







数据库优化
为什么进行数据库优化呢?
如今我们的数据量都很大,表的字段也越来越多,如果数据库不进行优化,改变查询速度,查询会很慢,用户进行访问的时候会很影响体验,所以,数据库优化是必要的
数据库优化带来的好处
-
可以避免网站页面出现访问错误
就比如慢查询很多(产生原因:数据查询慢,表特别大或者是忘加索引)
数据库连接超时的情况(产生原因:数据库连接池满了)
-
减少很多数据库问题,很多问题都是低效的查询造成的
-
可以避免因阻塞造成数据无法提交(超时或阻塞)
优化方案
不确定字段长度的时候用varchar代替char
对于一个字段来说,不确定长度varchar更适合,char是定长,数据长度小于char给定的长度,造成浪费,varchar是变长字段,实际长度是数据的长度,节省储存空间,对于查询来说在一个较小的字段内搜索,效率更高。char很适合固定长度的字符串,从检索效率上来说,char > varchar ,所以知道长度的话char较为适合,比如MD5
避免在where子句中使用or来连接条件
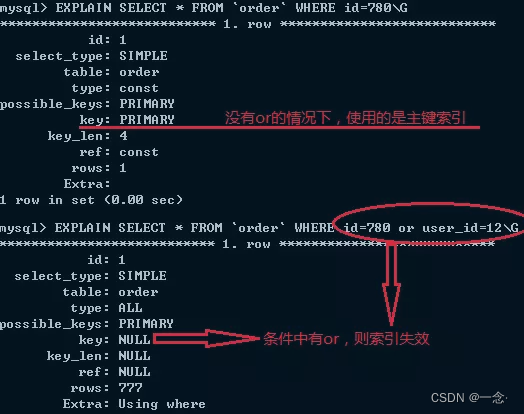
如图可看出使用or会导致索引失效,如果条件中有or,只要一个条件没有索引,其他字段有索引也不会使用
用or的情况下
-
不用索引,进行一次全表扫描就可以了
-
使用索引,一个走索引,一个不走,结果就是全表扫描+索引扫描+合并,
这样一比较,mysql优化器肯定选择不走索引,也就说明为啥其他字段有索引也不会使用
尽量使用数值替代字符串类型
原因:
1:因为引擎在处理查询和连接时会逐个比较字符串中每一个字符;
2:而对于数字型而言只需要比较一次就够了;
3:字符会降低查询和连接的性能,并会增加存储开销
查询尽量避免返回大量数据
如果查询返回数据量很大,就会造成查询时间过长,网络传输时间过长。
使用explain分析你SQL执行计划
SQL很灵活,一个需求可以很多实现,那哪个最优呢?SQL提供了explain关键字,它可以分析你的SQL执行计划,看它是否最佳。Explain主要看SQL是否使用了索引
- EXPLAIN SELECT * FROM student WHERE id = 1
type:
ALL 全表扫描,没有优化,最慢的方式
index 索引全扫描
range 索引范围扫描,常用语<,<=,>=,between等操作
ref 使用非唯一索引扫描或唯一索引前缀扫描,返回单条记录,常出现在关联查询中
eq_ref 类似ref,区别在于使用的是唯一索引,使用主键的关联查询
const 当查询是对主键或者唯一键进行精确查询,系统会把匹配行中的其他列作为常数处理
null MySQL不访问任何表或索引,直接返回结果
System 表只有一条记录(实际中基本不存在这个情况)
-
性能排行:
System > const > eq_ref > ref > range > index > ALL
给字段加索引
注意1:
-
有些情况会导致索引失效
-
sql语句中使用or,≠ <>
-
不符合最左前缀匹配
-
列进行运算
-
使用函数
-
类型不匹配(where id ='123’和where id = 123,不加单引号时,是字符串跟数字的比较,它们类型不匹配,MySQL会做隐式的类型转换,把它们转换为数值类型再做比较)
注意2:什么情况下不利于建立索引
-
数据量较少
-
字段中数据重复太多,比如:性别
-
经常增删改
-
参与列计算
-
where条件中用不到的字段
where中使用默认值代替null
EXPLAIN
SELECT * FROM student WHERE age IS NOT NULL
EXPLAIN
SELECT * FROM student WHERE age>0
asc和desc混用会导致索引失效
select * from _t where a=1 order by b desc, c asc
高级sql优化
批量插入性能提升
多次提交:
INSERT INTO student (id,NAME) VALUES(4,'name1');
INSERT INTO student (id,NAME) VALUES(5,'name2');
批量提交:
INSERT INTO student (id,NAME) VALUES(4,'name1'),(5,'name2');
-
默认新增SQL有事务控制,导致每条都需要事务开启和事务提交;而批量处理是一次事务开启和提交。自然速度飞升
-
数据量小体现不出来
批量删除优化
#一次删除10万或者100万+?
delete from student where id <100000;
#分批进行删除,如每次500
for(){
delete student where id<500;
}
一次性删除太多数据,可能造成锁表,会有lock wait timeout exceed的错误,所以建议分批操作
inner join 、left join、right join,优先使用inner join
三种连接如果结果相同,优先使用inner join,如果使用left join左边表尽量小
inner join 内连接,只保留两张表中完全匹配的结果集
left join会返回左表所有的行,即使在右表中没有匹配的记录
right join会返回右表所有的行,即使在左表中没有匹配的记录
原因:
-
如果inner join是等值连接,返回的行数比较少,所以性能相对会好一点
-
同理,使用了左连接,左边表数据结果尽量小,条件尽量放到左边处理,意味着返回的行数可能比较少。这是mysql优化原则,就是小表驱动大表,小的数据集驱动大的数据集,从而让性能更优
参考文章:
https://blog.csdn.net/weixin_53601359/article/details/115553449
https://blog.csdn.net/chenpengjia006/article/details/101228943















 232
232











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









