






一、什么是机器学习
从定义上来说,机器学习是一种功能、方法,或者更具体的说是一种算法,它能够赋予机器进行学习的能力,从而使机器完成一些通过编程无法直接实现的功能。
从具体的实践意义来说,其实机器学习是利用大量数据训练出一个最优模型,然后再利用此模型预测出其他数据的一种方法。比如要识别猫、狗照片就要拿它们各自的照片提炼出相应的特征(比如耳朵、脸型、鼻子等),从而训练出一个具有预测能力的模型。
机器学习与人工智能、深度学习有什么关系呢?
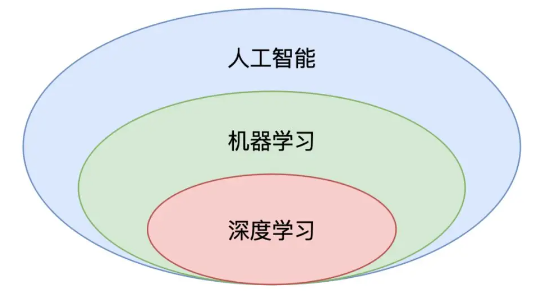
从图中可以看出,机器学习是人工智能的一部分,而深度学习又是机器学习的一部分。人工智能的范围最为广泛,机器学习是人工智能的核心分支,也是当前发展最迅猛的一部分。而关于深度学习,它之前也属于“机器学习”的一个分支,其主要研究对象是神经网络算法,因想要区别于“机器学习”,它重新起了一个高大上的名字:深度学习。
1.1 学习形式分类
- 有监督学习(supervised learning):
事先需要准备好要输入数据(训练样本)与真实的输出结果(参考答案),然后通过计算机的学习得到一个预测模型,再用已知的模型去预测未知的样本。 - 无监督学习(unsupervised learning):
在没有“参考答案”的前提下,计算机仅根据样本的特征或相关性,就能实现从样本数据中训练出相应的预测模型。 - 半监督学习
- 强化学习
1.2 预测结果分类
根据预测结果的类型,对上述学习形式做具体的问题划分。
- 有监督学习划分为:
①回归问题(预测结果是连续的,比如身高,从 1.2m 到 1.78m 这个长高的过程就是连续的)
②分类问题(预测结果是离散的,超市每天的销售额) - 无监督学习划分为:
聚类问题(将相似的样本聚合在一起后,然后进行分析)
二、机器学习常用术语
2.1 机器学习术语
- 模型:把它看做一个“魔法盒”,你向它许愿(输入数据),它就会帮你实现愿望(输出预测结果)
- 数据集:如果说“模型”是“魔法盒”的话,那么数据集就是负责给它充能的“能量电池”。数据集可划分为“训练集”和“测试集”,它们分别在机器学习的“训练阶段”和“预测输出阶段”起着重要的作用。
- 样本&特征:“一行一样本,一列一特征”
数据集中的数据,一条数据被称为“一个样本”;样本会包含多个特征值用来描述数据。

- 向量:在线性代数中,向量也称欧几里得向量、几何向量、矢量,指具有大小和方向的量。在机器学习中,模型算法的运算均基于线性代数运算法则,比如行列式、矩阵运算、线性方程等等。向量的计算可采用 NmuPy 来实现
- 矩阵:可以把矩阵看成由向量组成的二维数组,数据集就是以二维矩阵的形式存储数据的。
2.2 假设函数&损失函数
假设函数和损失函数是机器学习中的两个概念,“根据实际应用场景确定的一种函数形式”,就像解决数学的应用题目一样,根据题意写出解决问题的方程组。
- 假设函数:可表述为y=f(x),其中 x 表示输入数据,而 y 表示输出的预测结果
- 损失函数:又叫目标函数。简写为 L(x),这里的 x 是假设函数得出的预测结果“y”,如果 L(x) 的返回值越大就表示预测结果与实际偏差越大;越小则证明预测值越来越“逼近”真实值,这才是机器学习最终的目的。
- 优化方法:通过 损失函数L(x) 可以得知假设函数输出的预测结果与实际值的偏差值,当该值较大时就需要对其做出相应的调整,这个调整的过程叫做“参数优化”。如何实现优化呢?比如梯度下降法、牛顿法与拟牛顿法、共轭梯度法等等。
2.3 拟合&过拟合&欠拟合
-
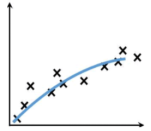
拟合:把平面坐标系中一系列散落的点,用一条光滑的曲线连接起来,因此拟合也被称为“曲线拟合”
-
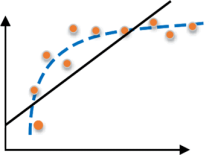
过拟合:在训练样本中表现优越,但是在验证数据以及测试数据集中表现不佳。比如你训练一个识别狗狗照片的模型,如果你只用金毛犬的照片训练,那么该模型就只吸纳了金毛狗的相关特征,此时让训练好的模型识别一只“泰迪犬”,那么结果可想而知,该模型会认为“泰迪”不是一条狗。

-
欠拟合:指的是“曲线”不能很好的“拟合”数据。在训练和测试阶段,欠拟合模型表现均较差,无法输出理想的预测结果。主要原因是由于没有选择好合适的特征值。
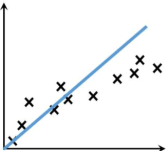
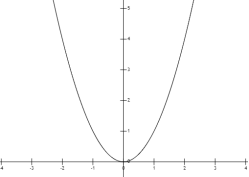
造成欠拟合的主要原因是由于没有选择好合适的特征值,比如使用一次函数(y=kx+b)去拟合具有对数特征的散落点(y=log2 x),示例图如下所示:
三、Python机器学习环境搭建
机器学习的研究方向有很多,比如图像识别、语音识别、自然语言处理、以及深度学习等,因此它是一门较为复杂的技术,有一定的“门槛”要求。如果你对编程知识一无所知,就想熟练应用机器学习,这几乎是天方夜谭。那么您应该掌握哪些知识才能更好地学习本教程呢?包括下列四大核心知识。
3.1 Python
在人工智能领域,由于 Python 语言的简洁性、易读性,以及 Python 对科学计算和深度学习框架(Tensorflow、Pytorch 等)的良好支持等,使得 Python 处于远远领先的位置。Python 学习参考:https://c.biancheng.net/python/
3.2 NumPy
