







概念回顾
熔断:A服务调用B服务的某个功能,由于网络不稳定等原因,或者B服务器卡顿,导致功能时间超长,如果如此反复的次数太多,我们就可以将B断路,凡是调用B的直接返回降级数据,不必等待B的超长执行,这样B故障的问题就不会级联影响到A
降级:整个网站处于流量高峰期,服务器压力剧增,根据当前业务情况以及流量,对一些服务和页面进行有策略的降级【停止服务直接返回降级数据】。以此来缓解服务器资源的压力,来保证核心业务的正常运行,同时也保持了客户 和大部分用户得到正确的响应
相同点:
- 为了保证集群大部分服务的可用性和可靠性,防止崩溃
- 用户最终的体验都是某个功能不可用
不同点:
- 熔断是被调用方故障,触发的系统主动服务
- 降级是基于全局考虑,停止一些正常的服务,释放资源,是主动的手段
限流:对打入服务的请求流量进行控制,使得服务能承担不超过自己能力的流量压力
Sentinel简介
| 功能 | Hystrix | Sentinel |
| 隔离策略 | 信号量隔离(并发线程数限流) | 线程池隔离/信号量隔离(后来加的) |
| 熔断降级策略 | 基于响应时间,异常比率,异常数 | 基于异常比率 |
| 实时统计实现 | 滑动窗口(LeapArray) | 滑动窗口(基于RxJava) |
| 动态规则配置 | 支持多种数据源 | 支持多种数据源 |
| 扩展性 | 多个扩展点 | 插件形式 |
| 基于注解的支持 | yes | yes |
| 限流 | 基于QPS,支持基于调用关系的限流 | 有限的支持 |
| 流量整形 | 支持预热模式,匀速器模式,预热排队模式 | 不支持 |
| 系统自适应保护 | 支持 | 不支持 |
| 控制台 | 可配置规则,查看秒级健康,机器发现等 | 简单的监控查看 |
如何使用:
1.定义资源
2.指定规则
3.检验规则是否生效
springBoot整合--我这里因为2.3.7版本过高导致整合失败了,所以没有整合在大项目里
common模块导入依赖
<!-- 可以把他配置到common中-->
<!--sentinel和actuator用于流量监控和统计-->
<dependency><!--流量监控-->
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
<dependency><!--流量统计-->
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
查看核心包版本根据版本下载控制台
使用如下命令打开这个项目
java -jar sentinel-dashboard-1.8.1.jar --server.port=8333账号密码默认都是sentinel
配置控制台信息(在所有要使用sentinel的服务yml文件配置)
# 3项sentinel配置
# sentinel控制台地址
spring.cloud.sentinel.transport.dashboard=localhost:8333
spring.cloud.sentinel.transport.port=8719
# 暴露所有监控端点,使得sentinel可以实时监控
management.endpoints.web.exposure.include=*
可以通过dashBoard的流控规则来控制,但是这个没有持久化,重启之后会消失
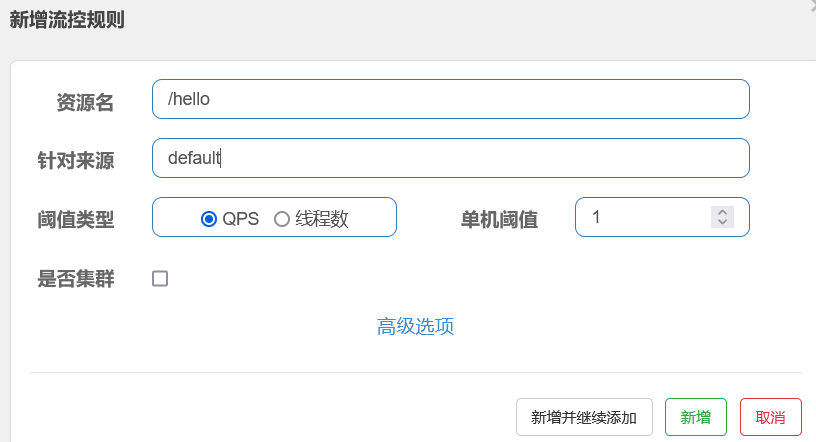
新增完成之后可以在流控规则里查看

持续请求发现会直接报错不会调用该方法
自定义流控响应
添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>添加之后已经可以看到实时监控信息了

