







Spring如何解决循环依赖问题?
首先明确,Spring不能解决由构造器注入产生的循环依赖并且不能解决原型模式下的循环依赖,此问题解决的前提是:单例模式,set方法注入
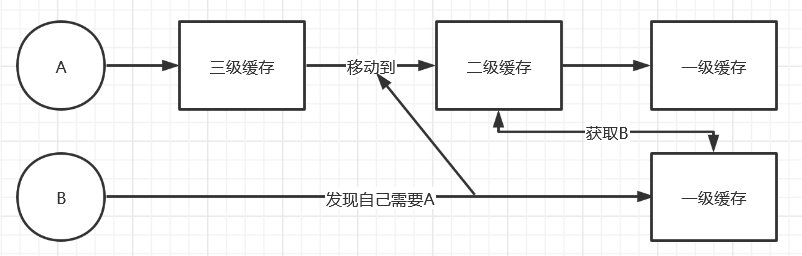
采用三级缓存的方式:
- 一级缓存:这里存放的都是初始化完成的bean--ConcurrentHashMap
- 二级缓存:实例化已经完成了但是属性还没有进行填充--HashMap
- 三级缓存:存放Bean的工厂--HashMap
流程说明:
- A的创建过程需要B,A首先把自己放到三级缓存中,去实例化B
- 在B实例化的过程中,发现需要A,于是依次去一,二,三级缓存中去找A,在三级缓存中找到了A,于是乎将A挪到了二级缓存,并且自己完成了初始化,自己进入一级缓存
- 在二级缓存中的A仍然是创建状态,此时将一级缓存中的B拿到,完成创建,并且将自己放入一级缓存中
为什么局部内部类和匿名内部类只可以访问局部final变量?
内部类和外部类是处于同一个级别的,内部类不会因为定义在方法中就随着方法的执行而销毁,当外部的方法结束了,局部变量就被销毁了,此时内部类对象会访问一个不存在的变量,为了解决这个问题,就将局部变量复制了一份作为内部类的成员变量,以此来延长局部变量的生命周期,可是将局部变量复制为内部类的成员变量的时候,必须保证这两个变量始终一样,也就是在内部类中修改了成员方法,方法中的局部变量也得跟着修改,所以干脆就将局部变量设置为final,这实际上也是一种妥协
守护线程是什么?
为所有非守护线程提供服务的线程,比如GC垃圾回收线程,当垃圾回收线程是jvm唯一的线程时,它会自己离开,在运行中它始终在低级别的状态运行,用于实时监控和管理系统中的可回收资源,守护线程不能去访问固有资源比如读写操作或者计算逻辑,因为它会随时中断
ThreadLocal的使用场景?
在对象进行跨层传递的时候,使用ThreadLocal可以避免多次传递(主要)
线程之间数据进行隔离
进行事务操作存储线程事务信息
线程池为什么可以对线程进行复用?
线程池将任务和线程进行了解耦,线程是线程,任务是任务,摆脱了之前通过Thread创建线程时的一个线程必须对应一个任务的限制.在线程池中,同一个线程可以从阻塞队列中不断获取新任务来执行,其核心原理在于线程池对Thread进行了封装,并不是每次执行任务都会调用Thread.start()来创建新的线程,而是让每一个线程都去执行一个循环任务,在这个循环任务重不停检查是否有任务需要被执行,如果有就直接执行,也就是调用任务的run方法,将run方法当成一个普通的方法执行,通过这种方式只使用固定线程就将所有任务的run方法串联起来
IOC和AOP的理解
IOC:控制反转,其实现的方式是依赖注入,对象a依赖于b,当a初始化运行到某一点的时候,自己必须手动的创建对象b,交给spring管理之后,ioc会主动的创建对象b在a需要的地方,a依赖的b的过程从主动变成了被动,对象的控制权交给了IOC容器
AOP:面向切面,可以把交叉业务逻辑(事务,安全日志)封装成切面,对对象的功能进行增强
BeanFactory和ApplicationFactory的区别?
- BeanFactory是ApplicationFactory的父接口,后者提供了更完整的功能:比如国际化,统一资源访问方式,载入多个上下文
- 前者通过延迟加载的形式注入Bean,后者一开始就创建了所有Bean,可以在容器刚启动的时候就检测spring中配置所产生的错误
- 前者以代码方式被创建,后者以声明或者代码的方式创建
描述一下Bean的生命周期?
- Bean的实例化阶段:容器找到Spring配置文件中bean的定义,使用反射机制实例化Bean
- Bean的设置属性阶段:对实例化的Bean设置值
- Bean的 初始化阶段:如果bean实现了BeanNameAware/BeanClassLoaderAware/BeanFactoryAware等接口执行相应的方法,接着BeanPostProcessor接口会在初始化前后调用,执行初始化(@PostConstruct注解,InitializingBean接口方法)
- Bean的销毁阶段:可以使用@PreDestroy执行自定义方法

