







本文是Python小白学习Python精心总结的基础语法,搭配有讲解语法的代码,适合快速上手Python,本人专栏还会更新Python的面向对象知识和Python常用库。
Python基础
01、注释
在Python中,单行注释用井号(#)标识,也就是#后面的内容;
多行注释用一对三引号(‘’’ ‘’’ )或者一对三个双引号(“”" “”")表示。
02、变量
Python编程中,我们叫标识符为变量名,并且使用等号(=)把变量名和值关联起来,
my_name = "刘德华"
print(my_name)
my_name = "周杰伦"
print(my_name)
整数也就是int类型,在Python中,可以直接对整数进行算数运算
# 加法
add = 3 + 4
# Python中,format方法是格式化输出,也就是在{}的地方替换为变量的值。后面项目实战中经常用到
print('3+4的值是{}'.format(add))
运行结果为:
3+4的值是7
注意:浮点数运算有一定误差
0.2+0.1的值是 0.30000000000000004
Python支持布尔类型的数据,布尔类型只有True和False两种值,但是布尔类型有以下几种运算:
True and True ==> True
True or True ==> True
not True ==> False
03、类型
type() : 获取变量类型
a = 1
print(type(a))
b = 3.14
print(type(b))
c = True
print(type(c))
d = 3+3j
print(type(d))
#<class 'int'>
#<class 'float'>
#<class 'bool'>
#<class 'complex'>
isinstance(a,b)
函数有两个参数,a: 要进行判断的数据,b: 自己指定的数据类型
结果会返回一个bool类型,true:a和b这两个参数类型一致;false:a和b这两个参数类型不一致。
a = 1
print(isinstance(a,int))
#True
b = 'abc'
print(isinstance(b,int))
#False
例题:元素类型判断
题目名称
给定一个列表,删除列表中长度大于 3 的所有元素。
描述
列表元素可能包含整数、字符串、列表、元组、字典。
输入
[1,"sadf",[1,2,3],('t','a','o','b'),3008,{'a':2,'n':5}]
输出
[1, [1, 2, 3], 3008, {'a': 2, 'n': 5}]
lst = eval(input())
new_lst=[]
for x in lst:
if (isinstance(x, str) and len(x) <= 3) or (isinstance(x, (list, tuple, dict)) and len(x) <= 3) or (isinstance(x, int)):
new_lst.append(x)
print(new_lst)
#[1,"sadf",[1,2,3],('t','a','o','b'),3008,{'a':2,'n':5}]
#[1, [1, 2, 3], 3008, {'a': 2, 'n': 5}]
04、列表
列表是由一系列按特定顺序排列的元素组成。也就是列表是有序集合。在Python中,用方括号([])来表示列表,并用逗号来分隔其中的元素。可以给列表起一个名字,并且使用(=)把列表名字和列表关联起来,这就叫做列表赋值。
# 定义一个列表
# Python列表
names_python_pc = ['毛豆','刘德华','张学友','美女']
print('Python列表有:{names_python_pc}')
print(f'Python列表有:{names_python_pc}')
运行结果为:
Python列表有:{names_python_pc}
Python列表有:['毛豆', '刘德华', '张学友', '美女']
列表方法
max(list) 用于返回列表元素中的最大值
当列表中种的元素都是字符串时,则比较第一个字符的ASCLL码
当列表中的元素都是数字的时候,则比较数字大小
list1, list2 = ['123', 'xyz', 'zara', 'abc'], [456, 700, 200]
print "Max value element : ", max(list1);
print "Max value element : ", max(list2);
Max value element : zara
Max value element : 700
pop() 方法用来删除列表中指定索引处的元素,具体格式如下:
listname.pop(index)
其中,listname 表示列表名称,index 表示索引值。如果不写 index 参数,默认会删除列表中的最后一个元素,类似于数据结构中的“出栈”操作。
nums = [40, 36, 89, 2, 36, 100, 7]
nums.pop(3)
print(nums)
nums.pop()
print(nums)
运行结果:
[40, 36, 89, 36, 100, 7]
[40, 36, 89, 36, 100]
例:从输入的列表ls中,删除指定的数据n,并保持其他数据顺序不变。
第一行输入一行以空格间隔的整数,并放入列表ls
第二行输入一个整数n
删除整数列表中的所有的n值,并输出删除后的列表
如果原输入列表中没有n,则输出NOT FOUND

报错,list out of index 因为i -= 1不能改变for循环遍历时i的值,减完1下一次循环时i还是原样

向后调试一步,i从1跳到3
解决方案:使用while循环,删除后i减1,循环尾部i–
或者不用索引遍历,使用列表切片,然后用for循环遍历列表

上面用’ ',下面用" "会报错

a = input()
b = a.split(' ')
d = input()
count = 1
for i in b[0:]:
if i == d:
b.remove(i) # 这里没有索引,不用pop
count = 0
for i in range(len(b)):
if (b[i] != ''):
b[i] = int(b[i])
else:
b.remove(b[i])
if count == 1:
print("NOT FOUND")
elif count == 0:
print(b)
列表切片
切片可用于获得子列表,或者修改、删除列表元素。
