







DeepAnt论文如下,其主要是用于时间序列的无监督粗差探测。

其提出的模型架构如下:
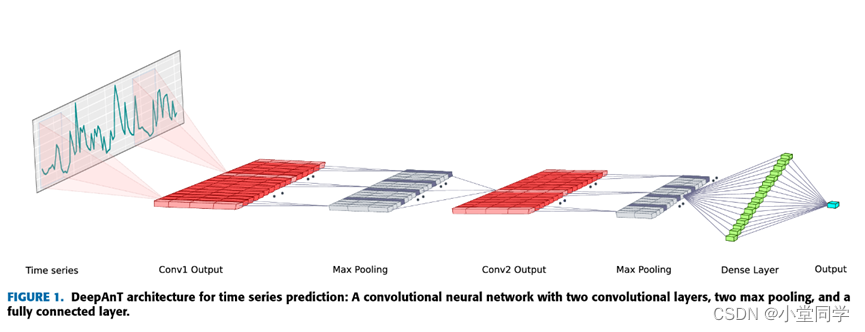
该文提出了一个无监督的时间序列粗差探测模型,其主要有预测模块和探测模块组成,其中预测模块的网络结构如下。
预测结构是将时间序列数据组织成数据集之后经过两次的卷积和最大池化,最后将卷积结果通过一个全连接层转换为一个输出数据(若是单步预测则输出单元个数为1)
探测模块是将模型的时序预测结果与该时刻的观测数据相比来计算欧氏距离,以此来作为当前时间点距离的异常分数。以此来作为数据粗差探测的标准。
(本博客主要是分享复现代码,论文中的细节原理可自行下载学习)
复现代码(数据不便分享):
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset,DataLoader,TensorDataset
from sklearn.preprocessing import MinMaxScaler,StandardScaler
def MSE(arr1,arr2):
arr1,arr2 = np.array(arr1).flatten(),np.array(arr2).flatten()
assert arr1.shape[0] == arr2.shape[0]
return np.sum(np.power(arr1-arr2,2)) / arr1.shape[0]
def MAE(arr1,arr2):
arr1,arr2 = np.array(arr1).flatten(),np.array(arr2).flatten()
assert arr1.shape[0] == arr2.shape[0]
return np.sum(np.abs(arr1-arr2)) / arr1.shape[0]
class MyData(Dataset):
def __init__(self,arr,history_window,predict_len) -> None:
self.length = arr.flatten().shape[0]
self.history_window = history_window
self.dataset_x,self.dataset_y = self.get_dataset(arr,history_window,predict_len)
def get_dataset(self,arr,history_window,predict_len):
arr = np.array(arr).flatten()
N = history_window
M = predict_len
dataset_x = np.zeros((arr.shape[0] - N,N))
dataset_y = np.zeros((arr.shape[0] - N,M))
for i in range(arr.shape[0] - N):
dataset_x[i] = arr[i:i+N]
dataset_y[i] = arr[i+N:i+N+M]
dataset_x = torch.from_numpy(dataset_x).to(torch.float)
dataset_y = torch.from_numpy(dataset_y).to(torch.float)
return (dataset_x,dataset_y)
def __getitem__(self, index): # 定义方法 data[i] 的返回值
return (self.dataset_x[index,:],self.dataset_y[index,:])
def __len__(self): # 获取数据集样本个数
return self.length - self.history_window
class DeepAnt(nn.Module):
def __init__(self,lag,p_w):
super().__init__()
self.convblock1 = nn.Sequential(
nn.Conv1d(in_channels=1, out_channels=32, kernel_size=3, padding='valid'),
nn.ReLU(inplace=True),
nn.MaxPool1d(kernel_size=2)
)
self.convblock2 = nn.Sequential(
nn.Conv1d(in_channels=32, out_channels=32, kernel_size=3, padding='valid'),
nn.ReLU(inplace=True),
nn.MaxPool1d(kernel_size=2)
)
self.flatten = nn.Flatten()
self.denseblock = nn.Sequential(
nn.Linear(32, 40), # for lag = 10
#nn.Linear(96, 40), # for lag = 20
#nn.Linear(192, 40), # for lag = 30
nn.ReLU(inplace=True),
nn.Dropout(p=0.25),
)
self.out = nn.Linear(40, p_w)
def forward(self, x):
x = x.view(-1,1,lag)
x = self.convblock1(x)
x = self.convblock2(x)
x = self.flatten(x)
x = self.denseblock(x)
