







 本文详细解读了MySQLInnoDB引擎的COMPACT行存储格式,包括变长字段长度列表的逆序存储、NULL值列表的二进制位图表示、记录头信息以及其设计背后的性能考量。作者通过实例和原理分析,展示了如何在存储效率和性能间取得平衡。
本文详细解读了MySQLInnoDB引擎的COMPACT行存储格式,包括变长字段长度列表的逆序存储、NULL值列表的二进制位图表示、记录头信息以及其设计背后的性能考量。作者通过实例和原理分析,展示了如何在存储效率和性能间取得平衡。
文章目录
前言
MySQL中InnoDB引擎存储数据有四种行存储格式,今天我们来谈谈Compact,是MySQL5.X版本中默认的也是最常用的一种存储格式。
1 InnoDB 储存引擎的行储存格式概述
InnoDB存储引擎在MySQL中支持四种行存储格式,它们分别是:
-
Compact(紧凑格式):Compact是InnoDB的默认行存储格式,也是最常用的格式。它以高效的方式存储行数据,包括NULL值列表的位图压缩和变长数据的前缀压缩。Compact格式在存储空间和性能之间取得了一个平衡。
-
Redundant(冗余格式):Redundant格式在存储行数据时不使用位图压缩,而是将每个列的NULL状态作为一个单独的字节存储。这种格式适用于具有大量NULL值的表,但在存储空间方面相对较高。MySQL5.0以前的上古行存储格式。
-
Dynamic(动态格式):Dynamic格式在存储行数据时使用可变长度的记录格式,它可以更好地处理可变长度的列(如VARCHAR)。Dynamic格式也使用了位图压缩来表示NULL值列表,但相对于Compact格式,它的存储效率更高。
-
Compressed(压缩格式):Compressed格式是InnoDB 页级压缩的一部分,它使用了压缩算法来减少行数据的存储空间。这种格式适用于对存储空间非常敏感的场景,但在处理压缩数据时会增加一些CPU开销。
MySQL5.0之前:Redundant行存储式
MySQL5.1——MySQL5.7:Compact行存储式
MySQL5.7之后:Dymatic行存储式
Dynamic 和 Compressed 两个都是紧凑的行格式,它们的行格式都和 Compact 差不多,因为都是基于 Compact 改进一点东西,这里我暂且不提及,有兴趣可以自行去学习。
这四种行存储格式各自有不同的特点和适用场景。选择适当的行存储格式取决于表的特性、数据访问模式以及对存储空间和性能的需求。
在创建表时,可以使用ROW_FORMAT子句来指定所需的行存储格式。例如,ROW_FORMAT=COMPACT可以用于指定紧凑格式。
2 COMPACT 行格式
2.1 COMPACT简略图
 一条完整的记录分为【记录的额外信息】和【记录的真实数据】两个部分。
一条完整的记录分为【记录的额外信息】和【记录的真实数据】两个部分。
2.1.1 记录的额外信息
记录的额外信息包含三个部分:变长字段长度列表,Null值列表,记录头信息。我们可以用数据传输过程中,报文前的头结点去相似的看待COMPACT 行格式中记录的额外信息。
(一)变长字段长度列表
变长字段长度列表,顾名思义就是保存字段中变长字段长度的一段信息,下面我们来建一个表。
