







打卡第9天,今天继续字符串。
今日任务
- 28.实现 strStr()
- 459.重复的子字符串
- 字符串总结
- 双指针回顾
28. 找出字符串中第一个匹配项的下标
给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字符串的第一个匹配项的下标(下标从 0 开始)。如果 needle 不是 haystack 的一部分,则返回 -1 。

我的题解
class Solution {
public:
int strStr(string haystack, string needle) {
return haystack.find(needle);
}
};
之前看卡哥的视频,学过KMP,看过两遍了,懂了又忘了,就是没有完全懂,又看了一遍。
代码随想录
KMP理论
KMP用处
KMP主要应用在字符串匹配上。
KMP的主要思想是当出现字符串不匹配时,可以知道一部分之前已经匹配的文本内容,可以利用这些信息避免从头再去做匹配了。
如何记录已经匹配的文本内容,是KMP的重点,也是next数组肩负的重任
什么是 next 数组
next数组 其实是 前缀表 (最长相等前后缀表)
前缀表有什么用?
前缀表是用来回退的,它记录了模式串与主串(文本串)不匹配的时候,模式串应该从哪里开始重新匹配。
例如:模式串 aadaaf, 匹配串 aadaadaaf
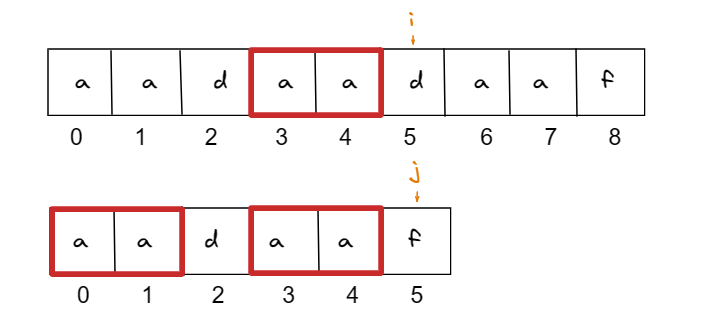
第一轮匹配俩字符串,从头开始匹配,直到发现 i 与 j 所指字符不匹配
暴力算法:发现不匹配,此时就要从头匹配了。
但是KMP算法,模式串 j 跳到 下标 2 开始匹配,因为 红框里的字符串已经确认是匹配的,不需要再从头匹配了,而 next 数组就是来告诉你下一步匹配中,模式串应该跳到哪个位置。
为什么模式串 j 是跳到下标2 开始匹配,可以看到 模式串 在指向 ‘f’ 之前的 字串‘aadaa’ 最长相等的前后缀为 ‘aa’ 。其实在第一轮匹配的时候 后缀‘aa’ 是匹配的,前缀跟后缀是相等的,就不需要再匹配多一次,直接跳到 ‘aa’ 下一个字符开始匹配。
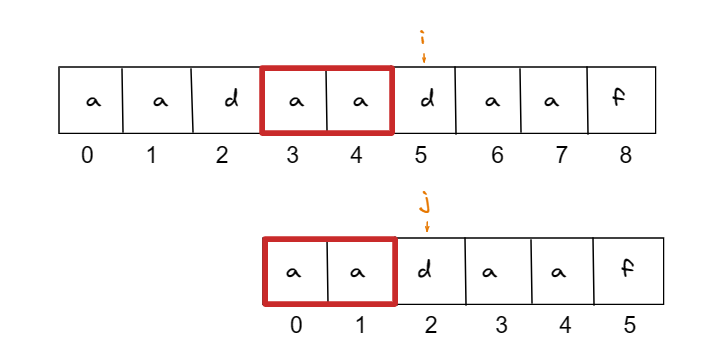
KMP算法就是利用前缀表来回退,减少匹配次数。前后缀相等,后缀在前一次匹配的时候跟匹配串相等,那下一次匹配直接跳到相等前缀的后一个字符开始匹配就行。
前缀表如何计算?