NumPy(https://numpy.org/)属于 Python 的第三方扩展程序包,它是 Python 科学计算的基础库,提供了多维数组处理、线性代数、傅里叶变换、随机数生成等非常有用的数学工具。NumPy 学习参考:https://c.biancheng.net/numpy/
3.3 Pandas
Pandas 属于 Python 第三方数据处理库,它基于 NumPy 构建而来,主要用于数据的处理与分析。我们知道对于机器学习而言数据是尤为重要,如果没有数据就无法训练模型。Pandas 提供了一个简单高效的 DataFrame 对象(类似于电子表格),它能够完成数据的清洗、预处理以及数据可视化工作等。除此之外,Pandas 能够非常轻松地实现对任何文件格式的读写操作,比如 CSV 文件、json 文件、excel 文件。Pandas 学习参考:https://c.biancheng.net/pandas/
3.4 Scikit-Learn
Scikit-learn 简称 sklearn,它是一个基于 Python 语言的机器学习算法库。Scikit-Learn 主要用 Python 语言开发,建立在 NumPy、Scipy 与 Matplotlib 之上。
Scikit-Leran官网:https://scikit-learn.org/stable/
它提供了大量机器学习算法接口(API),因此你可以把它看做一本“百科全书”。由于 Scikit-Learn 的存在极大地提高了机器学习的效率,让开发者无须关注数学层面的公式、计算过程,有更多的更多的时间与精力专注于业务层面,从而解决实际的应用问题。
Scikit-Learn 的基本功能主要被分为六大部分:分类,回归,聚类,数据降维,模型选择和数据预处理。本教程将围绕机器算法的讲解 Scikit-Learn 实际的应用。
当你想要调用机器学习算法时也非常简单,Scikit-Learn 已经将算法按模型分类,比如线性回归算法可以从线性模型中调用,如下所示:
import sklearn
from sklearn import linear_model
model = linear_model.LinearRegression()
sklearn 中常用的算法库:
·linear_model:线性模型算法族库,包含了线性回归算法,以及 Logistic 回归算法,它们都是基于线性模型。
.naiv_bayes:朴素贝叶斯模型算法库。
.tree:决策树模型算法库。
.svm:支持向量机模型算法库。
.neural_network:神经网络模型算法库。
.neightbors:最近邻算法模型库。
四、线性回归算法(Linear Regression)
4.1 线性回归
“性代”表示线性模型,而“回归”则表示回归问题。也就是用线性模型(模型中因变量与自变量之间存在线性关系) 来解决 回归问题(“预测”真实值的过程),即利用线性模型来“预测”真实值的过程。
4.2 回归模型
线性回归模型:
例如是我们所熟知的一次函数(即y=kx+b),这种线性函数描述了两个变量之间的关系,其函数图像是一条连续的直线。如下图蓝色直线:
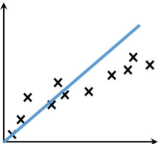
非线性回归模型:
(即不是一条直线),比如我们所熟知的对数函数、指数函数、二次函数等
4.3 线性回归方程
线性回归是如何实现预测的呢?其实主要是通过“线性方程”,或叫“回归方程”来实现。
现有以下一组数据
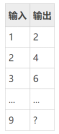
可得线性方程Y=2*X,预测出 9 所对应的输出值是18。在上述线程方程中2代表权值参数(权值,可理解为个不同“特征”对于预测结果的重要性。权值系数越大,那么这一项属性值对最终结果的影响就越大。),而求权值参数的过程就是“回归”,一旦有了这个参数,再给定输入,做预测就非常容易了。
具体的做法就是用 回归系数w1 乘以 输入值x ,这样就得到了 预测值y。上述示例的预测函数(或称假设函数)可记为: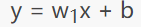
x :输入的样本数据
y :输出的预测结果
w1 :线性回归模型的权值参数
b :线性回归模型的“偏差值”
解决线性回归问题的关键就在于求出权值参数w1 、偏差值b
在实际应有中,线性回归模型要更复杂一些,比如要分析实际特征值对结果影响程度的大小,从而调整相应特征值的回归系数。下面举一个简单的应用示例:
现在要判断一个西瓜是否是成熟,根据我们的日常经验可从以下几个特征来判断:外表色泽(x)、根蒂(y)、敲声(z)。而以上三个特征所占用的权值参数也不同。如下所示:
上述表达式可以看出每一个特征值对预测结果的影响程度不同,根蒂是否“枯萎”对结果影响最大,而外表色泽是否鲜亮,敲声是否沉闷则占据次要因素。
当然采集数据的时也会存在一些无用数据,比如西瓜的外形、价格,这些特征不会对预测结果产生影响,因此它们权值参数为“0”。从这个例子可以得出“权值参数”是决定预测结果是否准确的关键因素。
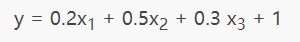
五、数学解析 Linear Regression
所谓“线性”其实就是一条“直线”(线性方程不能完全等同于“直线方程”,因为前者可以描述多维空间内直线,而后者只能描述二维平面内的 x 与 y 的关系。),先回顾初中的数学知识“一次函数”。
