







文章目录
1. 分词算法概述
分词算法是将文本序列分割成有意义的单元(如词、子词或字符)的过程,这是自然语言处理(NLP)中的基础步骤。分词算法的种类繁多,可以根据其核心思想、处理的语言以及具体技术进行分类。总的来说,分词算法可以大致分为以下几个主要类别:
1.1 基于词典的(或基于规则的)分词算法
- 这类方法依赖于一个预先构建好的词典。它们通过将输入文本与词典中的词条进行匹配来识别词语。
- 常见算法:
- 最大匹配法 (Maximum Matching, MM):从一个方向(通常是左到右,即正向最大匹配 FMM;或右到左,即逆向最大匹配 RMM)扫描文本,试图匹配词典中最长的词。
- 双向最大匹配法 (Bi-directional Maximum Matching, BMM):同时进行正向和逆向最大匹配,然后根据一些规则(如词数最少、歧义最少等)选择最佳结果。
- 全切分/最短路径法:将句子中所有可能的词都找出来,构成一个词图,然后使用类似 Dijkstra 等算法寻找最优路径(如词数最少)。
- 特点:实现简单,对于词典覆盖的词语效果较好。但对未登录词(词典中没有的词)和歧义处理能力较弱。
1.2 基于统计的(或基于机器学习的)分词算法
- 这类方法利用大量已分词的语料库进行训练,从中学习词语切分的统计规律。
- 常见模型/算法:
- N-gram 语言模型:通过计算相邻N个字/词出现的概率来判断成词的可能性。
- 隐马尔可夫模型 (Hidden Markov Model, HMM):将分词看作是一个序列标注问题,通过观测到的字序列来预测隐藏的词边界状态序列(如B-开始, M-中间, E-结束, S-单字成词)。
- 条件随机场 (Conditional Random Fields, CRF):也是一种序列标注模型,与HMM相比,CRF可以考虑更多的上下文特征,通常在分词任务上表现更好。
- 特点:对未登录词有一定的识别能力,效果通常优于纯基于词典的方法,但依赖大规模高质量的标注语料。
1.3 基于深度学习的分词算法
- 近年来,随着深度学习的发展,基于神经网络的模型在分词任务上也取得了显著成果。这些方法通常也将分词视为序列标注任务。
- 常见模型:
- 循环神经网络 (RNN) / 长短期记忆网络 (LSTM) / 门控循环单元 (GRU) + CRF。
- Transformer / BERT 等预训练语言模型进行微调。
- 特点:能够自动学习复杂的特征,端到端地进行分词,在很多情况下能达到目前最好的性能,但需要大量的计算资源和数据。
1.4 子词(Subword)分词算法
- 这类算法主要用于处理词表大小、未登录词以及罕见词等问题,尤其在神经机器翻译和大规模语言模型中广泛应用。它们将词切分成更小的有意义的单元。
- 常见算法:
- 字节对编码 (Byte Pair Encoding, BPE):通过迭代合并最高频的字节对或字符对来构建子词词表。
- WordPiece:与BPE类似,但合并的标准是最大化训练数据的似然值,BERT等模型使用。
- Unigram Language Model (ULM):从一个较大的初始词表开始,根据语言模型概率迭代地裁剪词表,以优化整体可能性。
- SentencePiece:一个开源的子词工具包,支持BPE和Unigram,并且可以直接处理原始文本流,无需预分词。
- 特点:有效减少词表大小,能表示几乎所有词(包括未登录词),并能捕捉词的形态结构。
1.5 混合分词算法
- 在实践中,常常会结合不同方法的优点,例如先用词典进行初步分词,再用统计模型处理歧义和未登录词。
1.6 针对不同语言的特点
- 英文等空格分隔语言:分词相对简单,主要依据空格和标点符号进行切分。 后续可能需要词形还原(Lemmatization)和词干提取(Stemming)等步骤。
- 中文、日文等无明显分隔符语言:分词更具挑战性,上述的词典、统计、深度学习方法都是解决这些语言分词问题的重要手段。 日文分词工具如MeCab、Kuromoji等也应用了类似CRF等技术。
2. Byte-Pair Encoding (BPE) 分词
2.1 主要思想
BPE 的核心目标是找到一种高效的方式,将文本切分成既能覆盖大量词汇,又能有效处理未登录词(OOV)和罕见词,同时控制词汇表大小的单元(token)。这些 token 最终会被转换为整数 ID,供大规模语言模型(LLM)使用。
- 从字符/字节开始:算法的起点是最基本的单元。对于多语言或复杂字符集,直接使用字节(0-255)作为初始单元更为通用,避免了对Unicode字符的复杂处理。
- 减少冗余与信息聚合:“n->n的数量关系"和"冗余"问题正是BPE试图解决的。通过合并高频字节对,BPE能够将常见的字符序列(如"ing”, “tion”, “est”)或整个高频词(如"the", “is”)表示为单个 token。这样,像 “apple” 这样的词可能被切分成
["ap", "ple"]或保持为["apple"](如果 “apple” 足够高频并被学习为一个单元),而不是['a', 'p', 'p', 'l', 'e']这样五个独立的ID。这大大减少了序列长度并保留了更多语义信息在单个 token 中。 - GPT分词示例:GPT分词倾向于将整个词分为一个token(如果该词常见)或分成有意义的子词是对的。这正是BPE这类子词切分算法的优势。例如,“unbelievably” 可能会被切分成
["un", "believ", "ably"],每个部分都是一个有意义的子词单元。
2.2 关于字节和初始词汇表
- 256个基本字节:这256个值构成了BPE词汇表的"基础层"。任何文本首先都可以被看作是这些字节的序列。
- 原始 GPT-2 BPE 的"缺点":GPT-2的BPE在预处理时,会将词与词之间的空格视为词的一部分(通常是词的前缀,例如 " apple" 而不是 “apple” 后跟一个单独的空格token)。这样做的好处是解码时可以自然恢复空格,但确实使得初始的单字节映射看起来像是双字符。例如,字节
b'a'(ASCII 97) 可能在词汇表中映射为类似' a'的字符串表示(如果它前面经常是空格)。tiktoken等后来的实现对这一点做了更清晰的处理。
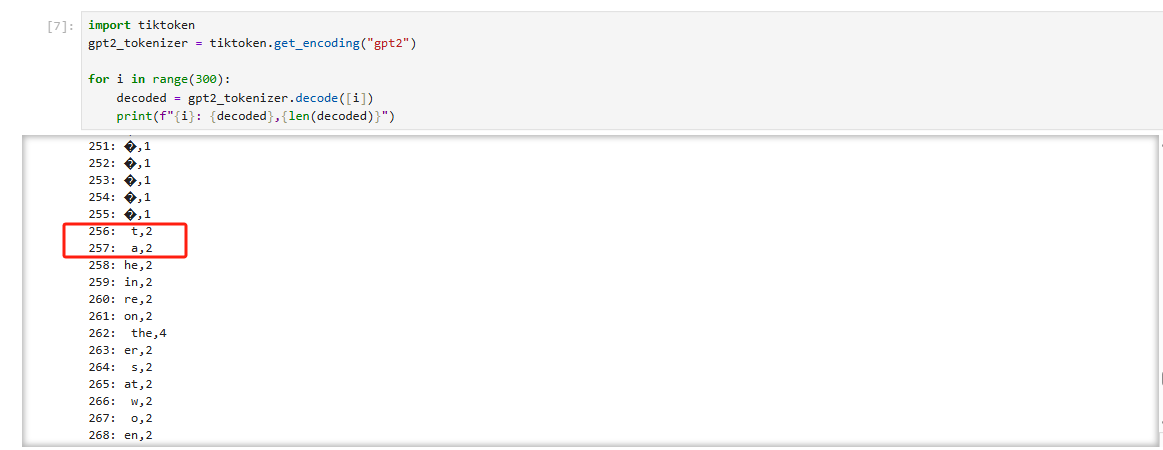
2.3 算法流程 (BPE Training)
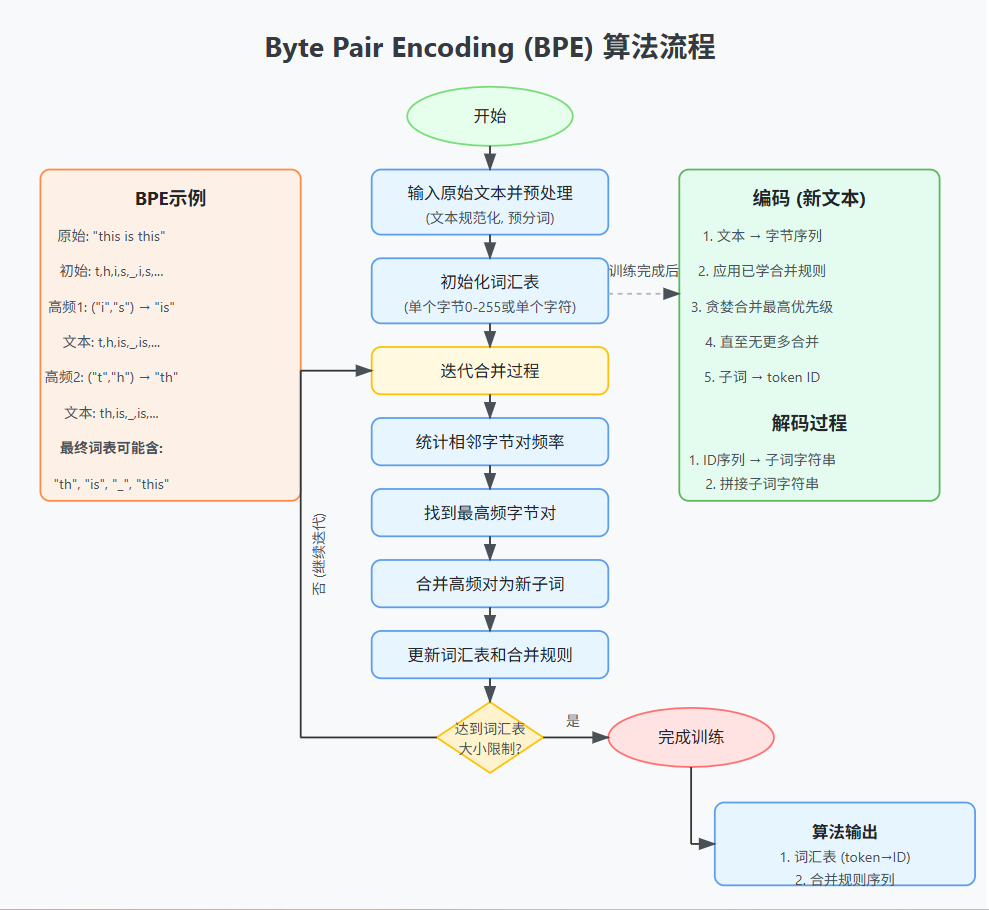
2.3.1 初始化 (Initialization)
- 输入: 大量的原始文本数据。
- 预处理 (可选但常见):
- 文本规范化 (Unicode normalization, lowercasing等)。
- 预分词 (Pre-tokenization): 对于某些BPE变体(如原始GPT-2的BPE或WordPiece),文本会先按空格或标点符号切分成"词"的列表。然后BPE在这些词的内部进行。SentencePiece等工具则可以直接处理原始文本流,将空格也视为一种待学习的字符。
- 初始词汇表: 通常由单个字节(0-255)组成,或者如果进行了预分词,则由语料中所有单个字符组成。
2.3.2 迭代合并 (Iterative Merging)
- 重复直到达到词汇表大小上限或无高频对可合并:
- a. 统计字节对频率 (Count Byte Pairs):
- 在当前文本表示(或所有词的当前切分状态)中,统计所有相邻字节/子词对的出现频率。
例如,如果文本是["t", "h", "i", "s", "_", "i", "s"],则字节对有("t", "h"),("h", "i"),("i", "s"),("s", "_"),("_", "i"),("i", "s")。
- 在当前文本表示(或所有词的当前切分状态)中,统计所有相邻字节/子词对的出现频率。
- b. 找到最高频对 (Find Most Frequent Pair):
- 从所有统计到的字节对中,选出出现次数最多的那个,例如
("i", "s")。
- 从所有统计到的字节对中,选出出现次数最多的那个,例如
- c. 合并字节对 (Merge Pair):
- 在文本中,将所有出现的该最高频对(如
("i", "s"))替换为一个新的、单一的子词单元(如"is")。