x = self.out(x)
return x
def Train(model,data_set,EPOCH,task_id):
if torch.cuda.is_available():
device = torch.device('cuda')
print('cuda is used...')
else:
torch.device('cpu')
print('cpu is used...')
scale = StandardScaler()
loss_fn = nn.MSELoss()
model.to(device)
loss_fn.to(device)
train_x,train_y = data_set.dataset_x,data_set.dataset_y
train_x = scale.fit_transform(train_x)
train_x = torch.from_numpy(train_x).to(torch.float).to(device)
train_y = train_y.to(device).to(torch.float)
torch_dataset = TensorDataset(train_x,train_y)
optimizer = torch.optim.Adam(model.parameters())
BATCH_SIZE = 100
model = model.train()
train_loss = []
print('======Start training...=======')
print(f'Epoch is {EPOCH}\ntrain_x shape is {train_x.shape}\nBATCH_SIZE is {BATCH_SIZE}')
for i in range(EPOCH):
loader = DataLoader(dataset=torch_dataset,
batch_size=BATCH_SIZE,
shuffle=True)
temp_1 = []
for step,(batch_x,batch_y) in enumerate(loader):
out = model(batch_x)
optimizer.zero_grad()
loss = loss_fn(out,batch_y)
temp_1.append(loss.item())
loss.backward()
optimizer.step()
torch.cuda.empty_cache()
train_loss.append(np.mean(np.array(temp_1)))
if i % 10 == 0:
print(f"The {i}/{EPOCH} is end, loss is {np.round(np.mean(np.array(temp_1)),6)}.")
print('========Training end...=======')
model = model.eval()
plt.plot(train_loss)
pred = model(train_x).cpu().data.numpy()
print(f'pred shape {pred.shape}')
plt.figure()
y = train_y.cpu().data.numpy().flatten()
print(f'y shape {y.shape}')
plt.plot(y,c='b',label='True')
plt.plot(pred,'r',label='pred')
plt.legend()
plt.title('Train_result')
plt.show()
return pred
if __name__ == "__main__":
data_f = pd.read_csv('HF05_processed.csv')
data = np.array(pd.DataFrame(data_f)['OT'])
lag = 10
dataset = MyData(data,lag,1)
model = DeepAnt(lag,1)
res = Train(model,dataset,200,'1')
data = data[lag:].flatten()
plt.plot(data)
plt.plot(res,c='r')
err = data - res.flatten()
anomaly_score = np.sqrt(np.power(err,2))
plt.figure()
plt.plot(anomaly_score)
error_list = []
threshold = 0.04
for i in range(anomaly_score.shape[0]):
if anomaly_score[i] > threshold:
error_list.append(i)
print(len(error_list))
plt.figure()
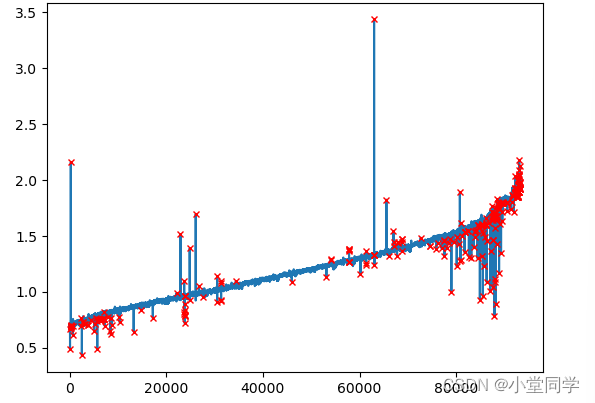
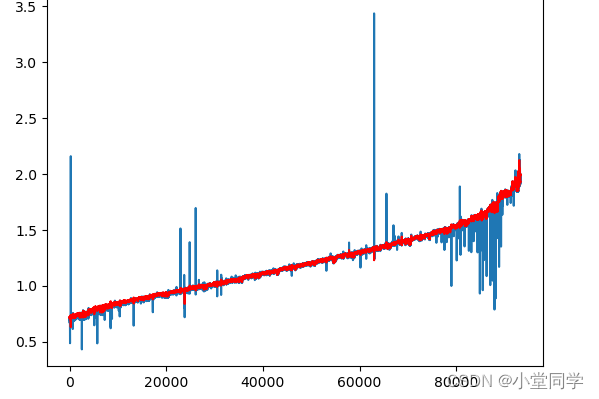
plt.plot(data)
plt.plot(error_list,[data[i] for i in error_list],ls='',marker='x',c='r',markersize=4)
plt.show()运行结果:
才疏学浅,敬请指正!
欢迎交流:
邮箱:rton.xu@qq.com
QQ:2264787072


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