自定义返回形式,新版本是实现BlockExceptionHandler这个接口
@Component
public class MyConfig implements BlockExceptionHandler {
@Override
public void handle(HttpServletRequest httpServletRequest, HttpServletResponse httpServletResponse, BlockException e) throws Exception {
httpServletResponse.setCharacterEncoding("UTF-8");
httpServletResponse.setContentType("application/json");
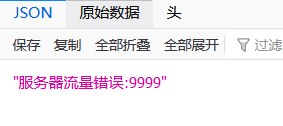
httpServletResponse.getWriter().write(JSON.toJSONString("服务器流量错误:9999"));
}
}
sentinel流量规则解释
资源名:唯一名称,默认请求路径
针对来源:sentinel可以针对调用者进行限流,填写微服务名,默认default(不区分来源)
阈值类型/单机值:
QPS(每秒钟的请求数量):当调用该api就QPS达到阈值的时候,进行限流
线程数.当调用该api的线程数达到阈值的时候,进行限流
单机/均摊阈值:和下面的选项有关
集群阈值模式:
单机均摊:前面设置的阈值是每台机器的阈值
总体阈值:前面设置的阈值是集群总体的阈值
流控模式:
直接:api达到限流条件时,直接限流。分为QPS和线程数
关联:当关联的资到阈值时,就限流自己。别人惹事,自己买单。当两个资源之间具有资源争抢或者依赖关系的时候,这两个资源便具有了关联。,举例来说,read_db 和 write_db 这两个资源分别代表数据库读写,我们可以给 read_db 设置限流规则来达到写优先的目的:设置 strategy 为 RuleConstant.STRATEGY_RELATE 同时设置 refResource 为 write_db。这样当写库操作过于频繁时,读数据的请求会被限流。
链路:只记录指定链路上的流量(指定资源从入口资源进来的流量,如果达到阈值,就进行限流)【api级别的针对来源】
流控效果:
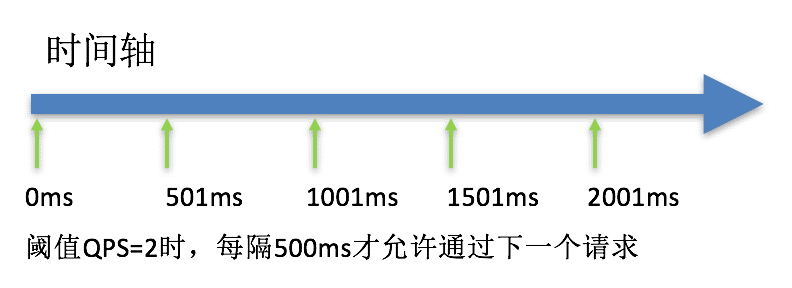
快速失败:直接拒绝。当QPS超过任意规则的阈值后,新的请求就会被立即拒绝,拒绝方式为抛出FlowException
warm up:若干秒后才能达到阈值。当系统长期处于低水位的情况下,当流量突然增加时,直接把系统拉升到高水位可能瞬间把系统压垮。通过"冷启动",让通过的流量缓慢增加,在一定时间内逐渐增加到阈值上限,给冷系统一个预热的时间,避免冷系统被压垮