- 在文本中,将所有出现的该最高频对(如
- d. 更新词汇表 (Update Vocabulary):
- 将这个新的子词单元(如
"is")及其对应的ID(例如,如果基础字节是0-255,新ID从256开始递增)添加到词汇表中。这个合并规则('i', 's') -> 'is'也会被记录下来,这构成了BPE的"merges"信息。
- 将这个新的子词单元(如
- a. 统计字节对频率 (Count Byte Pairs):
2.3.3 停止条件 (Stopping Criteria)
- 达到预设的词汇表大小 (vocab_size),这是一个重要的超参数。
- 或者,没有字节对的频率超过某个阈值(例如,所有字节对只出现一次),进一步合并无意义。
2.3.4 输出 (Training Output)
- 词汇表 (Vocabulary): 一个从子词字符串到整数ID的映射 (e.g.,
{"a": 0, ..., "z": 25, "is": 256, "th": 257, ...}). - 合并规则 (Merges): 一个有序列表,记录了每次迭代中合并的字节对 (e.g.,
[('t', 'h') -> 'th', ('i', 's') -> 'is', ...])。解码和对新文本编码时需要这个。
2.4 解码 (Decoding)
解码过程相对简单:
- 将整数ID序列转换回子词字符串序列(使用训练好的词汇表)。
- 将这些子词字符串拼接起来。如果BPE实现将空格编码为特殊字符或词的一部分,解码时就能自然恢复。例如,如果
_代表空格,且被编码为"_",那么["th", "is", "_", "a", "_", "test"]解码为 “this a test”。
2.5 代码实现思考
2.5.1 训练 (Building the Tokenizer)
-
get_stats(ids, counts=None)函数:- 输入:一个表示文本的整数ID列表(初始时是字节ID)。
- 输出:一个字典,key是相邻ID对
(id1, id2),value是它们的频率。
def get_stats(ids_list): # ids_list 是一系列词的id列表,或者整个文本的id列表 counts = {} for ids in ids_list: # 如果是按词处理,ids是单个词的id序列 for pair in zip(ids, ids[1:]): counts[pair] = counts.get(pair, 0) + 1 return counts -
merge(ids, pair, idx)函数:- 输入:一个ID列表
ids,要合并的对pair=(id1, id2),以及代表这个新合并对的新IDidx。 - 输出:一个新的ID列表,其中所有
pair的出现都被idx替换。
def merge_ids(ids, pair, new_id): newids = [] i = 0 while i < len(ids): if i < len(ids) - 1 and ids[i] == pair[0] and ids[i+1] == pair[1]: newids.append(new_id) i += 2 else: newids.append(ids[i]) i += 1 return newids - 输入:一个ID列表
-
主训练循环:
class BPETokenizer: def __init__(self, vocab_size): self.vocab_size = vocab_size self.merges = {} # (p1, p2) -> new_id self.vocab = {i: bytes([i]) for i in range(256)} # id -> bytes # self.reverse_vocab for string -> id might also be useful def train(self, text_corpus_path, num_merges): # num_merges = vocab_size - 256 # 1. 准备初始数据:将文本转换为字节ID序列列表 # 通常按词分割,每个词是其字节的ID列表 # e.g., text = "this is" -> words_ids = [[116, 104, 105, 115], [105, 115]] # (这需要一个预分词步骤,将文本分割成词,并处理空格) # 假设 pretokenized_words_ids 是一个列表,每个元素是代表一个词的字节ID列表 # Example: # with open(text_corpus_path, "r", encoding="utf-8") as f: # text = f.read() # pretokenized_words = text.split() # 非常粗糙的预分词 # words_ids_list = [[int(b) for b in word.encode('utf-8')] for word in pretokenized_words] current_vocab_size = 256 ids_list = [...] # 代表整个语料的,经过预分词并转换为初始字节ID的词列表 for i in range(num_merges): stats = get_stats(ids_list) if not stats: break # 没有更多可合并的了 best_pair = max(stats, key=stats.get) new_id = current_vocab_size + i # or 256 + i # 更新merges和vocab self.merges[best_pair] = new_id self.vocab[new_id] = self.vocab[best_pair[0]] + self.vocab[best_pair[1]] # 更新数据中的ids new_ids_list = [] for word_ids in ids_list: new_ids_list.append(merge_ids(word_ids, best_pair, new_id)) ids_list = new_ids_list # print(f"Merge {i+1}/{num_merges}: {best_pair} -> {new_id} ({self.vocab[new_id]})") # 构建最终的 str_to_id 和 id_to_str 词汇表 self.str_to_id = {v.decode('utf-8', errors='replace'): k for k, v in self.vocab.items()} self.id_to_str = {k: v.decode('utf-8', errors='replace') for k, v in self.vocab.items()}重要: 上面的
train方法中的ids_list更新逻辑需要非常小心。如果语料很大,在每次迭代中遍历和重建整个ids_listA会非常低效。实际实现通常会更智能地只更新受影响的部分,或者在词级别进行操作,并缓存词的当前BPE表示。
GPT-2的原始实现是将文本分割成词,然后对每个词独立应用合并规则直到不能再合并。
2.5.2 编码 (Tokenizing New Text)
- 输入: 新的文本字符串。
- 预处理: 与训练时类似(例如,如果训练时有特定的空格处理或Unicode规范化,这里也要做)。
- 转换为字节: 将文本字符串(或预分词后的每个词)转换为字节序列。
- 应用合并规则:
- 对于字节序列,迭代地应用已学习的
merges规则(按学习的顺序,或者贪婪地应用最高优先级的合并)。 - 从单个字节开始,不断查找可以合并的对,直到没有更多在
merges中的对可以被合并。
