






记录一下自学Java基础的知识点,以后还会慢慢补充,先写这么多吧。
Java基础知识点
Java基础学习笔记
JRE是java运行环境,包含JVM和运行时所需要的核心类库(JVM可以保证Java跨平台)
JDK是java程序开发工具包,包含JRE和开发人员使用的工具。其中的开发工具:编译工具(javac.exe)和运行工具(java.exe)
-
Java内建的
package机制是为了避免class命名冲突; -
JDK的核心类使用
java.lang包,编译器会自动导入; -
JDK的其它常用类定义在
java.util.*,java.math.*,java.text.*,……; -
包名推荐使用倒置的域名,例如
org.apache; -
如果有两个
class名称相同,例如,mr.jun.Arrays和java.util.Arrays,那么只能import其中一个,另一个必须写完整类名。
如果有很多.class文件,散落在各层目录中,肯定不便于管理。如果能把目录打一个包,变成一个文件,就方便多了。jar包就是用来干这个事的,它可以把package组织的目录层级,以及各个目录下的所有文件(包括.class文件和其他文件)都打成一个jar文件,这样一来,无论是备份,还是发给客户,就简单多了。jar包实际上就是一个zip格式的压缩文件,而jar包相当于目录。如果我们要执行一个jar包的class,就可以把jar包放到classpath中。
Java基本数据类型

除了上述基本类型的变量,剩下的都是引用类型。例如,引用类型最常用的就是String字符串。引用类型的变量类似于C语言的指针,它内部存储一个“地址”,指向某个对象在内存的位置。
整数运算:
-
整数运算的结果永远是精确的;
-
运算结果会自动提升;
-
可以强制转型,但超出范围的强制转型会得到错误的结果;
-
应该选择合适范围的整型(
int或long),没有必要为了节省内存而使用byte和short进行整数运算。
浮点数运算:
-
浮点数常常无法精确表示,并且浮点数的运算结果可能有误差;
-
比较两个浮点数通常比较它们的差的绝对值是否小于一个特定值;
-
整型和浮点型运算时,整型会自动提升为浮点型;
-
可以将浮点型强制转为整型,但超出范围后将始终返回整型的最大值。
字符和字符串:
-
Java的字符类型
char是基本类型,字符串类型String是引用类型; -
基本类型的变量是“持有”某个数值,引用类型的变量是“指向”某个对象;
-
引用类型的变量可以是空值
null; -
要区分空值
null和空字符串""。
数组:
-
数组是同一数据类型的集合,数组一旦创建后,大小就不可变;
-
可以通过索引访问数组元素,但索引超出范围将报错;
-
数组元素可以是值类型(如int)或引用类型(如String),但数组本身是引用类型。
-
遍历数组可以使用
for循环,for循环可以访问数组索引,for each循环直接迭代每个数组元素,但无法获取索引;使用
Arrays.toString()可以快速获取数组内容。
方法重载
方法的注意事项:
- 方法不能嵌套定义
- void方法无返回值,可以省略return,也可以单独书写return,但后面不加数据
方法的通用格式:
public static 返回值类型 方法名(参数){
方法体;
return 数据;
}
- 多个方法在同一个类中
- 多个方法具有相同的方法名
- 多个方法的参数不同、类型不同或者数量不同
- 重载与返回值无关,即不能通过返回值判定两个方法是否构成重载
//加法重载
public class MethodDemo{
public static void main(String[] args){
int result1 = sum(10,20);
System.out.println(result1);
double result2 = sum(10.0,20.0);
System.out.println(result2);
int result3 = sum(10, 20, 30);
System.out.println(result3);
}
public static int sum(int a, int b){
return a + b;
}
public static double sum(double a, double b){
return a + b;
}
public static int sum(int a, int b, int c){
return a + b + c;
}
}
方法的参数传递
-
对于基本类型的参数,形式参数的改变,不影响实际参数的值
-
对于引用类型的参数,形式参数的改变,影响实际参数的值(如数组)
System.out.println("内容"); //输出内容并换行
System.out.print("内容"); //输出内容不换行
System.out.println(); //起到换行的作用
//数组遍历方法
public class MethodTest{
public static void main(String[] args){
int arr[] = {11, 22, 33, 44, 55};