5.1 一次函数
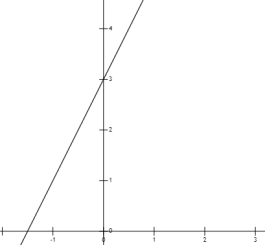
一次函数就是最简单的“线性模型”,其直线方程表达式为y = kx + b,其中 k 表示斜率,b 表示截距,x 为自变量,y 表示因变量。例如y = 2x + 3 的函数图像:
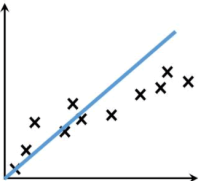
在机器学习中斜率 k 通常用 w 表示,也就是权重系数,因此“线性方程”通过控制 w 与 b 来实现 “直线”与数据点 最大程度的“拟合” 。如图。
5.2 构建线性模型
线性方程预测的结果具有连续性。下面通过示例简单说明:小亮今年 8 岁,去年 7 岁,前年 6 岁,那么他明年几岁呢?从机器学习的角度去看待这个问题。
首先年龄、时间是一组连续性的数据,也就是因变量随着自变量规律性地连续增长,显然它是一个“回归问题”。下面把上述数据以二维数组的形式表示出来,构建一个数据集,如下所示:
[[2021,8],
[2020,7],
[2019,6]]
由于“两点可以确定一条直线”,因此将两组数据代入 y = kx + b,最终求得“线程方程”: y = x - 2013
**y = x - 2013 就是所谓的 假设函数 ,通过它即可实现对结果的预测!**可以预测小亮明年的年龄为9岁。
六、线性回归:损失函数和假设函数
6.1 假设函数
通过前面知识的学习,我们知道假设函数是用来预测结果的。
线性方程并不等同于“直线方程”,线性方程描绘的是多维空间内的一条“直线”,并且每一个样本都会以向量数组的形式输入到函数中,因此假设函数也会发生一些许变化,函数表达式如下所示: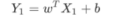
它和 Y=wX + b 是类似的,只不过我们这个标量公式 换成了 向量的形式。
Y1仍然代表预测结果, X1表示数据样本, b表示用来调整预测结果的“偏差度量值”,而wT表示权值系数的转置。
可以将假设函数写成关于 x 的函述表达式,如下所示:
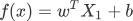
6.2 损失函数
我们知道,在线性回归模型中,数据样本散落在线性方程的周围
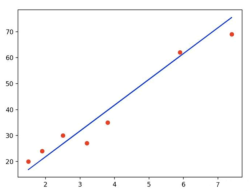
在线性回归中,损失函数是衡量模型预测值与实际观测值之间差异的函数,通常用于评估模型的拟合程度。
其实计算单个样本的误差值非常简单,只需用预测值减去真实值即可:
单样本误差值 = Y1 - Y
但是上述方法只适用于二维平面的直线方程。在线性方程中,要更加复杂、严谨一些,因此我们采用数学中的 “均方误差”公式 来计算单样本误差(分母 2 代表样本的数量):
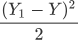
计算总样本误差: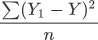
最后,将假设函数带入上述损失函数就会得到一个关于 w 与 b 的损失函数(loss),如下所示: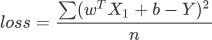
在机器学习中使用损失函数的目的,是为了使用“优化方法”来求得最小的损失值,这样才能使预测值最逼近真实值。
在上述函数中 n、Y、X1 都是已知的,因此只需找到一组 w 与 b 使得上述函数取得最小值即可,这就转变成了数学上二次函数求极值的问题,而这个求极值的过程也就我们所说的“优化方法”。
常见的损失函数包括均方误差(MSE)和平均绝对误差(MAE)
- 均方误差(MSE):将每个观测值的预测误差平方后求平均,对较大的误差给予更高的惩罚,适合对异常值比较敏感的情况。
- 平均绝对误差(MAE):则是观测值的预测误差的绝对值的平均,对异常值相对更加鲁棒。
七、梯度下降法求极值
上面解释了假设函数和损失函数,我们最终的目的要得到一个最佳的“拟合”直线,因此就需要将损失函数的偏差值减到最小,我们把寻找极小值的过程称为“优化方法”,常用的优化方法有很多,比如梯度下降法、共轭梯度法、牛顿法和拟牛顿法。
7.1 梯度下降
- 梯度下降:作为一种优化方法,其目的是要使得损失值最小。因此 “梯度下降”就需要控制损失函数的w和b参数来找到极小值。当损失函数取得极小值时,此时的参数值被称为“最优参数”。因此,在机器学习中最重要的一点就是寻找“最优参数”。
- 梯度:是微积分学的术语,它本质上是一个向量,表示函数在某一点处的方向导数上沿着特定的方向取得最大值,即函数在该点处沿着该方向变化最快,变化率最大。
7.2 求损失函数L的参数w和参数b
如何求损失函数L的参数w和参数b ?
即 如何求一个线性函数y’ = wx + b ?
使得 损失函数L(均方误差MSE)最小。
参考视频:https://www.bilibili.com/video/BV1oY411N7Xz
假设斜率w已知,如何找到b,使损失函数L最小?
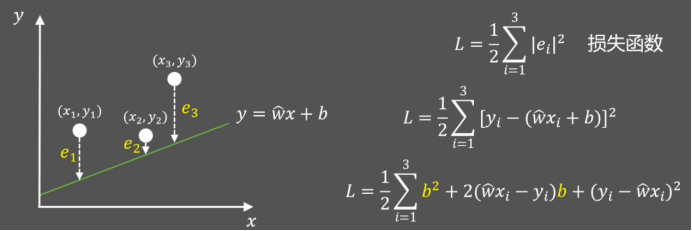
由上图可以看到损失函数L其实是关于b的一个二次函数,其他系数都可以直接计算出来。
假设该二次函数如下图所示,根据高中知识,求个导,可以算得L的最小值。
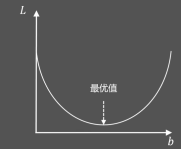
现在我们换一种求解思路: 我随便给出一个b的值(假>设已知w),能不能通过优化迭代的方式找到最好的b呢? 使用梯度下降法!!!