CREATE TABLE `student` (
`id` int(11) NOT NULL,
`name` VARCHAR(20) DEFAULT NULL,
`phone` VARCHAR(20) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB DEFAULT CHARACTER SET = ascii ROW_FORMAT = COMPACT;
# MySQL5.x的版本中InnoDB引擎默认为COMPACT行格式,因此此处可要可不要。如果你是其他版本,建议保留。
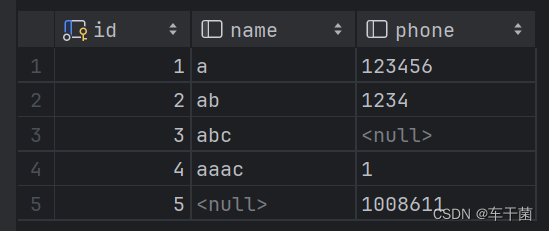
先来看第一条数据id为1的相关内容:
- id:主键,不是变长字段,不用管。
- name:值为‘a’,占用1个字节。
- phone:值为‘123456’,占用6字节。
他的变长字段长度列表会按照逆序存储,所以【变长字段长度列表】中存放的数据应该是【06 01】而不是【01 06】。
同理第二条【变长字段长度列表】中存放的数据应该是【04 02】,
第三条【变长字段长度列表】中存放的数据应该是【02】,
第四条【变长字段长度列表】中存放的数据应该是【01 04】,
第五条【变长字段长度列表】中存放的数据应该是【07】。
为什么要逆序存储
在MySQL中,存储引擎在处理变长数据列时通常会使用逆序排放的方式。这种逆序排放的设计选择是为了提高性能和效率,特别是在需要读取数据列的长度信息时。
-
快速定位长度信息:通过将长度信息放置在最后一个数据块,MySQL可以通过直接读取最后一个数据块来获取变长数据列的长度。这样可以避免在读取长度信息之前扫描和解析其他数据块,从而提高访问速度。
-
减少寻址次数:当数据列的长度信息放置在第一个数据块时,为了读取长度信息,需要先读取第一个数据块,然后跳转到最后一个数据块来读取实际的数据。而逆序排放的方式可以减少寻址次数,只需要读取最后一个数据块即可。
-
提高顺序读取效率:在许多应用场景中,对数据列的顺序读取是最常见的操作。通过逆序排放数据块,MySQL可以更加高效地进行顺序读取,因为每次读取后续数据块时,磁盘的读取头位置已经靠近下一个数据块的位置,减少了磁盘寻址的开销。
需要注意的是,这种逆序排放的方式可能会对随机访问或在特定情况下的性能产生影响。因此,在设计存储结构时,需要根据具体的应用需求和访问模式进行权衡和优化。
聪明的朋友们可能会问了:我们家三号子涵的【变长字段长度列表】为什么是【02】,五号子涵的【变长字段长度列表】为什么是【07】呢,麻烦工程师不要对我们家子涵不平等对待!
你先别急,听我说,我下面就要讲这个了
(二)Null值列表
字节一面:MySQL 是怎么存储 NULL 的?
遇到这个问题怎么看,还记得吗,我之前说过:
记录的额外信息包含三个部分:变长字段长度列表,Null值列表,记录头信息。我们可以用数据传输过程中,报文前的头结点去相似的看待COMPACT行格式中记录的额外信息。
经常学计算机网络的朋友们应该都知道,杀人容易抛尸难 发送容易接收难,什么TCP/IP啊,五层七层OSI模型啊,路由啊,协议啊,三握四挥啊,加密解密啊,公钥私钥啊,那些我们现在都不提。我们知道数据传输中他不是完全所有东西打个包丢垃圾一样的丢出去对吧,那就是网络攻防了。