lie = [3, 4, 6, 7, 2, 10, 16]
print(lie[:]) # 取全部元素
print(lie[0:]) # 取全部元素
print(lie[:-1]) # 取 除最后一个元素外的所有元素
print(lie[2:5]) # 取序号为2、3、4的元素,不包含最后一个序号的元素
print(lie[::2]) # 从0开始隔一个取一个元素
print(lie[1:5:2]) # 从1开始,每隔一个取一个元素,直到5为止
print(lie[::-1]) # 从右向左取全部成员
print(lie[5:0:-2]) # 从右向左隔一个取一个元素,不包含0
修改元素值时要求 “ = ” 左右两侧的元素个数相同
alist = [3, 4, 6, 7, 2, 10, 16, -8]
alist_x = alist[1:6:2]
print(alist_x)
# 输出结果:[4, 7, 10]
alist[1:6:2] = [28, 38, 48] # 修改元素值
print(alist)
# 输出结果:[3, 28, 6, 38, 2, 48, 16, -8]
del alist[3:5] # 删除元素,删除第3、4元素,不包括第5元素
print(alist)
# 输出结果:[3, 28, 6, 48, 16, -8]
例:输入一个整数列表,列表元素为18个,元素之间逗号隔开,编写程序,将前9个元素升序排列,后9个元素降序排列,并输出列表。
x=input()
x=x.split(",")
for i in range(len(x)):
x[i]=eval(x[i])
y = x[0:9]
y.sort()
x[0:9] = y
y = x[9:18]
y.sort(reverse=True)
x[9:18] = y
print(x)
05、元组
Python 的元组与列表类似,不同之处在于元组的元素不能修改。
元组使用小括号,列表使用方括号。
tup1 = 1,2,3
print(tup1)
结果为:
(1, 2, 3)
#输出元素为元组的列表,元组中元素依次是0-9中的奇数和该数的3次方[(1, 1), (3, 27), (5, 125), (7, 343), (9, 729)]
a = []
for i in range(1, 10, 2):
a.append((i, i * i * i))
print(a)
06、字典
字典是另外一个可变的数据结构,且可存储任意类型对象,比如字符串、数字、列表等。字典是由关键字和值两部分组成,也就是 key 和 value,中间用冒号分隔。这种结构类似于新华字典,字典中每一个字都有一个对应的解释。
#构建一个字典,记录家庭成员的收入
name_dictionary = {'老爸':300,'老婆':1000,'老妈':800,'自己':600,'孩子':200}
print(name_dictionary)
结果为:
{'老爸':300,'老婆':1000,'老妈':800,'自己':600,'孩子':200}
例:
开发一个循环 5 次计算的小游戏,设置随机种子为10,每次随机产生两个 1~10的数字以及随机选择“+、-、*”运算符,
构成一个表达式,让用户计算式子结果并输入结果,如果计算结果正确则加一分,如果计算结果错误不加分。
如果正确率大于等于 80%,则打印“闯关成功”,否则打印“闯关不成功”。
import random
c = 0
for i in range(5):
a = random.randint(1,10)
b = random.randint(1,10)
op = random.choice(['+','-','*'])
print("{}{}{}=".format(a,op,b),end='')
r = eval(input())
d = {'+':a+b,'-':a-b,'*':a*b}
if(r == d[op]):
c += 1
if c>=4:
print("闯关成功")
else:
print("闯关不成功")
添加元素
第一种方式:使用[]
book_dict["owner"] = "tyson"
说明:中括号指定key,赋值一个value,key不存在,则是添加元素(如果key已存在,则是修改key对应的value)
第二种方式:使用update()方法,参数为字典对象
book_dict.update({"country": "china"})
说明:使用dict的update()方法,为其传入一个新的dict对象,key不存在则是添加元素!(如果这个新的dict对象中的key已经在当前的字典对象中存在了,则会覆盖掉key对应的value)
字典方法
clear() 用于清空字典中所有元素(键-值对),对一个字典执行 clear() 方法之后,该字典就会变成一个空字典。
copy() 用于返回一个字典的浅拷贝。
list1 = ['Author', 'age', 'sex']
list2 = ['Python当打之年', 99, '男']
dic1 = dict(zip(list1, list2))
dic2 = dic1
dic3 = dic1.copy() # 浅拷贝:深拷贝父对象(一级目录),子对象(二级目录)不拷贝,还是引用
dic1['age'] = 18
# dic1 = {'Author': 'Python当打之年', 'age': 18, 'sex': '男'}
# dic2 = {'Author': 'Python当打之年', 'age': 18, 'sex': '男'}
# dic3 = {'Author': 'Python当打之年', 'age': 99, 'sex': '男'}
其中 dic2 是 dic1 的引用,所以输出结果是一致的,dic3 浅拷贝,不会随dic1 修改而修改
get() 用于返回指定键的值,也就是根据键来获取值,在键不存在的情况下,返回 None,也可以指定返回值。
list1 = ['Author', 'age', 'sex']
list2 = ['Python当打之年', [18,99], '男']
dic1 = dict(zip(list1, list2))
Author = dic1.get('Author')
# Author = Python当打之年
phone = dic1.get('phone')
# phone = None
phone = dic1.get('phone','12345678')
# phone = 12345678
items() 获取字典中的所有键-值对,一般情况下可以将结果转化为列表再进行后续处理。
