






写爬虫好难...头发掉了好几把...好在最后终于算是懂了个大概...吧。
在这里以NBA中国官方网站为例。
1.首先是对目标网站的分析过程:
打开NBA网站,单击右键查看网页源代码。会跳出这样一个页面:

看上去很恶心,但往下拖,认真看,找想爬的文章。比如我想爬这一些看起来就方方整整的标题和文章:

那具体怎么操作呢?
这些文章的标题都在一系列标签之间,对我们爬虫爬取文章有影响的标签从内到外分别是<a></a>,<li></li>,<ul></ul>三种。那我们就从这里找出了待会要写的代码的循环层数是三层。
爬虫不可缺少的除了标题,还有内容和时间,还可以带上来源使文章更具说服力。因此,我想还从网页源代码里找到这些东西,那就抓一篇文章来分析它的时间、来源和内容在源代码里是怎么表示的。
就让我点开《单月85记三分创史 库里:我是当世最强射手》这篇文章,可以一眼看到时间和来源就在标题下面。先把它复制下来。

查看这一页面的源代码,在键盘上按Ctrl+F,将刚刚复制的时间和来源分别输入,以时间为例:

有两个结果,另一个显然是作为文本输出的就不用管它。找到这个有标签的,那么此后时间都将从”span.article-time"找了。先记下这个class。来源和内容的查找也是同理。这就是大致的目标网站分析。
2、爬虫整体结构,使用的工具包:
不太会讲,先丢爬虫代码吧,也就是我写的爬取NBA网站的爬虫整体结构:
'use strict';
var cheerio = require('cheerio');
var fs = require('fs');
var request = require('request');
var iconv = require('iconv-lite');
var Title = [];
var Source = [];
var Time = [];
var Content = [];
var Url = [];
request({url: "https://china.nba.com/", encoding: null, headers: null }, function(err, res, body){
if(err || res.statusCode !=200){
console.error(err);
console.error(res.statusCode);
return;
}
let $ = cheerio.load(iconv.decode(body, 'gbk'));
let cnt = 0;
let ulArr = $("ul.text-news").eq(cnt);
while(ulArr.text()){
let cnt1 = 0;
let liArr = ulArr.children("li").eq(cnt1);
while(liArr.text()){
let cnt2 = 0;
let aArr = liArr.children("a").eq(cnt2);
while(aArr.text()){
let urlstr = aArr.attr("href");
let title = aArr.text();
if(urlstr && title){
console.log(`${title}`);
request({ url: urlstr, encoding: null, headers: null }, function (err,res,body){
if(err || res.statusCode != 200){
console.error(err);
console.error(res.statusCode);
return;
}
let $ = cheerio.load(iconv.decode(body, 'gbk'));
Title.push($("title").text());
Time.push($("span.article-time").text());
Source.push($("span.color-a-1").text());
Content.push($("div#Cnt-Main-Article-QQ").text());
Url.push(res.request.uri.href);
console.log(`${$("title").text()}`)
});
}
cnt2++;
aArr = liArr.children("a").eq(cnt2);
}
cnt1++;
liArr = ulArr.children("li").eq(cnt1);
}
cnt++;
ulArr = $("ul.text-news").eq(cnt);
}
});
setTimeout(function(){
for(let i in Url){
fs.writeFileSync("NBA/" + i + ".txt", `URL: ${Url[i]}\nTitle: ${Title[i]}\nSource: ${Source[i]}\nContent: ${Content[i]}\nTime: ${Time[i]}`);
}
},5000);以下是使用的工具包,要爬之前要把这四个都npm install一遍:
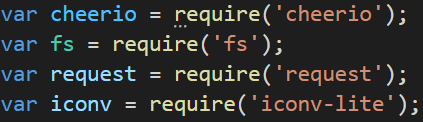
这是定义的数组,为了储存爬到的数据:
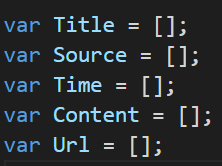
这是判断能不能爬或爬的网站对不对的请求操作,对就进去,不对返回:

这是个报错版块:
![]()
接下来就是本爬虫最核心的部分,其实也是三大循环,回到前面看,会发现其实这就是之前讲到的三个标签<ul><li><a>:
let cnt = 0;
let ulArr = $("ul.text-news").eq(cnt);
while(ulArr.text()){
let cnt1 = 0;
let liArr = ulArr.children("li").eq(cnt1);
while(liArr.text()){
let cnt2 = 0;
let aArr = liArr.children("a").eq(cnt2);
while(aArr.text()){
let urlstr = aArr.attr("href");
let title = aArr.text();
if(urlstr && title){
console.log(`${title}`);
request({ url: urlstr, encoding: null, headers: null }, function (err,res,body){
if(err || res.statusCode != 200){
console.error(err);
console.error(res.statusCode);
return;
}
let $ = cheerio.load(iconv.decode(body, 'gbk'));
Title.push($("title").text());
Time.push($("span.article-time").text());
Source.push($("span.color-a-1").text());
Content.push($("div#Cnt-Main-Article-QQ").text());
Url.push(res.request.uri.href);
console.log(`${$("title").text()}`)
});
}
cnt2++;
aArr = liArr.children("a").eq(cnt2);
}
cnt1++;
liArr = ulArr.children("li").eq(cnt1);
}
cnt++;
ulArr = $("ul.text-news").eq(cnt);
}
});循环的大概意思是找到第cnt个<ul class="text-news">存在ulArr里,class用.替换。
如果ulArr的文本里是有东西的,我们就将进下一层循环。
找到第cnt1个ulArr的子标签<li>存为liArr。
如果liArr的文本里有东西,我们又进下一层。
找到第cnt2个liArr的子标签<a>存为aArr后就不能再进循环了,进二级页面,将需要一个网址。
![]()
href就是我要的网址,下面的语句会自行把网址导入爬虫:
![]()
最后一段是爬虫爬取结果的输出,我将爬取内容存到了叫NBA的文件中:

