







目录
一、项目介绍
今天的项目是Kaggle的另一个经典新手项目House Prices Prediction,通过所给数据预测房价。项目网站链接:www.kaggle.com/competitions/house-prices-advanced-regression-techniques
以下是项目的背景介绍:

再浏览所给样本数据,如图:
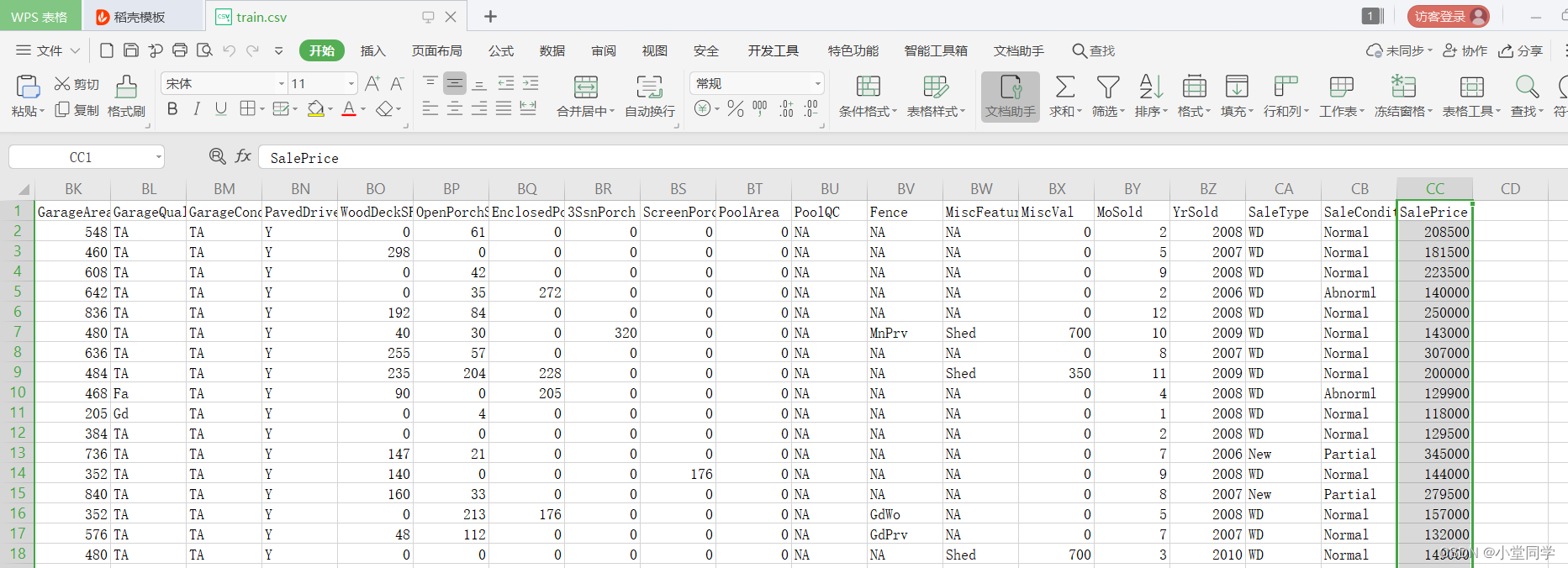
在train.csv数据中,给出了每个房子的几十个属性的数据并给出了房子的价格数据SalePrice。需要我们以这些数据为基础,去寻找这些属性数据与房价之间的关系,并完成对test.csv中所给的数据进行房价预测。
二、项目分析
首先我们需要确切的计算出每个房子的价格,所以这是一个典型的回归问题,选择的回归模型主要是以下几种:
# 随机森林回归模型(Random Forest)
# 支持向量回归机模型(SVR)
# 神经网络回归模型(MLP)
# K邻近回归模型(K-Neighbors)
在确定好算法模型之后,首先对数据进行预处理,给了几十个属性数据,显然不能都用,用pandas的相关性分析API进行相关性分析,代码如下:
# 计算各组数据间的相关性
corr_data = train_df.corr()
# 提取对房屋价格的相关性
saleP_corr = corr_data['SalePrice']将相关性可视化如图所示:
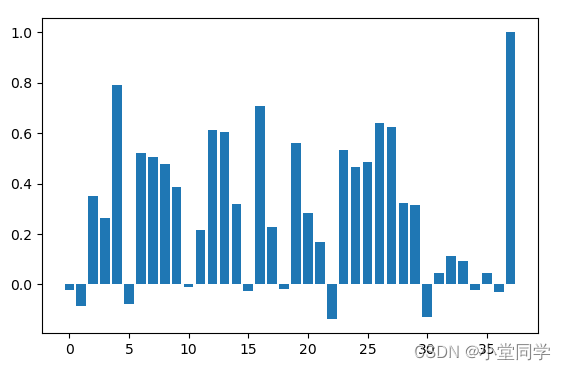
根据相关性的高低选择房价的影响因子:OverallQual(0.790982)、YearBuilt(0.522897)、TotalBsmtSF(0.613581)、1stFlrSF(0.605852),GrLivArea(0.708624)、FullBath(0.560664)、TotRmsAbvGrd(0.533723)、GarageCars(0.640409),GarageArea(0.623431)。
随后便进行数据集的组建,代码如下:
# 构建训练数据集
data_len = len(train_df['OverallQual'])
feature_data = np.array(
pd.DataFrame(train_df,columns=['OverallQual','YearBuilt','TotalBsmtSF',
'1stFlrSF', 'GrLivArea','FullBath',
'TotRmsAbvGrd','GarageCars','GarageArea'])
)
# feature_data 即为训练数据
label_data = np.array(train_df['SalePrice'])
# label_data 数据为房价数据,即训练过程中的对照# 构建测试数据集
test_len = len(test_df['OverallQual'])
test_data = np.array(
pd.DataFrame(test_df,columns=['OverallQual','YearBuilt','TotalBsmtSF',
'1stFlrSF', 'GrLivArea','FullBath',
'TotRmsAbvGrd','GarageCars','GarageArea'])
)
# test_data即为测试数据集在进行数据集组建后就可以进行模型构建,选择scikit-learn库进行模型搭建,轻便好用。
from sklearn.ensemble import RandomForestRegressor