排队等待:让请求以均匀的速度通过
熔断降级
使用sentinel来保护feign的远程调用
开启调用方的sentinel功能
![]()
指定远程调用的fallback
@FeignClient(value = "gulimall-product",fallback = FallBackTest.class)
public interface TestFeign {
@GetMapping("/hellogulimall")
String hello();
}
fallback类
@Component//需要加入到容器中,因为是使用对象来调用的
public class FallBackTest implements TestFeign {
@Override
public String hello() {
return "远程调用失败了,这是我自定义的熔断保护错误";
}
}
在gulimall模拟失败
@ResponseBody
@GetMapping("/hellogulimall")
public String hello2() throws InterruptedException {
Thread.sleep(5000);
return "hellogulimall";
}测试结果
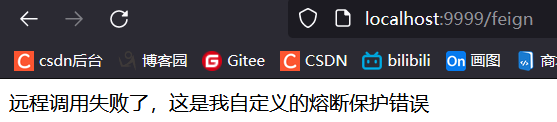
可以在调用方手动指定降级策略,服务降级后也会调用我们的熔断方法
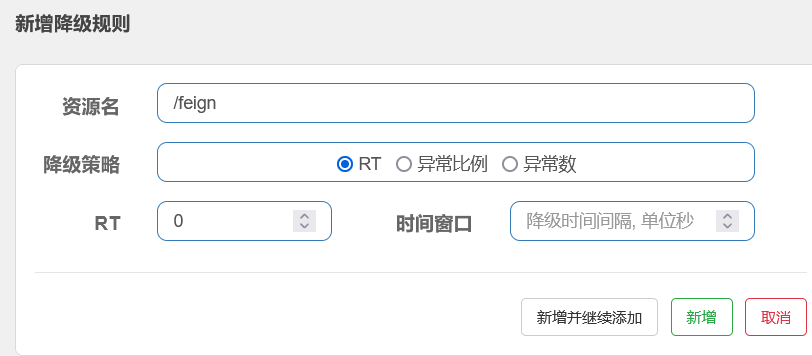
1 DEGRADE_GRADE_RT, 基于响应时间的熔断降级
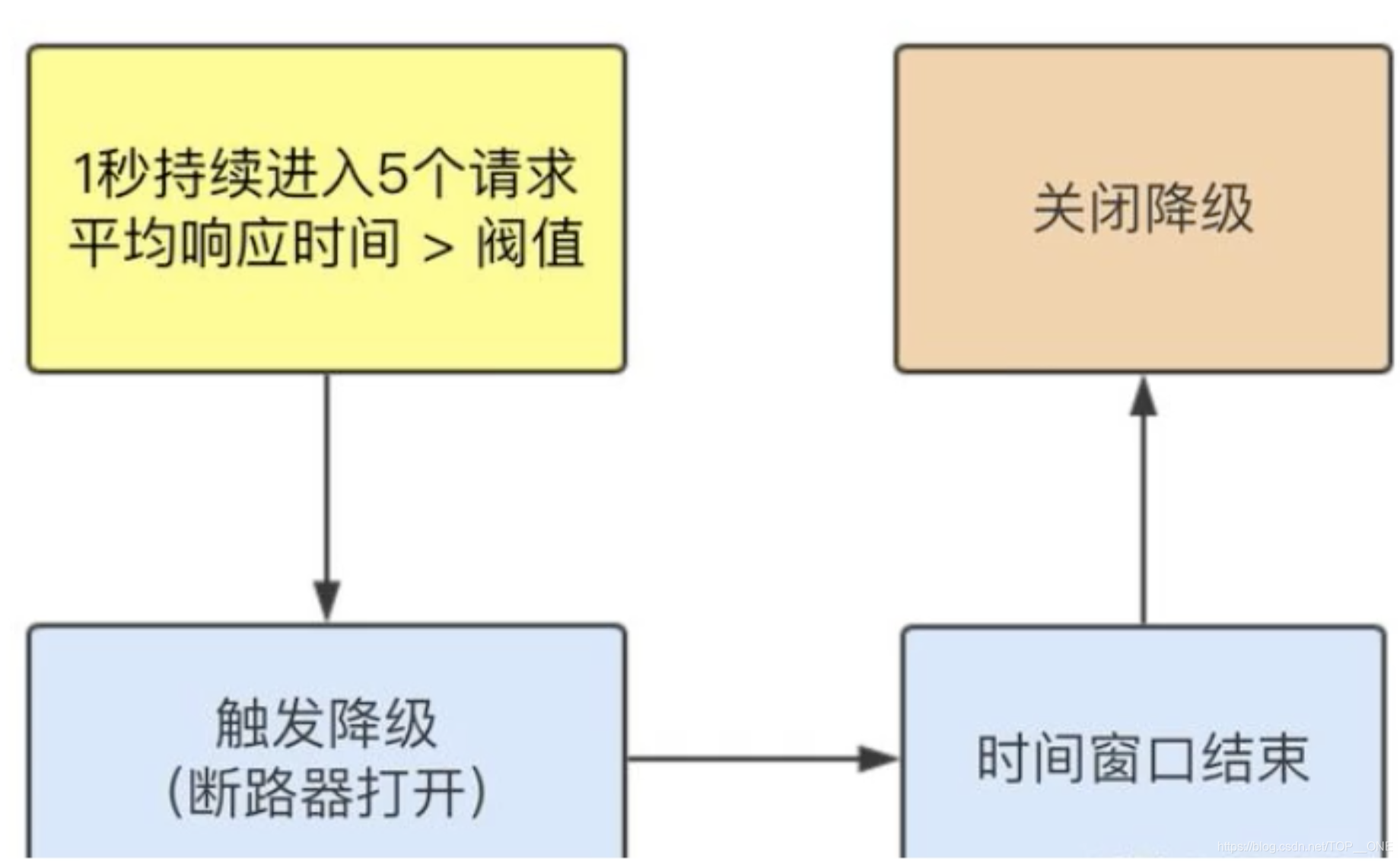
2 DEGRADE_GRADE_EXCEPTION_RATIO, 基于异常比例的熔断降级策略
3 DEGRADE_GRADE_EXCEPTION_COUNT, 基于异常数的熔断降级策略
超大浏览的时候,必须牺牲一些远程服务,在服务的提供方也可以指定降级策略,提供方是在运行,但是不运行自己的业务逻辑,返回的是默认的熔断数据
自定义受到保护的资源
@GetMapping("/feign")
public String test2(){
System.out.println("执行了正常方法");
String hello="";
try(Entry entry= SphU.entry("helloSource")){
hello = testFeign.hello();
}catch (BlockException e){
System.out.println("资源限流异常");
}
return hello;
}对souce可以采用自己的规则