OpenAI 的def encode_word(self, text_word): # 假设输入是一个词 byte_tokens = list(text_word.encode("utf-8")) # 初始字节列表 while len(byte_tokens) >= 2: stats = get_stats([byte_tokens]) # 这里 get_stats 稍作修改以处理单个列表 # 找到在 self.merges 中存在且在当前 byte_tokens 中频率最高的合并规则 # 这需要根据 self.merges 的优先级(学习顺序)来选择 # 简化:找到第一个可以应用的合并 possible_merges = {} # (idx_in_byte_tokens, pair_to_merge, new_id_for_pair) for i in range(len(byte_tokens) - 1): pair = (byte_tokens[i], byte_tokens[i+1]) if pair in self.merges: # 这里需要一种方法来决定哪个合并优先 # 简单起见,我们假设merges是有序的,或者直接选第一个找到的 # GPT-2的实现中,merges是有优先级的 # 查找 self.merges 中存在的、当前tokens中能应用的最佳pair # 假设我们找到了 best_pair_to_apply pass # 实际查找逻辑更复杂 # 简化:假设我们按 merges 的顺序尝试应用 applied_a_merge = False for pair_to_merge, new_id in self.merges.items(): # merges 应该是有序的 new_byte_tokens = [] j = 0 while j < len(byte_tokens): if j < len(byte_tokens) - 1 and \ byte_tokens[j] == pair_to_merge[0] and \ byte_tokens[j+1] == pair_to_merge[1]: new_byte_tokens.append(new_id) j += 2 applied_a_merge = True # 标记发生了合并 else: new_byte_tokens.append(byte_tokens[j]) j += 1 byte_tokens = new_byte_tokens if applied_a_merge: # 如果一个合并发生了,就重新从头开始检查当前tokens # 这个逻辑并不完全正确,GPT-2的encode更像是贪婪地替换 # 找到当前tokens中"最好"的合并,应用它,然后重复 break # 简化版:一次只应用一个merge规则然后重新迭代 merges # 一个更符合GPT-2的encode思路是不断找当前tokens中最高优先级的可合并对 # while True: # find best_pair in current byte_tokens that is in self.merges # if no such pair: break # merge this best_pair in byte_tokens # 上面的 encode_word 逻辑只是一个初步的思路,实际的GPT-2 encode更精细 # 它会持续迭代,在当前词的字节表示中寻找最高优先级的合并,直到不能再合并 # 然后将最终的子词ID列表返回 return [self.str_to_id[self.vocab[tid].decode('utf-8', errors='replace')] for tid in byte_tokens_final] def encode(self, text): # 1. 预分词 (e.g., GPT-2的正则) # import re # pat = re.compile(r"""'s|'t|'re|'ve|'m|'ll|'d| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+""") # pre_tokenized_words = re.findall(pat, text) all_token_ids = [] # for word in pre_tokenized_words: # word_ids = self.encode_word(word) # 上述 encode_word 需完善 # all_token_ids.extend(word_ids) # return all_token_ids pass # 伪代码,实际实现参考 tiktoken 或 HF tokenizers 的 BPE 实现tiktoken库中的gpt2.py或 Hugging Facetransformers库中GPT2Tokenizer的源代码是很好的参考,它们展示了如何高效地应用合并规则。关键在于有一个排序好的合并规则列表,然后贪婪地在当前字节序列中应用这些规则。 - 对于字节序列,迭代地应用已学习的
2.5.3 解码 (Detokenizing)
- 输入: 整数ID列表。
- 转换为子词: 使用
id_to_str(或vocabID到bytes,然后解码为字符串) 将ID转换回子词字符串。 - 拼接: 将子词字符串拼接起来。如果空格是作为词的一部分或特殊符号被编码的,这里会自动恢复。
def decode(self, ids): # tokens_bytes = b"".join(self.vocab[idx] for idx in ids) # text = tokens_bytes.decode("utf-8", errors="replace") # return text # 或者如果 vocab 存的是字符串 tokens_str = "".join(self.id_to_str[idx] for idx in ids) return tokens_str
2.6 关键挑战
- 效率: 训练BPE,尤其是统计字节对和更新文本表示,==在大型语料库上可能非常耗时。==优化这些步骤至关重要。
- 预分词策略: 是否预分词以及如何预分词(例如,GPT-2使用正则表达式,SentencePiece直接处理原始流)会影响最终的tokenization行为和性能。
- 词汇表大小: 这是一个需要根据具体任务和数据调整的超参数。太小可能导致过长的编码序列,太大则模型参数增多。
- Unicode 处理: 直接在字节层面操作简化了Unicode问题,但最终解码回字符串时需要正确处理UTF-8。
- 特殊 Token: LLMs 通常还需要一些特殊 token,如
[CLS],[SEP],[PAD],<|endoftext|>。这些通常在BPE词汇表构建之后,通过在词汇表中添加额外的条目来处理,或者预留一些ID给它们。
3. WordPiece Tokenization
WordPiece 是另一种子词分词算法,由谷歌开发并广泛应用于像 BERT 这样的模型中,后续也被许多基于 Transformer 的架构所采用。它与 BPE 有相似之处,都会迭代地构建一个子词单元的词汇表,但它们合并词对的标准不同。
3.1 主要思想
- 似然最大化 (Likelihood Maximization):与 BPE 合并最常见词对不同,WordPiece 会合并那些加入词汇表后能够最大化训练数据在该词汇表构成的 Unigram 语言模型下的似然值的词对。
- 预分词 (Pre-tokenization):WordPiece 通常处理已经经过预分词的文本(例如,按空格和标点符号切分)。
- 子词界定符 (Subword Delimiter):它经常使用一个特殊的前缀(通常是
##)来表明一个子词 token 是一个词的延续部分,而不是一个词的开始。例如,“tokenization” 可能会被切分成["token", "##ization"]。这有助于无歧义地重构原始单词,并区分比如作为独立单词的 “un” 和作为 “undo” 一部分的 “un”。
3.2 算法流程 (训练过程)
WordPiece 的训练过程通常包含以下步骤:
-
初始化 (Initialization):
- 从一个包含训练语料中所有单个字符的初始词汇表开始。
- 将训练语料预分词成一个词的列表。
- 初始化词的计数。
-
迭代 (Iterative Vocabulary Building):