假设一个常数epsilon(学习率),
新参数b = 当前参数b - epsilon * 当前点的斜率(导数、偏导数)
新参数b = 当前参数b - 学习率 * 参数的梯度
通过这种方法更新b的值,使L变小…不断迭代更新。当优化到最低点时,斜率为0,b值不会再被更新了,优化结束。找到了最小的损失函数L,得到 线性回归模型!!!学习率:是一个由外部输入的参数,被称为“超参数”,可以形象地把它理解为下山时走的“步长”大小,想要 w 多调整一点,就把学习率调高一点。不过学习率也不是越高越好,过高的学习率可能导致调整幅度过大,导致无法求得真正的最小值。
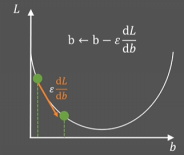
若将w记作a,损失函数L记作g(a,b),迭代方程:
梯度下降是个大家族,它有很多成员,比如批量梯度下降(BGD)、随机梯度下降(SGD)、小批量梯度下降(MBGD),其中批量梯度下降是最常用的。
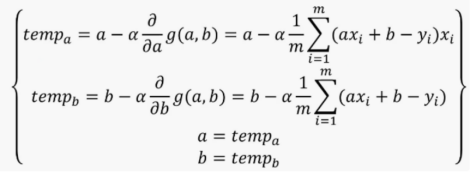
7.3 线性回归 步骤总结
线性回归适用于有监督学习的回归问题,首先在构建线性模型前,需要准备好待输入的数据集,数据集按照需要可划分为训练集和测试集,使用训练集中的向量 X 与向量 Y 进行模型的训练,其中向量 Y 表示对应 X 的结果数值(也就是“参考答案”);而输出时需要使用测试集,输入测试 X 向量输出预测结果向量 Y。
其实线性回归主要解决了以下三个问题:
第一,为假设函数设定了参数 w,通过假设函数画出线性“拟合”直线。
第二,将预测值带入损失函数,计算出一个损失值。
第三,通过得到的损失值,利用梯度下降等优化方法,不断调整 w 参数,使得损失值取得最小值。我们把这个优化参数值的过程叫做“线性回归”的学习过程。
八、实战:房价预测模型
代码实现过程大致可以分为以下6个步骤:
- 加载数据
- 划分训练集和测试集
- 建立线性回归模型
- 对给定的测试集数据进行预测
- 模型评估
- 绘图观察
import pandas as pd
import numpy as np
data = pd.read_csv('house.csv')
#训练集(数据集共5000条,选择70%作为训练集,前3500条)
X_train = data.drop(['Price'],axis=1).iloc[:3500]
Y_train = data['Price'].iloc[:3500]
#测试集(数据集共5000条,选择30%作为测试集,后1500条)
X_test = data.drop(['Price'],axis=1).iloc[3500:]
Y_test = data['Price'].iloc[3500:]
from sklearn.linear_model import LinearRegression
LR_multi = LinearRegression() #创建一个默认配置的线性回归模型对象 LR_multi
LR_multi.fit(X_train,Y_train) #将训练集数据喂进去,进行模型训练
Y_predict= LR_multi.predict(X_test)
from sklearn.metrics import mean_squared_error,r2_score
MSE = mean_squared_error(Y_test,Y_predict)
R_squared = r2_score(Y_test,Y_predict)
print("均方误差:",MSE) # MSE越接近0表示模型表现越好
print("确定系数:",R_squared) # R-squared越接近1表示模型表现越好
from matplotlib import pyplot as plt
fig = plt.figure(figsize=(8,5))
plt.scatter(Y_test,Y_predict)
plt.show()
#预测 Income=65000,,House Age=5, Number of Rooms=5, Population=30000, size=200的合理房价
#预测结果是大概82万,价格高出82万太多就不值得买了
X_test_df = pd.DataFrame(data=[[65000, 5, 5, 30000, 200]], columns=['Area Income', 'House Age', 'Number of Rooms', 'Area Population', 'size'])
y_test_predict = LR_multi.predict(X_test_df)
print("预测房价:", y_test_predict[0])
九、逻辑回归算法(Logistic Regression)
有监督学习分为“回归问题”和“分类问题”,前面我们已经认识了什么是“回归问题”,从本节开始我们将讲解“分类问题”的相关算法。Logistic回归算法 是针对“分类问题”的算法。不是用来解决“回归问题”的算法。
9.1 什么是分类问题
拿最简单的“垃圾分类处理”的过程来认识一下这个词。
“可回收”与“不可回收”是两种预测分类,而小明是主观判断的个体,他通过自己日常接触的知识对“垃圾种类”做出判断,我们把这个过程称作“模型训练”,只有通过“训练”才可以更加准确地判断“垃圾”的种类。小明进行每一次垃圾投放,都要对“垃圾”种类做出预先判断,最终决定投放到哪个垃圾桶内。这就是根据模型训练的结果进行预测的整个过程。