tinydict = {'Google': 'www.google.com', 'Runoob': 'www.runoob.com', 'taobao': 'www.taobao.com'}
print(tinydict.items())
#dict_items([('Google', 'www.google.com'), ('Runoob', 'www.runoob.com'), ('taobao', 'www.taobao.com')])
_contains_() :字典是否包含某个键
fromkeys(): 使用给定的多个键创建一个新字典,值默认都是 None,也可以传入一个参数作为默认的值。
list1 = ['Author', 'age', 'sex']
dic1 = dict.fromkeys(list1)
dic2 = dict.fromkeys(list1, 'Python当打之年')
# dic1 = {'Author': None, 'age': None, 'sex': None}
# dic2 = {'Author': 'Python当打之年', 'age': 'Python当打之年', 'sex': 'Python当打之年'}
例:随机生成50个介于[1,20)之间的整数,随机种子设置为10,统计每个整数出现次数,并按照整数出现次数由高到低输出。
import random
random.seed(10)
s={}
for i in range(50) :
num=random.randint(1,19)
if s.__contains__(num):
s[num]+=1
else:s[num]=1
a=dict(sorted(s.items(),key=lambda x:x[1],reverse=True))
for x in a.keys():
print(f"{int(x)}出现了{s[x]}次")
07、缩进
在Python语言中,Python根据缩进来判断代码行与前一行的关系。如果代码的缩进相同,Python认为它们为一个语句块;否则就是两个语句块。一般使用tab按键缩进代码,有的IDE自动缩进代码,比如Pycharm.
this is one block
this is a new line in the one block
this issecond block
this isa new line in the second block
xxxxxx
this is the three block
this is a new line in the three block
08、运算符
运算符的作用是根据已有的变量生成新的变量,主要有以下几种:
- 算术运算符:+,-,*,/,%,即加、减、乘、除、取余
- 比较运算符:==,!=,>,<,>=,<=,即等于、不等于、大于、小于、大于等于、小于等于
- 赋值运算符:=,+=,-=,*=,/=,%=,即赋值、加赋值、减赋值、乘赋值、除赋值、取余赋值
- 逻辑运算符:and,or,not,即与、或、非
- (幂):x的y次幂。 print(c**d)
- %(取余):两者相除取余数。
- //(取整):两者相除取整数。
- 函数max() 来计算任意数的最大值。
一位警察,抓获4个盗窃嫌疑犯甲、乙、丙、丁,他们的供词如下:
甲说:不是我偷的。
乙说:是甲偷的。
丙说:不是我。
丁说:是乙偷的。
他们4人中只有一人说的是真话,你知道谁是小偷吗?
for p in ['甲', '乙', '丙', '丁']:
if (p!='甲') + (p=='甲') + (p!='丙') + (p=='乙') ==1 :
print(p, '是小偷')
#正确是1,错误是0
09、输入
input()函数首先输出提示字符串,然后等待用户键盘输入,直到用户按回车键结束,函数最后返回用户输入的字符串(不包括最后的回车符),保存于变量中。
birth_year = input("请输入您的出生年份:")
now_year = datetime.datetime.now().year
age = now_year - int(birth_year)
print("您的年龄为: " + str(age) + "岁")
-
input()的小括号中放入的是提示信息,用来在获取数据之前给用户的一个简单提示
-
input()会把用户输入的任何值都作为字符串来对待
逗号隔开输入
m,n = eval(input()) 用户输入两个数m和n,结果间用空格分隔。
eval函数
eval函数能够识别字符串中的表达式并将其转换为相应的类型
eval函数只负责对表达式进行处理,并没有赋值的功能,也就是说,eval函数只负责对你的输入进行输出
eval()会去掉字符串最外层的引号,直观理解是:看起来像数字的字符串变成数字了
10、输出
不换行打印 end=’ ’
print("dasd",end='')
%□修改输出精度、宽度

animal = 'monkey'
num = 4
print('A %s has %d legs' % (animal, num))
#A monkey has 4 legs
import math
#default
print "PI = %f" % math.pi
#width = 10,precise = 3,align = left
print "PI = %10.3f" % math.pi
#width = 10,precise = 3,align = rigth
print "PI = %-10.3f" % math.pi
#前面填充字符
print "PI = %06d" % int(math.pi)
#输出结果
#PI = 3.141593
#PI = 3.142
#PI = 3.142
#PI = 000003
#浮点数的格式化,精度、度和
11、排序
sort() 函数用于对原列表进行排序,如果指定参数,则使用比较函数指定的比较函数。
list.sort(cmp=None, key=None, reverse=False)
- cmp – 可选参数, 如果指定了该参数会使用该参数的方法进行排序。
- key – 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
- reverse – 排序规则,reverse = True 降序, reverse = False 升序(默认)。
aList = ['123', 'Google', 'Runoob', 'Taobao', 'Facebook'];
aList.sort();
print(aList)
#['123', 'Facebook', 'Google', 'Runoob', 'Taobao']