- 重复进行,直到达到期望的合并操作次数或目标词汇表大小:
- 对于词汇表中当前所有的 token,考虑通过连接每对可能的 token 来形成新的候选 token(例如,如果
t1和t2在词汇表中,t1t2就是一个候选)。 - 计算似然增益 (Calculate Likelihood Gain):对于每个候选合并(例如,合并
t_i和t_j形成t_i_j),计算这次合并会使训练数据的似然增加多少。这个分数通常通过计算合并后的组合token在语料中出现的次数,除以原先两个独立token分别出现的次数的乘积来得到,即Score(t_i, t_j) = Count(t_i_j) / (Count(t_i) * Count(t_j)),或者更准确地说是基于语言模型概率的变化:P(t_i_j) / (P(t_i) * P(t_j)),其中 P(token) 是其 unigram 概率。 - 选择最佳词对 (Select Best Pair):选择合并后能带来最高分数的词对
(t_i, t_j)。 - 加入词汇表 (Add to Vocabulary):将新合并的 token
t_i_j加入词汇表。 - 更新数据 (Update Data):概念上,通过用
t_i_j替换t_i t_j的出现来更新训练数据,并更新计数。(实践中,通常是更新计数和概率,而不是在每一步都显式地重写整个数据集)。
- 对于词汇表中当前所有的 token,考虑通过连接每对可能的 token 来形成新的候选 token(例如,如果
- 重复进行,直到达到期望的合并操作次数或目标词汇表大小:
-
最终词汇表 (Final Vocabulary):最终的词汇表包含初始字符和合并后的子词单元。
3.3 编码 (处理新文本)
当对一段新的文本进行分词时:
- 将输入文本预分词成单词(例如,按空格切分,处理标点符号)。
- 对于每个单词:
- 迭代地从已学习的 WordPiece 词汇表中找到是当前单词剩余部分的最长前缀的子词。
- 如果这个子词不是单词的第一个部分,它通常会是带有
##前缀的版本。 - 将这个子词添加到 token 列表中,并从单词的开头移除它。
- 重复此过程,直到整个单词被切分完毕。
- 如果剩下任何无法用词汇表表示的字符,它们可能会被映射到一个"未知"token(例如
[UNK])。
3.4 代码实现思路
3.4.1 训练过程关键代码逻辑
WordPiece 的训练比 BPE 更复杂,因为它涉及到基于语言模型似然的评估。
-
初始化
vocab和word_counts:# vocab: 初始时包含所有单个字符 # word_counts: 统计预分词后每个词在语料中出现的频率 vocab = set(all_characters_in_corpus) # corpus_words: 预分词后的词列表,例如 ["tokenization", "is", "tokenization", ...] word_counts = count_frequencies(corpus_words) # 为了计算似然,我们需要将每个词表示为其当前的最佳子词切分 # 初始时,每个词被切分为字符 current_segmentations = {word: list(word) for word in word_counts.keys()} -
迭代构建词汇表:
num_merges = target_vocab_size - len(vocab) for i in range(num_merges): candidate_pairs = {} # 存储 (token1, token2) -> score # 1. 收集所有可能的合并对并计算它们的分数 # 这个过程需要遍历当前词汇表中的token,并考虑它们的组合 # 更高效的方式是遍历当前所有词的切分结果 for word, segments in current_segmentations.items(): for j in range(len(segments) - 1): pair = (segments[j], segments[j+1]) # 计算分数:Score(t_i, t_j) = Count(t_i_j) / (Count(t_i) * Count(t_j)) # Count(t_i_j) 是合并后新token t_i_j 在整个语料中(基于当前切分)的预期频率 # Count(t_i) 和 Count(t_j) 是单个token的频率 # A这里的Count计算需要基于当前所有词的切分状态,并乘以每个词的word_counts # 简化的分数计算(实际更复杂,涉及整个语料的语言模型似然变化): # 假设我们能估计出合并此pair带来的"好处" score = calculate_likelihood_gain(pair, current_segmentations, word_counts, vocab) candidate_pairs[pair] = candidate_pairs.get(pair, 0) + score # 或者直接存最大score if not candidate_pairs: break # 没有可合并的了 # 2. 选择分数最高的词对 best_pair = max(candidate_pairs, key=candidate_pairs.get) # 3. 将新合并的 token 加入词汇表 new_token = best_pair[0] + best_pair[1] # 字符串拼接 vocab.add(new_token) # 4. 更新 current_segmentations,将所有 best_pair 替换为 new_token # 这是一个非常耗时的步骤,实际实现会有更高效的更新方式, # 例如只更新受影响的词的切分,或者直接更新一个全局的语言模型概率。 new_current_segmentations = {} for word, segments in current_segmentations.items(): new_segments = [] k = 0 while k < len(segments): if k < len(segments) - 1 and segments[k] == best_pair[0] and segments[k+1] == best_pair[1]: new_segments.append(new_token) k += 2 else: new_segments.append(segments[k]) k += 1 new_current_segmentations[word] = new_segments current_segmentations = new_current_segmentations # print(f"Merge {i+1}: {best_pair} -> {new_token}") # final_vocab = vocab注意:
calculate_likelihood_gain和update current_segmentations是 WordPiece 训练中最核心和计算最复杂的部分。实际的 BERT WordPiece 训练代码并没有完全开源,但其思想是最大化语料库的对数似然。
3.4.2 编码过程关键代码逻辑
编码(分词)新文本相对直接,通常采用贪婪的最长匹配策略。
class WordPieceTokenizer:
def __init__(self, vocab_path, unk_token="[UNK]", prefix="##"):
self.vocab = load_vocab(vocab_path) # 从文件加载词汇表,通常是一个 token -> id 的映射
self.unk_token = unk_token
self.prefix = prefix
def tokenize(self, text):
# 1. 预分词(例如,按空格和标点,BERT有自己的BasicTokenizer)
pre_tokenized_words = basic_tokenizer(text) # e.g., "tokenization is fun." -> ["tokenization", "is", "fun", "."]