更快捷的方法是基于注解
@SentinelResource(value="getFeignResource")
@GetMapping("/feign")
public String test2() {
System.out.println("执行了正常方法");
String hello = "";
hello = testFeign.hello();
return hello;
}默认限流后会抛一个异常
并且可以使用blockHandler来调用指定限流回调方法
@SentinelResource(value="getFeignResource",blockHandler = "blockHandler")
@GetMapping("/feign")
public String test2() {
System.out.println("执行了正常方法");
String hello = "";
hello = testFeign.hello();
return hello;
}
//返回值必须一样,参数可以使用BlockException
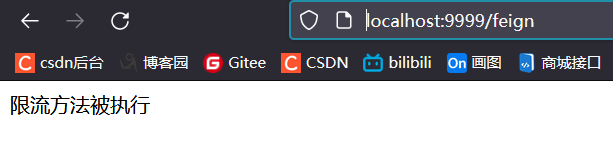
public String blockHandler(BlockException e) {
System.out.println("限流方法被执行");
return "限流方法被执行";
}
可以增加fallback参数
blockHandler会在原方法被限流、降级、系统保护的时候调用,fallback函数会针对所有类型的异常

Sentinel网关流控
引入依赖即可
<!-- 引入sentinel网关限流 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-sentinel-gateway</artifactId>
<version>2.1.0.RELEASE</version>
</dependency>
相当于在网关层可以控制所有请求的流量和降级
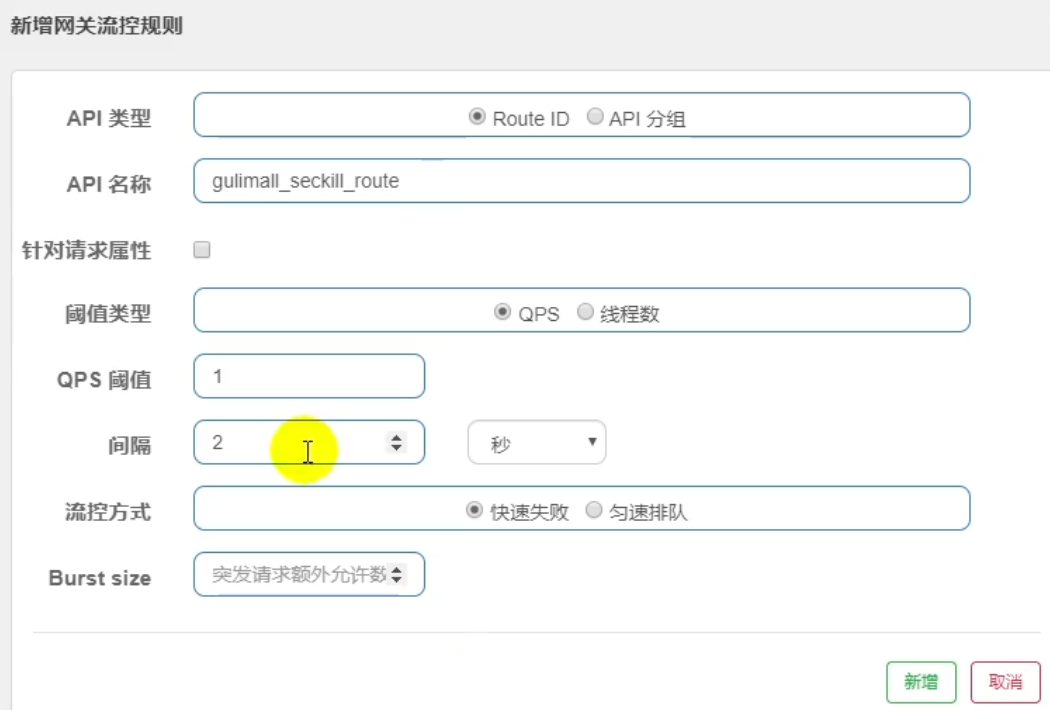
同时也可以指定请求头等,如果不带这个请求头就不受控制
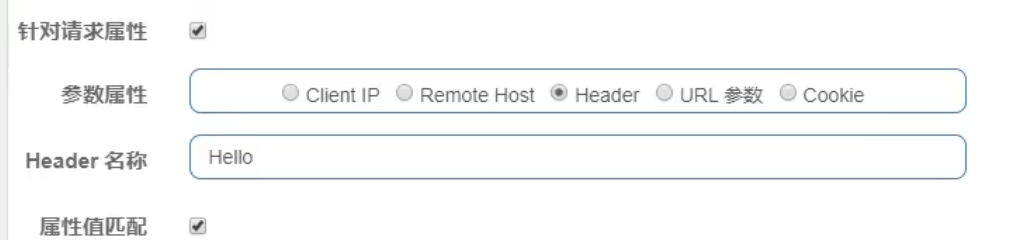
网关定制回调返回
