






| 项目 | 内容 |
|---|---|
| 这个作业属于哪个课程 | 2023年北航敏捷软件工程 |
| 这个作业的要求在哪里 | 结对项目-最长英语单词链 |
| 我在这个课程的目标是 | 锻炼工程思维,提高开发能力 |
| 这个作业在哪个具体方面帮助我实现目标 | 体验结对编程,提高编程水平 |
项目地址
1.在文章开头给出教学班级和可克隆的 Github 项目地址(例子如下)。
- 教学班级:周二班
- 项目地址:https://github.com/github/platform-samples.git
- 教学班级:周四下午班
- 项目地址:https://github.com/cccvs/WordList
项目耗时
2.在开始实现程序之前,在下述 PSP 表格记录下你估计将在程序的各个模块的开发上耗费的时间。
15.在你实现完程序之后,在附录提供的PSP表格记录下你在程序的各个模块上实际花费的时间。
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 90 |
| · Estimate | · 估计这个任务需要多少时间 | 60 | 90 |
| Development | 开发 | 1770 | 2430 |
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 150 |
| · Design Spec | · 生成设计文档 | 120 | 60 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 60 | 90 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| · Design | · 具体设计 | 120 | 150 |
| · Coding | · 具体编码 | 600 | 720 |
| · Code Review | · 代码复审 | 120 | 150 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 600 | 720 |
| Reporting | 报告 | 120 | 150 |
| · Test Report | · 测试报告 | 60 | 100 |
| · Size Measurement | · 计算工作量 | 30 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 1950 | 2670 |
设计与实现
接口设计思想
3.看教科书和其它资料中关于 Information Hiding,Interface Design,Loose Coupling 的章节,说明你们在结对编程中是如何利用这些方法对接口进行设计的。
- 信息隐藏:信息隐藏指在设计和确定模块时,使得一个模块内包含的特定信息(过程或数据),对于不需要这些信息的其他模块来说,是不可访问的。在我们的设计中,我们只为计算模块保留了三个必要的接口,而隐藏了计算模块内部的算法和数据,调用者无需关注内部实现细节。
- 接口设计:好的接口设计有助于各模块之间的解耦,我们的接口设计遵循了单一职责原则,每个接口仅负责一个功能,互不干扰,例如三个接口分别对应
-n、-w、-c参数。通过这些接口,用户可以根据不同需求调用相应的方法,为后续的解耦合、单元测试等提供了便利。 - 松耦合:松耦合的目标是最小化依赖,使得修改一个模块时不会影响其他模块的结构。我们将整个项目解耦成计算模块、CLI 模块、GUI 模块与单元测试模块,使得后三者可以单独调用计算模块而不会相互影响,方便了 bug 的定位与修复,同时也可以与他人交换模块进行调试。
接口设计与实现
4.计算模块接口的设计与实现过程。设计包括代码如何组织,比如会有几个类,几个函数,他们之间关系如何,关键函数是否需要画出流程图?说明你的算法的关键(不必列出源代码),以及独到之处。
对外接口
计算模块设计了如下三个对外暴露的接口函数:
int gen_chains_all(char *words[], int len, char *result[], void *my_malloc(size_t));
int gen_chain_word(char *words[], int len, char *result[], char head, char tail, char reject, bool enable_loop, void *my_malloc(size_t));
int gen_chain_char(char *words[], int len, char *result[], char head, char tail, char reject, bool enable_loop, void *my_malloc(size_t));
各个接口函数的含义如下:
gen_chains_all:获取所有单词链的接口,返回值代表返回时result指针数组的长度。gen_chain_word:获取单词最多的单词链,返回值代表返回时result指针数组的长度。gen_chain_char:获取字母数最多的单词链,返回值代表返回时result指针数组的长度。
各个参数的含义如下:
words:输入单词的字符指针数组,在传入前已转小写和去重。len:输入指针数组words的有效长度。result:接收单词返回值的字符指针数组。head:对单词链开头字母的限制,无限制则为'\0'。tail:对单词链结尾字母的限制,无限制则为'\0'。reject:单词链中禁止出现的以该字母开头的单词,无限制则为'\0'。enable_loop:是否允许出现单词环。my_malloc:外部传入分配内存空间的函数指针。