SpringBean的作用域?
Singleton:默认,单例模式
prototype:多例,每次都会创建一个新的对象
request:每个Http请求中创建一个新的对象
session:确保每个session中有一个bean的实例,session过期后,bean随之消失
application:被定义为ServletContext的生命周期中复用的一个单例对象
websocket:被定义为websocket的生命周期中复用的一个单例对象
Mybatis的优缺点
优点:
- 解耦:sql写在xml里,解除和程序代码的耦合,便于统一管理
- 简化:相比于jdbc,简化了手动开关连接的操作
缺点:
- sql语句编写工作量大,对sql功底要求高
- sql语句依赖于数据库,可移植性差
建立索引的原则?
- 经常进行增删改的字段不要建立索引
- 复合索引效率高于单个的索引
- 基数小的表没必要建立索引
- 重复值过多的列比如性别不要建立索引
- 有外建的数据列一定要建立索引
ACID分别靠什么来保证?
A:由undolog日志来保证,它记录了需要回滚的日志信息
C:由其他三大特性保证,程序代码要考虑一致性
I:由MVCC来保证
D:由redo log(记录事务操作的变化,记录修改之后的值)和内存保证:mysql修改数据同时在内存和redo log记录操作,宕机的时候从redo log可以恢复操作
binlog是MySQL Server层面的叫归档日志,光依靠binlog是没有crash-safe的能力(如果进程异常重启,系统自动检查redo log,将未写入到mysql的数据从redo log恢复到mysql中去),相对于redo log来说它是追加写而不是循环写,因此不会覆盖文件,binlog用于恢复数据使用,主从复制搭建,redolog作为异常宕机恢复数据使用
Redis哨兵的作用?
集群监控:查看master和slave是否在正常工作
消息通知:如果某个redis实例有故障,那么哨兵负责发送消息通知给管理员
故障转移:如果master node挂了,自动转移到slave node上面
配置中心:如果故障转移发生了,通知client客户端新的master地址
CAP理论和BASE理论
cap理论中c表示的是强一致性,P是一定要保证的,剩下的只能在C和A中做选择
- C:一致性(所有节点在同一时间的数据完全一致)
- A:可用性 (服务一直可用,而且是正常响应时间)
- P:分区容错性(一个机器宕掉,剩下机器依然key满足系统需求)
BASE是基本可用,软状态和最终一致性
基本可用:访问量激增可能使得系统的非核心功能无法使用,响应时间会有一部分的损失
软状态:数据同步允许延迟
最终一致性:不要求数据实时一致,只要最后是一样的就行
如何排查JVM的问题?
- jmap--查询jvm各个区域的使用情况
- jstack--查看进程的运行情况,是否死锁,是否阻塞
- jstat--查看垃圾回收情况
- jvisualvm--结合可视化界面查看堆状态
- top命令找到cpu/内存占用最多的进程,再进一步锁定线程
- 如果频繁fullgc但是没发生oom可以尝试增加年轻代的大小
什么是服务雪崩和服务限流
服务雪崩:如果有如下调用链a->b->c,a本身可以抗下大量请求,b也可以,但是c不行,c的请求堆积,从而导致b的请求也堆积,最终导致整个服务不可用,解决方式是熔断和降级
服务限流:高并发情况为了保护系统,可以对服务的请求进行数量上的限制
BIO,NIO和AIO?
BIO:同步阻塞IO,使用它读取数据的时候,线程会被阻塞,并且需要线程主动去查询是否有数据刻度,并且要处理完一个socket之后才能继续处理下一个socket
NIO:同步非阻塞IO,使用它读取数据,线程不会阻塞,但是需要线程主动去查询是否有IO事件
AIO:也叫NIO2.0,异步非阻塞IO,使用AIO读取数据的时候,线程不阻塞,并且当有数据可读的时候会通知线程,不需要线程主动去查询
Synchronized锁的对象?
对于静态同步方法,对象是类对象,普通同步方法锁的是实例对象,对于同步方法块,锁的是括号里的对象
简述面向对象的六原则一法则?
单一职责原则:一个类只做他该做的事
开闭原则:软件实体应该对扩展开放,对修改关闭
依赖倒转原则:面向接口编程
里式替换原则:任何时候都可以使用子类型替换掉父类型
接口隔离原则:接口要小而专不要大而全
合成聚合复用原则:优先使用聚合或者组合关系复用代码(不使用继承)
迪米特法则:又叫最小知识原则,一个对象应当对其他对象有尽可能少的了解
泛型的上下界?
上界的list <? extend A> 只能get,不能add(确切地说不能add出除null之外的对象,包括Object),具有只读属性,只能获取,放在List中没什么卵用,但是可以用作泛型规定表示继承于A的所有子类
public class Solution {
public static <T extends Fruit> String getFruitName(T t){
return t.getName();
}
public static void main(String[] args) {
System.out.println(getFruitName(new Banana()));
System.out.println(getFruitName(new Apple()));
}
}
class Fruit {
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
class Banana extends Fruit{
public Banana(){
setName("bababa");
}
}
class Apple extends Fruit{
public Apple(){
setName("apple");
}
}
下界的list<? super B> 只能add不能get(get只能用Object来接着),add方法只能添加B的子类及其对象,可以用B来接着
public class Solution {
public static void main(String[] args) {
List<? super B> list = new ArrayList<>();// 下界
B b = new B();
C c = new C();
list.add(b);//只能添加B的子类
list.add(c);
B cast = (B) list.get(0);
System.out.println(cast.age);//1
System.out.println(cast.name);//b
}
}
class A {
String name = "a";
}
class B extends A {
String name = "b";
int age = 1;
}
class C extends B {
String name = "c";
int age = 2;
}Java中的流分类
按照流的方向:输入流和输出流
按照流的功能:节点流(FileReader)和处理流(BufferedReader)对其他流进行包装
按照数据单位:字节流(InputStream)和字符流(OutPutStream)

