







1. 窗口函数概述
什么是窗口函数?
窗口函数是MySQL8.0新增的,窗口函数又称开窗函数,属于MySQL的一大特点。
非聚合窗口函数是相对于聚函数来说的。聚合函数是对一组数据计算后返回单个值(即分组),非聚合函数一次只会处理一行数据。窗口聚合函数在行记录上计算某个字段的结果时,可将窗口范围内的数据输入到聚合函数中,并不改变行数。
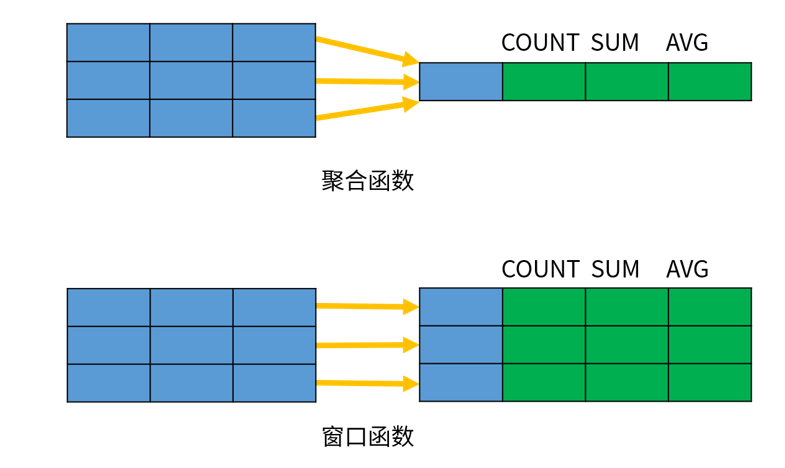
窗口函数有什么用?
窗口函数可以对数据库数据进行实时分析处理,比如市场分析、创建财务报表、创建计划等日常性商务工作。
窗口函数分为哪几种?
窗口函数分为以下几种:
- 序号函数
- ROW_NUMBER() —— 排序:1,2,3
- RANK0 —— 排序: 11,3
- DENSE_RANK() —— 排序: 1,1,2
- 分布函数
- PERCENT_RANK() —— (rank-1) /(rows-1)
- CUME_DIST() —— <=当前rank值的行数/总行数
- 前后函数
- LAG (expr,n) —— 返回当前行的前n行的expr的值
- LEAD (expr,n) —— 返回当前行的后n行的expr的值
- 头尾函数
- FIRST_VALUE(expr) —— 返回第一个expr的值
- LAST_VALUE (expr) —— 返回最后一个expr的值
- 其他函数
- NTH_VALUE (expr,n) —— 返回第n个expr的值
- NTILE (n) —— 将有序数据分为n个桶,记录等级数

窗口函数的基本用法是怎么样的?
<窗口函数> OVER ( [PARTITION BY <列清单>] ORDER BY <排序用列清单>)
over关键字用来指定函数执行的窗口范围,若后面括号中什么都不写,则意味着窗口包含满足WHERE条件的所有行,窗口函数基于所有行进行计算;如果不为空,则支持以下4中语法来设置窗口。
-
window_name:给窗口指定一个别名。如果SQL中涉及的窗口较多,采用别名可以看起来更清晰易读
-
partition by子句:窗口按照哪些字段进行分组,窗口函数在不同的分组上分别执行,**它的作用类似于GROUP BY分组。**如果省略了 PARTITION BY,所有的数据作为一个组进行计算
-
order by子句:按照哪些字段进行排序,窗口函数将按照排序后的记录顺序进行编号
-
frame子句:frame是当前分区的一个子集,子句用来定义子集的规则,通常用来作为滑动窗口使用
2. 序号函数
序号函数有三个,分别是ROW_NUMBER()、RANK()、DENSE_RANK(),可以用来实现分组排序,并添加序号
格式如下
row_number()|rank()|dense_rank() over (
partition by ...
order by ...