参数特殊说明:
words统一由调用者分配和释放空间。result统一由计算模块分配空间,调用者释放空间。- 对于
my_malloc参数,考虑到core.dll与调用者编译时的环境(编译器、库函数版本等)不同,如果直接使用库函数malloc分配空间,可能会因内部malloc函数和外部free函数的不匹配而导致内存泄漏(参考 https://stackoverflow.com/questions/13625388/is-it-bad-practice-to-allocate-memory-in-a-dll-and-give-a-pointer-to-it-to-a-cli)。因此可以从外部传入malloc的函数地址,保证malloc和free的编译环境一致。
功能函数
core.dll 中还有若干对外不可见的功能函数。功能如下:
make_graph:根据输入的单词字符串建立图,根据“最长”的判定条件设置边的权重,并通过tarjan算法求出各强连通分量。check_loop:检查输入数据是否存在单词环,如果存在,则抛出异常。dfs_all:枚举起点,通过深度优先搜索,获得所有单词链。solve_dag:在有向无环图上广度优先搜索+动态规划求最长路。solve_loop:在一般的有向图上,遍历起始节点,记忆化搜索最长路。
算法细节
对于无单词环的情况,调用 solve_dag,采用动态规划的策略求解最长路。
设
d
p
u
dp_u
dpu 是以节点
u
u
u 为终点的最长路径长度,
s
u
s_u
su 为节点
u
u
u 所有自环的权重之和(若
u
u
u 没有自环则权重
s
u
s_u
su 为
0
0
0)。在初始化阶段,
d
p
v
dp_v
dpv 被初始化为
s
v
s_v
sv 。对于从
u
u
u 到
v
v
v,权值为
w
w
w 的有向边,状态转移方程为:
d
p
v
=
max
(
d
p
u
+
w
+
s
u
,
d
p
v
)
dp_v = \max(dp_u + w + s_u, dp_v)
dpv=max(dpu+w+su,dpv)
对于有单词环的情况,调用 solve_loop,采用遍历节点搜索的策略求解最长路。
该问题是 NP 问题,但可以使用记忆化搜索对其优化。
状态一部分由当前节点编号组成,使用一个 int 表示。另外一部分为该节点所在连通分量内边的使用情况,第 i 位为 0/1 表示编号为 i 的边未使用/使用,使用两个 long long 组成 128 位的位向量表示。将状态作为键,当前状态的最长路径长度最为值,使用 map 储存搜索记录。
每次搜索时,如果进入了已经搜索的状态,则及时剪枝,避免重复搜索。
编译通过截图
5.展示在所在开发环境下编译器编译通过无警告的截图
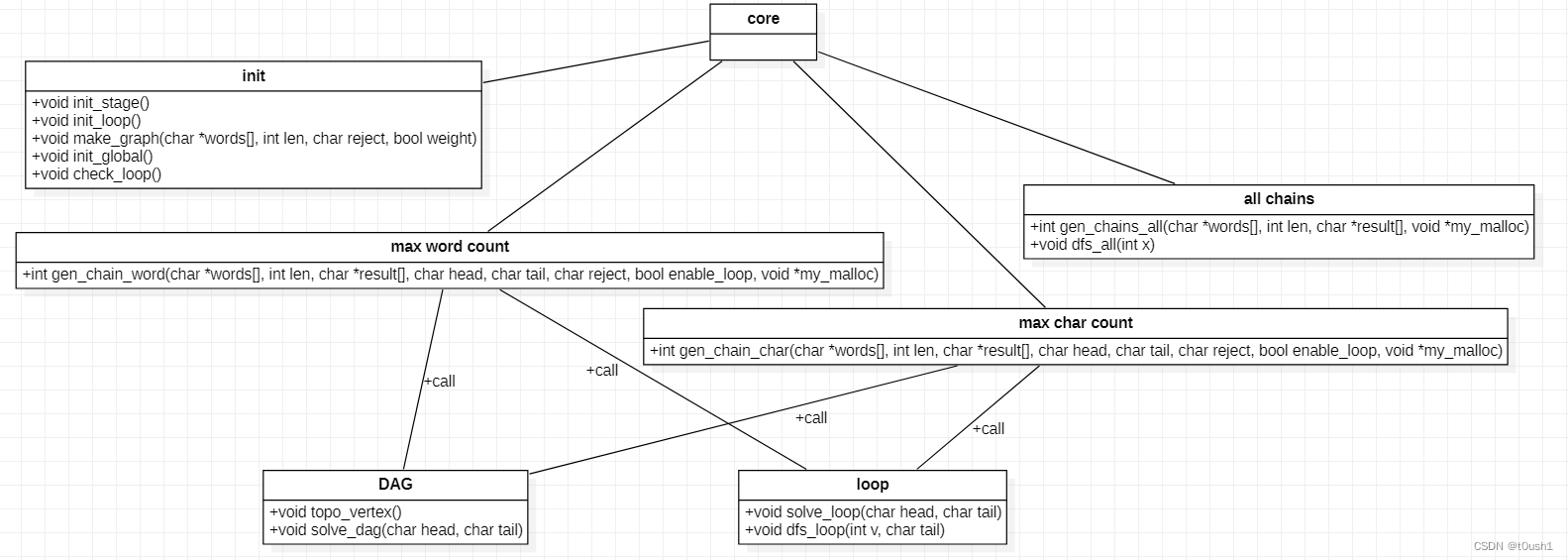
UML 图
6.阅读有关 UML 的内容,画出 UML 图显示计算模块部分各个实体之间的关系(画一个图即可)。
- https://en.wikipedia.org/wiki/Unified_Modeling_Language
界面模块设计
11.界面模块的详细设计过程。在博客中详细介绍界面模块是如何设计的,并写一些必要的代码说明解释实现过程。
CLI 部分
命令行模块的处理过程主要分为以下几步:解析参数、检查参数、读文件、解析单词、单词去重、调用计算模块、输出结果,封装在函数 cli 中。
int cli(int argc, char *argv[], bool output) {
content = result[0] = nullptr;
bool flags[NUM_OF_FLAG] = {};
char *values[NUM_OF_FLAG] = {};
parse_args(argc, argv, flags, values);
check_args(flags, values);
char *file_path = flags[N] ? values[N] : flags[W] ? values[W] : values[C];
char head = flags[H] ? values[H][0] : '\0';
char tail = flags[T] ? values[T][0] : '\0';
char reject = flags[J] ? values[J][0] : '\0';
bool enable_loop = flags[R];
int r;
content = read_file(file_path);
parse_words(content, words, len);
unique_words(words, len);
if (flags[N]) {
r = gen_chains_all(words, len, result, malloc);
} else if (flags[W]) {
r = gen_chain_word(words, len, result, head, tail, reject, enable_loop, malloc);
} else {
r = gen_chain_char(words, len, result, head, tail, reject, enable_loop, malloc);
}
if (output) {
if (flags[N]) {
write_result_to_screen(result, r);
} else {
write_result_to_file(result, r);