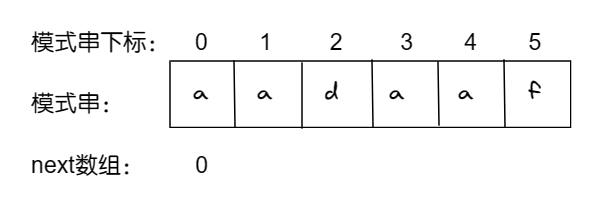
我们很清楚 ‘a’ 没有前缀,也没有后缀,所以它的最长相等前后缀为 0。
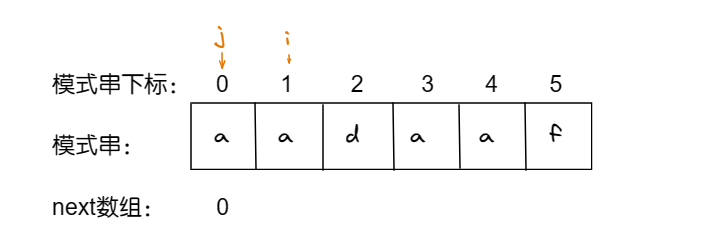
我们定义, j 为 前缀表的尾(而且也是最长相等前后缀的长度),i 为后缀的表的尾。
当 s[j] 和 s[i] 相等,说明此时最长相等前后缀的长度+1,所以 j++,然后更新前缀表next[i] = j,i 也往后挪。
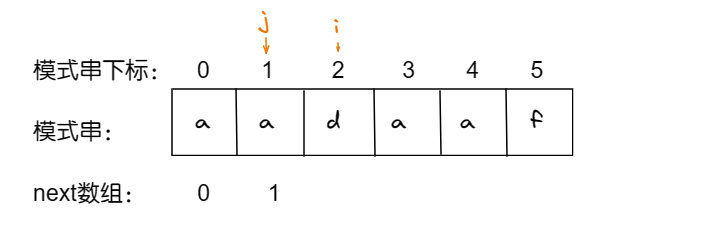
当 s[j] 和 s[i] 不相等,说明此时的最长相等前后缀并没有长,j 要往回退,怎么退,根据 next[j - 1] 往前退。退多少,退到 s[j] 和 s[i] 相等或者 j = 0为止。
KMP 实现
class Solution {
public:
void getNext(int *next,const string& s) {
// j 表示最长相等前后缀的前缀尾,同时是最长相等前后缀的长度,
// i 表示最长相等前后缀的后缀尾
// next[i] 表示最长相等前后缀的长度
int j = 0;
next[0] = 0;
for(int i = 1; i < s.size(); i++) {
// 当s[i] != s[j],则 j 要回退到 s[i] == s[j], 所以是while。
while(j > 0 && s[j] != s[i])
j = next[j - 1];
if(s[j] == s[i]) j++;
next[i] = j; //更新next数组
}
}
int strStr(string haystack, string needle) {
int next[needle.size()];
getNext(next, needle);
int j = 0;
for(int i = 0; i < haystack.size(); i++) {
while(j > 0 && needle[j] != haystack[i])
j = next[j - 1];
if(needle[j] == haystack[i]) j++;
if(j == needle.size()) return (i - needle.size() + 1);
}
return -1;
}
};
459.重复的子字符串
给定一个非空的字符串 s ,检查是否可以通过由它的一个子串重复多次构成。