from sklearn.svm import SVR
from sklearn.neural_network import MLPRegressor
from sklearn.neighbors import KNeighborsRegressor三、项目实现
四种算法最后的结果对比图如下:
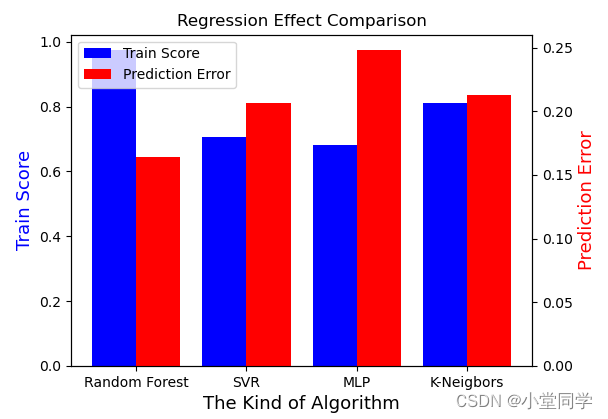
# 蓝色为模型训练得分,红色为预测误差。
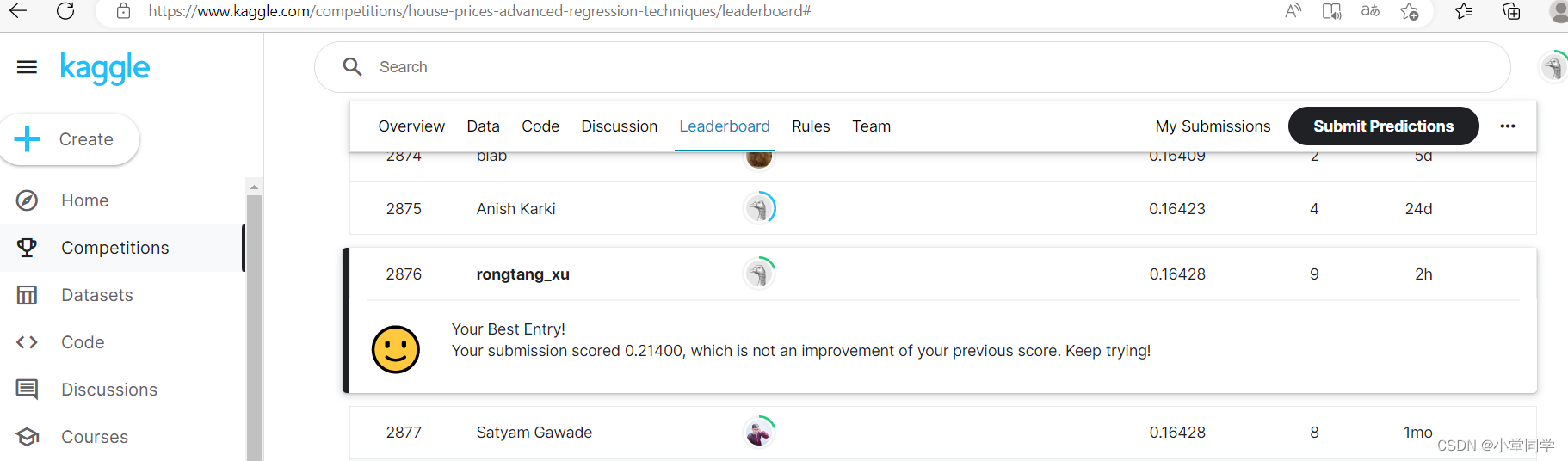
最好的预测分数为0.16428,在Kaggle排名2876/4839,对于一个新手没垫底不错了hhh。
整个项目代码如下:
# 房价预测项目
import sys
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.ensemble import RandomForestRegressor
from sklearn.svm import SVR
from sklearn.neural_network import MLPRegressor
from sklearn.neighbors import KNeighborsRegressor
# 设置文件路径,读取文件
train_path = "train.csv"
test_path = "test.csv"
train_df = pd.read_csv(train_path)
test_df = pd.read_csv(test_path)
# 计算各组数据间的相关性
corr_data = train_df.corr()
# 提取对房屋价格的相关性
saleP_corr = corr_data['SalePrice']
# print(saleP_corr)
# 选择标签:OverallQual(0.790982)、YearBuilt(0.522897)、TotalBsmtSF(0.613581)、1stFlrSF(0.605852)
# GrLivArea(0.708624)、FullBath(0.560664)、TotRmsAbvGrd(0.533723)、GarageCars(0.640409)
# GarageArea(0.623431)
# 构建训练数据集
data_len = len(train_df['OverallQual'])
feature_data = np.array(
pd.DataFrame(train_df,columns=['OverallQual','YearBuilt','TotalBsmtSF',
'1stFlrSF', 'GrLivArea','FullBath',
'TotRmsAbvGrd','GarageCars','GarageArea'])
)
# feature_data 即为训练数据
label_data = np.array(train_df['SalePrice'])
# label_data 数据为房价数据,即训练过程中的对照
# print("train_in",feature_data.shape)
# print("train_out",label_data.shape)
# 构建测试数据集
test_len = len(test_df['OverallQual'])
test_data = np.array(
