






- 实验目的
1、熟悉Hadoop环境安装
2、掌握MapReduce的编程方法
- 实验环境
Windows 10操作系统
- 实验内容
1、Hadoop单机配置(非分布式)
Hadoop 默认模式为非分布式模式,无需进行其他配置即可运行。非分布式即单 Java 进程,方便进行调试。Hadoop 附带了丰富的例子(运行 ./bin/hadoop jar ./share/hadoop/mapreduce/ hadoop-mapreduce-examples-2.6.0.jar 可以看到所有例子),包括 wordcount、terasort、join、grep 等。
本部分实验选择运行 grep 例子,将 input 文件夹中的所有文件作为输入,筛选当中符合正则表达式 dfs[a-z.]+ 的单词并统计出现的次数,最后输出结果到 output 文件夹中。
- tar xvfz hadoop-2.6.0.tar.gz
- mv hadoop-2.6.0 hadoop
- cd /home/chen/hadoop
- mkdir ./input
- cp ./etc/hadoop/*.xml ./input # 将配置文件作为输入文件
- ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output 'dfs[a-z.]+'
- cat ./output/* # 查看运行结果
执行成功后如下所示,输出了作业的相关信息,输出的结果是符合正则的单词 dfsadmin 出现了1次。
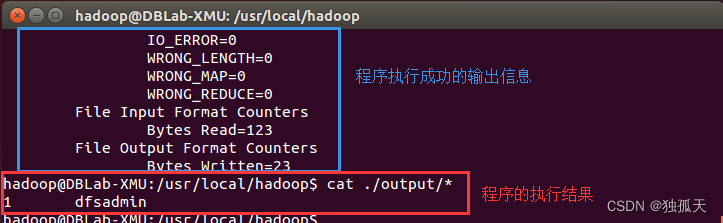
注意,Hadoop 默认不会覆盖结果文件,因此再次运行上面实例会提示出错,需要先将 ./output 删除。
- rm -r ./output
2、Hadoop伪分布式配置
Hadoop 可在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。Hadoop 的配置文件位于 hadoop/etc/hadoop/中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
在终端执行命令gedit ./etc/hadoop/core-site.xml修改配置文件core-site.xml ,将当中的
- <configuration>
- </configuration>
修改为下面配置:
- <configuration>
- <property>
- <name>hadoop.tmp.dir</name>
- <value>file:/home/chen/hadoop/tmp</value>
- <description>Abase for other temporary directories.</description>
- </property>
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://localhost:9000</value>
- </property>
- </configuration>
同样的,修改配置文件 hdfs-site.xml:
- <configuration>
- <property>
- <name>dfs.replication</name>
- <value>1</value>
- </property>
- <property>
- <name>dfs.namenode.name.dir</name>
- <value>file:/home/chen/hadoop/tmp/dfs/name</value>
- </property>
- <property>
- <name>dfs.datanode.data.dir</name>
- <value>file:/home/chen/hadoop/tmp/dfs/data</value>
- </property>
- </configuration>
注:Hadoop 的运行方式是由这两个配置文件决定的(运行 Hadoop 时会读取配置文件),因此如果需要从伪分布式模式切换回非分布式模式,需要删除 core-site.xml中的配置项。此外,伪分布式虽然只需要配置 fs.defaultFS 和 dfs.replication 就可以运行,不过若没有配置 hadoop.tmp.dir 参数,则默认使用的临时目录为/tmp/hadoo-hadoop,而这个目录在重启时有可能被系统清理掉,因此每次重启系统必须重新执行format才行。
配置完成后,执行 NameNode 的格式化:
- ./bin/hdfs namenode -format