下面对上述过程做简单总结:
类别标签:“可回收”与“不可回收”。
模型训练:以小明为主体,把他所接受的知识、经验做为模型训练的参照。
预测:投放垃圾的结果,预测分类是否正确。并输出预测结果。
分类问题是当前机器学习的研究热点,它被广泛应用到各个领域,比图像识别、垃圾邮件处理、预测天气、疾病诊断等等。“分类问题”的预测结果是离散的,它比线性回归要更加复杂,那么我们应该从何处着手处理“分类问题”呢,这就引出了本节要讲的 Logistic 回归分类算法。
9.2 Logistic回归算法(分类问题)
Logistic 回归算法,又叫做逻辑回归算法,或者 LR 算法(Logistic Regression)。分类问题同样也可以基于“线性模型”构建。“线性模型”最大的特点就是“直来直去”不会打弯,而我们知道,分类问题的预测结果是“离散的”,即对输出数据的类别做判断。比如将类别预设条件分为“0”类和“1”类(或者“是”或者“否”)那么图像只会在 “0”和“1”之间上下起伏,如下图所示:
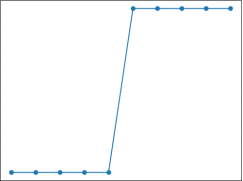
此时你就可能会有很多疑问,线性回归函数(例如y=2x+5)不可能“拟合”上述图像。没错,所以接下来我们要学习另一个线性函数 Logistic 函数。
在机器学习中,Logistic 函数通常用来解决二元分类问题,也就是涉及两个预设类别的问题。而当类别数量超过两个时就需要使用 Softmax函数来解决。
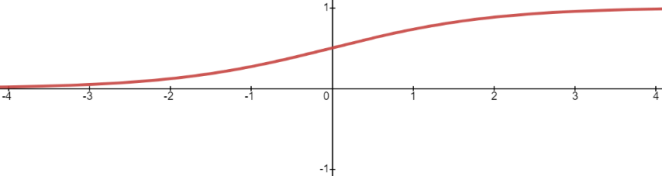
Logistic 函数 在神经网络算法中被称为 Sigmoid 函数,也有人称它为 Logistic 曲线。其函数图像如下所示:
该函数图像的数学表达式如下: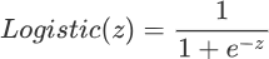
e 称为自然常数,也就是一个固定值的“常量”。
Logistic 函数也称为 S 型生长曲线,取值范围为 (0,1),它可以将一个实数映射到 (0,1) 的区间,非常适合做二元分类。
当z=0 时,其函数值为 0.5;
随着 z 的增大,其函数值将逼近于 1;
随着 z 的减小,其函数值将逼近于 0。
因此,对 Logistic 函数而言,坐标轴 0 是一个有着特殊意义坐标,越靠近 0 和越远离 0 会出现两种截然不同的情况:任何大于 0.5 的数据都会被划分到 “1”类中;而小于 0.5 会被归如到 “0”类。因此你可以把 Logistic 看做解决二分类问题的分类器。如果想要 Logistic 分类器预测准确,那么 x 的取值距离 0 越远越好,这样结果值才能无限逼近于 0 或者 1。
下面通过极限的思想进一步对上述函数展开研究:我们可以考虑两种情况:当 x 轴坐标取值缩小时就会出现以下图像,由此可见 Logistic 回归算法属于“线性”模型。
而当 x 逐渐放大时则会出现以下情况:
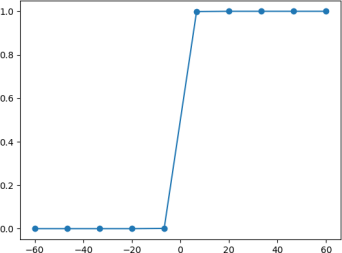
由上图可知,当 x 增大到一定程度时,Logistic 函数图像变成了“台阶”式图像,由此可知,该函数能够很好的“拟合”二分类问题函数图像。在数学上,我们把具有如上图所示,这种“阶梯式”图像的函数称为“阶跃函数”。
十、数学解析 Logistic Regression
从上文可知,分类问题的预测结果是离散型数据,那么我们在程序中要如何表述这些数据呢,再者我们要如何从数学角度理解 Logistic 算法,比如它的损失函数、优化方法等。
10.1 分类数据表示形式
-
向量形式
在机器学习中,向量形式是应用最多的形式,使用向量中的元素按顺序代表“类别”。现在有以下三个类别分别是 a/b/c,此时就可以使用 [1,2,3] 来分别代表上述三类,预测结果为哪一类,向量中的元素就对应哪个元素,比如当预测结果为 c 类的时候,则输出以下数据:[ 0 , 0 , 3 ] -
数字形式
我们可以用 0 代表“负类”(即 x < 0时的取值),而用“1”代表正类(即 x>0 时的取值)。那么当预测结果输出“1”就代表正类,而预测结果输出“0”代表“负类”。当然这里选择的数字只是形式,你可以选择任意其他数字,不过按照约定俗成,我们一般采用 “1”代表正类,而 “-1”或者“0”代表“负类”。 -
概率形式
在有些实际场景中,我们无法准确的判断某个“样本”属于哪个类别,此时我们就可以使用“概率”的形式来判断“样本”属于哪个类别的几率大,比如对某个“样本”有如下预测结果:[ 0.8 , 0.1 , 0.1 ]
从上述输出结果不难看出,该样本属于 a 类的概率最大,因此我们可以认定该样本从属于 a 类。
10.2 Logistic函数 数学解析
-
假设函数
经过上一节的学习得知 Logistic 函数能够很好的拟合“离散数据”,因此可以把它看做“假设函数”,但是还需要稍稍的改变一下形式,如下所示: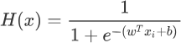
上述公式和 Logistic 函数基本一致,只不过我们它换成了关于x的表达式,并将幂指数x换成了 “线性函数”表达式。H(x) 的函数图像呈现 S 形分布,从而能够预测出离散的输出结果。 -
损失函数
表达式: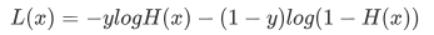
如何理解上述损失函数的表达式?