}
}
return r;
}
其中所调用的函数的原型及功能如下:
-
参数处理
// 解析命令行参数,并把 flag 和参数值以键值对的形式保存到 flags 和 values 数组中 void parse_args(int argc, char *argv[], bool flags[], char *values[]); // 参数合法性检查,若不通过则会抛出相应异常 void check_args(const bool flags[], char *values[]); -
输入及处理
// 读入文件内容,并返回所分配空间的地址 char *read_file(char *file_path); // 解析单词,将 words 数组中的指针分别指向 content(文件内容)中的每个单词的首地址,并把非单词的空间设为 '\0',从而无需为每个单词重新分配内存,提高了运行速度,也便于统一回收整块空间 void parse_words(char *content, char *words[], int &len); // 将单词去重,具体方法为将最后一个元素 words[len-1] 移动到待删除元素的位置并将长度减一,也无需分配额外空间 void unique_words(char *words[], int &len); -
计算模块的调用
对于三个接口函数,参考上文接口设计一节。
-
输出结果
// 将结果输出到文件 solution.txt void write_result_to_file(char *result[], int len); // 将结果输出到控制台 void write_result_to_screen(char *result[], int len)
GUI 部分
图形用户界面由 c++ 和 Qt 5.14 实现,核心类其对应功能如下:
MainView:主视图,包含输入、输出、选项三个子视图InputView:输入视图,包含导入文件、显示输入、修改输入等功能OutputView:输出视图,显示运行后的结果,支持导出到文件OptionView:选项视图,提供交互按钮和复选框,实现 7 个参数的功能,显示运行时间等
主要业务逻辑的处理过程为:加载 dll,获得参数和输入,处理单词,调用计算模块,显示输出和运行时间,释放资源。其中还复用了 parse_words、unique_words 等功能函数,减少了重复代码。
void MainView::execute() const {
core = LoadLibraryA("core.dll");
gen_chains_all = (func1)GetProcAddress(core, "gen_chains_all");
gen_chain_word = (func2)GetProcAddress(core, "gen_chain_word");
gen_chain_char = (func2)GetProcAddress(core, "gen_chain_char");
QString text = this->input->text->toPlainText();
char *content = (char *)malloc(text.length() + 1);
strcpy(content, text.toLatin1().data());
char head = this->option->head->get_char();
char tail = this->option->tail->get_char();
char reject = this->option->reject->get_char();
bool enable_loop = this->option->check->isChecked();
int mode = this->option->mode->currentIndex();
int r;
parse_words(content, words, len);
unique_words(words, len);
result[0] = nullptr;
try {
qint64 start = QDateTime::currentDateTime().toMSecsSinceEpoch();
if (mode == 0) {
r = gen_chains_all(words, len, result, malloc);
} else if (mode == 1) {
r = gen_chain_word(words, len, result, head, tail, reject, enable_loop, malloc);
} else if (mode == 2) {
r = gen_chain_char(words, len, result, head, tail, reject, enable_loop, malloc);
}
qint64 end = QDateTime::currentDateTime().toMSecsSinceEpoch();
QString res = QString::number(r) % '\n';
for (int i = 0; i < r; ++i) {
res = res % QString(result[i]) % '\n';
}
this->output->text->setText(res);
this->option->time->setText("计算时间:" + QString::number((double)(end - start) / 1000, 'f', 3) + "s");