printArray(arr);
}
public static void printArray(int arr[]){
System.out.println("[");
for(int x = 0;x<arr.length;x++){
if(x==arr.length-1){
System.out.print(arr[x]);
}else{
System.out.print(arr[x]+", ");
}
System.out.println("]");
}
}
}
类和对象
类的重要性:是Java程序的基本组成单位,是对现实生活中一类具有共同属性和行为的事物的抽象,确定对象将会拥有的属性和行为。类是对象的数据类型。
- 属性:在类中通过成员变量来体现(类中方法外的变量)
- 方法:在类中通过成员方法来实现(和前面的方法相比去掉static即可)
对象:客观存在的事物皆为对象,是类的实体
创建对象:类名 对象名 = new 类名();
var关键字:
有些时候,类型的名字太长,写起来比较麻烦。例如:
StringBuilder sb = new StringBuilder(); //语句1
这个时候,如果想要省略变量类型,可以使用var关键字:
var sb = new StringBuilder(); //语句2
编译期会根据赋值语句自动推断出变量sb的类型是StringBuilder。对编译器来说,语句2实际上会自动变成语句1。
成员变量和局部变量的区别:
- 成员变量在类中方法外,局部变量在方法内或者方法声明上
- 成员变量在堆内存,局部变量在栈内存
- 成员变量随着对象的存在而存在,随着对象的消失而消失;局部变量随着方法的调用而存在,随着方法的调用完毕而消失
- 成员变量有默认的初始化值;局部变量没有默认的初始化值,必须先定义,赋值,才能使用
private关键字:
- 是一个权限修饰符
- 可以修饰成员(成员变量和成员方法)
- 作用是保护成员不被别的类使用,被private修饰的成员只在本类中才能被访问
其他类使用private修饰的成员变量的方法:
get变量名()方法:用于获取成员变量的值,用public修饰set变量名(参数)方法,用于设置成员变量的值,用public修饰
this关键字:
- this修饰的变量用于指代成员变量
- 方法的形参如果与成员变量同名,不带this修饰的变量指的是形参,而不是成员变量
- 方法的形参没有与成员变量同名,不带this修饰的变量指的是成员变量
- this的使用是为了解决局部变量隐藏成员变量的问题
- 方法被哪个对象调用,this就代表哪个对象
封装:
提高代码的安全性和复用性
构造方法:
-
构造方法是一种特殊的方法,因此和普通的方法一样也可以重载
-
构造方法的作用是创建对象,功能主要是完成对象数据的初始化
-
构造方法的名字必须和类名一致,在创建对象时被调用
-
如果没有定义构造方法,系统将给出一个默认的无参构造方法;如果定义了构造方法,系统将不再提供默认的构造方法
-
如果自定义了带参构造方法,还要使用无参构造方法,就必须再写一个无参构造方法
-
因此无论是否使用,都要手工书写无参构造方法
字符串
- String类在Java.lang包下,使用的时候不需要导包
- String类代表字符串,Java程序中的所有字符串文字都被称为实现此类的实例,即Java程序中的所有的双引号字符串都是String类的对象
- 字符串不可变,它们的值在创建后不能被更改,但是可以被共享
- 字符串效果上相当于字符数组,但是底层原理是字节数组
String对象的特点:
- 通过new创建的字符串对象,每一次new都会申请一个内存空间,虽然内容可能相同,但是地址值不同
- 以**“ ”**方式给出的字符串,只要字符串序列相同(顺序和大小写),无论在程序代码中出现几次,JVM都只会建立一个String对象,并在字符串池(常量池)中进行维护
字符串的比较:
在Java中,判断值类型的变量是否相等,可以使用==运算符。但是,判断引用类型的变量是否相等,==表示“引用是否相等”,或者说,是否指向同一个对象。要判断引用类型的变量内容是否相等,必须使用equals()方法。
- 基本类型:比较的是数据值是否相同
- 引用类型:比较的是地址值是否相同
字符串是对象,它比较内容是否相同,是通过一个方法来实现的,这个方法是:equals()
StringBuilder:
对字符串进行拼接操作时,每次拼接都会构建一个新的String对象,既耗时又浪费内存空间,而这种操作还不可避免,因此使用java提供的StringBuilder类来解决这个问题
使用时不需要导包,是一个可变(内容可变)的字符串类,可以把它看成是一个容器
public StringBuilder append(任意类型) //添加数据,并返回对象本身
public StringBuilder reverse() //返回相反的字符串序列,也是对象本身
-
StringBuilder转换为String:
public String toString() // 通过toString()就可以实现把StringBuilder转换为String -
String转换为StringBuilder:
public StringBuilder(String s) //通过构造方法就可以实现把String转换为StringBuilder
集合基础
集合类的特点:提供一种存储空间可变的存储模型,存储的数据容量可以发生改变
ArrayList:
- 可调整大小的数组实现
- :是一种特殊的数据类型,泛型(使用方法:在出现E的地方使用引用的数据类型替换即可)
ArrayList构造方法和添加方法:
public ArrayList() //创建一个空的集合对象
public boolean add(E e) // 将指定的元素追加到集合的末尾
public void add(int index,E element) //在此集合中的指定位置插入指定的元素
ArrayList集合常用方法:
public boolean remove(Object o) //删除指定的元素,返回删除是否成功
public E remove(int index) //删除指定索引处的元素,返回被删除的元素
public E set(int index,E element) //修改指定索引处的元素,返回被修改的元素
public E get(int index) //返回指定索引处的元素
public int size() //返回集合中的元素的个数
项目实战–学生管理系统
- Student类的编写:
package myStudent;
/*
学生类
快捷键:右键选择generate或者Alt+Fn+Insert
*/
public class Student {
//学号
private String sid;
//姓名
private String name;
//年龄
private String age;
//居住地
private String address;
public Student() {
}
public Student(String sid, String name, String age, String address) {
this.sid = sid;
this.name = name;
this.age = age;
this.address = address;
}
public String getSid() {
return sid;
}
public void setSid(String sid) {
this.sid = sid;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAge() {
return age;
}
public void setAge(String age) {
this.age = age;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
}
- StudentManager类的编写:
package myStudent;
import java.util.ArrayList;
import java.util.Scanner;
/*
学生管理系统
*/
public class StudentManager {
public static void main(String[] args) {
//创建集合对象,用于存储学生数据
ArrayList<Student> array = new ArrayList<Student>();
while (true) {
//用输出语句完成主界面的编写
System.out.println("--------欢迎来到学生管理系统--------");
System.out.println("1 添加学生");
System.out.println("2 删除学生");
System.out.println("3 修改学生");
System.out.println("4 查看所有学生");
System.out.println("5 退出");
System.out.println("请输入你的选择: ");
//用Scanner实现键盘录入数据
Scanner sc = new Scanner(System.in);
String line = sc.nextLine();
//用switch语句完成操作的选择
switch (line) {
case "1":
System.out.println("添加学生");
addStudent(array);
break;
case "2":
System.out.println("删除学生");
deleteStudent(array);
break;
case "3":
System.out.println("修改学生");
updateStudent(array);
break;
case "4":
System.out.println("查看所有学生");
findAllStudent(array);
break;
case "5":
System.out.println("谢谢使用");
System.exit(0); //JVM退出
}
}
}
//定义一个方法,用于添加学生信息