我们需要继续分析假设函数。我们知道假设函数的值域是从 (0,1) 之间的数值,而这个数据区间恰好与概率值区间不谋而合。如果我们把预测结果看做概率,则可以得到另外一种写法的损失函数: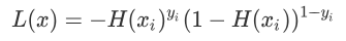
上述函数是根据概率设计出来的,它由
两部分组成
我们知道 y 输出值概率值只能为 0 或者 1,因此上述函数只会有一部分输出数值。
当 y=1 时候,1-y 就等于 0,因此上述表达式的第二部分的值为 1,相乘后并不会对函数值产生影响。
当 y = 0 时,上述表达式的第一部分的值为 1,相乘后并不会对函数值产生影响。
综上所述:当 y=1 时,
如果预测正确,预测值H(x)则无限接近 1,也即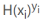 的值为 1,损失值则为 -1;
的值为 1,损失值则为 -1;
如果预测错误,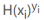 的值为 0,损失值也为 0。
的值为 0,损失值也为 0。
预测错误的损失值确实比预测正确的损失值大(0 > -1),满足要求。
虽然上述函数能够表达预测值和实际值之间的偏差,但它有一个缺点就是不能使用梯度下降等优化方法。因此,在机器学习中要通过取对数的方法来解决此问题,这样就得到了最开始的损失函数。如下所示:
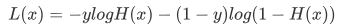
- 优化方法
如果将 Logistic 函数的输出记做 z 可得如下公式:
采用向量的形式可以写为: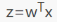
其中, 向量x 是分类器的输入数据,向量 w (最佳参数)会使得分类器尽可能的精确。为了寻找该 最佳参数w 就需要用到优化方法,下面我们简单介绍梯度上升优化方法。
梯度上升优化方法:
梯度上升与梯度下降同属于优化方法,梯度下降求的是“最小值”,而梯度上升求的是“最大值”。梯度上升基于的思想是:要找到某函数的最大值,最好的发放是沿着该函数的梯度方向寻找,如果把梯度记为▽,那么关于 f(x,y) 有以下表达式:
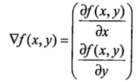
该函数分别对 x 与 y 求的偏导数,其中关于 x 的偏导数表示沿着 x 的方向移动,而关于 y 的偏导数一个表示沿 y 的方向移。其中,函数f(x,y) 必须要在待计算的点上可导。在梯度上升的过程中,梯度总是指向函数值增长最快的方向,我们可以把每移动一次的“步长”记为α 。用向量来表示的话,其公式如下:w1 = w + α ▽w f(w)
在梯度上升的过程中,上述公式将一直被迭代执行,直至达到某个停止条件为止,比如达到某个指定的值或者某个被允许的误差范围之内。
十一、范数 与 回归类算法
11.1 什么是范数?
范数又称为“正则项“,它表示了一种运算方式,“范数”的种类有很多,不过常见的范数主要分为两种:L1 和 L2
-
L1范数:表示向量中每个元素绝对值的和。
计算分两步:,首先逐个求得元素的绝对值,然后相加求和即可。下面给出了 L1 范数 正则化定义的数学表达式,如下所示:
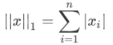
注意:此时两个绝度值符号,是符合范数规定的,两个绝对值符号表示范数 -
L2范数:表示向量中每个元素的平方和的平方根。
计算分三步,首先逐个求得元素的平方,然后相加求和,最后求和的平方根。L2范数 正则化定义的数学表达式如下:

11.2 回归类算法
除了“线性回归算法”,还有以下常用算法:
-
Ridge类:Ridge 回归算法,又称“岭回归算法”主要用于预测回归问题,是在线性回归的基础上添加了 L2 正则项,使得权重 w 的分布更加均匀,其损失函数如下:
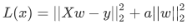
损失函数的左侧与线性回归算法的损失函数一致。只是在最后添加右侧的 L2 正则项,其中 a 只是一个常数,需要根据经验设置。 -
Lasso类:Lasso 回归算法,可以预测回归问题,使用了 L1 正则项的线性回归是 Lasso 回归算法。
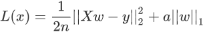
上述表达式的左侧与 Ridge 回归算法的损失函数基本一致,只是将右侧的 L2 范数替换成了 L1 范数,而且左侧式子相比线性回归表达式而言,多了一个1/2,但实际的优化过程中,它并不会对权重 w 产生影响。
十二、实战:鸢尾花类别预测模型
sklearn 库中自带了许多种类的内建数据集,比如波士顿房价数据集,手写数字识别数据集,鸢尾花数据集,糖尿病数据集等,这些数据集对我们学习机器学习算法提供了很好的帮助,节省了我们收集、整理数据集的时间。下面我们以鸢尾花数据集对 Logistic 回归算法进行简单的应用。
#logistic算法
#从 scikit-learn库导入线性模型中的logistic回归算法
from sklearn.linear_model import LogisticRegression
#导入sklearn 中的自带数据集 鸢尾花数据集
from sklearn.datasets import load_iris
#skleran 提供的分割数据集的方法
from sklearn.model_selection import train_test_split
#载入鸢尾花数据集
iris_dataset=load_iris()
#data 数组的每一行对应一朵花,列代表每朵花的四个测量数据,分别是:花瓣的长度,宽度,花萼的长度、宽度
print("data数组类型: {}".format(type(iris_dataset['data'])))
#前五朵花的数据
print("前五朵花数据:\n{}".format(iris_dataset['data'][:5]))