降序排序
vowels = ['e', 'a', 'u', 'o', 'i']
vowels.sort(reverse=True)
print( vowels )
#['u', 'o', 'i', 'e', 'a']
通过key和lambda表达式指定元素排序
random = [(2, 2), (3, 4), (4, 1), (1, 3)]
# 指定第二个元素排序
random.sort(key=lambda x:x[1])
print(random)
#[(4, 1), (2, 2), (1, 3), (3, 4)]
sorted() 函数对所有可迭代的对象进行排序操作。
sorted(iterable, cmp=None, key=None, reverse=False)
sort 与 sorted 区别:
- sort 是应用在 list 上的方法,sorted 可以对所有可迭代的对象进行排序操作。
- sort 方法对已经存在的列表进行操作,无返回值, sorted 返回的是一个新的 list。
a = [5,7,6,3,4,1,2]
b = sorted(a) # 保留原列表
#a=[5, 7, 6, 3, 4, 1, 2]
#b=[1, 2, 3, 4, 5, 6, 7]
L= [('b', 2), ('a', 1), ('c', 3), ('d', 4)]
print(sorted(L, key=lambda x: x[1]))
#[('a', 1), ('b', 2), ('c', 3), ('d', 4)]
students = [('john', 'A', 15), ('jane', 'B', 12), ('dave', 'B', 10)]
print(sorted(students, key=lambda s: s[2])) # 按年龄排序
#[('dave', 'B', 10), ('jane', 'B', 12), ('john', 'A', 15)]
12、导入Python库
导入内置库使用import
sqrt()函数在math库中
import math
math.sqrt()
导入第三方库,cmd命令行中 pip install 库名
注意如果Python解释器配置错误会找不到第三方库,详情见另外一篇博客
13、函数
def 函数名(参数列表):
//实现特定功能的多行代码
[return [返回值]]
#自定义 len() 函数
def my_len(str):
length = 0
for c in str:
length = length + 1
return length
#调用自定义的 my_len() 函数
length = my_len("http://c.biancheng.net/python/")
print(length)
#再次调用 my_len() 函数
length = my_len("http://c.biancheng.net/shell/")
print(length)
函数的参数(可变、关键字)
必选参数:必选参数就是在调用函数的时候必须指定参数值,传入的参数必须符合定义时的样子,有几个就要传入几个。
默认参数:默认参数是指给函数参数提供默认值,如果在调用函数的时候没有给该参数传递值,则该参数使用默认值。
默认参数必须放在所有必选参数后面,默认参数指向不变对象
# 定义加法函数plus,参数a是必选参数,参数b是默认值2的参数
def plus(a,b=2):
c=a+b
return(c)
# 调用函数plus时,必须给参数a传递值,若不给b传递值,则b默认为2
d=plus(1)
# 输出结果d
print(d)
可变参数:在定义函数的时候不确定参数的数量时使用可变参数,可变参数就是传入的参数是可变的。
格式:*可变参数名
注:在函数内部,可变参数接收到的值是一个元组。调用参数是可变参数的函数时,可以给该函数传递任意个数的参数,包括0个参数。
# 定义plus函数,完成的功能是返回输入的整数之和。
# 参数numbers是可变参数,表示输入的参数个数可以为任意值
def plus(*numbers):
add = 0
for i in numbers:
add += i
print(add)
# 调用3次plus函数,每次的参数个数都不相同
d1 = plus(1,2,3) #6
d2 = plus(1,2,3,4) #10
d3 = plus(1,3,5,7,9) #25
# 向函数中可以传递任意参数,包括0个参数
d4 = plus() #0
关键字参数:允许我们传入任意个含参数名的参数,这些关键字参数在函数调用时自动组装为一个dict,就是字典。也就是说,关键字参数将长度任意的键-值对,作为参数传递给函数。
关键字参数可以扩展函数功能,使传递参数过程更为简便。
格式:**关键字参数名
示例如下:
# 定义一个包含关键字参数的函数,返回值为参数值
def plus(**kw):
return kw
# 调用plus函数,参数值为空
d1 = plus()
#{}
# 调用plus函数,参数值为x=1
d2 = plus(x=1)
#{'x': 1}
# 调用plus函数,参数值为x=1,y=2
d3 = plus(x=1, y=2)
#{'x': 1, 'y': 2}
根据main函数以及输出设计person函数的参数以及函数的功能
def person(name, **other):
print("name {}".format(name))
for key, value in other.items():
print("{} {}".format(key, value))
person('Alice', city='GL')
#name Alice
#city GL
person('Bob', gender='M', job='Teacher')
#name Bob
#gender M
#job Teacher
14、文件
路径的表示
路径 F:\documents\python\5-1.py
路径字符串 "F:\\documents\\python\\5-1.py"
路径字符串 r"F:\documents\python\5-1.py "
路径字符串 "F:/documents/python/5-1.py"
文件的操作一般包含三个步骤:打开文件 → 读/写文件 → 关闭文件
1. 打开文件:将文件从外存调入内存
2. 文件与文件对象file关联,后续文件操作通过文件对象实现 文件对象名 = open(文件路径字符串,模式字符)
3. 读写文件:利用文件对象,增删改查文件内容