public static void addStudent(ArrayList<Student> array) {
//键盘录入学生对象所需要的数据,显示提示要输入何种信息
Scanner sc = new Scanner(System.in);
String sid;
//为了让程序能够回到这里,我们使用循环实现
while (true) {
System.out.println("请输入学生学号: ");
sid = sc.nextLine();
boolean flag = isUsed(array, sid);
if (flag) {
System.out.println("你输入的学号已经被使用,请重新输入");
} else {
break;
}
}
System.out.println("请输入学生姓名: ");
String name = sc.nextLine();
System.out.println("请输入学生年龄: ");
String age = sc.nextLine();
System.out.println("请输入学生居住地: ");
String address = sc.nextLine();
//创建学生对象,把键盘录入的数据赋值给学生对象的成员变量
Student s = new Student();
s.setSid(sid);
s.setName(name);
s.setAge(age);
s.setAddress(address);
//将学生对象添加到集合中
array.add(s);
//给出添加成功提示
System.out.println("添加成功");
}
//定义一个方法,用于查看学生信息
public static void findAllStudent(ArrayList<Student> array) {
//判断集合中是否有数据,如果没有显示提示信息
if (array.size() == 0) {
System.out.println("无信息,请先添加信息再查询");
return; //让程序不再往下执行
}
//显示表头信息
System.out.println("学号\t\t\t\t姓名\t\t年龄\t\t居住地");
//将集合中的数据取出按照对应格式显示学生信息,年龄显示补充“岁”
for (int i = 0; i < array.size(); i++) {
Student s = array.get(i);
System.out.println(s.getSid() + "\t" + s.getName() + "\t\t" + s.getAge() + "岁\t\t" + s.getAddress());
}
}
//定义一个方法,用于删除学生信息
public static void deleteStudent(ArrayList<Student> array) {
//键盘录入要删除学生的学号,显示提示信息
Scanner sc = new Scanner(System.in);
System.out.println("请输入你要删除的学生的学号:");
String sid = sc.nextLine();
int index = -1;
//遍历集合将对应学生对象从集合中删除
for (int i = 0; i < array.size(); i++) {
Student s = array.get(i);
if (s.getSid().equals(sid)) {
index = i;
break;
}
}
if (index == -1) {
System.out.println("该信息不存在,请重新输入");
} else {
array.remove(index);
System.out.println("删除学生成功");
}
}
//定义一个方法,用于修改学生信息
public static void updateStudent(ArrayList<Student> array) {
Scanner sc = new Scanner(System.in);
System.out.println("请输入你要修改的学生的学号: ");
String sid = sc.nextLine();
System.out.println("请输入学生新姓名:");
String name = sc.nextLine();
System.out.println("请输入学生新年龄:");
String age = sc.nextLine();
System.out.println("请输入学生新居住地:");
String address = sc.nextLine();
//创建学生对象
Student s = new Student();
s.setSid(sid);
s.setName(name);
s.setAge(age);
s.setAddress(address);
//遍历集合修改对应的学生信息
for (int i = 0; i < array.size(); i++) {
Student student = array.get(i);
if (student.getSid().equals(sid)) {