在数据传输中,数据是通过一段一段的报文进行传输的,通过报文的头尾节点进行设置:目标服务器,路由协议,是否加密,该报文处于当前报文的第几部分,收到以后如何拼接。
这里我们就和计算机网络大相庭径,我们会在COMPACT行存储格式的记录的额外信息中的Null值列表进行配置,并且和计算机网络非常相似,采取整数个字节的二进制位图进行表示,不足补0。
还是这一张表
我们可以看到在id为3时phone为null,而在id为5时,name为null。根据我们了解到的二进制位图表示【Null值列表】,不难推断:id为3的【Null值列表】应该为|0|0|0|0|0|0|1|0|,那么为什么是10不是00呢,因为和前面【变长字段长度列表】相对应,需要逆序存储。注意此时的 ‘ | ’ 是我自己添加方便观察的,实际上应该是00000010,在COMPACT 行格式中表示应转换成16进制。
①为什么要逆序存储
在MySQL中,存储引擎在处理变长数据列时通常会使用逆序排放的方式。这种逆序排放的设计选择是为了提高性能和效率,特别是在需要读取数据列的长度信息时。
快速定位长度信息:通过将长度信息放置在最后一个数据块,MySQL可以通过直接读取最后一个数据块来获取变长数据列的长度。这样可以避免在读取长度信息之前扫描和解析其他数据块,从而提高访问速度。
减少寻址次数:当数据列的长度信息放置在第一个数据块时,为了读取长度信息,需要先读取第一个数据块,然后跳转到最后一个数据块来读取实际的数据。而逆序排放的方式可以减少寻址次数,只需要读取最后一个数据块即可。
提高顺序读取效率:在许多应用场景中,对数据列的顺序读取是最常见的操作。通过逆序排放数据块,MySQL可以更加高效地进行顺序读取,因为每次读取后续数据块时,磁盘的读取头位置已经靠近下一个数据块的位置,减少了磁盘寻址的开销。
需要注意的是,这种逆序排放的方式可能会对随机访问或在特定情况下的性能产生影响。因此,在设计存储结构时,需要根据具体的应用需求和访问模式进行权衡和优化。
同理,id为5的【Null值列表】应该为|0|0|0|0|0|0|0|1|,同样在COMPACT 行格式表示应转换成16进制。

(三)记录头信息
记录头的信息为40个bit位。
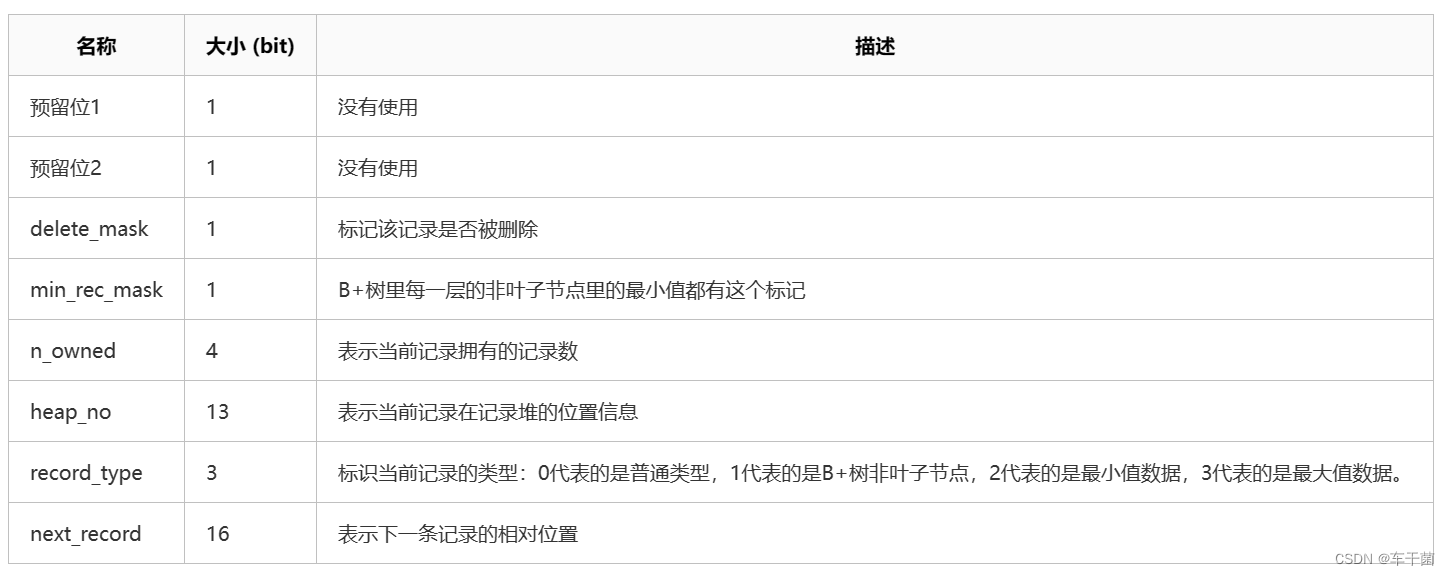
这一部分了解就行,我在这里不再赘述。
2.1.2 记录的真实数据
(一)row_id
如果没有定义主键或唯一约束,这个row_id就是MySQL自动给你生成的主键,不是必须字段,占6个字节。
(二)trx_id
事务id,必须字段,占6个字节,MVCC机制出现较多,不再赘述。
(三)roll_pointer
这条记录上一个版本的指针。必须字段,占7个字节,MVCC机制中非常重要的部分。
(四)数据库字段
这里就是你自己定义的数据库字段,没什么好说的,就你定义的‘id’,‘name’,‘phone’那些东西。
总结
我们再回头来看这个图,相信大家已经了解了什么是COMPACT行存储式,那么我们来回答一个问题,MySQL的null值到底是怎么存放的,他在存储中设定了null值列表,确认那个值为null,那他实际存的东西是什么,他的物理磁盘那个区域存的是什么东西?