4. 关闭文件:将文件从从内存保存到外存。
5. 写完文件后,必须关闭文件,系统才会将文件从缓存写到外存。

写入文件
文件对象.write(字符串) 字符串被写入文件当前插入点位置,返回写入的字符数。
file=open('F:/桌面/a.txt','r+')
a=file.write('Python\n')
b=file.write('Java')# write不会自动换行,需加'\n'
file.close()# 不关闭或flush不会写出
print(a)#7
print(b)#4

多个字符串写入文件的方法:
文件对象.writelines(序列)
接收字符串、元组(元素必须为字符串)、列表(元素必须为字符串) 、字典(写入键,键必须为字符串)作为参数
file=open('F:/桌面/a.txt','r+')
ls = ['Python','\n','Java']
file.writelines(ls)
file.close()

读取文件
从文件中读取内容的方法:
字符串变量 = 文件对象.read()
读出文件所有内容并作为一个字符串返回
file=open('F:/桌面/a.txt','r+')
content = file.read()
print(content)
#Python
#Java
每次读一行文件内容:
文件对象.readline()
读出文件中当前行(包括分隔符),并以字符串的形式返回
file=open('F:/桌面/a.txt','r+')
content = file.readline()
print(content)
#Python
读文件所有行:以列表返回
文件对象.readlines()
读出文件所有内容(包括分隔符)并以列表返回,每行作为一个字符串元素放入列表。
file=open('F:/桌面/a.txt','r+')
content = file.readlines()
print(content)
#['Python\n', 'Java']
15、format()函数
format函数用于字符串的格式化
format() 函数与参数结合使用,括号及其里面的字符 (称作格式化字段) 将会被 format() 中的参数替换
print("我叫{},今年{}!".format("张三",22))
print("我叫{0},今年{1}!".format("张三",22))
print("我叫{1},今年{0}!".format("张三",22))
#我叫张三,今年22!
#我叫张三,今年22!
#我叫22,今年张三!
在format()中使用关键字参数,它们的值会指向使用该名字的参数
print("我叫{name},今年{age}!".format(name="张三",age=22))
print("我叫{name},今年{age}!".format(age=22,name="张三"))
#我叫张三,今年22!
#我叫张三,今年22!
format() 函数与数字,字符结合使用
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ir2AnmjQ-1681549845242)(../img/image-20230227222638171.png)]](https://img-blog.csdnimg.cn/f5e182e30f354e6286031539d430f6de.png)
print('{:.2f}'.format(3.1415926))
#3.14
print('{:+.2f}'.format(-3.1415926))
#-3.14
print('{:.0f}'.format(3.5415926))#四舍五入
#4
print('{:0>2d}'.format(3))
#03
print('{:0<2d}'.format(3))
#30
print('{: ^5d}'.format(3))
#$$3$$
16、lambda 函数
lambda匿名函数,可以结合表达式更灵活地调用函数
lambda [args…]:expression[args…] 是参数列表,expression是对参数的处理
[args...]形式如下:
a, b
a=1, b=2
*args
**kwargs
a, b=1, *args
空
expression 是一个参数表达式,表达式中出现的参数需要在[arg......]中有定义,以下都是合法的表达式:
expression形式如下:
1
None
a + b
sum(a)
1 if a >10 else 0
lambda x, y: x*y # 函数输入是x和y,输出是它们的积x*y
lambda:None # 函数没有输入参数,输出是None
lambda *args: sum(args) # 输入是任意个数参数,输出是它们的和(隐性要求输入参数必须能进行算术运算)
lambda **kwargs: 1 # 输入是任意键值对参数,输出是1
调用方式
a=lambda x,y,z:x*y*z
print(a(2, 3, 4))
#24
print((lambda x: x ** 2)(3))#**是乘方的意思
#9
lambda函数作为参数传递给其他函数,如map、filter、sort、reduce等
random = [(2, 2), (3, 4), (4, 1), (1, 3)]
# 指定第二个元素排序
random.sort(key=lambda x:x[1])
print(random)
#[(4, 1), (2, 2), (1, 3), (3, 4)]
squares = map(lambda x:x**2,range(5)
print(lsit(squares))
#[0,1,4,9,16]
17、ASCII码

例题:大小写转换
a=input()
ar=list(a)
for i in range(0,len(ar)):
c=ord(ar[i])
if c>=65 and c<=90:
ar[i]=chr(c+32)
elif c>=97 and c<=122:
ar[i]=chr(c-32)
a=''.join(ar)
print(a)
18、if 语句
Python中if语句的一般形式如下所示:
if condition_1:
statement_block_1
elif condition_2:
statement_block_2
else:
statement_block_3
- 1、每个条件后面要使用冒号 :,表示接下来是满足条件后要执行的语句块。
- 2、使用缩进来划分语句块,相同缩进数的语句在一起组成一个语句块。
19、while 循环
