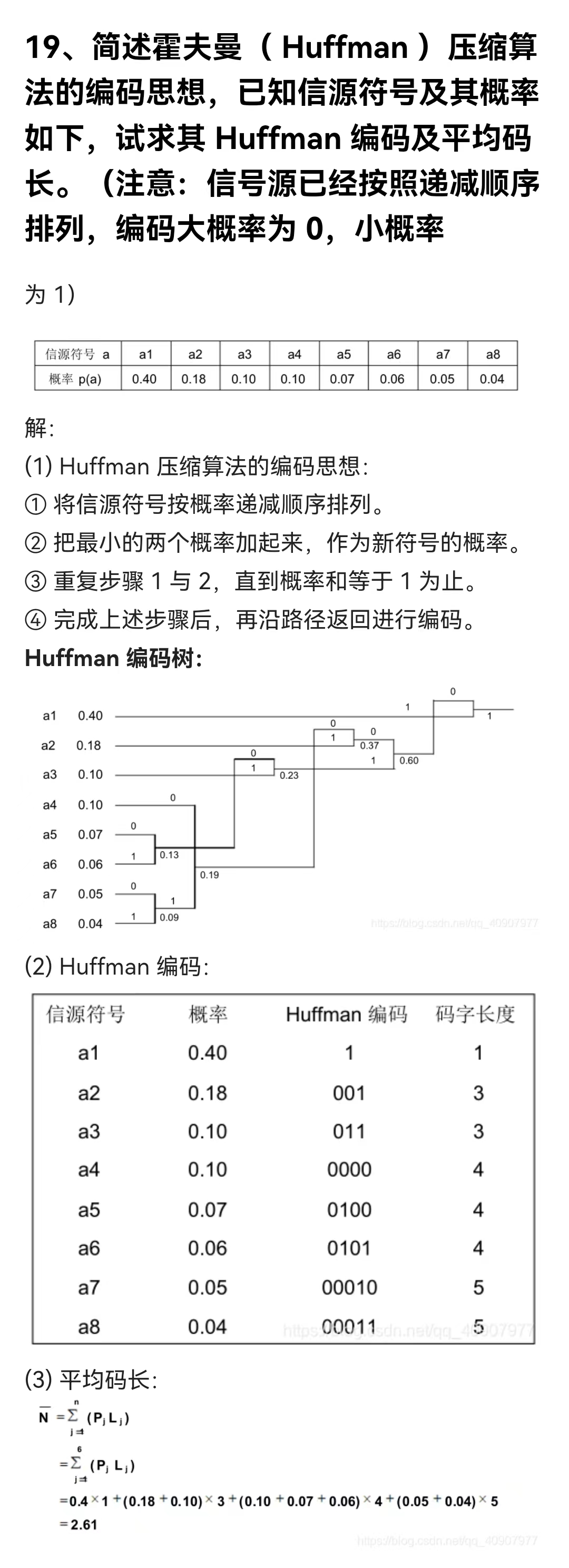
Huffman
编码的局限性:
利用霍夫曼编码,每个符号的编码长度只能为整数,所以如果源符号集的概率分布不是2负n次方的形式,则无法达到熵极限。
输入符号数受限于可实现的码表尺寸
译码复杂
需要实现知道输入符号集的概率分布
没有错误保护功能
更多例题可以参考:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