pd.DataFrame(test_df,columns=['OverallQual','YearBuilt','TotalBsmtSF',
'1stFlrSF', 'GrLivArea','FullBath',
'TotRmsAbvGrd','GarageCars','GarageArea'])
)
# test_data即为测试数据集
test_dataframe = pd.DataFrame(test_data)
test_dataframe = test_dataframe.fillna(test_dataframe.mean()) # 均值填充空值
test_data = np.array(test_dataframe)
# print("test_in",test_data.shape)
# 开始进行预测
# 首先选择使用随机森林回归模型
model = RandomForestRegressor(n_estimators=100)
model.fit(feature_data,label_data)
print("随机森林回归模型训练得分:",model.score(feature_data,label_data))
PricePrediction = np.array(model.predict(test_data))
ID = test_df['Id']
# ID = np.array(ID).reshape(test_len,1)
PricePrediction = pd.Series(PricePrediction,name="SalePrice")
submission = pd.concat([ID,PricePrediction],axis=1)
submission.to_csv("RFR_prediction.csv",index=False)
# 提交kaggle误差为0.16428 #
# 支持向量回归机SVR #
model_SVR = SVR(kernel='linear')
# kernel={‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’}
model_SVR.fit(feature_data,label_data)
print("支持向量回归机模型训练得分:",model_SVR.score(feature_data,label_data))
svr_prediction = np.array(model_SVR.predict(test_data))
svr_prediction = pd.Series(svr_prediction,name="SalePrice")
svr_submission = pd.concat([ID,svr_prediction],axis=1)
svr_submission.to_csv("SVR_prediction.csv",index=False)
# 提交kaggle误差为0.20672 #
# 使用神经网络进行回归 #
MLP_model = MLPRegressor(hidden_layer_sizes=100,max_iter=2000)
# hidden_layer_sizes 隐含层数。max_iter 最大迭代次数
MLP_model.fit(feature_data,label_data)
print("神经网络模型训练得分为:",MLP_model.score(feature_data,label_data))