)
这里分别使用三种序号函数进行查询
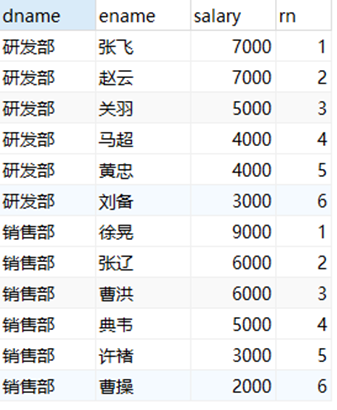
-- 对每个部门的员工按照薪资排序,并给出排名
select
dname,
ename,
salary,
row_number() over(partition by dname order by salary desc) as rn
from employee;
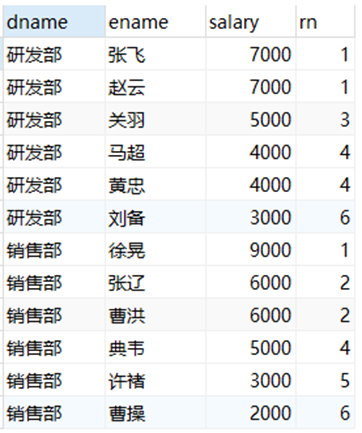
-- 对每个部门的员工按照薪资排序,并给出排名 rank
select
dname,
ename,
salary,
rank() over(partition by dname order by salary desc) as rn
from employee;
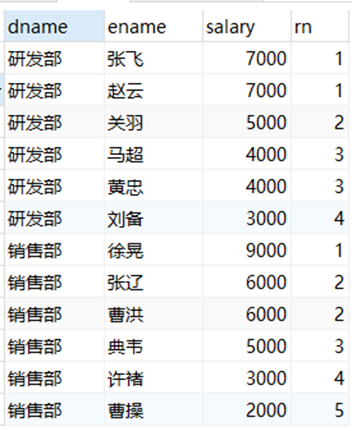
-- 对每个部门的员工按照薪资排序,并给出排名 dense-rank
select
dname,
ename,
salary,
dense_rank() over(partition by dname order by salary desc) as rn
from employee;
观察上面各个序号函数的区别是什么?
- ROW_NUMBER():顺序排序——1、2、3
- RANK():并列排序,跳过重复序号——1、1、3
- DENSE_RANK():并列排序,不跳过重复序号——1、1、2
3. 分布函数
分布函数包括PERCENT_RANK()和CUME_DIST()
1)PERCENT_RANK()函数将某个数值在数据集中的排位作为数据集的百分比值返回,此处的百分比值的范围为 0 到 1
- 用途:每行按照公式(rank-1) / (rows-1)进行计算。其中,rank为RANK()函数产生的序号,rows为当前窗口的记录总行数
- 应用场景:不常用
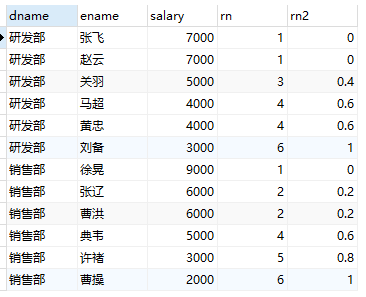
select
dname,
ename,
salary,
rank() over(partition by dname order by salary desc ) as rn,
percent_rank() over(partition by dname order by salary desc ) as rn2
from employee;
2) CUME_DIST
- 用途:分组内小于、等于当前rank值的行数 / 分组内总行数
- 应用场景:查询小于等于当前薪资(salary)的比例
select
dname,
ename,
salary,
cume_dist() over(order by salary) as rn1, -- 没有partition语句 所有的数据位于一组
cume_dist() over(partition by dname order by salary) as rn2
from employee;
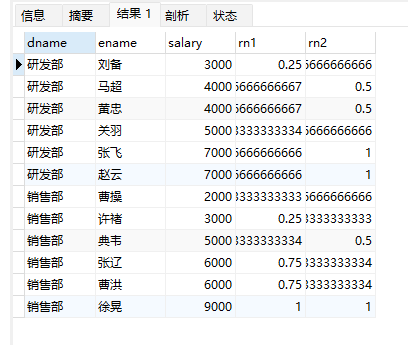
这里需要解释一下,就rn1而言
首先组共12个人(因为没有partition语句 所有的数据位于一组),刘备这行数据对应的rn1是0.25
大于等于3000的数据共有3条,因此是3/12=0.25
4. 前后函数
前后函数有LAG (expr,n)和LEAD (expr n)。
Lag()和Lead()分析函数可以在同一次查询中取出同一字段的前N行的数据(Lag)和后N行的数据(Lead)作为独立的列。
在实际应用当中,若要用到取今天和昨天的某字段差值时,Lag()和Lead()函数的应用就显得尤为重要。当然,这种操作可以用表的自连接实现,但是LAG()和LEAD()与left join、rightjoin等自连接相比,效率更高,SQL更简洁。
- 用途:返回位于当前行的前n行(LAG(expr,n))或后n行(LEAD(expr,n))的expr的值。
- 应用场景:查询前1名同学的成绩和当前同学成绩的差值。
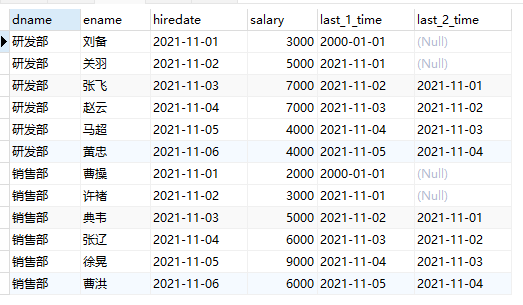
/*
last_1_time: 指定了往上第1行的值,default为'2000-01-01'