你眼中的JAVASE框架?
面向对象,集合,多线程,异常,反射,io,网络编程
为什么String会被定义为final?
当字符串不可变的时候,字符串池才有可能实现,因为不同的字符串变量都指向池中的同一个字符串,这样可以节省很多堆空间
由于字符串是不可变的,所以它是多线程安全的,当一个字符串被多个线程共享的时候,就不用担心线程安全问题了
字符串因为拥有不可变的性质,它在创建的时候HashCode就被缓存了,不需要重新计算,这就使得String类型很适合作为HashMap中的键
抽象的方法是否可同时是static或者native或者synchronized?
都不可以
- 抽象方法需要子类重写,静态方法无法被重写
- native方法是本地代码实现的方法,抽象方法是没有实现的
- synchronized和方法的实现细节有关,抽象方法不涉及任何实现细节
来五个常见的运行时异常?
- 空指针异常 NullPointerException
- 数组越界异常 IndexOutOfBoundsException
- 类转换异常 ClassCaseException
- 向数组中存放与声明类型不兼容对象异常 ArrayStoreException
- Io操作异常 BufferOverFlowException
- 算术异常ArithmeticException
静态内部类和内部类的区别?
如果一个类是静态内部类,他可以不依赖于外部类实例从而被实例化,普通的内部类必须在外部类实例化之后才能实例化
Java是否有内存泄漏问题?
可能会有,在实际开发中存在无用但可达的对象无法被gc回收,比如模拟一个栈的时候,pop方法弹出对象的时候,该对象不会被当做垃圾回收