output_tokens = []
for word in pre_tokenized_words:
if word in self.vocab: # 整个词在词典中
output_tokens.append(word)
continue
tokens_for_word = []
remaining_word = list(word) # 将词转换为字符列表
while remaining_word:
found_subword = False
# 从最长的可能子词开始尝试匹配
for i in range(len(remaining_word), 0, -1):
subword_candidate = "".join(remaining_word[:i])
# 如果不是词的开头,则尝试匹配带前缀的子词
if tokens_for_word and (self.prefix + subword_candidate) in self.vocab:
tokens_for_word.append(self.prefix + subword_candidate)
remaining_word = remaining_word[i:]
found_subword = True
break
# 尝试匹配不带前缀的子词 (通常用于词的第一个子词)
elif not tokens_for_word and subword_candidate in self.vocab:
tokens_for_word.append(subword_candidate)
remaining_word = remaining_word[i:]
found_subword = True
break
if not found_subword:
# 如果找不到任何子词(即使是单个字符也不在词汇表中,这通常不应该发生,因为字符应该在)
# 或者为了处理非常罕见的字符序列
output_tokens.append(self.unk_token)
break # 当前词处理失败,跳到下一个预分词的词
if found_subword: # 仅当成功切分了整个词时才加入
output_tokens.extend(tokens_for_word)
return output_tokens
# def load_vocab(vocab_path): ...
# def basic_tokenizer(text): ... # BERT的BasicTokenizer包含空格处理、标点分割、中文特殊处理等
3.5 与 BPE 的主要区别
- 合并标准 (Merge Criterion):BPE 合并最频繁的词对。WordPiece 合并能使训练数据在当前词汇构成的语言模型下似然值最大化的词对。
- 前缀使用 (Prefix Usage):WordPiece 显式使用像
##这样的前缀来标记词的延续部分,这是一种约定,而不是 BPE 算法本身固有的部分(尽管 BPE 的实现也可以采用类似的约定)。
3.6 代表模型
- BERT、DistilBERT、ELECTRA 以及许多其他由谷歌开发或受其启发的模型。Hugging Face 的
BertTokenizer使用的就是 WordPiece。
4. Unigram Tokenization
Unigram 分词,通常通过谷歌的 SentencePiece 库实现(需要注意的是,SentencePiece 也可以实现 BPE),它采用了一种不同的方法。它不是通过合并来迭代地构建词汇表,而是从大量的候选词开始,然后逐渐裁剪它们。它明确地基于 Unigram 语言模型。
4.1 主要思想
- 概率化切分 (Probabilistic Segmentation):核心思想是将文本表示为一个子词单元序列,其中每个单元都从 Unigram 语言模型中分配得到一个概率。目标是找到使观察到的序列概率最大化的切分方式。
- 删减式方法 (Subtractive Approach):与 BPE 和 WordPiece(它们是从字符开始向上构建的增量式方法)不同,Unigram 通常从一个更大的候选子词集合开始(例如,训练数据中的所有子字符串,或通过其他方法获得的词汇表),然后迭代地移除价值较低的子词。
- 多种切分方式与正则化 (Multiple Segmentations & Regularization):一个关键特性是,同一段文本可能会有多种有效的切分方式。在训练期间(有时在推理期间,这在 SentencePiece 中被称为子词正则化或 BPE-dropout),模型可以从这些不同的切分中进行采样。这使得模型对分词的微小变化更具鲁棒性。
- SentencePiece: 虽然 Unigram 是一种通用算法,但它最广为人知的是通过 SentencePiece 实现。SentencePiece 可以直接处理原始文本,无需预分词(空格被视作普通字符或一个特殊的元符号,如
4.2 算法流程 (训练过程)
Unigram 模型的训练通常遵循一个类似期望最大化(EM)的过程:
-
初始化 (Initialization):
- 从一个初始的、可能很大的候选子词 token 集合开始。这可以是训练数据中的所有子字符串,或者是通过 BPE 等简单方法生成的词汇表,再加上所有单个字符。
- 为了效率,SentencePiece 通常使用 BPE 生成的词汇表作为起点。
-
迭代优化 (EM-like steps):
- 重复进行,直到收敛或达到目标词汇表大小:
- E-步骤 (Expectation-like):给定当前的词汇表及其估计的概率(初始时,这些可以是频率),对于训练语料中的每个句子,使用维特比(Viterbi)算法找到最可能的切分方式。维特比算法可以高效地在所有可能切分的格网中找到最优路径(子词序列)。
- M-步骤 (Maximization-like):根据子词在 E-步骤中找到的维特比切分中的出现频率,重新估计词汇表中每个子词的概率。
P(子词) = count(子词) / total_count_of_all_subwords_in_Viterbi_segmentations。 - 剪枝 (Pruning):为每个子词计算一个"损失",表示如果该子词从词汇表中移除,训练语料(使用维特比切分时)的总似然会降低多少。
- 移除一定百分比(例如 10-20%)损失最小的子词,同时确保所有字符仍然可以由剩余的子词构成。词汇表大小因此缩小。
- 重复进行,直到收敛或达到目标词汇表大小:
-
最终词汇表 (Final Vocabulary):当词汇表达到期望的目标大小时,过程停止。最终词汇表中的每个子词都有一个关联的概率。
4.3 编码 (处理新文本)
对一段新的文本进行分词:
- 给定输入文本和训练好的 Unigram 词汇表(包含子词及其概率)。
- 使用维特比算法找到来自词汇表的子词序列
s_1, s_2, ..., s_k,该序列能够最大化它们概率的乘积P(s_1) * P(s_2) * ... * P(s_k)。 - 这个最可能的序列就是分词后的输出。
4.4 与 BPE 和 WordPiece 的主要区别
- 方法论 (Approach):BPE/WordPiece 是增量式的(合并词对)。Unigram 通常是删减式的(从大的候选集中剪枝)。
- 优化目标 (Optimization Goal):BPE 直接优化合并操作的频率/似然。Unigram 直接优化整个语料在给定子词 Unigram 语言模型下的切分似然。
- 解码/编码 (Decoding/Encoding):Unigram 使用维特比解码来找到最可能的切分。BPE/WordPiece 通常使用贪婪的最长匹配方法进行编码。
- 子词正则化 (Subword Regularization):Unigram(尤其是在 SentencePiece 中)天然支持对多种切分方式进行采样,从而增强模型的鲁棒性。这在基础的 BPE/WordPiece 算法中不那么固有。
- 预分词 (Pre-tokenization):SentencePiece 的 Unigram 实现可以直接处理原始文本,将空格视为待学习的字符。而 BPE/WordPiece 传统上需要预分词。
4.5 代码实现思路
Unigram 的实现核心在于维特比算法 (Viterbi algorithm) 和基于期望最大化 (EM) 的词汇表剪枝。SentencePiece 是其代表性实现。
4.5.1 训练过程关键代码逻辑
-
初始化:
