







目录
1. Selenium的用途
在前面我们提到:在我们爬取网页没有得到实际的HTML内容时,会想到通过Ajax请求去寻找,寻找其请求链接的规律。但若是其请求链接接口规律不可寻怎么办?例如如下接口:

我们要爬取的页面的链接都是如此,难道一个个复制?这时候就需要我们的Selenium。
Selenium可以让程序直接模拟浏览器运行,然后爬取数据,可以实现在浏览器中所见即所爬。
要在pycharm中使用Selenium,需要安装Selenium库以及安装相应浏览器的driver。
2. 安装Selenium库
在Anaconda Prompt中conda install Selenium或者其他方法

3. 安装chromedriver
3.1. 查看谷歌版本号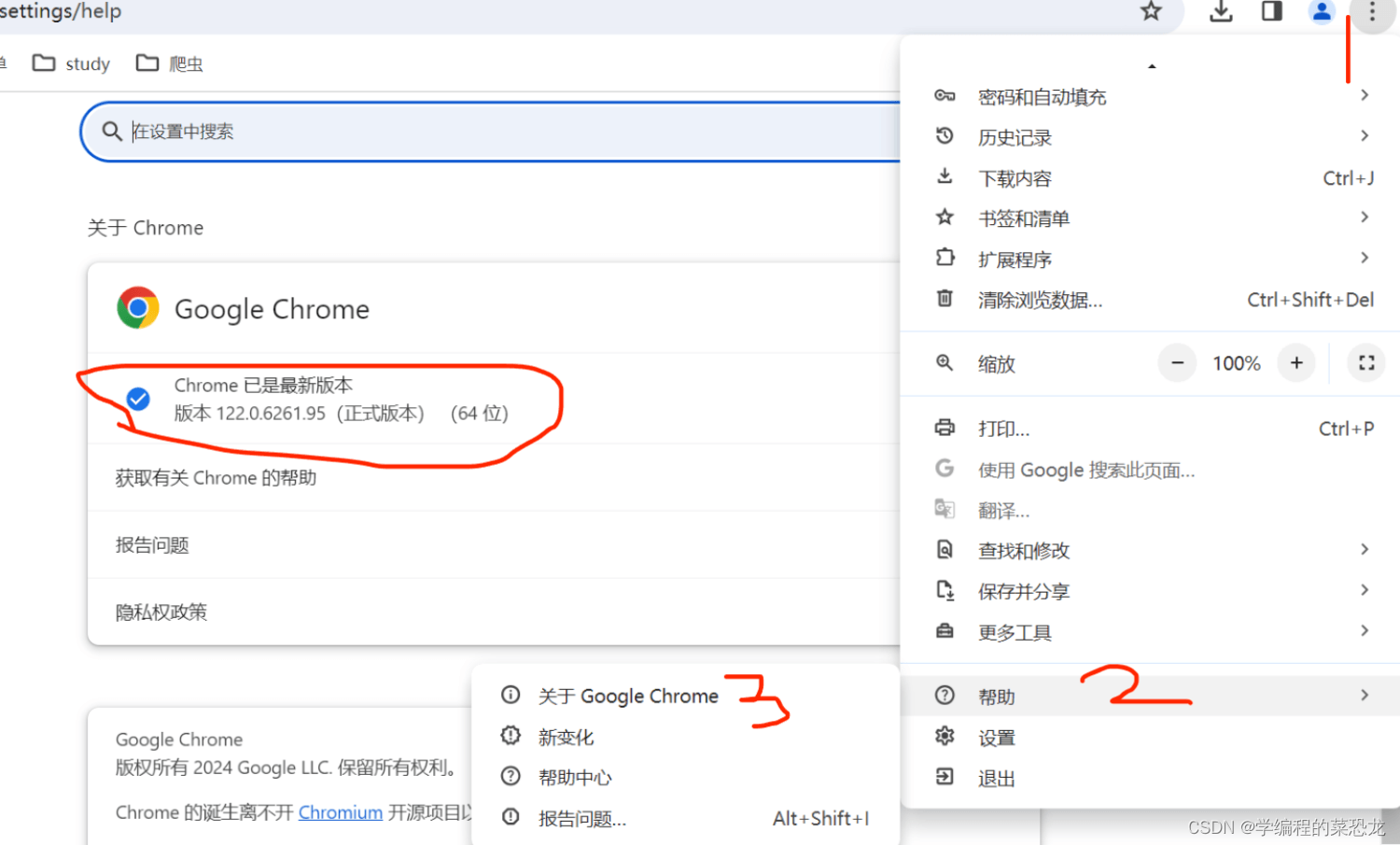
3.2. 找到最新版本及下载
在这个链接中找 Chrome for Testing availability(没有完全相同没关系,找最相近的)

这是与我最相近的版本。在浏览器里复制这个链接,就可以下载,下载到与chrome.exe同位置(该位置一般在下面我的图片差不多位置)

3.3. 配置环境变量
(1) 点击我的电脑/此电脑->右键点击属性->点击高级系统设置->环境变量->系统变量。
(2)点击系统变量中的path,点击新增,并将chromeDriver的安装目录复制填入后,点击确定,出来再点击确定。
例如我的安装目录(点击上面就可复制):

3.4. 检测是否配置成功
chromedriver
如果没成功,回到第二步,在那个链接中把第三个文件也下了,环境也配了。
3.5. 用python初始化浏览器对象检测:
from selenium import webdriver
browser = webdriver.Chrome()弹出以下页面,即可以开始后续操作。

3.6. 参考链接
本人新手,若有错误,欢迎指正;若有疑问,欢迎讨论。若文章对你有用,点个小赞鼓励一下,谢谢,一起加油吧!















 848
848

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