Super关键字?
主要存在于子类方法中,用于指向子类对象中父类对象,用于访问父类的属性,函数和构造函数,和this一样只能在有对象的前提下使用,不能在静态上下文使用
子类的构造函数默认第一行会调用父类的无参构造函数,这是一条隐式语句,如果手动调用(只能放在第一行)有参构造器super(int),无参构造的调用会直接消失
Try Catch Finally的理解
以下结果是31,在执行try的return方法前会执行finally
public static void main(String[] args) {
System.out.println(test());
}
public static int test() {
try {
return 1;
} catch (Exception e) {
return 2;
} finally {
System.out.print("3");
}
}这段代码的执行结果是2,因为在finally执行前jvm会先将i的结果暂存起来,然后等finally执行完毕后,再取回之前暂存的结果
public static void main(String[] args) {
System.out.println(test1());
}
public static int test1() {
int i = 0;
try {
i = 2;
return i;
} finally {
i = 3;
}
}原生jdbc操作数据库的流程
- Class.forName()加载数据库连接驱动
- DriverManager.getConnection()获取数据连接对象
- 根据SQL获取sql会话对象,有两种方式Statement和PreparedStatement
- 执行SQL,执行SQL前如果有参数值就设置参数值setXXX()
- 处理结果集,关闭结果集,关闭会话,关闭连接
http常见状态码
- 200 ok
- 301 Moved Permanent,请求的URL已经移走了,Response中应该携带一个Location URL,说明资源现在所处的位置
- 302 重定向
- 400 Bad Request 客户端请求有语法错误,不能被服务器所理解
- 401 Unauthorized 请求未经授权
- 403 Forbidden 服务器收到请求 但是拒绝提供服务
- 404 Not Found 请求资源不存在
http长连接和短连接的区别?
- HTTP协议有HTTP/1.0版本和HTTP/1.1版本。HTTP1.1默认保持长连接(HTTP persistent connection,也翻译为持久连接),数据传输完成了保持TCP连接不断开(不发RST包、不四次握手),等待在同域名下继续用这个通道传输数据;相反的就是短连接。
- 在 HTTP/1.0 中,默认使用的是短连接。也就是说,浏览器和服务器每进行一次HTTP操作,就建立一次连接,任务结束就中断连接。从HTTP/1.1起,默认使用的是长连接,用以保持连接特性。
Get请求和Post请求的区别?
- get请求的数据会附加在URL之后(就是把数据防止在HTTP协议头中),使用?分割URL和传输数据,参数之间使用&相连,Post请求提交的数据会放在HTTP包的包体中
- get方式提交的数据由于浏览器对URL的长度的限制,所以提交的数据根据不同的浏览器也会有不同的上限(比如IE是2083字节),在具体的协议中Get请求的长度其实是没有限制的,Post就更不用说了
- Post请求的安全性比Get高,使用Get请求提交密码和账号将明文出现在URL上,别人就可以拿到你的私密信息,除此之外Get提交数据还有可能造成CRSF攻击
- GET请求会被浏览器主动cache,而POST不会,除非手动设置
- GET请求只能进行url编码,而POST支持多种编码方式
- GET在浏览器回退时是无害的,而POST会再次提交请求
一张自增表里面总共有 7 条数据,删除了最后 2 条数据,重启 mysql 数据库,又插入了一条数据,此时 id 是几
- 一般情况下,我们创建的表的类型是InnoDB,如果新增一条记录(不重启mysql的情况下),这条记录的ID是8;但是如果重启MySQL的话,这条记录的ID是6。因为InnoDB表只把自增主键的最大ID记录到内存中,所以重启数据库或者对表OPTIMIZE操作,都会使最大ID丢失。
- 但是,如果我们使用表的类型是MylSAM,那么这条记录的ID就是8。因为MylSAM表会把自增主键的最大ID记录到数据文件里面,重启MYSQL后,自增主键的最大ID也不会丢失
ArrayList的线程安全问题
ArrayList的问题发生在如下代码:elementData[size++] = e;
对于如下两个线程,他们的执行顺序从1-4:
1.线程1赋值element[1]=1;而后中断
2.线程2赋值element[1]=2;而后中断
---此处已经导致了一个问题,线程2的数字将线程1的数字覆盖掉了
3.线程1自增size++; size=2
4.线程2自增size++ size=3
--此处导致了某些值为null的问题,因为原size为1,但是由于覆盖和自增导致了elemnt[2]没有值

对于数组越界情况:
- 线程1判断数组是否越界,因为size=2,而且长度为2,没有越界,执行赋值操作,而后中断
- 线程2重复线程一的操作而后中断
- 线程1重新获取到主动权,进行赋值操作并且size++
- 线程2也进行赋值操作并且size++,此时size已经等于3了,再执行element[3]=2,导致了数组越界
















 2100
2100











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