seed_vocab_with_probs: 一个初始的子词词汇表及其(对数)概率。可以从所有子串的频率估计,或用 BPE 生成一个初始词汇表然后估计概率。- 所有单个字符必须在初始词汇表中,以保证任何字符串都能被切分。
# seed_vocab_with_probs: {"token1": log_prob1, "token2": log_prob2, ...} # 确保所有单个字符都在里面 -
EM 迭代优化:
current_vocab_with_probs = seed_vocab_with_probs num_iterations = 10 # 或者直到收敛 target_vocab_size = 32000 for iter_num in range(num_iterations): # E-step: 使用当前词汇表和概率,为语料中的每个句子找到最优切分 # 并统计每个token在这些最优切分中出现的次数 token_counts_in_viterbi_paths = defaultdict(int) total_tokens_in_viterbi_paths = 0 for sentence in corpus: # best_segmentation is a list of tokens, e.g., ["this", " ", "is", " ", "good"] best_segmentation = viterbi_segment(sentence, current_vocab_with_probs) for token in best_segmentation: token_counts_in_viterbi_paths[token] += 1 total_tokens_in_viterbi_paths += 1 # M-step: 根据新的计数更新每个token的概率 new_vocab_with_probs = {} for token, count in token_counts_in_viterbi_paths.items(): new_vocab_with_probs[token] = math.log(count / total_tokens_in_viterbi_paths) current_vocab_with_probs = new_vocab_with_probs # Pruning step: 如果当前词汇表大小 > 目标大小,则进行剪枝 if len(current_vocab_with_probs) > target_vocab_size: # 计算每个token的"损失":如果移除这个token,语料库总的对数似然会降低多少 # 损失小的token是候选被移除的 token_losses = {} for token_to_remove in current_vocab_with_probs.keys(): if len(token_to_remove) == 1 and is_essential_char(token_to_remove): # 单个字符通常不移除 token_losses[token_to_remove] = float('inf') # 设为无限大,避免被移除 continue # 模拟移除token_to_remove后的词汇表 temp_vocab = {t:p for t,p in current_vocab_with_probs.items() if t != token_to_remove} # 计算移除后的总对数似然 (或其变化量作为损失) # 这需要重新对一部分或全部语料进行Viterbi切分,计算量很大 # SentencePiece有更高效的损失近似计算方法 loss = calculate_corpus_likelihood_decrease(corpus, temp_vocab, current_vocab_with_probs) token_losses[token_to_remove] = loss # 保留 target_vocab_size 个损失最大的(即最重要的)token # 或者移除 (len(current_vocab) - target_vocab_size) 个损失最小的token num_to_remove = len(current_vocab_with_probs) - target_vocab_size sorted_tokens_by_loss = sorted(token_losses.items(), key=lambda item: item[1]) new_pruned_vocab = {} kept_tokens = {item[0] for item in sorted_tokens_by_loss[num_to_remove:]} # 确保所有单个字符都被保留 for char_token in all_single_char_tokens_in_corpus: kept_tokens.add(char_token) for token in kept_tokens: if token in current_vocab_with_probs: # 确保token还在(可能已被其他逻辑移除) new_pruned_vocab[token] = current_vocab_with_probs[token] current_vocab_with_probs = new_pruned_vocab # print(f"Iteration {iter_num+1}, Vocab size: {len(current_vocab_with_probs)}") if len(current_vocab_with_probs) <= target_vocab_size: # 提前停止剪枝 # 可能还需要几轮EM来稳定概率 pass # final_trained_vocab_with_probs = current_vocab_with_probs -
viterbi_segment(text, vocab_with_probs)函数:
这是 Unigram 的核心。它找到给定文本的最优(最高概率)子词切分。def viterbi_segment(text, vocab_with_probs): # dp[i] 存储到位置i的最佳切分的对数概率 # backpointers[i] 存储到达位置i的最佳切分的最后一个token length = len(text) dp = [-float('inf')] * (length + 1) backpointers = [""] * (length + 1) dp[0] = 0 # 空字符串的概率为1,对数概率为0 for i in range(1, length + 1): # 结束位置 for j in range(0, i): # 开始位置 subword = text[j:i] if subword in vocab_with_probs: log_prob = vocab_with_probs[subword] if dp[j] + log_prob > dp[i]: dp[i] = dp[j] + log_prob backpointers[i] = subword # 从后向前回溯,构建最优切分序列 if dp[length] == -float('inf'): # 无法切分,这理论上不应发生,因为单个字符总是在词汇表中 # 可以默认切分为单个字符 return list(text) segmentation = [] current_pos = length while current_pos > 0: last_token = backpointers[current_pos] segmentation.append(last_token) current_pos -= len(last_token) return segmentation[::-1] # 反转得到正确的顺序
4.5.2 编码过程关键代码逻辑
编码新文本就是直接调用训练好的 viterbi_segment 函数。
class UnigramTokenizer:
def __init__(self, model_path): # model_path 通常存储了词汇表及其概率
self.vocab_with_probs = load_unigram_model(model_path)
def tokenize(self, text):
return viterbi_segment(text, self.vocab_with_probs)