其实对于三层循环的爬虫来说,整个框架中白色部分的内容基本是不变的,要改的内容几乎就是显示绿色的东西,通过修改它们可以爬一些普通的你想要爬的不同网址不同文章。
大概就是这些了,我可能讲不太清楚,剩下的自求多福吧...
2.数据库设计:
由于对mysql ptsd了,将爬取内容存入数据库我用的是另一个软件,长这样:
进去后要新建表,预备把你要爬的东西存进去。一顿操作后,我弄了一个叫news的表要存数据,右键点击“设计表”,把我们要的几项如URL,Title,Time,Content,Source都打进去,还要修改表的各项属性,此处太多就不一一截图了。
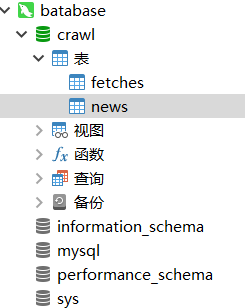

表弄好之后,接下来就要把VScode里的爬取内容导入表中。我们要修改一下之前的代码,因为之前的代码是把爬取内容存进文件夹的,现在要让它们入库。以下是修改过的代码:
'use strict'; var cheerio = require('cheerio'); var fs = require('fs'); var request = require('request'); var iconv = require('iconv-lite'); var database = require('./mysql.js'); var Title = []; var Source = []; var Time = []; var Content = []; var Url = []; request({url: "https://china.nba.com/", encoding: null, headers: null }, function(err, res, body){ if(err || res.statusCode !=200){ console.error(err); console.error(res.statusCode); return; } let $ = cheerio.load(iconv.decode(body, 'gbk')); let cnt = 0; let ulArr = $("ul.text-news").eq(cnt); while(ulArr.text()){ let cnt1 = 0; let liArr = ulArr.children("li").eq(cnt1); while(liArr.text()){ let cnt2 = 0; let aArr = liArr.children("a").eq(cnt2); while(aArr.text()){ let urlstr = aArr.attr("href"); let title = aArr.text(); if(urlstr && title){ console.log(`爬取${title}`); request({ url: urlstr, encoding: null, headers: null }, function (err,res,body){ if(err || res.statusCode != 200){ console.error(err); console.error(res.statusCode); return; } let $ = cheerio.load(iconv.decode(body, 'gbk')); database.query('INSERT INTO news(URL, Title, Time, Content, Source) VALUES(?, ?, ?, ?, ?);', [ res.request.uri.href, $("title").text(), $("span.article-time").text(), $("div#Cnt-Main-Article-QQ").text(), $("span.color-a-1").text() ], function (err, vals, fields) { if (err) { console.error(`数据库错误:${err}`); } console.log(`完成爬取${$("title").text()}`); }); }); } cnt2++; aArr = liArr.children("a").eq(cnt2); } cnt1++; liArr = ulArr.children("li").eq(cnt1); } cnt++; ulArr = $("ul.text-news").eq(cnt); } });其实也就是中间的输出部分做了些调整,其他大致上一样。运行成功后,爬取数据就被写入数据库了。以下是写入数据库的效果:

3.搜索网站前后端:
为了搜索爬取内容的关键字,还要建一个搜索网站,先展示一下我设计的搜索网站:

要设计这样一个网站需要写前后端。前段设计搜索网站的显示方式,也就是通过写前端告诉电脑你想要的搜索网站要长什么样。我通过HTML写,以下是我的代码(index.html):
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=1900">
<title>查询NBA网页具体信息</title>
</head>
<body background="NBA1.jpg"
style="background-repeat:no-repeat;
background-size:100% 100%;
filter:alpha(opacity=10);
background-attachment:fixed;">
<form action="/" method="GET">
<p style="background-color:rgba(146, 127, 127, 0.5);">请输入关键词 <input name="kw" type="text" style="width: 640px" /><input type="submit" value="Search" /></p>
</form>
<table border="1" id="news">
<caption style="font-size: 24px;font-weight:700">News</caption>
<tr>
<th>Title</th>
<th>Time</th>
<th>Content</th>
<th>Source</th>
</tr>
</table>
</body>
</html>单写前端还不够,还要写后端将要呈现的内容连接到前端去。后端还是通过js写(serve1.js):
'use strict';
var express = require('express');
var cheerio = require('cheerio');
var fs = require('fs');
var database = require('./mysql.js');
var port = process.env.PORT || 1337;
var server = express();
server.use(express.static("public"));
server.get('/', function (req, res) {
res.writeHead(200, { 'Content-Type': 'text/html' });
let AdditionSQL = "";
var html = fs.readFileSync("index.html");
let $ = cheerio.load(html);
if (req.query.kw) {
AdditionSQL = ` WHERE (Title LIKE '%${req.query.kw}%') OR (Content LIKE '%${req.query.kw}%')`;
}
database.query_noparam('SELECT * FROM news' + AdditionSQL + ';', function(qerr, vals, fields) {
if (qerr) {
console.error(qerr);
return;
}
for (let i in vals) {
$('table#news').append(`<tr>
<td><a href=${vals[i].URL}>${vals[i].Title}</ a></td>
<td>${vals[i].Time}</td>
<td>${vals[i].Content}</td>
<td>${vals[i].Source}</td>
</tr>`);
}
res.end($.html());
});
});
server.listen(port);运行serve1.js文件,在浏览器搜索框输入127.0.0.1:1337,就会跳出刚刚我们设计的搜索网站,实现爬虫爬取内容的搜索。
总的爬虫大概就是这样。















 50
50











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