第一行,往上1行为null,因此取默认值 '2000-01-01'
第二行,往上1行值为第一行值,2021-11-01
第三行,往上1行值为第二行值,2021-11-02
last_2_time: 指定了往上第2行的值,为指定默认值
第一行,往上2行为null
第二行,往上2行为null
第四行,往上2行为第二行值,2021-11-01
第七行,往上2行为第五行值,2021-11-02
*/
-- lag的用法
select
dname,
ename,
hiredate,
salary,
lag(hiredate,1,'2000-01-01') over(partition by dname order by hiredate) as last_1_time,
lag(hiredate,2) over(partition by dname order by hiredate) as last_2_time
from employee;
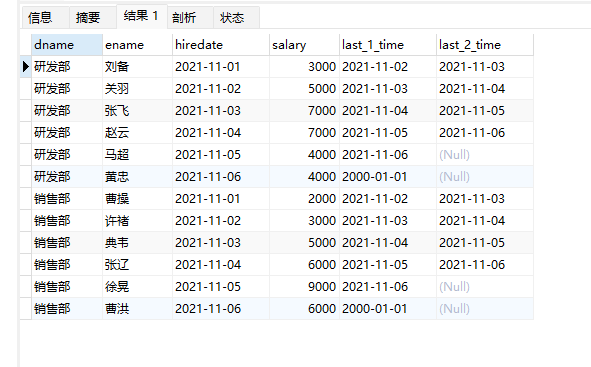
-- lead的用法
select
dname,
ename,
hiredate,
salary,
lead(hiredate,1,'2000-01-01') over(partition by dname order by hiredate) as last_1_time,
lead(hiredate,2) over(partition by dname order by hiredate) as last_2_time
from employee;
5. 头尾函数
头尾函数包括:LAST_VALUE (expr)与FIRST_VALUE(expr)
-
返回第一个expr的值:FIRST_VALUE(expr)
-
返回最后一个expr的值:LAST_VALUE(expr)
-
用途:返回第一个(FIRST_VALUE(expr))或最后一个(LAST_VALUE(expr))expr的值
-
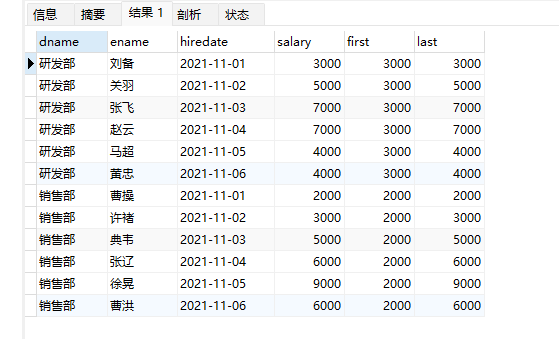
应用场景:截止到当前,按照日期排序查询第1个入职和最后1个入职员工的薪资
-- 注意, 如果不指定ORDER BY,则进行排序混乱,会出现错误的结果
select
dname,
ename,
hiredate,
salary,
first_value(salary) over(partition by dname order by hiredate) as first,
last_value(salary) over(partition by dname order by hiredate) as last
from employee;
6. 其他函数
其他函数包括NTH_VALUE (expr,n)与NTILE (n)
-
NTH_VALUE (expr,n) —— 返回第n个expr的值
-
NTILE (n) —— 将有序数据分为n个桶,记录等级数
-
用途:将分区中的有序数据分为n个等级,记录等级数
-
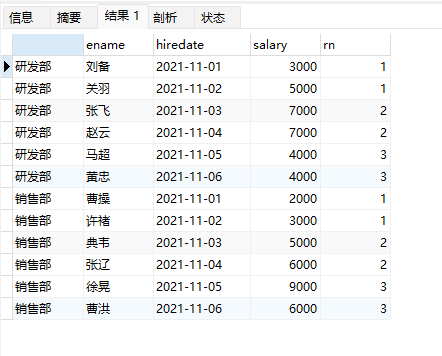
应用场景:将每个部门员工按照入职日期分成3组
-- 根据入职日期将每个部门的员工分成3组
select
dname,
ename,
hiredate,
salary,
ntile(3) over(partition by dname order by hiredate ) as rn
from employee;
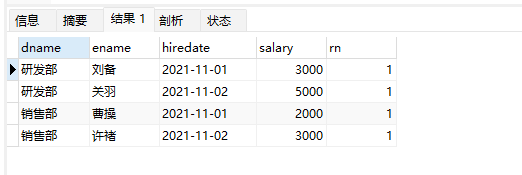
-- 取出每个部门的第一组员工
select
*
from
(
SELECT
dname,
ename,
hiredate,
salary,
NTILE(3) OVER(PARTITION BY dname ORDER BY hiredate ) AS rn
FROM employee
)t
where t.rn = 1;
参考:
















 495
495











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