# def load_unigram_model(model_path): ...
# 返回 {"token": log_prob, ...} 形式的字典
子词正则化 (Subword Regularization) / BPE-Dropout 的代码思路 (SentencePiece 特有):
在编码时,不是总是选择最优的 Viterbi路径,而是根据概率从多个可能的切分中采样一条路径。
viterbi_segment 需要修改为能够计算所有路径的概率,或者使用一种叫做 “lattice sampling” 的方法:
- 构建和 Viterbi 类似的格网 (lattice)。
- 在解码时,不是总是选择概率最高的边,而是根据每条边的概率(
exp(log_prob))进行随机选择。- 从格网的起始点开始。
- 查看所有从当前节点出发的可能的下一个子词。
- 根据这些子词的概率(归一化后)进行加权随机抽样,选择一个子词作为路径的一部分。
- 移动到该子词的结束节点,重复此过程,直到到达文本末尾。
这使得模型在训练时能看到同一种文本的不同切分方式,增强其对输入扰动的鲁棒性。
4.6 代表模型
- ALBERT、T5、XLNet、mBERT(多语言 BERT 通常使用 SentencePiece)以及许多需要处理多种语言或希望获得子词正则化优势的模型,经常使用 SentencePiece(采用其 Unigram 或 BPE 实现)。
5. 总结与对比
- BPE:合并最高频的词对。简单有效。
- WordPiece:合并能使语料库在当前词汇构成的 Unigram 模型下似然值最大化的词对。用于 BERT。
- Unigram:从一个大的候选集开始,通过剪枝来优化整个语料库的切分似然。使用维特比算法进行切分,并允许子词正则化。通常通过 SentencePiece 实现。
每种方法都有其细微差别和权衡,但它们的目标都是用一个固定大小的子词单元集合来表示一个开放的词汇表。
6. 如何选择分词器
6.1 总览原则
-
如果你在微调 (Fine-tuning) 或使用一个已有的预训练模型:
- 首要且唯一的规则是:必须使用该预训练模型原始训练时所使用的分词器和词汇表。 更换分词器会导致模型输入与预期不符,性能会急剧下降甚至完全失效。
- 例如:
- 使用 GPT-3/GPT-4 系列模型(OpenAI API 或其开源版本):通常使用
tiktoken库,它实现了 OpenAI 模型使用的 BPE 分词。 - 使用 BERT 系列模型:通常使用基于 WordPiece 的分词器 (例如 Hugging Face 的
BertTokenizer)。 - 使用 T5, ALBERT, XLNet, mBERT 等模型:通常使用 SentencePiece (可能是 Unigram 或 BPE 模式,具体看模型文档)。
- 使用 GPT-3/GPT-4 系列模型(OpenAI API 或其开源版本):通常使用
-
如果你在从头开始训练 (Training from Scratch) 一个新模型:
- 这时你有更多的选择权,可以根据数据特点和模型需求来定。
6.2 BPE (Byte Pair Encoding)
- 特点:
- 算法相对简单,通过合并最高频字节对来构建词汇。
- 效果良好,被广泛采用,尤其是在 GPT 系列模型中。
- 实现众多,包括 OpenAI 的
tiktoken(针对其模型高度优化,速度快),Hugging Face 的GPT2Tokenizer或其他基于 BPE 的分词器,以及 SentencePiece 也可以实现 BPE。
- 适用场景/任务:
- 通用文本的语言建模:如 GPT 系列的文本生成任务。
- 从头训练类似 GPT 结构的模型。
- 当需要一个相对简单、效果不错的子词分词方案时。
tiktoken特别适用于需要与 OpenAI 模型行为一致或追求极致编码速度的场景。
- 考虑因素:
- 传统的 BPE 实现可能需要预分词(按空格或规则切分)。
- 合并标准纯粹基于频率,可能不总是产生语言学上最有意义的子词。
6.3 WordPiece
- 特点:
- 合并标准是最大化训练数据的语言模型似然,理论上可能产生更符合语言结构的子词。
- BERT 及其衍生模型的核心分词算法。
- 通常使用
##前缀标记词内非开头的子词。
- 适用场景/任务:
- 从头训练类似 BERT 结构的模型 (例如用于 Masked Language Modeling, Next Sentence Prediction 等任务)。
- 需要与 BERT 生态系统兼容的任务。
- 考虑因素:
- 原始 Google 实现不开源,但 Hugging Face 提供了优秀的开源实现。
- 通常也需要预分词。
6.4 Unigram (通常通过 SentencePiece 实现)
- 特点:
- 基于 Unigram 语言模型,目标是找到概率最大的子词切分序列。
- 从一个大的候选词表开始,通过剪枝得到最终词汇表。
- 支持子词正则化 (Subword Regularization):在训练和推理时可以从多种可能的切分中采样,增强模型鲁棒性。
- SentencePiece 实现可以直接处理原始文本流,无需显式预分词,对多语言处理友好。
- 适用场景/任务:
- 多语言模型训练:SentencePiece 对 Unicode 的原生处理和无需预分词的特性使其非常适合多语言场景。
- 需要提高模型鲁棒性的任务:子词正则化是一个很大的优势。
- 从头训练注重端到端处理的模型:如 T5, ALBERT 等。
- 当不希望依赖外部预分词工具时。
- 考虑因素:
- 训练过程可能比 BPE 稍复杂。
- Viterbi 解码寻找最佳切分,相比贪婪匹配会有一点点额外开销,但通常可忽略。
6.5 SentencePiece (作为一个工具/库)
- 特点:
- 它是一个开源的工具包,可以实现 BPE 或 Unigram 算法。
- 核心优势:
- 直接处理原始文本 (Raw Text Processing):将空格也视为一种普通字符或特殊符号来学习,无需外部预分词器。
- 语言无关性:对各种语言都表现良好。
- 可定制的文本正规化。
- 高效的 C++ 实现,并提供 Python 接口。
- 适用场景/任务:
- 几乎所有需要从头训练模型的场景,特别是:
- 多语言项目。
- 希望简化数据预处理流程(避免繁琐的预分词规则)。
- 需要子词正则化(选择 Unigram 模式)。
- 许多现代 LLM (如 PaLM, LLaMA 的部分版本, T5) 都使用 SentencePiece。
- 几乎所有需要从头训练模型的场景,特别是:
- 如何选择 SentencePiece 的内部算法 (BPE vs Unigram):
- Unigram:理论上更优,支持子词正则化,但训练稍复杂。如果追求最佳效果和鲁棒性,通常推荐。
- BPE:训练更快,概念更简单。如果 Unigram 训练遇到困难或对正则化需求不高,BPE 模式也是不错的选择。
6.6 总结与如何选择
- 已有模型? -> 严格遵守原模型的分词器。
- 从头训练?