array.set(i, s);
break;
}
}
System.out.println("修改学生信息成功");
}
//定义一个方法,对信号是否被使用进行判断
public static boolean isUsed(ArrayList<Student> array, String sid) {
boolean flag = false;
for (int i = 0; i < array.size(); i++) {
Student s = array.get(i);
if (s.getSid().equals(sid)) {
flag = true;
break;
}
}
return flag;
}
}
继承
继承是面向对象三大特征之一,可以使得子类具有父类的属性和方法,还可以在子类中重新定义,追加属性和方法。继承体现的是种属关系,即A是B的一种或者B是A的一种
继承的格式:public class 子类名 extends 父类名{}
继承的好处和弊端:
- 提高了代码的复用性(多个类相同的成员可以放到同一个类中)
- 提高了代码的维护性(如果方法的代码需要修改,修改一处即可)
- 继承让子类与父类之间产生了关系,类的耦合性增强了,当父类发生变化时子类实现也不得不跟着变化,削弱了子类的独立性
继承中变量的访问特点(在子类方法中访问一个变量):
- 子类局部范围找
- 子类成员范围找
- 父类成员范围找
- 如果都没有就报错
super:
- this代表本类对象的引用
- super代表父类存储空间的标识(可以理解为父类对象引用)
- 它们都可以访问成员变量、成员方法、构造方法
继承中构造方法的访问特点:
子类中所有的构造方法默认都会访问父类中无参的构造方法
- 子类会继承父类中的数据,可能还会使用父类的数据,因此子类初始化之前一定要先完成父类数据的初始化
- 每一个子类构造方法的第一条语句默认都是:super()
如果父类中没有无参构造方法,只有带参构造方法,解决办法:
- 通过使用super关键字去显式的调用父类的带参构造方法
- 在父类中自己提供一个无参构造方法
继承中成员方法的访问特点(通过子类对象访问一个方法):
- 子类成员范围找
- 父类成员范围找
- 如果都没有就报错
super内存图:

方法重写
子类中出现了和父类中一模一样的方法声明
**方法重写的应用:**当子类需要父类的功能,而功能主体子类有自己特有内容时,可以重写父类中的方法,这样既沿袭了父类的功能,又定义了子类特有的内容
**@Overridde:**是一个注解,可以帮助我们检查重写方法声明的正确性
- 私有方法不能被重写(父类私有成员子类是不能继承的)
- 子类方法访问权限不能更低(public>默认>私有)
Java中继承的注意事项
- Java中类只支持单继承,不支持多继承
- Java中类支持多层继承
修饰符
包:
其实就是文件夹,作用就是对类进行分类管理
格式:package 包名;
- 手动建包
- 自动建包:javac -d . HelloWorld.java(执行时都要带包执行)
导包:
使用不同包下的类时,使用的时候要写类的全路径,写起来太麻烦了。为了简化带包的操作,Java提供了导包的功能
导包的格式:import 包名;
权限修饰符:

状态修饰符:
-
final(最终态)
final关键字是最终的意思,可以修饰成员方法,成员变量,类
final修饰的特点:
- 修饰方法:表明该方法是最终方法,不能被重写
- 修饰变量:表明该变量是常量,不能被再次赋值
- 修饰类:表明该类是最终类,不能被继承
- 修饰局部变量:
- 变量是基本类型:final修饰指的是最笨类型的数据值不能发生改变
- 变量是引用类型:final修饰指的是引用类型的地址值不能发生改变,但是地址里面的内容是可以发生改变的
-
static(静态)
static关键字是静态的意思,可以修饰成员方法,成员变量
static修饰的特点:
- 被类所有对象共享(这也是我们判断是否使用静态关键字的条件)
- 可以通过类名调用,当然也可以通过对象名调用,推荐使用类名调用
非静态的成员方法
- 能访问静态的成员变量
- 能访问非静态的成员变量
- 能访问静态的成员方法
- 能访问非静态的成员方法
静态的成员方法:
- 能访问静态的成员变量
- 能访问静态的成员方法
静态成员方法只能访问静态成员
实例字段在每个实例中都有自己的一个独立“空间”,但是静态字段只有一个共享“空间”,所有实例都会共享该字段。对于静态字段,无论修改哪个实例的静态字段,效果都是一样的:所有实例的静态字段都被修改了,原因是静态字段并不属于实例

虽然实例可以访问静态字段,但是它们指向的其实都是Person class的静态字段。所以,所有实例共享一个静态字段。
因此,不推荐用实例变量.静态字段去访问静态字段,因为在Java程序中,实例对象并没有静态字段。在代码中,实例对象能访问静态字段只是因为编译器可以根据实例类型自动转换为类名.静态字段来访问静态对象。
推荐用类名来访问静态字段。可以把静态字段理解为描述class本身的字段(非实例字段)
