






目录
一、论文概况
本文是一篇SIGIR-2018的论文,研究内容是基于强化学习的对话推荐系统,与本人的毕设题目相关。在这篇文章中,作者提出了一个统一的深度强化学习(DRL)框架,融合了对话系统和推荐系统,提出对话推荐系统以达到更好的推荐效果。
definition:
推荐系统 (recommender system):指的是从用户过去的购买习惯中学习用户的兴趣,从而给用户推荐合适的商品,是一个单轮交互的过。
任务型对话系统 (task-oriented dialogue system):通过多轮对话,在会话过程中,捕捉用户的兴趣等,完成一个特定的任务,是一个多轮交互的过程。
对话推荐系统 (conversational recommender system, CRS):由于推荐系统更多的是去关注用户过去的偏好,但是用户当前的兴趣可能已经改变。而对话系统更多的是关注当前session的用户兴趣,而不太关注用户历史的兴趣,所以这样做出来的推荐可能会偏离用户长期的购买习惯。所以在用户决策的过程中,历史信息与当前的信息都很重要,结合这两点因素,就提出了对话推荐系统,在对话推荐系统中,系统与用户将发生多轮对话,系统结合用户的历史兴趣,以及当前对话中捕捉到的用户兴趣,对用户进行商品推荐。
二、introduction
- 作者观察到推荐系统以及对话系统各自的优势和弊端,想到是否可以把二者结合起来,达到更好的推荐效果。
- 在具体设计中,作者设计了一个基于强化学习的模型,进行对话推荐。若用户已经提供了足够信息的时候,就执行推荐;若用户尚未提供足够的信息,则对用户进行反问,收集更多的信息。
- 另外,对于用户的兴趣,作者使用Facet-Value Pairs的形式进行捕捉。其中Facet可以理解为商品的某一个属性,Value代表该属性的一个具体值。(比如Facet=颜色,Value=红色,代表用户选取的是颜色为红色的商品)
三、method
对话系统的三大部分:
1)Natural Language Understanding (NLU):NLU模块的作用是对用户的输入进行解析,通常包括意图识别,以及命名实体识别 (通常这些命名实体是和商品紧密相连的),由belief tracker实现
2)Data Management (DM):DM模块的作用是管理整个对话流程。通常是根据之前的对话以及用户当前的输入,决定当前时刻系统该做什么样的action,由policy network构建
3)Natural Language Generation (NLG):NLG模块的作用是根据DM模块的决策,输出一段流利的文字回复用户
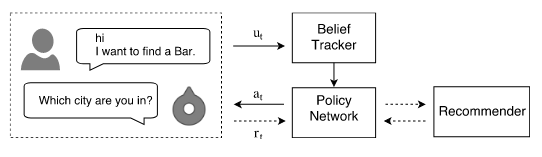
图1 对话推荐系统结构概览
图1介绍了该系统的整体结构。当用户有文本进来的时候,首先经过一个NLU模块,这里是使用一个Belief Tracker来实现的,理解用户的意图。进而进入到DM模块,这里使用了一个Policy Network,去识别当前的场景并作出决策。如果当前系统判断信息已经足够了,就跳转到Recommender模块,进行推荐,并把推荐的结果反馈给用户,对话结束;如果当前系统判断信息并不充足,此时需要就直接对用户进行反问。
A.Belief Tracker
facet search:当用户在电商网站购买商品的时候,经常会通过faceted search进行商品搜索。所以对于对话机器人来说,也可以通过对用户询问facet,来缩小商品的推荐范围,进而提高推荐的质量。