我的题解
KMP做法
class Solution {
public:
void getNext(int *next, const string& s) {
int j = 0;
next[0] = 0;
for(int i = 1; i < s.size(); i++) {
while(j > 0 && s[i] != s[j]) j = next[j - 1];
if(s[i] == s[j]) j++;
next[i] = j;
}
}
bool repeatedSubstringPattern(string s) {
int next[s.size()];
getNext(next, s);
string t = s + s;
int j = 0;
for(int i = 1; i < t.size() - 1; i++) {
while(j > 0 && s[j] != t[i]) j = next[j - 1];
if(s[j] == t[i]) j++;
if(j == s.size()) return true;
}
return false;
}
};

t = s + s,掐头去尾,当在 t 中 找到 s 的匹配项,说明 s 是由它的一个子串重复多次构成。
代码随想录
移动匹配
class Solution {
public:
bool repeatedSubstringPattern(string s) {
string t = s + s;
t.erase(t.begin()); t.erase(t.end() - 1); // 掐头去尾
if (t.find(s) != std::string::npos) return true; // r
return false;
}
};
t 复制两遍 s,掐头去尾,判断 t 中是否出现 s
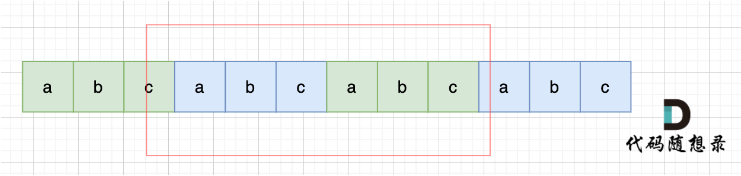
KMP
class Solution {
public:
void getNext (int* next, const string& s){
next[0] = -1;
int j = -1;
for(int i = 1;i < s.size(); i++){
while(j >= 0 && s[i] != s[j + 1]) {
j = next[j];
}
if(s[i] == s[j + 1]) {
j++;
}
next[i] = j;
}
}
bool repeatedSubstringPattern (string s) {
if (s.size() == 0) {
return false;
}
int next[s.size()];
getNext(next, s);
int len = s.size();
if (next[len - 1] != -1 && len % (len - (next[len - 1] + 1)) == 0) {
return true;
}
return false;
}
};
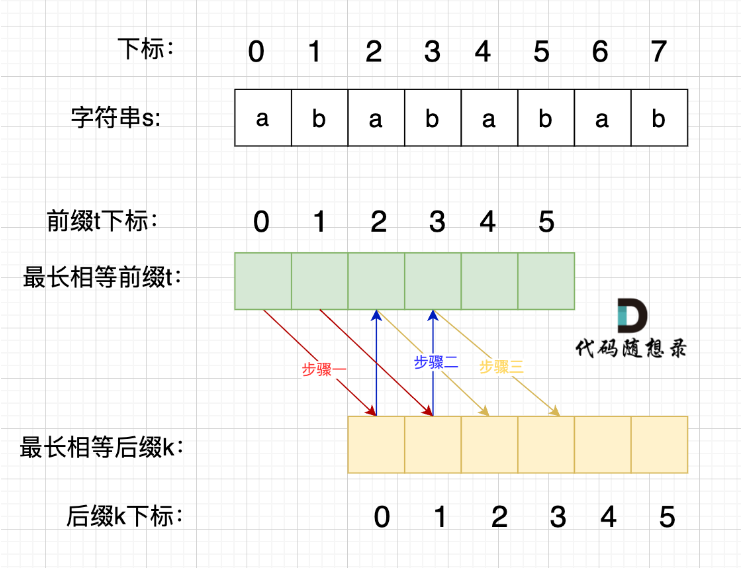
步骤一:因为 这是相等的前缀和后缀,t[0] 与 k[0]相同, t[1] 与 k[1]相同,所以 s[0] 一定和 s[2]相同,s[1] 一定和 s[3]相同,即:,s[0]s[1]与s[2]s[3]相同 。
步骤二: 因为在同一个字符串位置,所以 t[2] 与 k[0]相同,t[3] 与 k[1]相同。
步骤三: 因为 这是相等的前缀和后缀,t[2] 与 k[2]相同 ,t[3]与k[3] 相同,所以,s[2]一定和s[4]相同,s[3]一定和s[5]相同,即:s[2]s[3] 与 s[4]s[5]相同。
步骤四:循环往复。
所以字符串s,s[0]s[1]与s[2]s[3]相同, s[2]s[3] 与 s[4]s[5]相同,s[4]s[5] 与 s[6]s[7] 相同。
正是因为 最长相等前后缀的规则,当一个字符串由重复子串组成的,最长相等前后缀不包含的子串就是最小重复子串。














 207
207











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