} catch (const logic_error &e) {
if (strcmp(e.what(), "Too many word chains!") == 0) {
QMessageBox::warning((QWidget *)this, "core 错误", "单词链数目过多");
} else {
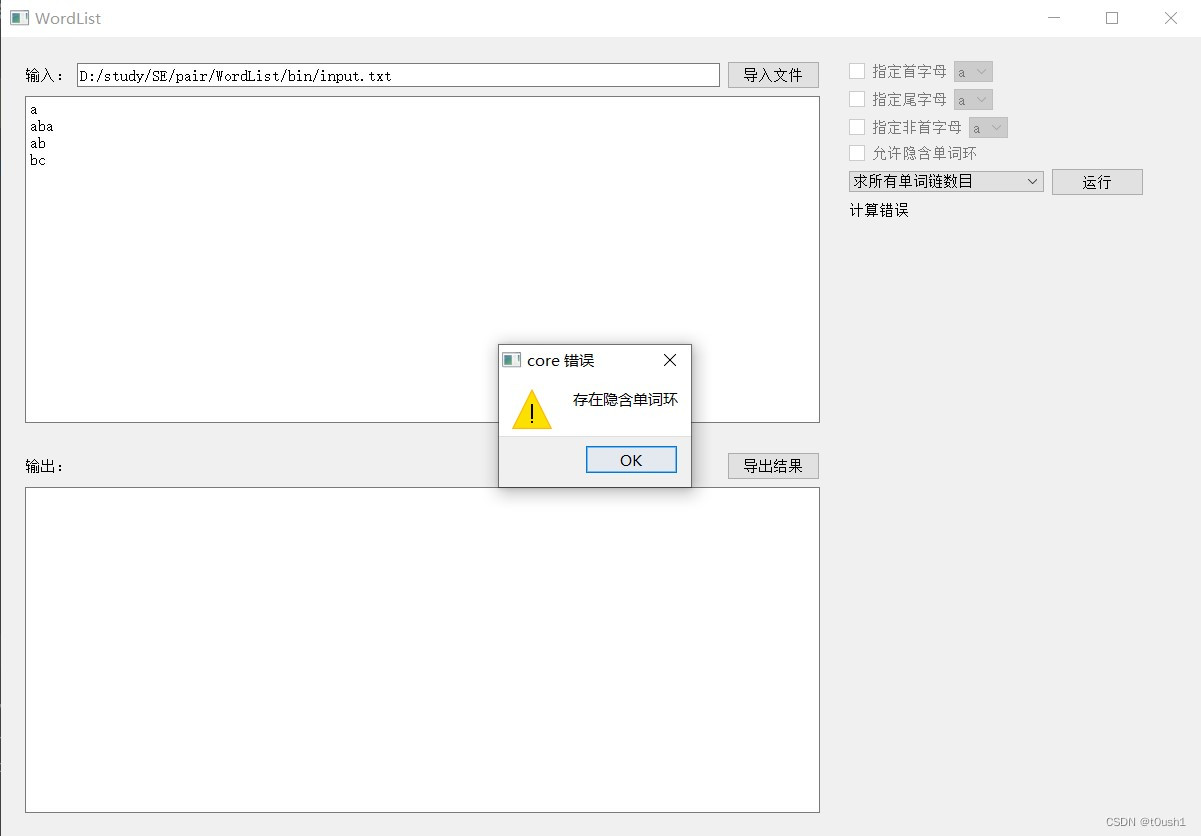
QMessageBox::warning((QWidget *)this, "core 错误", "存在隐含单词环");
}
this->output->text->clear();
this->option->time->setText("计算错误");
}
free(content);
free(result[0]);
FreeLibrary(core);
}
模块对接
12.界面模块与计算模块的对接。详细地描述 UI 模块的设计与两个模块的对接,并在博客中截图实现的功能。
CLI 部分
core 通过 extern "C" __declspec(dllexport) 导出接口函数,并编译成动态链接库。
CLI 通过 target_link_libraries 命令来导入动态链接库。
add_library(core SHARED
core.cpp
core.h)
target_link_libraries(Wordlist core)
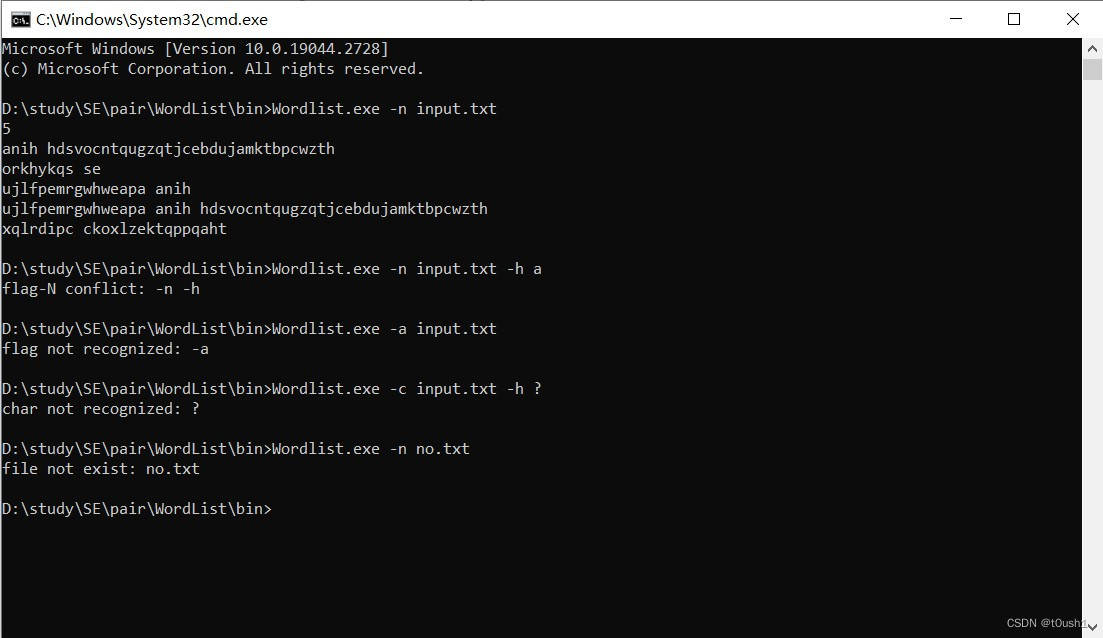
命令行程序负责解析参数和输入,将其转化为对应函数参数后调用计算模块接口,并把返回结果转化为输出,打印到控制台或文件。
正常运行时的功能和错误处理功能如图:
GUI 部分
GUI 通过 LoadLibraryA 动态加载 dll 和 GetProcAddress 导入接口函数,最后用 FreeLibrary 释放 dll 资源。
typedef int (*func1)(char *[], int, char *[], void *(size_t));
typedef int (*func2)(char *[], int, char *[], char, char, char, bool, void *(size_t));
HMODULE core = LoadLibraryA("core.dll");
func1 gen_chains_all = (func1)GetProcAddress(core, "gen_chains_all");
func2 gen_chain_word = (func2)GetProcAddress(core, "gen_chain_word");
func2 gen_chain_char = (func2)GetProcAddress(core, "gen_chain_char");
FreeLibrary(core);
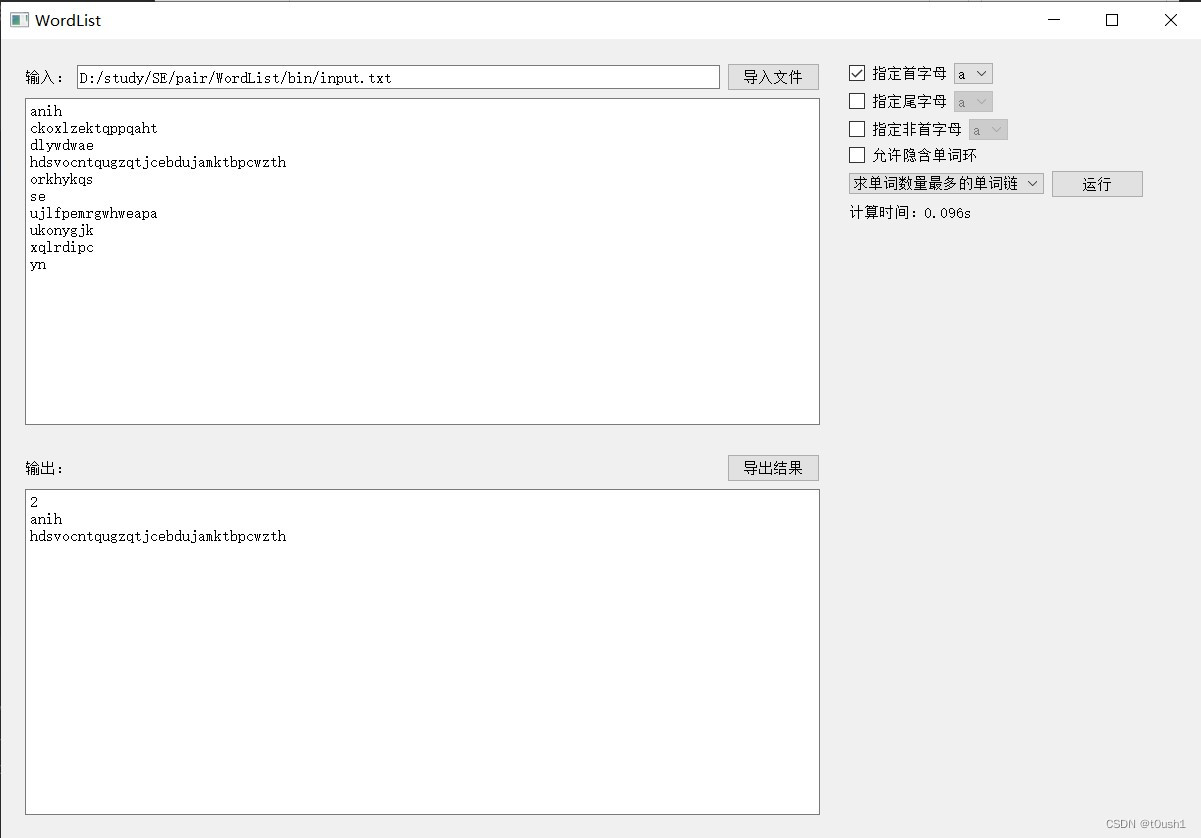
GUI 程序先动态加载 dll,再从界面中读取输入和相关参数,转化为对应函数参数后调用计算模块接口,将结果输出到界面中,最后释放资源,防止内存泄漏。
正常运行时的功能如图:
错误处理功能如图:
性能改进
7.计算模块接口部分的性能改进。记录在改进计算模块性能上所花费的时间,并展示你程序中消耗最大的函数,陈述你的性能改进策略。
我们在设计时考虑了如下优化:
- 内存分配时,计算好分配的空间大小,一次性分配所有存储字符串的空间。避免分配多次分配零碎的小空间。
- 在 DAG 中求解最长路时,按照拓扑序遍历更新节点状态,时间复杂度可以优化到 O ( ∣ V ∣ + ∣ E ∣ ) O(|V| + |E|) O(∣V∣+∣E∣) 水平。
- 在有环情况下,遍历结点时,优先走完所有自环;在多个平行边可供选择时,优先走权重最高的边。
- 在有环情况下,使用记忆化搜索减少搜索的分支。将当前已使用的边集与当前节点包装为状态结构体,使用
map记录已搜索过的状态。如果搜索时发现当前状态在此前被搜索过,则及时剪枝,停止该分支的搜索。具体实现细节参见core.cpp中dfs_loop和solve_loop函数。
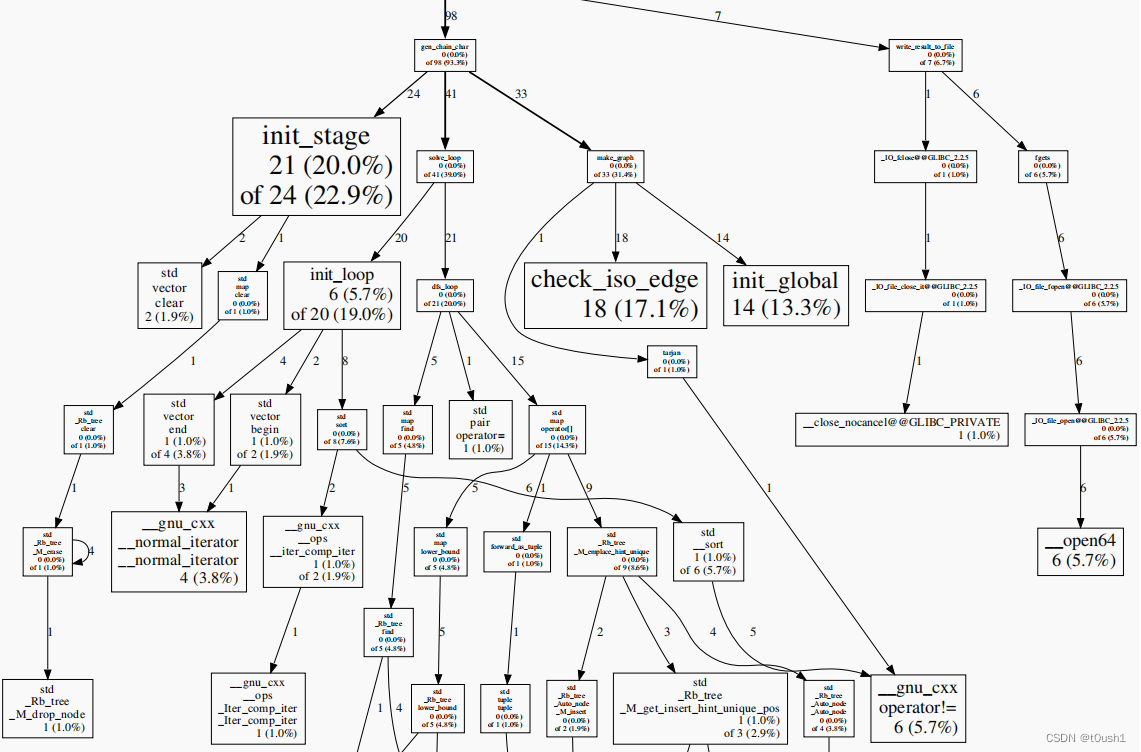
使用 gperftools 得到性能分析图如下,发现当样例规模较少(边数在 40 量级时),初始化占用了大部分的运算开销:
数据构造与测试
计算模块单元测试
9.计算模块部分单元测试展示。展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路。并将单元测试得到的测试覆盖率截图,发表在博客中。要求总体覆盖率到 90% 以上,否则单元测试部分视作无效。
测试框架
采用 googletest 编写单元测试,设置了 30 个测试点如下:
#define TEST_FUNC(suite, case_) TEST(suite, case_) { suite(#suite, #case_); }
TEST_FUNC(core_test, test01)
TEST_FUNC(core_test, test02)
TEST_FUNC(core_test, test03)
TEST_FUNC(core_test, test04)
TEST_FUNC(core_test, test05)
TEST_FUNC(core_test, test06)
TEST_FUNC(core_test, test07)
TEST_FUNC(core_test, test08)
TEST_FUNC(core_test, test09)