Sleuth+Zipkin服务链路追踪
微服务架构是一个分布式架构,它按照业务划分单元,由于服务单元数量众多,如果出现了错误和异常往往很难去定位。主要体现在,一个请求可能会调用很多个服务。所以微服务架构必须实现分布式链路追踪,去跟进一个请求到底有哪些服务参与。
span:跨度,基本的工作单元,发送一个远程调度任务就会产生一个span
trace:跟踪,一系列span组成的一个树状结构,请求一个微服务系统的api接口,这个api接口需要调用多个微服务,调用每个微服务都会产生一个新的span,所有由这个请求产生的span组成了这个trace
annotation:标注,用来及时记录一个事件的,一些核心注解用来定义一个请求的开始和结束。这些注解包括以下:
- cs-Client Sent --客户端发送一个请求,这个注解描述了这个span的开始
- sr-Server Received --服务端获得请求并准备开始处理它,如果将其sr减去cs时间戳就可以获得网络传输的时间
- ss-Server Sent 服务端发送响应 -该注解表面请求处理的完成(当请求返回客户端),如果ss减去sr时间戳就可以获得服务器请求的时间
- cr-Client Received 客户端接受响应-此时span结束,如果cr时间戳减去cs时间戳就可以获得整个请求消耗的时间
整合步骤
1.引入sleuth依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>如果不使用可视化操作,可以开启debug的日志打印
logging.level.org.springframework.cloud.openfeign=debug
logging.level.org.springframework.cloud.sleuth=debugdocker安装zipkin服务器进行可视化操作
docker run -d 9411:9411 openzipkin/zipkin导入依赖

添加配置
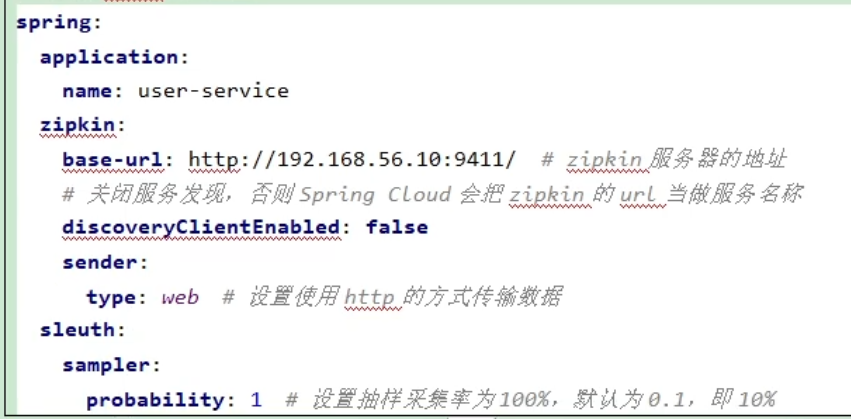
持久化方式

界面分析















 895
895











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