MLP_prediction = np.array(MLP_model.predict(test_data))
MLP_prediction = pd.Series(MLP_prediction,name="SalePrice")
MLP_submission = pd.concat([ID,MLP_prediction],axis=1)
MLP_submission.to_csv("MLP_prediction.csv",index=False)
# 提交kaggle误差为0.24787 #
# 使用最近邻回归算法进行回归 #
KN_model = KNeighborsRegressor(n_neighbors=5)
# 实验结果:n_neighbors越小得分越高?
KN_model.fit(feature_data,label_data)
print("K最近邻算法模型训练得分为:",KN_model.score(feature_data,label_data))
KN_prediction = np.array(KN_model.predict(test_data))
KN_prediction = pd.Series(KN_prediction,name="SalePrice")
KN_submission = pd.concat([ID,KN_prediction],axis=1)
KN_submission.to_csv("KN_prediction.csv",index=False)
# 提交kaggle误差为0.21275 #
# 绘图
data1 = [0.974,0.707,0.682,0.812]
data2 = [0.16428,0.20672,0.24787,0.21275]
label = ["Random Forest","SVR","MLP","K-Neigbors"]
x = range(4)
fig,ax1 = plt.subplots()
width = 0.4
f1 = ax1.bar(x,data1,width=width,label='Train Score',fc='b')
ax2 = ax1.twinx()
f2 = ax2.bar([i+width for i in x],data2,width=width,label='Prediction Error',fc='r')
# 设置坐标轴标签
ax1.set_xlabel("The Kind of Algorithm",fontsize=13)
ax1.set_ylabel("Train Score",fontsize=13)
ax2.set_ylabel("Prediction Error",fontsize=13)
# 设置颜色
ax1.yaxis.label.set_color(f1[0].get_facecolor())
ax2.yaxis.label.set_color(f2[0].get_facecolor())
# 设置x轴点
ax1.set_xticks([i+width/2 for i in x],label)
# 设置标题
plt.title("Regression Effect Comparison")
plt.legend(handles = [f1,f2])
plt.show()
敬请批评指正!
共勉!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