TEST_FUNC(core_test, test10)
TEST_FUNC(core_test, test11)
TEST_FUNC(core_test, test12)
TEST_FUNC(core_test, test13)
TEST_FUNC(core_test, test14)
TEST_FUNC(core_test, test15)
TEST_FUNC(core_test, test16)
TEST_FUNC(core_test, test17)
TEST_FUNC(core_test, test18)
TEST_FUNC(core_test, test19)
TEST_FUNC(core_test, test20)
TEST_FUNC(core_test, test21)
TEST_FUNC(core_test, test22)
TEST_FUNC(core_test, test23)
TEST_FUNC(core_test, test24)
TEST_FUNC(core_test, test25)
TEST_FUNC(core_test, test26)
TEST_FUNC(core_test, test27)
TEST_FUNC(core_test, test28)
TEST_FUNC(core_test, test29)
TEST_FUNC(core_test, test30)
TEST_FUNC 为自定义的宏函数,功能为利用 gtest 中的 TEST 宏定义测试函数,去调用自定义的测试函数(其名称与测试套件的名称相同),将测试套件名称与测试点名称以字符串的形式传给自定义测试函数。
对于 core 的单元测试,自定义的测试函数为 core_test,主要逻辑为加载并解析测试点,调用计算模块接口,检验结果正确性。
void core_test(const string &suite_name, const string &case_name) {
load_core_case(case_path(suite_name, case_name));
result[0] = nullptr;
if (mode == 'n') {
r = gen_chains_all(words, len, result, malloc);
} else if (mode == 'w') {
r = gen_chain_word(words, len, result, head, tail, reject, enable_cycle, malloc);
} else if (mode == 'c') {
r = gen_chain_char(words, len, result, head, tail, reject, enable_cycle, malloc);
} else {
throw runtime_error("mode error");
}
check();
free(result[0]);
}
数据构造
针对基本情况以及部分容易出错的特殊情况,我们手工构造了 30 个样例进行测试,这些样例均基于 10 个基本的有向图如下:
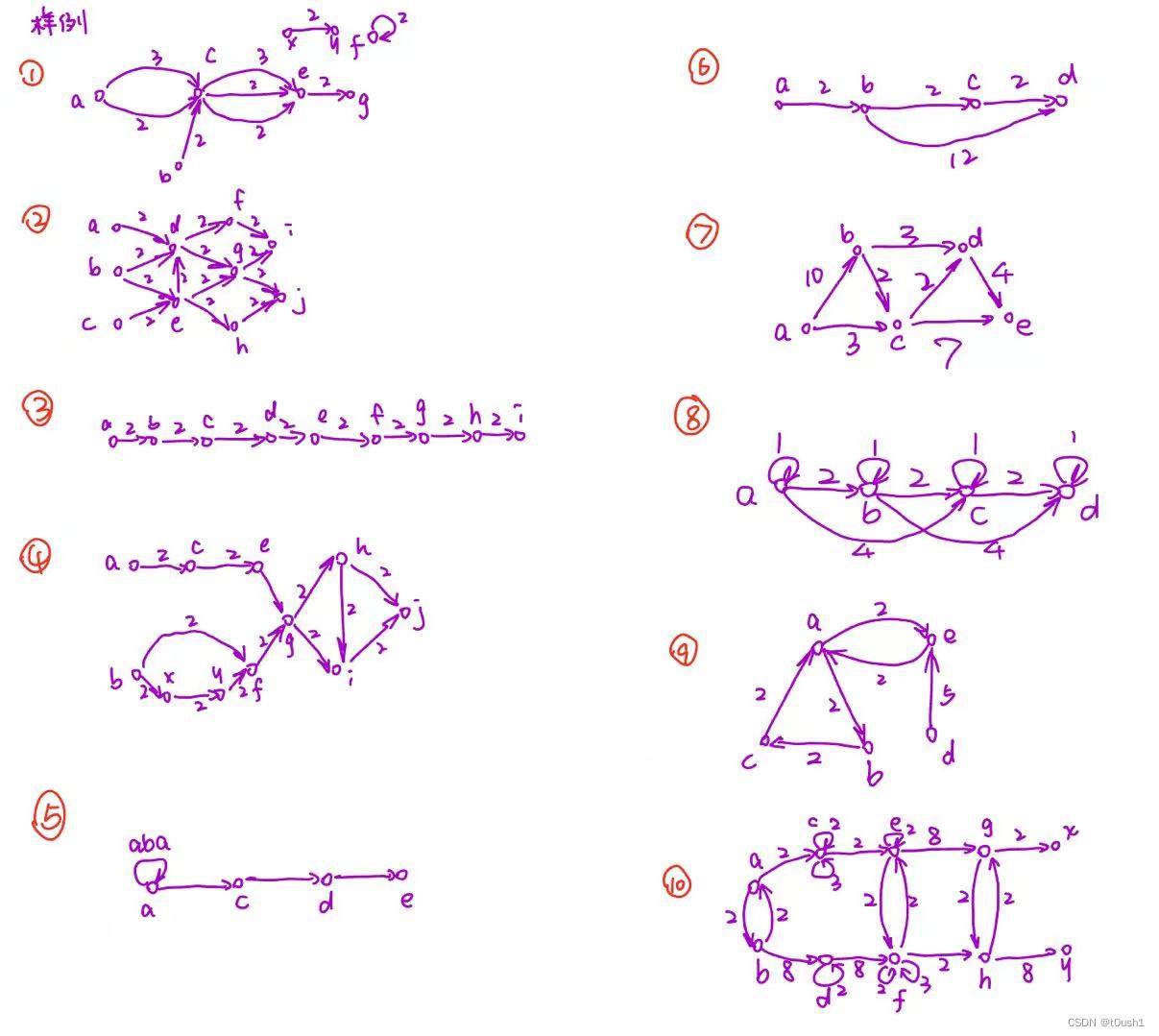
10 个基本图结合不同的参数,最终生成 30 个测试样例点,对应的数据构造表格如下:
| 数据样例 | 说明 | 对应图 | 期望返回值 |
|---|---|---|---|
| 1 | 无环,输出所有单词链 | 1 | 21 |
| 2 | 无环,输出所有单词链 | 2 | 43 |
| 3 | 无环,输出所有单词链 | 3 | 28 |
| 4 | 无环,最大单词数,指定单词链开头字母、结尾字母 | 2 | 2 |
| 5 | 无环,最大单词数,指定单词链开头字母、不允许出现的首字母 | 2 | 3 |
| 6 | 无环,最大单词数,指定单词链结尾字母、不允许出现的首字母 | 4 | 5 |
| 7 | 无环,最大单词数,指定单词链开头字母、结尾字母、不允许出现的首字母 | 4 | 3 |
| 8 | 无环,最大单词数,指定单词链结尾字母 | 5 | 4 |
| 9 | 无环,最大单词数,指定单词链开头字母 | 6 | 2 |
| 10 | 无环,最大字符数,指定单词链开头字母 | 6 | 2 |
| 11 | 无环,最大字符数 | 6 | 2 |
| 12 | 无环,最大字符数 | 7 | 3 |
| 13 | 无环,最大字符数,指定单词链不允许出现的首字母 | 7 | 3 |
| 14 | 无环,最大字符数,指定单词链开头字母 | 7 | 2 |
| 15 | 无环,最大字符数 | 8 | 7 |
| 16 | 无环,最大字符数,指定单词链结尾字母、不允许出现的首字母 | 8 | 3 |
| 17 | 无环,最大字符数,指定单词链开头字母、不允许出现的首字母 | 8 | 3 |
| 18 | 无环,最大字符数,指定单词链开头字母、结尾字母 | 8 | 3 |
| 19 | 有环,最大单词数 | 9 | 5 |
| 20 | 有环,最大单词数,指定单词链开头字母 | 9 | 5 |
| 21 | 有环,最大单词数,指定单词链不允许出现的首字母 | 9 | 4 |
| 22 | 有环,最大字符数,指定单词链不允许出现的首字母 | 9 | 3 |
| 23 | 有环,最大字符数,指定单词链结尾字母 | 9 | 4 |
| 24 | 有环,最大单词数 | 10 | 15 |
| 25 | 有环,最大单词数,指定单词链不允许出现的首字母 | 10 | 11 |
| 26 | 有环,最大单词数,指定单词链结尾字母 | 10 | 14 |