成功的话,会看到 “successfully formatted” 和 “Exitting with status 0” 的提示,若为 “Exitting with status 1” 则是出错。
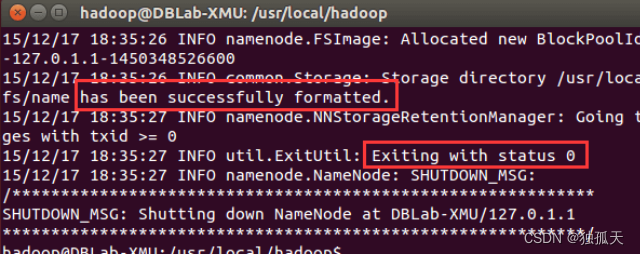
注:如果在这一步时提示 Error: JAVA_HOME is not set and could not be found. 的错误,则说明之前设置 JAVA_HOME 环境变量那边就没设置好,请按教程先设置好 JAVA_HOME 变量,否则后面的过程无法进行。
随后执行以下命令开启 NameNode 和 DataNode 守护进程。
- ./sbin/start-dfs.sh
若出现如下SSH提示,输入yes即可。

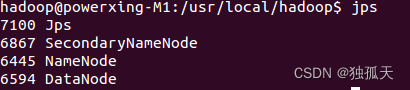
启动完成后,可以通过命令 jps 来判断是否成功启动,若成功启动则会列出如下进程: “NameNode”、”DataNode” 和 “SecondaryNameNode”(如果 SecondaryNameNode 没有启动,请运行 sbin/stop-dfs.sh 关闭进程,然后再次尝试启动尝试)。如果没有 NameNode 或 DataNode ,那就是配置不成功,请仔细检查之前步骤,或通过查看启动日志排查原因。
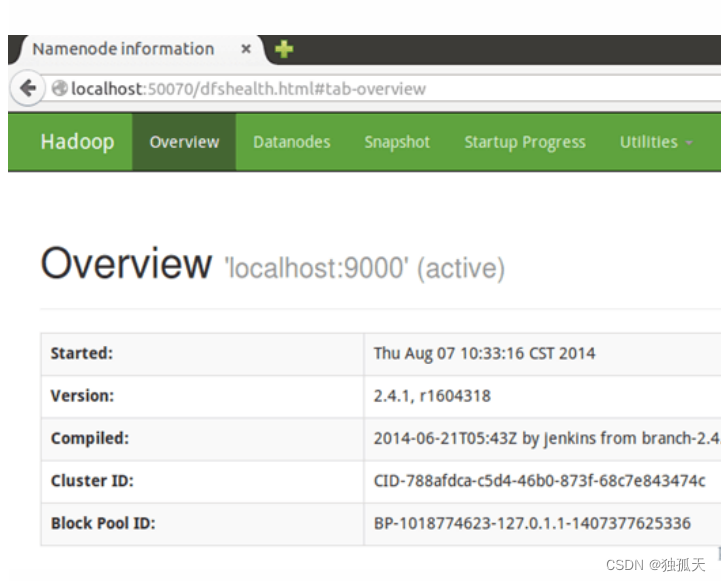
成功启动后,可以访问 Web 界面 http://localhost:50070 查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。
3、运行Hadoop伪分布式实例
上面的单机模式,grep 例子读取的是本地数据,伪分布式读取的则是 HDFS 上的数据。要使用 HDFS,首先需要在 HDFS 中创建用户目录:
- ./bin/hdfs dfs -mkdir -p /user/hadoop
接着将 ./etc/hadoop 中的 xml 文件作为输入文件复制到分布式文件系统中,即将 /home/chen/hadoop/etc/hadoop 复制到分布式文件系统中的 /user/hadoop/input 中。使用的是 hadoop 用户,并且已创建相应的用户目录 /user/hadoop ,因此在命令中使用其对应的绝对路径 /user/hadoop/input:
- ./bin/hdfs dfs -mkdir /user/hadoop/input
- ./bin/hdfs dfs -put ./etc/hadoop/*.xml /user/hadoop/input
复制完成后,可以通过如下命令查看文件列表:
- ./bin/hdfs dfs -ls /user/hadoop/input
伪分布式运行 MapReduce 作业的方式跟单机模式相同,区别在于伪分布式读取的是HDFS中的文件。
- ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep /user/hadoop/input /user/hadoop/output 'dfs[a-z.]+'
查看运行结果的命令(查看的是位于 HDFS 中的输出结果):
- ./bin/hdfs dfs -cat /user/hadoop/output/*
结果如下,注意到刚才已经更改了配置文件,所以运行结果不同。
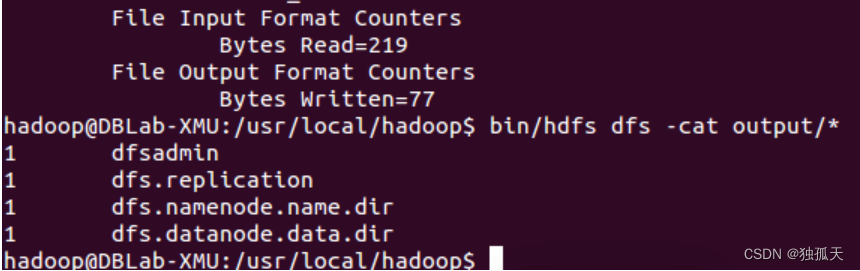
也可以通过cp命令将运行结果取回到本地:
- rm -r ./output # 先删除本地的 output 文件夹(如果存在)
- ./bin/hdfs dfs -get /user/hadoop/output ./output # 将 HDFS 上的 output 文件夹拷贝到本机
- cat ./output/*
Hadoop 运行程序时,输出目录不能存在,否则会提示错误 “org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://localhost:9000/user/hadoop/output already exists” ,因此若要再次执行, 需要执行如下命令删除 output 文件夹:
- ./bin/hdfs dfs -rm -r output # 删除 output 文件夹
下次启动 hadoop 时,无需进行 NameNode 的初始化,只需要运行 ./sbin/start-dfs.sh 就可以。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