在本文中,作者通过facet-value pairs来捕捉用户的兴趣。其中,用户对于每个属性的选择,表示为 (f,v) 的形式, f代表facet, v 代表对应的取值。每一个facet-value pair就可以代表对商品的一个限制。例如, (color , red) 是一个面值对,它限制项目的颜色必须为红色。
belief tracker就是用于从用户对话中提取出facet-value对
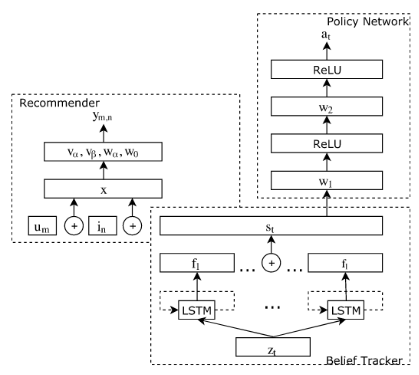
图2:对话推荐模型结构
belief tracker 的结构如图二右下位置表示
在对话中,我们把用户在时间步 t的文本表示成 et,belief tracker的输入是 n-gram 向量z t,z t 的维度是 n-gram 词汇表的大小。
![]()
接下来,截至当前时间的 n-gram 序列由 LSTM 网络编码为向量 ht ,
![]()
然后将其输出到 softmax 激活层转换为整个可用值的概率分布 。对于具有 j 个可能值的facect ,softmax 激活层的输出大小为 V j。
![]()
其中 i代表第i 个facet,fi是面 i 的学习向量表示,i ≤ l。
在每一轮中,所有 fi 都相互异或以形成代理对当前会话中对话状态的当前belief。
![]()
通过直接使用 LSTM 网络的学习输出,我们为以下模块保留了来自belief tracker的不确定性。
B.Recommender System
获得了足够的信息时,就可以进行推荐了。这里作者使用了Factorization Machine (FM)作为推荐模型,因为FM可以结合不同的特征,,例如s t 来一起训练推荐模型
recommender system的结构如图二左上所示。
图2:对话推荐模型结构
令U表示用户,I表示item。对于数据集中的 M 个用户和 N 个item,用户和item分别表示为集合:{u1 , u2 , ..., u M } 和 {i 1 , i 2 ,..., i N }
输入特征向量x 是 one-hot 编码的用户/item向量的concatenation,其中向量中唯一不为零的元素对应于编码信息的索引,以及对话的belief,
![]()
![]()
其中,m和n是用户和商品分别的index,其中 m 和 n 表示in由um评分,输出的ymn表示用户m对商品n的反馈,可以是显式反馈的评分,也可以是隐式反馈的 0-1 标量。我们使用 2 路 (K = 2)Factorization Machine :
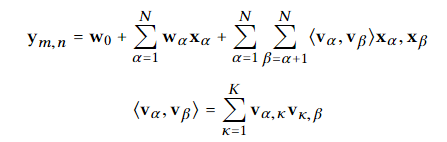
上述式子是FM的基本公示,其中
![]()
对于评分预测,使用随机梯度下降来最小化预测评分与真实评分之间的 L2 损失。目标函数随数据大小线性缩放。
在使用经过训练的模型进行推荐时,首先取每个facet 的belief的最大值,以获得值的 L个categorical分布,每个facet一个。facet的组合形成新的分布,概率为L个 原来概率值的乘积。然后我们保留u个最可能的组合,并使用它们的facet value从整个项目集中检索项目。检索到的项目形成候选集。然后,我们使用经过训练的模型根据候选人的评分对他们进行重新排名。
C.Deep Policy Network
策略网络的结构如图二右上所示
在每一个时间步,强化学习模型基于对话状态 (dialogue state),选择一个action
该强化学习模型有4个基本模块组成:state S ,action A ,reward R,policy π(a|s)
state: state是从agent角度下的当前环境描述。在该任务中,就是conversation context的description,也就是belief tracker的输出,
![]()
action: action是当前是当前时间下做的决策的描述。在这篇文章中,主要有两种类型的action,一种是对应 l 个facet,请求对应facet的值 {a1,a2,…,al} 。另一种是对应作出推荐 arec。
reward: reward是指agent从环境交互中获得的benefit/penalty。在每一轮, 给定当前状态 st ,agent选择一个action at ,根据policy。并且立刻得到一个reward rt ,表示当前的决策有多好,之后,状态就会转变成 s′ 。
policy: policy指的是模型的学习目标,用 ![]() 表示。这个policy代表着当前处于状态 st,执行action at的概率。目标函数为:
表示。这个policy代表着当前处于状态 st,执行action at的概率。目标函数为:
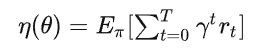

gradient就变成了

这里 G t 是从时间步 t 开始到最终时间步 T 的奖励或回报的总和。在本文的例子中,总是有对话的终止状态,例如,用户离开聊天或用户被成功推荐给目标。在强化学习文献中,每一种这样的序列都被称为一个episode。这使得能够使用梯度下降方法直接优化策略网络中的参数θ。请注意,如果随机初始化 θ,则学习可能会完全失败。为了解决这个问题,这篇论文采用了一种rule-based policy,来初始化参数。
D.模型训练过程
基于Yelp公开数据集和Amazon Mechanical Turks 创建的数据集,按照非常简单的议程创建了模拟用户来与代理进行交互。使用模拟用户用于预训练模型。

预训练过程中模拟用户和系统的交互过程:

- rq:negative reward,当用户退出对话
- rp :positive reward,当用户成功在推荐中找到目标
- rc:small negative reward,防止对话过长
E.实验过程
baseline:基于最大熵规则(Maximum Entropy)
该方法计算每个未知方面的熵,并选择具有最大熵的facet作为下一个agent要询问的facet。当没有项目满足当前对话belief(即没有符合用户期望的商品)或所有facet都已知,或对话长度超过对话回合的最大限制时,它会停止询问。因此它是一种贪心方法。该baseline是基于规则的策略,因为agent总是询问各个方面,直到收集到所有fecet的值,在这种情况下,它会向用户提出推荐。本文还使用了最大熵方法的变体,在做出推荐之前总是询问 K 个slot (K < 5)。
将询问所有facet的baseline命名为"MaxEntFull",将仅询问 K 个面的baseline命名为"MaxEnt@K
Evaluation Methodology:

离线实验:
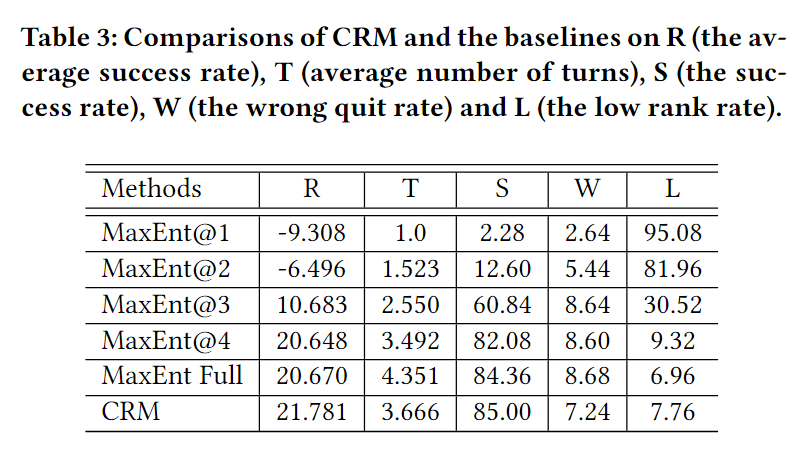
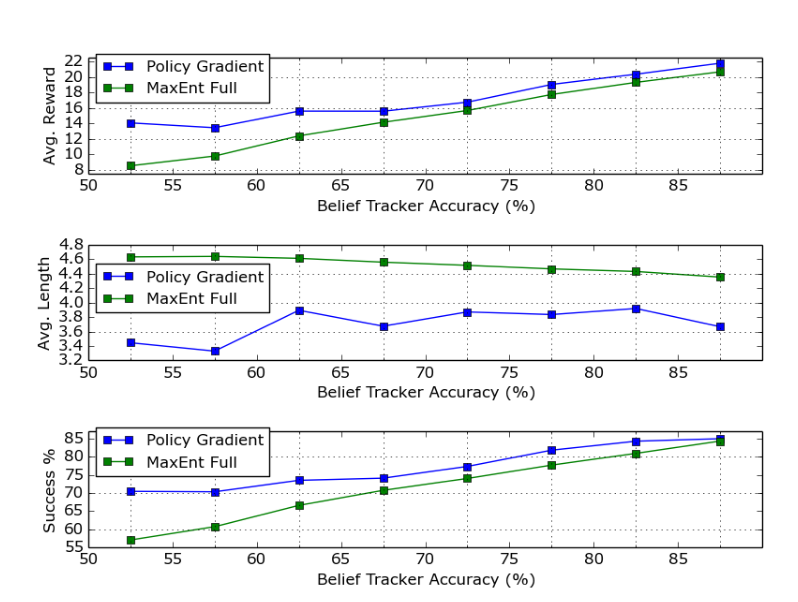
不同belief tracker准确率对两种方法的影响
在线实验:
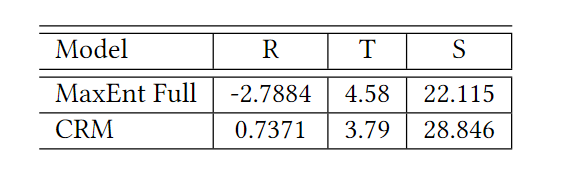
四、总结
本篇文章发表于2018,处于基于强化学习的对话话推荐的初期,论文提出了一个基于深度强化学习的框架,将对话系统和推荐系统相结合,以建立一个个性化的对话式推荐代理。论文还提出了一种将用户对话历史表示为半结构化用户查询的方法,优化用户体验和商业指标。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