结论
狠狠拷打chatGPT得出来的结果,网上基本上都没怎么讲清楚,截止到2024年1月4日15:47:14,小林coding和博客园没有具体的结论,因此我上穷碧落下黄泉找到了答案:
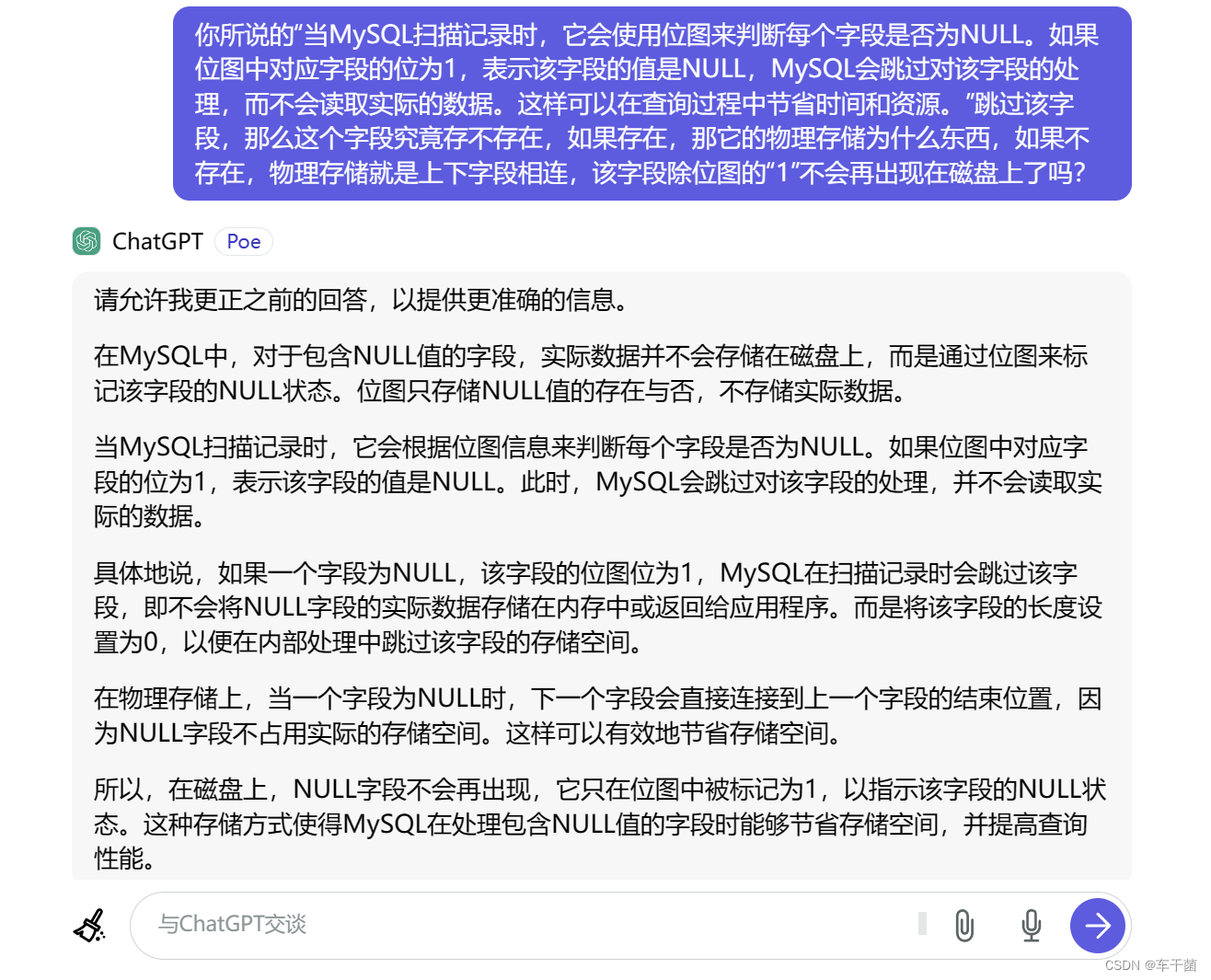
终于,我挽回了女神;大家基于互联网开源精神学到了知识;csdn收获了稍微有点价值的东西。
















 384
384











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