| 27 | 有环,最大单词数,指定单词链结尾字母、不允许出现的首字母 | 10 | 6 |
| 28 | 有环,最大字符数 | 10 | 12 |
| 29 | 有环,最大字符数,指定单词链不允许出现的首字母 | 10 | 14 |
| 30 | 有环,最大字符数,指定单词链结尾字母、不允许出现的首字母 | 10 | 8 |
SPJ 设计
special judge 的逻辑如下:
- 先判断返回值与答案是否相等
- 对于多条单词链
- 检查单词链是否重复
- 对于其中每条单词链
- 检查单词是否重复
- 检查单词是否能组成链
- 检查单词是否存在
- 对于单条单词链
- 检查是否满足
-h、-t、-j约束 - 检查单词是否重复
- 检查单词是否能组成链
- 检查单词是否存在
- 检查是否满足
special judge 的核心函数如下:
void check() {
ASSERT_EQ(r, ans);
if (result[0] == nullptr) {
return;
}
if (mode == 'n') {
char *split[100][100];
int split_len[100];
repeat_check(result, r);
split_result(split, split_len);
for (int i = 0; i < r; ++i) {
repeat_check(split[i], split_len[i]);
chain_check(split[i], split_len[i]);
exist_check(split[i], split_len[i]);
}
} else {
char_check(result, r);
repeat_check(result, r);
chain_check(result, r);
exist_check(result, r);
}
}
其中包含了四种检测函数,分别为:
repeat_check:利用set检测单词是否重复char_check:根据输入参数,检测是否满足字符约束chain_check:检测单词是否能组成链,即前一个单词的尾字母和后一个单词的首字母是否相等exist_check:检测单词是否存在于输入(words数组)中
代码覆盖率
我们在 win10+clion 环境下使用 gcov 和 lcov 测试代码覆盖率,执行手工生成基本数据与异常数据,得到代码覆盖率如下:
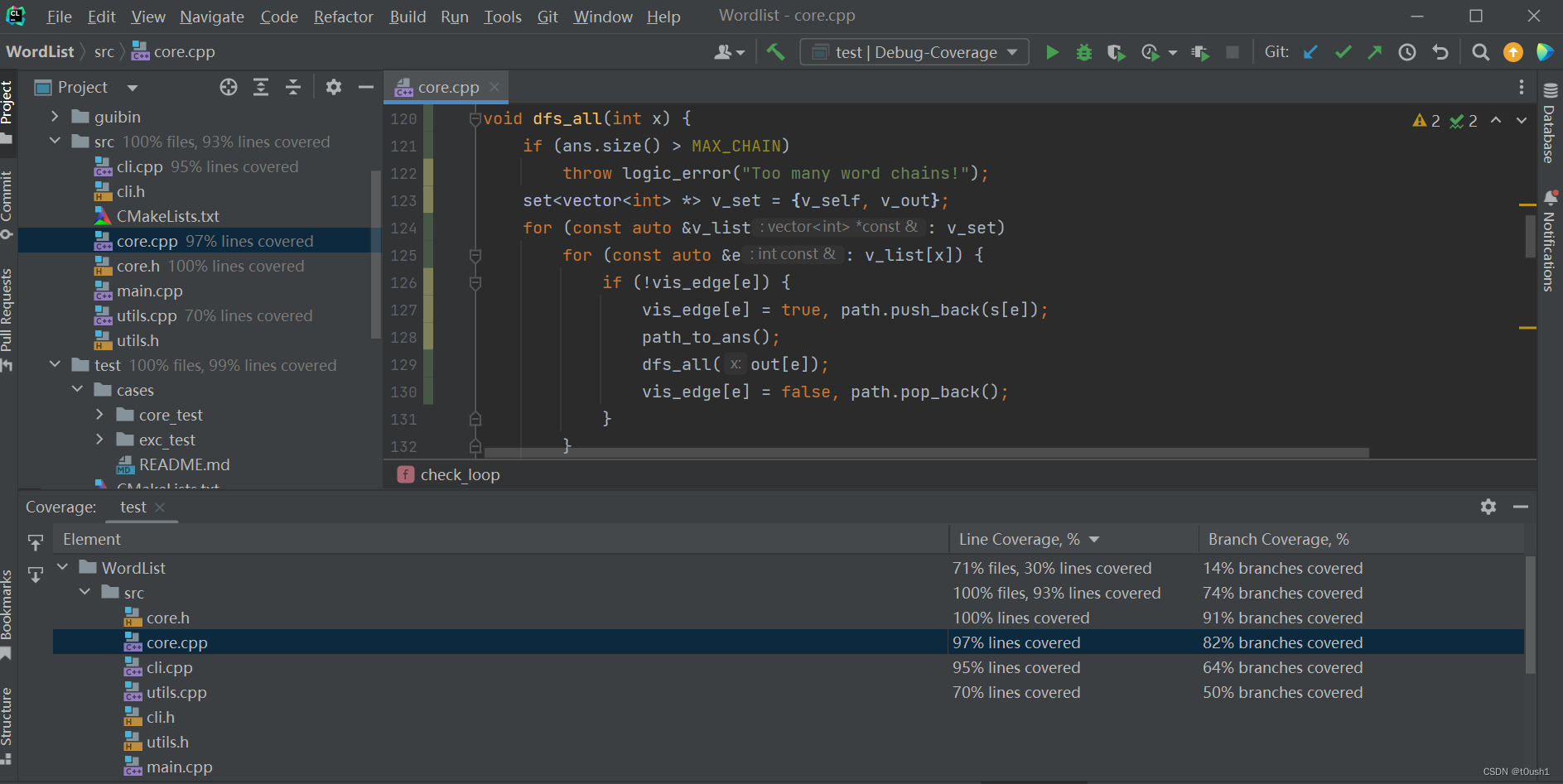
可以观察到在计算模块主要部分对应的代码 core.cpp 中,行覆盖率达到 97%,但是分支覆盖率仅有 82%。
分析原因,起初我们以为是我们构造的数据不够强,没有覆盖到所有可能运行的分支。我们针对没有完全覆盖到的分支刻意制造数据,但分支覆盖率仍然无法提高,依然存在大量行数的代码在测试中仅显示为”部分覆盖”,对应图中黄色部分。
后来发现,凡是使用 cpp 中 STL 的代码在测试中均显示为”部分覆盖”,其中包括但不限于所有 vector,string,map,set 的所有操作。
打开位于根目录下位于 cmake-build-debug-coverage/coverage/core.cpp.gcda##core.cpp.gcov 的文件,应该是测试框架下 core.cpp 对应的中间代码文件。与 core.cpp 对比,左侧 47-48 行对应右侧的 117-128 行,在每一条调用 cppSTL 的语句下面,编译器自动添加了 branch 语句,推测是测试框架编译时自动加入了 STL 内部异常处理的分支。
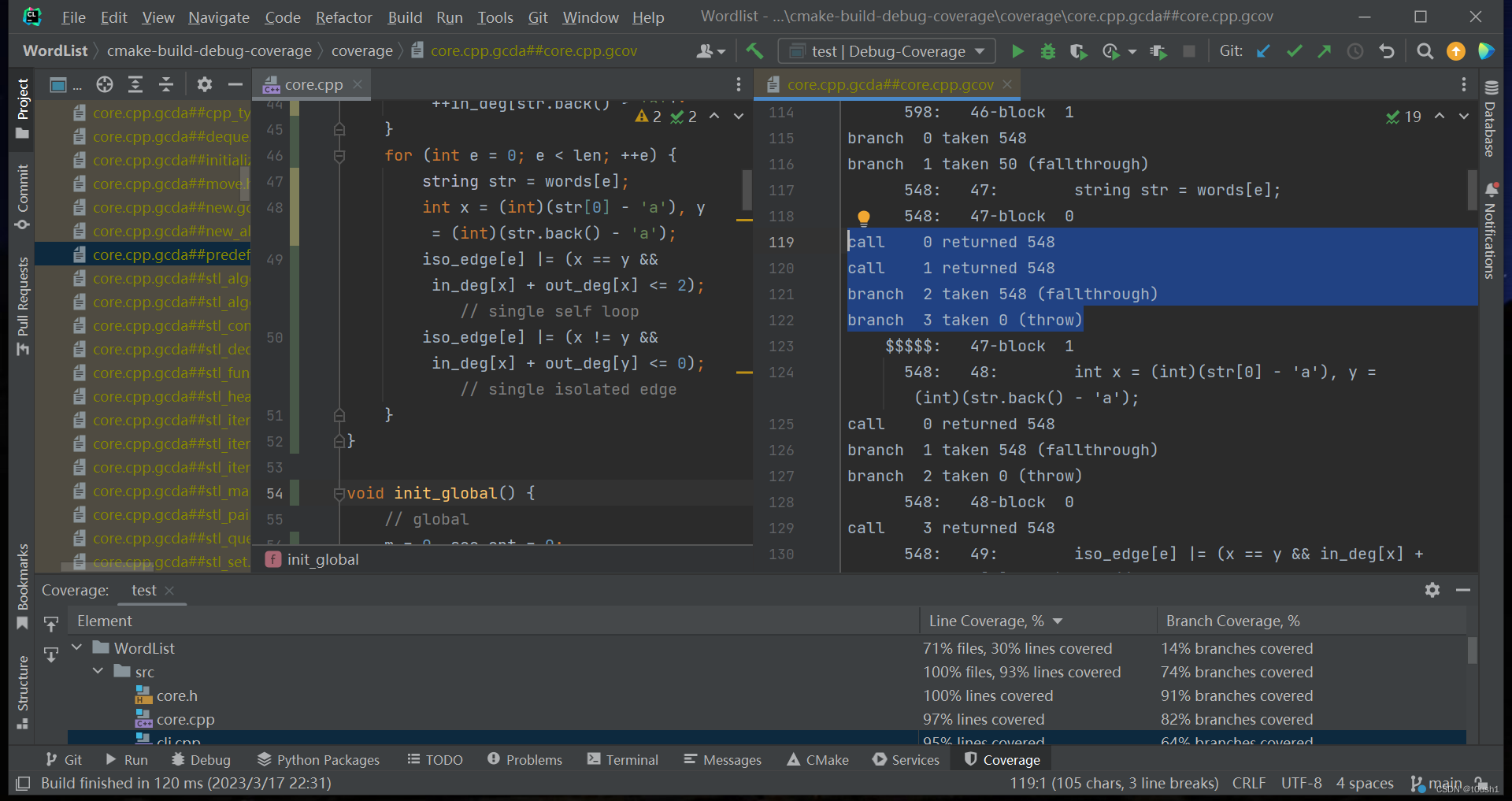
若上述假设成立,则在测试覆盖率时,异常部分对应的分支没有被触发,从而将调用 cppSTL 的语句判定为“部分覆盖”的语句,这是我认为较为合理的解释。
由于 cppSTL 内部代码无法更改,并且计算模块的先验条件保证 cppSTL 的异常不会触发,因此在 gtest 测试框架下,覆盖率无法达到 90%。在 core.cpp 文件中,被误判为“部分覆盖”的语句约为 40 行;去除定义和注释后,文件的行数不超过 400 行。如果将这部分误判的语句修改为“完全覆盖”,则分支覆盖率可以 82% 基础上提升至少 10%,达到超过 90% 的分支覆盖率。
异常处理及测试
10.计算模块部分异常处理说明。在博客中详细介绍每种异常的设计目标。每种异常都要选择一个单元测试样例发布在博客中,并指明错误对应的场景。
异常种类
-
core 异常
错误类型 错误字符串 说明 a Word ring detected, at least two self ring on one node!在没有-r情况下,有至少一个点上有至少两个自环 b Word ring detected, at least one scc has more than two nodes!在没有-r情况下,强连通分量个数少于26个(注:优先检查上面自环的错误) c Too many word chains!单词链个数超过20000 -
cli 异常
错误类型 错误字符串 说明 d flag not recognizedflag无法识别,例如-、-g2、-a e basic flag not exist-n、-w、-c均不存在 f basic flag conflict-n、-w、-c存在多个 g flag-N conflict-n与-h、-t、-j冲突 h file name not exist基本 flag 后无参数(文件名) i char not exist-h、-t、-j后无字符 j char not recognized字符无法识别,例如1、ab k arg exceed多余参数,例如-r后有参数、或参数前无 flag l file not exist文件不存在 m file can't open文件不无法打开 n memory alloc failed内存申请失败
