







一、什么是专家混合模型
专家混合模型(MoE)是一种强大的神经网络架构,能够通过多个专家模型(Experts)和一个门控网络(Gating Network)来有效地处理复杂的任务。MoE的核心思想是根据输入样本的特征动态地选择最合适的专家模型,然后整合这些专家的输出,从而在保证计算效率的同时提升模型的性能。
这种模型在自然语言处理、推荐系统、医疗预测等领域得到了广泛应用,尤其是在大型深度学习模型中,像GPT-4和DeepSeekMoE等新一代大语言模型也采用了MoE架构,从而大大提升了其计算效率和预测精度。
想象你在一个很大的公司工作,这个公司有很多部门(这些部门就是“专家”)。每个部门都有不同的专长,比如一个部门专门处理财务,一个部门专门做市场营销,还有一个部门专门做技术开发。
现在,当你有一个问题要解决(比如一个任务或者一个数据输入),你可以去找公司里最合适的部门来处理你的问题。为了让事情更高效,公司的“门卫”会根据你的问题(这就像输入的特征)判断,哪个部门最适合解决你的问题,并把任务交给那个部门。门卫的作用就像“门控网络”,它决定了哪些部门被调用。
这样,你就不需要每次都让所有部门都忙碌起来,只需要调用最合适的部门来解决问题,这样既能保证高效,又能确保结果更准确。
在一些超级复杂的任务里,像处理大量的文本或数据时(比如GPT-4那样的大型语言模型),专家混合模型就像这种“大公司”,根据问题的不同,动态地调配不同的专家来解决问题,这样既能节省资源,也能提高解决问题的精度。
二、MoE的基本工作原理
2.1 MoE的基本架构包括两大核心部分:
-
专家网络(Experts): 这些专家是由多个独立的模型组成,每个专家擅长处理某一类特定的数据或任务。例如,一个专家可能专注于处理某种类型的输入数据,而另一个专家可能专注于不同类型的任务。专家可以是简单的线性模型,也可以是复杂的神经网络。
-
门控网络(Gating Network): 门控网络是MoE的控制中心,负责根据输入样本选择适当的专家进行处理。具体来说,门控网络会根据输入数据计算出每个专家的“权重”或“概率”,这些权重决定了哪些专家将参与计算以及如何组合各专家的输出。
在传统的神经网络中,所有的节点在每一层都参与计算,但MoE通过让每次计算仅由少数几个专家完成,极大提高了计算效率。这种按需激活部分专家的方式,使得MoE在处理大规模数据时表现出色。
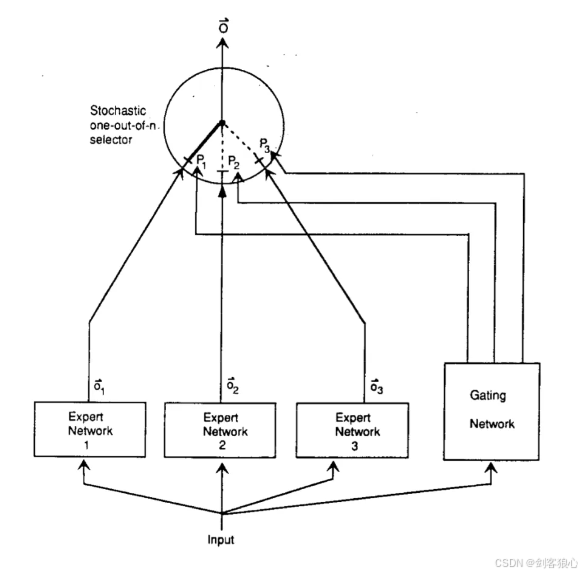
理解一下这个专家混合模型(MoE)的架构:
-
专家网络:这些是多个神经网络,每个专家负责处理输入数据并产生输出。所有专家的输入是一样的,它们的输出数量也一样。可以把这些专家想象成不同的“部门”,每个部门负责解决问题的一部分。
-
门控网络(Gating Network):这个网络的作用是决定哪个专家应该处理给定的任务。门控网络也是一个前
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











