




 ISODATA聚类算法基于K均值,但增加了聚类合并和分裂操作,能够自动调整类别数。文章介绍了K均值算法的基本步骤和优缺点,随后详细阐述了ISODATA算法的流程,包括初始化、合并和分裂规则,并讨论了算法的优缺点,如参数设置的敏感性。
ISODATA聚类算法基于K均值,但增加了聚类合并和分裂操作,能够自动调整类别数。文章介绍了K均值算法的基本步骤和优缺点,随后详细阐述了ISODATA算法的流程,包括初始化、合并和分裂规则,并讨论了算法的优缺点,如参数设置的敏感性。
文章目录
ISODATA聚类算法
一、 K均值算法
ISODATA算法是在k-均值算法的基础上,增加对聚类结果的“合并”和“分裂”两个操作
1、K均值算法概述
k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法
2、K均值算法步骤
步骤一:
预将数据分为K组,则随机选取K个对象作为初始的聚类中心。
步骤二:
计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。
可以根据实际需要选择一种距离作为相似性度量,其中最常用的是欧氏距离:X中的样本用d个描述属性A1,A2…Ad来表示,并且d个描述属性都是连续型属性。数据样本xi=(xi1,xi2,…xid), xj=(xj1,xj2,…xjd)其中,xi1,xi2,…xid和xj1,xj2,…xjd分别是样本xi和xj对应d个描述属性A1,A2,…Ad的具体取值。样本xi和xj之间的相似度通常用它们之间的距离d(xi,xj)来表示,距离越小,样本xi和xj越相似,差异度越小;距离越大,样本xi和xj越不相似,差异度越大。
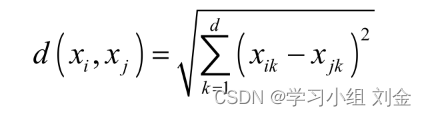
步骤三:
每分配一个样本,聚类的聚类中心会根据聚类中现有的对象被重新计算。
各个聚类子集的均值代表点(也称聚类中心)分别为m1,m2,…,mk。
步骤四:
上述过程将不断重复直到满
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 833
833

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