#分割数据集训练集,测试集
X_train,X_test,Y_train,Y_test=train_test_split(iris_dataset['data'],iris_dataset['target'],random_state=0)
#训练模型
#设置最大迭代次数为3000,默认为1000.不更改会出现警告提示
log_reg = LogisticRegression(max_iter=3000)
#给模型喂入数据
clm=log_reg.fit(X_train,Y_train)
#使用模型对测试集分类预测,并打印分类结果
print("分类结果:",clm.predict(X_test))
#最后使用性能评估器,测试模型优良,用测试集对模型进行评分
print("对模型进行评分:",clm.score(X_test,Y_test))
最后,我们对 Logistic 算法做一下简单总结:首先 Logistic 算法适用于分类问题,该算法在处理二分类问题上表现优越,但在多分类(二个以上)问题上容易出现欠拟合。Logistic 算法除了适用于回归分类问题,还可以作为神经网络算法的激活函数(即 Sigmoid 函数)。
机器学习中有许多的算法,我们不能评价一个算法的优劣性,因为算法只有合适与不合适,每个算法都有其适用的场景。因此,我们不能仅依据模型评分来评价模型的好与坏。这就好比从每个班级中选出数学非常优秀的学生去参加数学竞赛一样,如果竞赛的第一名只得了 60 分,而其余学生都不及格,那你会说他们都是是个差生吗,因此,在后续学习机器学习算法的过程中要牢记这一点。
十三、KNN最邻近分类算法(K-Nearest-Neighbor)
它是有监督学习分类算法的一种。所谓 K 近邻,就是 K 个最近的邻居。比如对一个样本数据进行分类,我们可以用与它最邻近的 K 个样本来表示它,这与俗语“近朱者赤,近墨者黑”是一个道理。
在学习 KNN 算法的过程中,你需要牢记两个关键词,一个是“少数服从多数”,另一个是“距离”,它们是实现 KNN 算法的核心知识。
13.1 KNN算法原理
为了判断未知样本的类别,以所有已知类别的样本作为参照来计算未知样本与所有已知样本的距离,然后从中选取与未知样本距离最近的 K 个已知样本,并根据少数服从多数的投票法则(majority-voting),将未知样本与 K 个最邻近样本中所属类别占比较多的归为一类。
KNN 算法简单易于理解,无须估计参数,与训练模型,适合于解决多分类问题。但它的不足是:当样本不平衡时(例如一个类的样本容量很大,而其他类样本容量很小时),有很能导致当输入一个新样本时,该样本的 K 个邻居中大容量类的样本占多数,而此时只依照数量的多少去预测未知样本的类型,就会可能增加预测错误概率。此时,我们就可以采用对样本取“权值”的方法来改进。
13.2 KNN算法流程
KNN 分类算法主要包括以下 4 个步骤:
- 准备数据,对数据进行预处理 。
- 计算测试样本点(也就是待分类点)到其他每个样本点的距离(选定度量距离的方法)。
- 对每个距离进行排序,然后选择出距离最小的 K 个点。
- 对 K 个点所属的类别进行比较,按照少数服从多数的原则(多数表决思想),将测试样本点归入到 K 个点中占比最高的一类中。
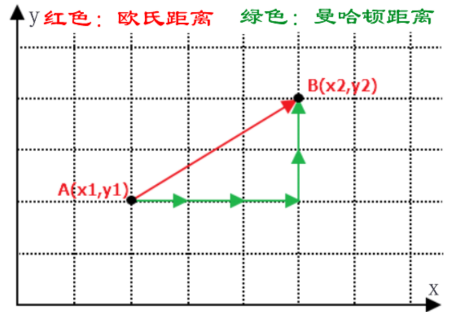
在机器学习中有多种不同的距离公式,下面以计算二维空间 A(x,y),B(x1,y1) 两点间的距离为例进行说明,下图展示了如何计算欧式距离和曼哈顿街区距离。
计算公式如下:
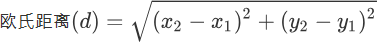
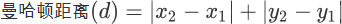
那么如何考虑它们两者的区别呢?其实很容易理解,我们知道两点之前线段最短,A 和 B 之间的最短距离就是“欧式距离”,但是在实际情况中,由于受到实际环境因素的影响,我们有时无法按照既定的最短距离行进,比如你在一个楼宇众多的小区内,你想从 A 栋达到 B 栋,但是中间隔着其他楼房,因此你必须按照街道路线行进(图中红线),这种距离就被称作“曼哈顿街区距离”。在 KNN 算法中较为常用的距离公式是“欧氏距离”。
13.3 KNN预测分类
我们应该如何确定 K 值呢?因为不同的 K 值会影响分类结果,如下所示:
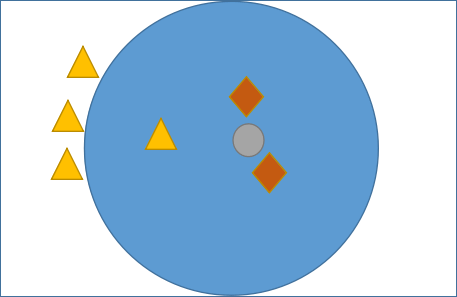
如图 1 所示,有三角形和菱形两个类别,而“灰色圆”是一个未知类别,现在通过 KNN 算法判断“灰色圆”属于哪一类。如果当 K 的取值为 3 时,按照前面讲述的知识,距离最近且少数服从多数,那“灰色圆”属于菱形类,而当 K= 6 时,按照上述规则继续判断,则“灰色圆”属于三角形类。
十四、实战:红酒类别预测模型
Python Sklearn 机器学习库提供了 neighbors 模块,该模块下提供了 KNN 算法的常用方法,如下所示:
| 类方法 | 说明 |
|---|---|
| KNeighborsClassifier | KNN 算法解决回归问题 |
| KNeighborsRegressor | KNN 算法解决回归问题 |
| RadiusNeighborsClassifier | 基于半径来查找最近邻的分类算法 |
| NearestNeighbors | 基于无监督学习实现KNN算法 |
| KDTree | 无监督学习下基于 KDTree 来查找最近邻的分类算法 |
| BallTree | 无监督学习下基于 BallTree 来查找最近邻的分类算法 |
本节可以通过调用 KNeighborsClassifier 实现 KNN 分类算法。下面对 Sklearn 自带的“红酒数据集”进行 KNN 算法分类预测。最终实现向训练好的模型喂入数据,输出相应的红酒类别,示例代码如下:
#加载红酒数据集
from sklearn.datasets import load_wine
#KNN分类算法