Python 中 while 语句的一般形式:
while 判断条件:
执行语句
while 循环使用 else 语句
如果 while 后面的条件语句为 false 时,则执行 else 的语句块。
while count < 5:
print (count, " 小于 5")
count = count + 1
else:
print (count, " 大于或等于 5")
20、for 语句
Python for 循环可以遍历任何可迭代对象,如一个列表或者一个字符串。
for <variable> in <sequence>:
<statements>
else:
<statements>
#遍历整数列表
numbers = [12, 454, 123, 785, 65]
for n in numbers:
print(n)
#12
#454
#123
#785
#65
#遍历字符串列表
sites = ["Baidu", "Google","Runoob","Taobao"]
for site in sites:
print(site)
#Baidu
#Google
#Runoob
#Taobao
#遍历字符串
word = 'runoob'
for letter in word:
print(letter)
#r
#u
#n
#o
#o
#b
#遍历一定范围的整数 如果你需要遍历数字序列,可以使用内置 range() 函数,它会生成数列
for number in range(1, 6):
print(number)
#1
#2
#3
#4
#5
#遍历某范围结束时,打印语句
for x in range(6):
print(x)
else:
print("Finally finished!")
#0
#1
#2
#3
#4
#5
#Finally finished!
range()函数
range() 函数语法:range(start, stop[, step])
start: 计数从 start 开始。默认是从 0 开始。
stop: 计数到 stop 结束,但不包括 stop。
step:步长,默认为1。
//正序遍历:
range(5):默认step=1,start=0,生成可迭代对象,包含[0, 1, 2, 3, 4]
range(1,5):指定start=1,end = 5,默认step=1,生成可迭代对象,包含[1, 2, 3, 4]
range(1,10,2):指定start=1,end=10,step=2,生成可迭代对象,包含[1, 3, 5, 7, 9]
//逆序遍历
range(9,-1,-1):step=-1,start=9,生成可迭代对象,包含[9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
如果你需要遍历数字序列,可以使用内置 range() 函数。它会生成数列
for i in range(5):
print(i)
#0
#1
#2
#3
#4
range() 设置变量每次增加多少(甚至可以是负数,有时这也叫做’步长’):
for i in range(0, 10, 3) :
print(i)
#0
#3
#6
#9
结合 range() 和 len() 函数以遍历一个序列的索引,如下所示:
a = ['Google', 'Baidu', 'Runoob', 'Taobao', 'QQ']
for i in range(len(a)):
print(i, a[i])
#0 Google
#1 Baidu
#2 Runoob
#3 Taobao
#4 QQ
例题:判断身份证号码是否正确
校验码计算方法如下:
第一步:从第一位到第17位的系数分别是(7,9,10,5,8,4,2,1,6,3,7,9,10,5,8,4,2)。将身份证号码前17位数字按顺序分别乘以上述系数并相加。
第二步:将上步加得的和除以11取余数
第三步:使用(12-余数)%11计算得到验证码。
编程实现:输入一个身份证号码,按上述说明计算得到验证码,与输入的身份证号码的最后一位比对,输出判断结果。具体见输入输出示例:
nums=list(input())#18位身份证号码
weight=(7,9,10,5,8,4,2,1,6,3,7,9,10,5,8,4,2)
s=0
for i in range(17):
s+=int(nums[i])*weight[i] #加权和,注意原身份证号码都是字符,需要转换为整数再参与计算
y=s%11 #和与11除的余数
code=(12-y)%11 #验证码=(12-余数)%11
if str(code)==nums[-1] or code==10 and nums[-1]=='X': #与最后一位比较,对10特别的处理
print("这是一个正确的身份证号码。")
else:
print("这是一个错误的身份证号码。")
21、字符串
字符串就是一系列字符。在Python中,单引号、双引号或者三引号里面的内容就是字符串。
字符串的索引与切片
字符串中每个字符都对应两个编号(也称下标)
字符串str正向编号从0开始,代表第一个字符,依次往后;字符串str负向编号从-1开始,代表最后一个字符,依次往前。
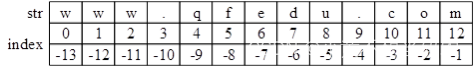
例如索引str中字符’q’
str[4]
str[-9]
字符串可以通过运算符 [ ] 进行索引与切片,
字符串分片是指从字符串中截取部分字符并组成新的字符串,并不会对原字符串做任何改动,其语法格式如下:
[起始编号:结束编号:步长] 包头不包尾
str = "www.baidu.com"
print(str[4:9])
#baidu
print(str[4:9:2]) #设置步长为2
#biu
print(str[-9:-4]) #-4是尾,不包尾
#baidu
print(str[-9:-4:2]) #设置步长为2
#biu
print (str[: ]) #整个字符串
#www.baidu.com
print(str[:9]) #等价于str[0∶9∶1]
#www.baidu
print (str[4: ]) #默认到字符串尾部(包括最后一个字符)
#baidu.com
print(str[:-9]) #从第一个字符到编号为-9的字符(不包括编号为-9的字符)
#www.
print(str[-4:) #从编号为-4的字符到最后一个字符(包括最后一个字符)
#.com
print(str[::-2]) #从后往前,步长为2
#mcuibww
print (str[:-9])) #从第一个字符到编号为-9的字符(不包括编号为9的字符)
#www.