异常测试
采用 googletest 编写单元测试,设置了 14 个测试点,测试点的首字母对应上面的每种错误类型。
TEST_FUNC(exc_test, a_two_self_ring)
TEST_FUNC(exc_test, b_ring)
TEST_FUNC(exc_test, c_result_too_long_1)
TEST_FUNC(exc_test, c_result_too_long_2)
TEST_FUNC(exc_test, d_flag_not_recognized)
TEST_FUNC(exc_test, e_basic_flag_not_exist)
TEST_FUNC(exc_test, f_basic_flag_conflict)
TEST_FUNC(exc_test, g_flagN_conflict)
TEST_FUNC(exc_test, h_file_name_not_exist)
TEST_FUNC(exc_test, i_char_not_exist)
TEST_FUNC(exc_test, j_char_not_recognized)
TEST_FUNC(exc_test, k_arg_exceed)
TEST_FUNC(exc_test, l_file_not_exist)
TEST_FUNC(exc_test, m_file_cant_open)
对于异常处理的单元测试,自定义的测试函数为 exc_test,主要逻辑为加载并解析测试点,调用计算模块接口,检验抛出异常的类型。
void exc_test(const string &suite_name, const string &case_name) {
chdir(suite_path(suite_name).data());
load_exc_case(case_path(suite_name, case_name));
string msg;
try {
throw logic_error(to_string(cli(argc, argv, false)));
} catch (const logic_error &e) {
ASSERT_STREQ(e.what(), exc_msg);
}
free_resource();
remove("solution.txt");
}
对拍测试
这并不是作业里面要求的问题,但我们认为有必要对其进行说明。
由于单元测试和手动构造的样例并不能完全保证程序的正确性,因此我们编写了数据生成器,并搭建了评测机与他人对拍。
数据构造
单个数据的生成函数为:
def generate(num: int, steep: bool, repeat: bool, mix: bool, loop: bool) -> str:
"""
:param num: 单词数量,代表数据规模
:param steep: 单词长度差异大
:param repeat: 单词允许重复
:param mix: 输入中插入无关字符
:param loop: 允许环
:return: 测试数据
"""
根据函数的参数不同,我们构造了 5 种不同特征的数据,并将编写成配置文件,以便批量生成。配置文件的内容及说明如下:
{
"random": {
"word_num": [0, 1, 10, 100, 1000],
"case_num": [1, 1, 100, 100, 100],
"loop": false
},
"steep": { // 测试集名称
"word_num": [10, 100, 1000], // 单词数量,可以有多种规模
"case_num": [10, 100, 100], // 每种规模数据对应的测试点数量
"steep": true, // steep 参数的值,缺省时表示随机
"repeat": false, // repeat 参数的值,缺省时表示随机
"mix": false, // mix 参数的值,缺省时表示随机
"loop": false // loop 参数的值,缺省时表示随机
},
"repeat": {
"word_num": [0, 1, 10, 100, 1000],
"case_num": [2, 2, 50, 50, 50],
"steep": false,
"repeat": true,
"mix": false,
"loop": false
},
"mix": {
"word_num": [0, 1, 10, 100, 1000],
"case_num": [2, 2, 50, 50, 50],
"steep": false,
"repeat": false,
"mix": true,
"loop": false
},
"loop": {
"word_num": [10, 50],
"case_num": [100, 100],
"steep": false,
"repeat": false,
"mix": false,
"loop": true
}
}
解析配置文件和批量生成数据的核心代码如下:
with open(sys.path[0] + "/config.json", "r") as f:
config = json.load(f)
for name, mode in config.items():