- 追求与 OpenAI GPT 类似或极致速度? ->
tiktoken(BPE)。 - 追求与 BERT 类似? -> Hugging Face 的 WordPiece 实现。
- 处理多语言、希望简化预处理、需要子词正则化、追求鲁棒性? -> SentencePiece (Unigram 模式是首选,BPE 模式也可考虑)。这是目前从头开始训练时一个非常强大和通用的选择。
- 一般单语言项目,想快速开始? -> Hugging Face 的 BPE (如
ByteLevelBPETokenizer) 或 SentencePiece (BPE 模式) 都是不错的起点。
- 追求与 OpenAI GPT 类似或极致速度? ->
实际项目中的选择流程如下:
- 确定是否基于预训练模型。 如果是,选择结束,使用其原生分词器。
- 如果不是,评估数据特性:
- 是单语言还是多语言?(多语言强烈倾向 SentencePiece)
- 文本是否干净?是否有很多特殊格式?(SentencePiece 对原始文本处理更好)
- 是否需要模型对输入噪声更鲁棒?(SentencePiece Unigram 的子词正则化有优势)
- 评估项目需求:
- 是否追求与特定知名模型(GPT/BERT)相似的内部机制?
- 开发时间和复杂度是否是重要考量?(BPE 概念和训练相对简单)
- 试验与评估: 如果时间和资源允许,可以尝试几种候选方案,训练分词器,并在下游任务的小规模实验中评估其对模型性能的影响(例如,序列长度、OOV 率、最终任务指标)。
7. 性能对比
不同任务,实验性能会有区别,这只是简单实验
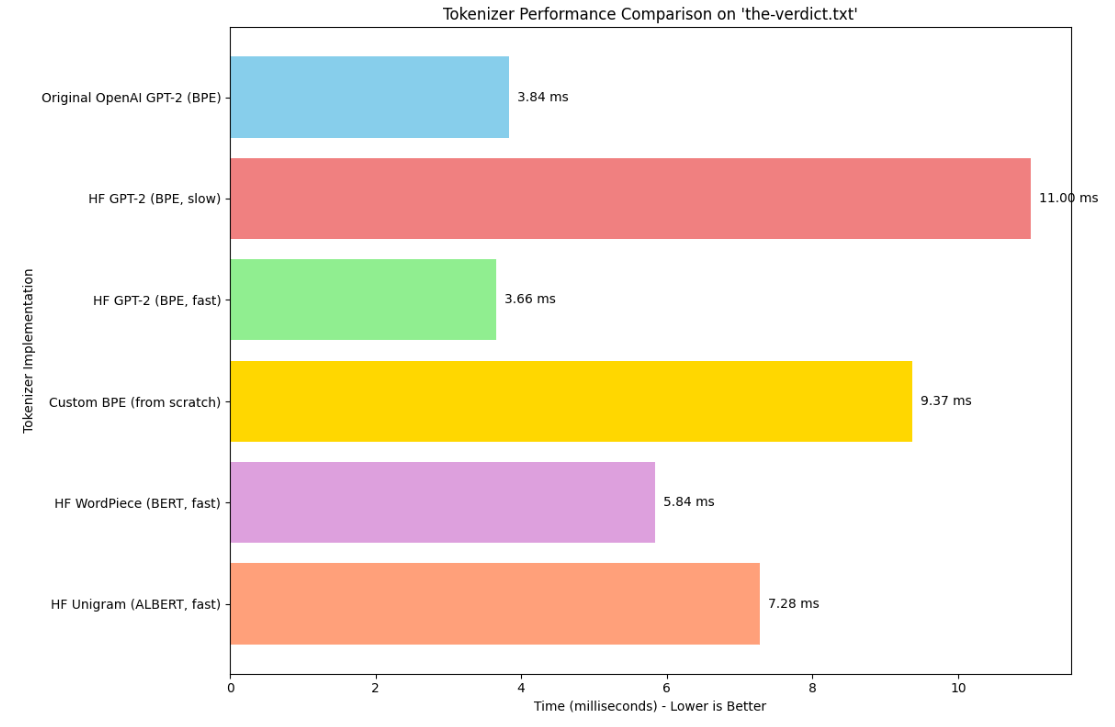
性能对比实验结果分析 (results_str):
| 分词器实现 | 时间 (ms) | 分析与说明 |
|---|---|---|
| Tiktoken OpenAI GPT-2 (BPE) | 0.901 | 明显最快。tiktoken 是 OpenAI 用 Rust 编写的高度优化的库,专门为其模型服务,性能卓越。这符合预期。 |
| HF GPT-2 (BPE, fast) | 3.66 | Hugging Face 的 “fast” tokenizer (通常也是 Rust 实现) 表现非常好,比纯 Python 实现快很多,接近原始 OpenAI BPE (Python 参考版) 的性能。 |
| Original OpenAI GPT-2 (BPE) | 3.84 | 从 OpenAI 原始 GPT-2 Python 代码移植过来的实现。作为 Python 参考实现,速度尚可。 |
| HF WordPiece (BERT, fast) | 5.84 | Hugging Face 的 WordPiece “fast” 实现。WordPiece 算法本身可能比 BPE 的贪婪合并稍微复杂一点,或者这个特定实现/数据集下略慢。仍然是高性能的。 |
| HF Unigram (ALBERT, fast) | 7.28 | Hugging Face 的 Unigram (SentencePiece) “fast” 实现。Unigram 分词在编码时通常需要跑 Viterbi 算法来找最优路径,这比 BPE 的贪婪合并计算量稍大。 |
| Custom BPE (from scratch) | 9.37 | Notebook 中从零开始实现的 BPETokenizerSimple。作为教学目的的纯 Python 实现,这个速度是符合预期的,它没有经过底层优化,比 Rust 实现慢是正常的。 |
| HF GPT-2 (BPE, slow) | 11.00 | Hugging Face 的纯 Python BPE 实现。这个结果清晰地展示了 Rust 实现 (“fast”) 相对于纯 Python 实现 (“slow”) 的巨大性能优势。 |
7.1 结论
-
优化和实现语言至关重要:
tiktoken(Rust) 的速度一骑绝尘,展示了针对特定任务高度优化的威力。- Hugging Face 的 “fast” tokenizers (Rust) 比它们的 “slow” (Python) 版本快了数倍。这强调了在性能敏感的应用中,使用底层语言(如 Rust, C++)编写的库的重要性。
-
教学代码与生产代码的差异:
Custom BPE (from scratch)的性能表现符合其教育定位。它清晰地展示了算法逻辑,但没有进行生产级的性能优化。这再次说明了理解算法和编写高效生产代码是两回事。
-
不同子词算法的性能差异 (在这些实现中):
- 在这个特定的测试文本和实现下,BPE 的 “fast” 实现 (无论是
tiktoken还是HF GPT-2 (fast)) 似乎比 WordPiece 和 Unigram 的 “fast” 实现要快一些。 - 这可能是因为 BPE 的编码过程主要是贪婪地应用合并规则,而 WordPiece(最长匹配)和 Unigram(Viterbi 算法)在编码时可能涉及更复杂的查找或路径搜索。
- 但这并不意味着 BPE 算法本身在所有情况下都比 WordPiece 或 Unigram 更优越。选择哪个算法还取决于分词质量、对特定语言的处理能力、是否需要子词正则化等因素。这里的比较主要集中在编码速度上。
- 在这个特定的测试文本和实现下,BPE 的 “fast” 实现 (无论是



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