from sklearn.neighbors import KNeighborsClassifier
#分割训练集与测试集
from sklearn.model_selection import train_test_split
#导入numpy
import numpy as np
#加载数据集
wine_dataset=load_wine()
#查看数据集对应的键
print("红酒数据集的键:\n{}".format(wine_dataset.keys()))
print("数据集描述:\n{}".format(wine_dataset['data'].shape))
#data 为数据集数据;target 为样本标签
#分割数据集,比例为 训练集:测试集 = 8:2
X_train,X_test,y_train,y_test=train_test_split(wine_dataset['data'],wine_dataset['target'],test_size=0.2,random_state=0)
#构建knn分类模型,并指定 k 值
KNN=KNeighborsClassifier(n_neighbors=10)
#使用训练集训练模型
KNN.fit(X_train,y_train)
#评估模型的得分
score=KNN.score(X_test,y_test)
print(score)
#给出一组数据对酒进行分类
X_wine_test=np.array([[11.8,4.39,2.39,29,82,2.86,3.53,0.21,2.85,2.8,.75,3.78,490]])
predict_result=KNN.predict(X_wine_test)
print(predict_result)
print("分类结果:{}".format(wine_dataset['target_names'][predict_result]))
最终输入数据的预测结果为 1 类别。
十五、贝叶斯定理(公式)
15.1 贝叶斯定理
贝叶斯定理的发明者 托马斯·贝叶斯 提出了一个很有意思的假设:“如果一个袋子中共有 10 个球,分别是黑球和白球,但是我们不知道它们之间的比例是怎么样的,现在,仅通过摸出的球的颜色,是否能判断出袋子里面黑白球的比例?”
在统计学中有两个较大的分支:一个是“频率”,另一个便是“贝叶斯”,它们都有各自庞大的知识体系,而“贝叶斯”主要利用了“相关性”一词。下面以通俗易懂的方式描述一下“贝叶斯定理”:
通常,事件A在事件B发生的条件下 与 事件B在事件A发生的条件下,它们两者的概率并不相同,但是它们两者之间存在一定的相关性,并具有以下公式(称之为“贝叶斯公式”):
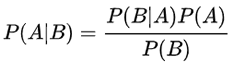
上述公式中符号的意义?
- P(A) 这是概率中最基本的符号,表示 A 出现的概率。比如在投掷骰子时,P(2) 指的是骰子出现数字“2”的概率,这个概率是 六分之一。
- P(B|A) 是条件概率的符号,表示事件 A 发生的条件下,事件 B
发生的概率,条件概率是“贝叶斯公式”的关键所在,它也被称为“似然度”。 - P(A|B) 是条件概率的符号,表示事件 B 发生的条件下,事件 A 发生的概率,这个计算结果也被称为“后验概率”。
有上述描述可知,贝叶斯公式可以预测事件发生的概率,两个本来相互独立的事件,发生了某种“相关性”,此时就可以通过“贝叶斯公式”实现预测。
15.2 条件概率
条件概率是“贝叶斯公式”的关键所在,那么如何理解条件概率呢?
其实我们可以从“相关性”这一词语出发。举一个简单的例子,比如小明和小红是同班同学,他们各自准时回家的概率是
P(小明回家) = 1/2
P(小红回家) = 1/2
但是假如小明和小红是好朋友,每天都会一起回家,那么 (理想状态下)
P(小红回家|小明回家) = 1
但是还有一种情况,比如小亮每天准时到家 P(小亮回家) =1/2,但是小亮喜欢独来独往,如果问 P(小亮回家|小红回家) 的概率是多少呢?你会发现这两者之间不存在“相关性”,小红是否到家,不会影响小亮的概率结果,因此小亮准时到家的概率仍然是 1/2。
贝叶斯公式的核心是“条件概率”,譬如 P(B|A),就表示当 A 发生时,B 发生的概率,如果P(B|A)的值越大,说明一旦发生了 A ,B就越可能发生。两者可能存在较高的相关性。
15.3 先验概率
在贝叶斯看来,世界并非静止不动的,而是动态和相对的,他希望利用已知经验来进行判断,那么如何用经验进行判断呢?这里就必须要提到“先验”和“后验”这两个词语。我们先讲解“先验”,其实“先验”就相当于“未卜先知”,在事情即将发生之前,做一个概率预判。比如从远处驶来了一辆车,是轿车的概率是 45%,是货车的概率是 35%,是大客车的概率是 20%,在你没有看清之前基本靠猜,此时,我们把这个概率就叫做“先验概率”。
15.4 后验概率
我们知道每一个事物都有自己的特征,比如前面所说的轿车、货车、客车,它们都有着各自不同的特征,距离过远的时候,我们无法用肉眼分辨,而当距离达到一定范围内就可以根据各自的特征再次做出概率预判,这就是后验概率。比如轿车的速度相比于另外两者更快可以记做 P(轿车|速度快) = 55%,而客车体型可能更大,可以记做 P(客车|体型大) = 35%。
如果用条件概率来表述 P(体型大|客车)=35%,这种通过“车辆类别”推算出“类别特征”发生的的概率的方法叫作“似然度”。这里的似然就是“可能性”的意思。
解完上述概念,你可能对贝叶斯定理有了一个基本的认识,实际上贝叶斯定理就是求解后验概率的过程,而核心方法是通过似然度预测后验概率,通过不断提高似然度,自然也就达到了提高后验概率的目的。
十六、朴素贝叶斯分类算法原理
笔记参考:C语言中文网https://c.biancheng.net















 520
520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