字符串连接
两个字符串连接用+号,但字符串和整型、浮点型变量不能直接用+号连接
a='123'
b='a'
print(a+b)
#123a
a=123
b='a'
print(a+b)
TypeError: unsupported operand type(s) for +: 'int' and 'str'
字符串和整型、浮点型变量拼接要使用 str() 方法先将变量转字符串
a=123
b='a'
print(str(a)+b)
#123a
字符串运算

str1, str2 = "百度", "知道"
print(str1 + str2)
#百度知道
print(3 * (str1 + str2))
#百度知道百度知道百度知道
if "baidu" in "baidu.com":
print("baidu is in baidu.com")
else:
print("baidu is not in baidu.com")
#baidu is in baidu.com
print('abc' in 'abdfcfhj')
#False
== 判断字符串是否相等
print('abc' == 'abdfcfhj')
#False
去除首尾空格 str.strip() 方法
print(str.strip(' ab c '))
#ab c
join() 函数
‘sep’.join(seq)
sep:分隔符。可以为空
seq:要连接的元素序列、字符串、元组、字典
上面的语法即:以sep作为分隔符,将seq所有的元素合并成一个新的字符串
返回值:返回一个以分隔符sep连接各个元素后生成的字符串
字符串逆序
reserved() 函数返回返回一个逆序序列的迭代器(用于遍历该逆序序列),join()函数将序列组装成一个字符串
a=input()
b="".join(reversed(a))
print(b)
字符串索引切片的方法
str = "ABCDEFG"
print(str[::-1])
字符串修改(某个字符)
方法1:将字符串转换成列表后修改值,然后用join组成新字符串
import string
s = 'abcdef' # 原字符串
s1 = list(s) # 将字符串转换为列表
s1[4] = 'E' # 将列表中的第5个字符修改为E
s1[5] = 'F' # 将列表中的第5个字符修改为E
s = ''.join(s1) # 用空串将列表中的所有字符重新连接为字符串
方法2: 通过字符串序列切片方式
import string
s = 'Hello World'
s = s[:6] + 'Bital' # s前6个字符串+'Bital'
print(s) # 输出应为:Hello Bital
s = s[:3] + s[8:] # s前3个字符串+s第8位之后的字符串
print(s) # 输出应为:Heltal
for循环中修改没有效果,不要使用
a=input("请输入:")
for i in a:#感觉类似Java的迭代器
if i=='a':
i='b'
print(a)
#请输入:aaa
#aaa
a=input("请输入:")
for i in range(0,len(a)):
if a[i]=='a':
a[i]='b'
print(a)
#请输入:aaa
TypeError: 'str' object does not support item assignment
原因是python中字符串是一个不可变类型,想要改变python字符串中的某个字符,只能对字符串重新赋值。
字符串和列表的互相转化
str 转换成list,使用list()方法直接转换
str1 = "12345"
list1 = list(str1)
print(list1)
#['1', '2', '3', '4', '5']
使用split()方法分割字符串,括号里是分隔符
str2 = "123 sjhid dhi"
list2 = str2.split() #or list2 = str2.split(" ")
print(list2)
#['123', 'sjhid', 'dhi']
str3 = "www.google.com"
list3 = str3.split(".")