assert len(mode["word_num"]) == len(mode["case_num"])
for i in range(len(mode["word_num"])):
for j in range(mode["case_num"][i]):
n = mode["word_num"][i]
st = mode["steep"] if "steep" in mode else randint(0, 1)
re = mode["repeat"] if "repeat" in mode else randint(0, 1)
mi = mode["mix"] if "mix" in mode else randint(0, 1)
lo = mode["loop"] if "loop" in mode else randint(0, 1)
file_name = f"{name}_{n}_{j}{'_r' if lo else ''}.txt"
with open(file_name, "w") as f:
f.write(generate(n, st, re, mi, lo))
对于每个测试样例,根据是否带环会生成两组或三组不同的命令行参数来运行,分别测试 -n、-w、-c 三种模式;对于 -w 和 -c 模式,-h、-t、-j 参数随机生成,-r 参数取决于是否带环。
评测机
利用 Popen 进行多进程并发测试,对于大规模数据可节省一定时间。
利用 ctypes.windll 获取程序运行时间和 CPU 时间,便于比较性能。
special judge 逻辑与单元测试的几乎一致,只是实现语言换成了 python,故不赘述。
松耦合测试
在博客中指明合作小组两位同学的学号,分析两组不同的模块合并之后出现的问题,为何会出现这样的问题,以及是如何根据反馈改进自己模块的。
合作小组的成员:
- 王小鸽:20373117
- 王哲:20373209
由于在开发前就约定了接口设计、异常处理和内存分配回收规则等,因此交换模块时并未遇到问题。
交换结果位于 https://github.com/cccvs/WordList/tree/dev-combine 中的 combine 文件夹下,其中 our-core 目录保存的是我们的计算模块和他们的 GUI 模块与单元测试模块,their-core 目录反之。
附上他们 GUI 模块和单元测试模块调用我们计算模块的运行截图:
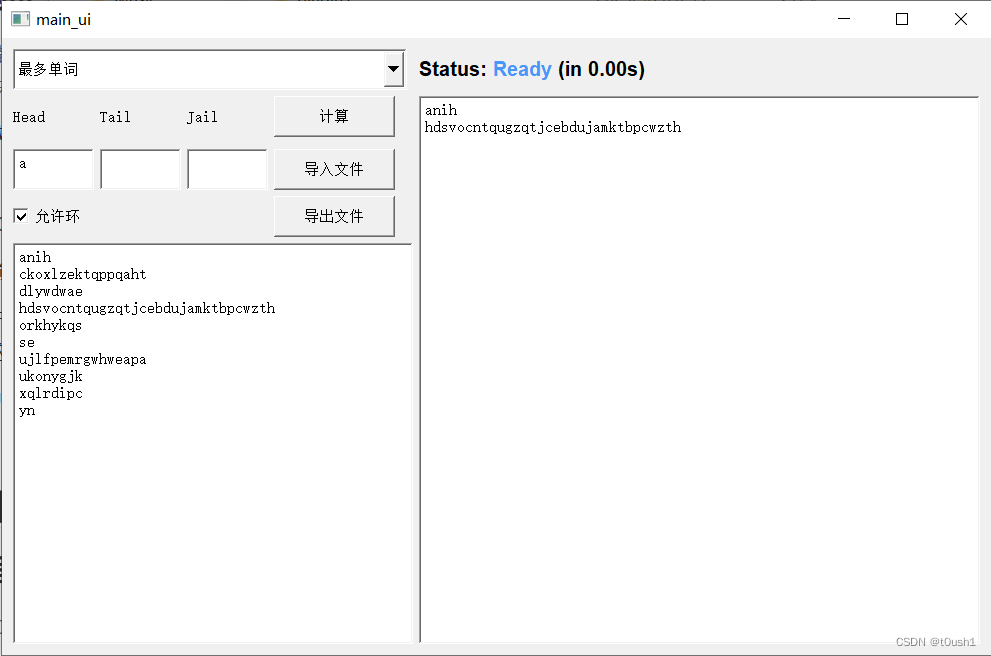
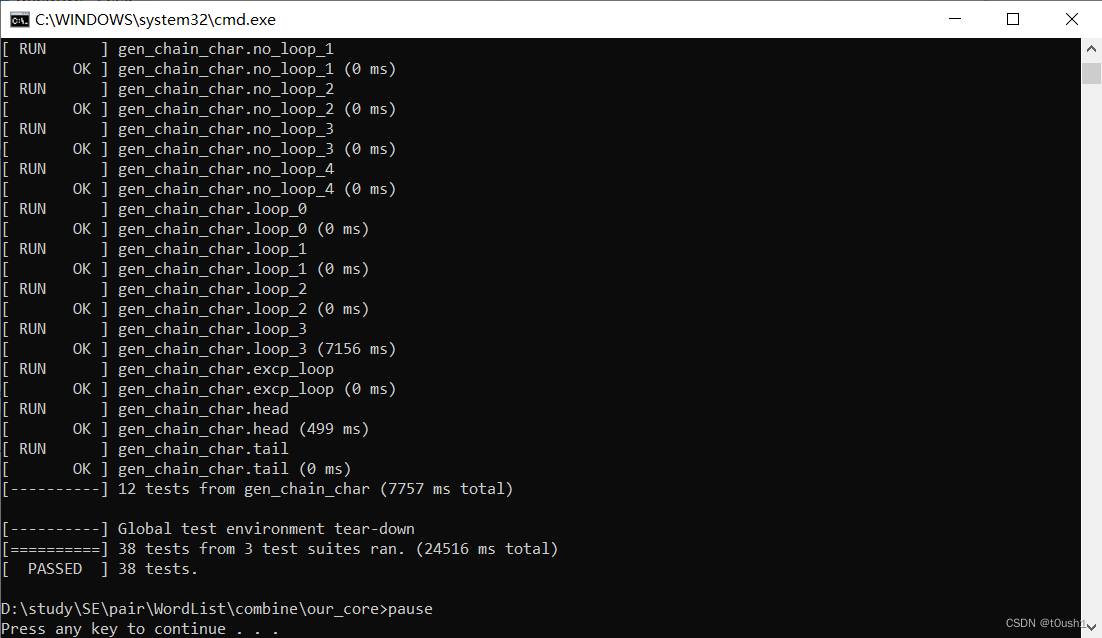
结对编程相关
契约编程
8.阅读 Design by Contract,Code Contract 的内容,并描述这些做法的优缺点,说明你是如何把它们融入结对作业中的。
- http://en.wikipedia.org/wiki/Design_by_contract
- http://msdn.microsoft.com/en-us/devlabs/dd491992.aspx
契约式设计是一种设计计算机软件的方法。这种方法要求软件设计者为软件组件定义正式的,精确的并且可验证的接口,为传统的抽象数据类型又增加了先验条件、后验条件和不变式。
优点:可以减少错误的发生,使 bug 定位更加容易;开发时要求更加明确;便于做单元测试。
缺点:设置契约需要额外的时间成本;一旦违反契约,程序将无法运行;检查契约的过程可能会影响程序性能。
在正式进行开发前,我们约定好了接口设计、异常处理和内存分配回收规则等。以接口 int gen_chains_all(char *words[], int len, char *result[], void *my_malloc(size_t)) 为例,words 需满足调用前后元素的值不改变,result 需满足在计算模块内用 my_malloc 分配内存,在计算模块外由调用者回收。
结对过程
13.描述结对的过程,提供两人在讨论的结对图像资料(比如 Live Share 的截图)。关于如何远程进行结对参见作业最后的注意事项。
我们在主楼南侧二楼公共学习区进行结对编程,图片如下:

优缺点分析
14.看教科书和其它参考书,网站中关于结对编程的章节,例如:http://www.cnblogs.com/xinz/archive/2011/08/07/2130332.html ,说明结对编程的优点和缺点。同时描述结对的每一个人的优点和缺点在哪里(要列出至少三个优点和一个缺点)。
结对编程的优点
- 在开发层次,结对编程能提供更好的设计质量和代码质量,两人合作解决问题的能力更强。
- 两人合作还有相互激励的作用,看到别人的思路和技能,得到实时的讲解,受到激励,从而努力提高自己水平,提出更多创意。
- 结对编程让两个人所写的代码不断地处于“复审”的过程,可以及时地发现问题和解决问题。
结对编程的缺点
- 两人磨合需要时间成本。
- 对于较简单的任务或需要敏捷开发时,效率可能不如两人分工编程。
自己的优点
- 擅长数据构造和搭评测机。
- 擅长设计代码架构。
- 熟悉 Qt 和 GUI 的绘制。
自己的缺点
- 算法水平较弱。
- 不爱写文档和博客。
- 对 cmake 不太熟悉。
队友的优点
- 擅长算法设计和优化。
- 对 c++ 和 STL 的使用较为熟悉。
- 按时完成 dll。
队友的缺点
- 对 cmake 不太熟悉。















 194
194











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