print(list3)
#['www', 'google', 'com']
list 转换成 str,使用join()函数
str4 = "".join(list3)
print(str4)
#wwwgooglecom
str5 = ".".join(list3)
print(str5)
#www.google.com
str6 = " ".join(list3)
#www google com
print(str6)
22、random库
random库生成各种随机数
#导入random库
import random
# 随机整数:
print(random.randint(1, 50))
#12
# 随机选取0到100间的偶数:
print(random.randrange(0, 101, 2))
#0
# 0~1之间随机浮点数:
print(random.random())
#0.6082811070839508
#指定范围的随机浮点数
print(random.uniform(1, 10))
#3.12503583052705
# 随机字符:
print(random.choice('abcdefghijklmnopqrstuvwxyz!@#$%^&*()'))
#@
# 多个字符中生成指定数量的随机字符:
print(random.sample('zyxwvutsrqponmlkjihgfedcba', 5))
#['f', 'b', 'y', 'r', 'l']
# 多个字符中选取指定数量的字符组成新字符串:
print(''.join(random.sample(
['z', 'y', 'x', 'w', 'v', 'u', 't', 's', 'r', 'q', 'p', 'o', 'n', 'm', 'l', 'k', 'j', 'i', 'h', 'g', 'f', 'e', 'd','c', 'b', 'a'], 5)))
#krznh
# 随机选取字符串:
print(random.choice(['剪刀', '石头', '布']))
#布
# 打乱排序
items = [1, 2, 3, 4, 5, 6, 7, 8, 9, 0]
random.shuffle(items)
print(items)
#[6, 1, 0, 9, 8, 7, 3, 2, 5, 4]
当seed()没有参数时,每次生成的随机数是不一样的;
当seed()有参数时,每次生成的随机数是一样的;
当seed()参数不同时生成的随机数也不一样
import random
# 随机数不一样
random.seed()
print('随机数1:',random.random())
#随机数1: 0.7643602170615428
random.seed()
print('随机数2:',random.random())
#随机数2: 0.31630323818329664
# 随机数一样
random.seed(1)
print('随机数3:',random.random())
#随机数3: 0.13436424411240122
random.seed(1)
print('随机数4:',random.random())
#随机数4: 0.13436424411240122
random.seed(2)
print('随机数5:',random.random())
#随机数5: 0.9560342718892494
例题:随机运算式、随机砍价
例:开发一个循环 5 次计算的小游戏,设置随机种子为10,每次随机产生两个 1~10的数字以及随机选择“+、-、*”运算符,构成一个表达式,让用户计算式子结果并输入结果,如果计算结果正确则加一分,如果计算结果错误不加分。如果正确率大于等于 80%,则打印“闯关成功”,否则打印“闯关不成功”。
需要用到random库中的seed、randint和choice函数
import random
c = 0
for i in range(5):
a = random.randint(1,10)
b = random.randint(1,10)
op = random.choice(['+','-','*'])
print("{}{}{}=".format(a,op,b),end='')
r = eval(input())
d = {'+':a+b,'-':a-b,'*':a*b}
if(r == d[op]):
c += 1
if c>=4:
print("闯关成功")
else:
print("闯关不成功")
某电商平台开发出一个新功能:友谊验真器。“是不是朋友,帮忙砍一刀!” 一件商品价格为 price 元,假设每位朋友帮忙砍价都是整数,最少可以砍掉0元,最多只能砍掉不超过商品标价十分之一的价钱,请问每件商品至少要多少人帮忙砍价才能0元拿?
本题使用random函数库,要求使用random.randint()函数生成每次砍价的整数金额
import random
a, b = eval(input())
e = a #a的值会改变
random.seed(b)
count = 0
while (a > 0):
i = random.randint(0, e / 10)
a -= i
count += 1
print(count)
random.choice() 函数
random.choice(seq)函数,从非空序列中随机选取一个数据并返回,该序列可以是list、tuple、str、set。
import random
print(random.choice('choice'))
#结果:choice其中任意一个字母,可能是c也可能是h
random.choices(population,weights=None,*,cum_weights=None,k=1)函数
作用:从集群中随机选取k次数据,返回一个列表,可以设置权重。
population:集群。
weights:相对权重。
cum_weights:累加权重,是weights的累加,即当weight=[1, 2, 3, 4]时,则cum_weights=[1, 3, 6, 10];weight=[1, 2, 3, 4],则cum_weights=[1, 3, 6, 10]。
k:选取次数。
import random
a = [1,2,3,4,5]
print(random.choices(a,k=6))
#重复6次从列表a中的各个成员中选取一个数输出,各个成员出现概率基本持平。
#[5, 4, 5, 4, 1, 3](随机生成的)
print(random.choices(a,weights=[0,0,1,0,0],k=6))
#重复6次从列表a中提取3,最终得到[3, 3, 3, 3, 3, 3]
#[3, 3, 3, 3, 3, 3](固定结果)
print(random.choices(a,weights=[1,1,1,1,1],k=6))
#重复6次从列表a中的各个成员中选取一个数输出,各个成员出现概率基本持平。
#[5, 4, 3, 5, 4, 3](随机生成的)
print(random.choices(a,cum_weights=[1,1,1,1,1],k=6))
#当weight=[1, 0, 0, 0]时,cum_weight=[1, 1, 1, 1],所以打印出来的列表只出现选取列表的第一个元素
#[1, 1, 1, 1, 1, 1](固定结果)
23、集合
定义集合:set()
x = set("abc")
y = set("cdef")
求集合的交集:&
result = x & y
print(result)
#{'c'}
求集合的并集:|
result = x | y
print(result)
#{'c','f','b','d','e','a'}
求集合的差集:-
result = x - y
print(result)
#{'b','a'}
求集合的对称差集:^ (只属于其中一个集合,而不属于另一个集合的元素组成的集合)
result = x ^ y
print(result)
#{'f','d','a','b','e'}
谢谢你看到这里啦,觉得博主总结的还可以请留下一个点赞吧,祝你的Python之路一帆风顺!














 3316
3316











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