调用实例方法必须通过一个实例变量,而调用静态方法则不需要实例变量,通过类名就可以调用。静态方法类似其它编程语言的函数。因为静态方法属于class而不属于实例,因此,静态方法内部,无法访问this变量,也无法访问实例字段,它只能访问静态字段。
多态
多态:同一个对象在不同时候表现出来的不同形态。是指,针对某个类型的方法调用,其真正执行的方法取决于运行时期实际类型的方法
多态的前提和体现:
- 有继承/实现关系
- 有方法重写
- 有父类引用指向子类对象
多态中成员访问特点:
- **成员变量:**编译看左边,执行看左边
- **成员方法:**编译看左边,执行看右边
这是由于成员方法有重写,而成员变量没有
多态的好处和弊端:
- 提高了程序的扩展性。具体体现:定义方法的时候,使用父类型作为参数,将来在使用的时候,使用具体的子类型参与操作。多态具有一个非常强大的功能,就是允许添加更多类型的子类实现功能扩展,却不需要修改基于父类的代码
- 不能使用子类特有的功能
多态中的转型:
- 向上转型:从子到父 父类引用指向子类对象
- 向下转型:从父到子 父类引用转为子类对象
抽象类
在Java中,一个没有方法体的方法应该定义为抽象方法,而类中如果有抽象方法,该类必须定义为抽象类
面向抽象编程的本质就是:
-
上层代码只定义规范(例如:
abstract class Person); -
不需要子类就可以实现业务逻辑(正常编译);
-
具体的业务逻辑由不同的子类实现,调用者并不关心。
抽象类的特点:
- 抽象类和抽象方法必须使用abstract关键字修饰
- 抽象类中不一定有抽象方法,有抽象方法的类一定是抽象类
- 抽象类不能实例化,要参照多态的方式,通过子类对象实例化,这叫抽象类多态
- 抽象类的子类要么重写抽象类中的所有抽象方法,要么是抽象类
抽象类的成员特点:
-
成员变量:可以是变量,也可以是常量
-
构造方法:有构造方法,但是不能实例化,其作用是用于子类访问父类数据的初始化
-
成员方法:可以有抽象方法:限定子类必须完成某些动作
也可以有非抽象方法:提高代码复用性
接口
接口就是一种公共的规范标准,只要符合标准,大家都可以通用。Java中的接口更多的体现在对行为的抽象
接口的特点:
- 接口用关键字interface修饰:
public interface 接口名{} - 类实现接口用implements表示:
public class 类名 implements 接口名{} - 接口不能实例化,必须通过实现类对象实例化,称为接口多态
- 多态的形式:具体类多态,抽象类多态,接口多态
- 有继承或者实现关系;有方法重写;有父(类/接口)引用指向(子/实现)类对象
- 接口实现的类:要么重写接口中的所有抽象方法,要么是抽象类
接口的成员特点:
-
成员变量:只能是常量,默认修饰符为:public static final
-
构造方法:接口没有构造方法,因为接口主要是对行为进行抽象的,是没有具体存在的。
一个类如果没有父类,默认继承自Object类
-
成员方法:只能是抽象方法,默认修饰符:public abstract
类和接口的关系:
- 类和类的关系:继承关系,只能单继承,但是可以多层继承
- 类和接口的关系:实现关系,可以单实现,也可以多实现,还可以继承一个类的同时实现多个接口
- 接口和接口的关系:继承关系,可以单继承,也可以多继承
抽象类和接口的区别:
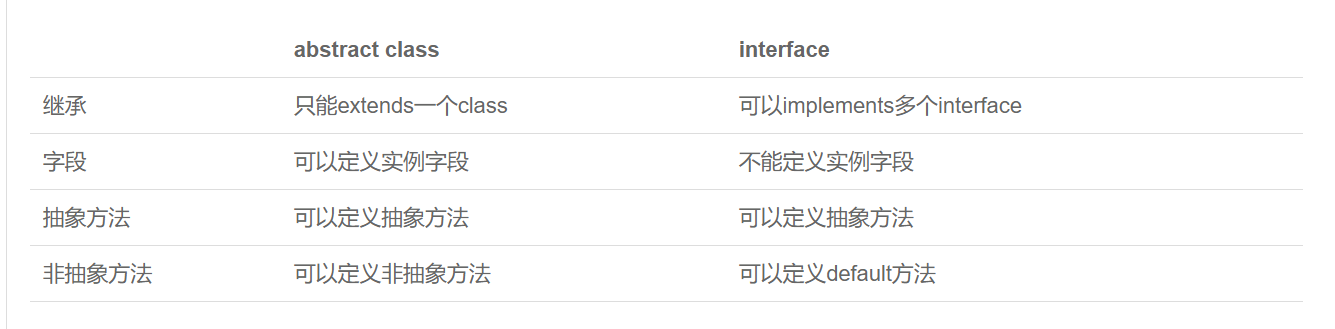
抽象类是对事物的抽象,接口是对行为的抽象
- 成员区别
- 抽象类:变量,常量;有构造方法;有抽象方法,也有非抽象方法
- 接口:常量;抽象方法
- 关系区别
- 类与类:继承,单继承
- 类与接口:实现,可以单实现,也可以多实现
- 接口与接口:继承,单继承,多继承
- 设计理念区别
- 抽象类:对类抽象,包括属性、行为
- 接口:对行为抽象,主要是行为
抽象类名作为实参和返回值:
- 方法的形参是抽象类名,其实需要的是该抽象类的子类对象
- 方法的返回值是抽象类名,其实返回的是该抽象类的子类对象
接口名作为实参和返回值:
- 方法的形参是接口名,其实需要的是该接口的实现类对象
- 方法的返回值是接口名,其实返回的是该接口的实现类对象
实现类可以不必覆写default方法。default方法的目的是,当我们需要给接口新增一个方法时,会涉及到修改全部子类。如果新增的是default方法,那么子类就不必全部修改,只需要在需要覆写的地方去覆写新增方法。
default方法和抽象类的普通方法是有所不同的。因为interface没有字段,default方法无法访问字段,而抽象类的普通方法可以访问实例字段。
项目实战–运动员和教练

- 抽象接口–说英语
/*
说英语的接口
*/
public interface SpeakEnglish {
public abstract void speak();
}
- 抽象类–人类
//抽象人类
public abstract class Person {
private String name;
private int age;
public Person() {
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public abstract void eat();
}
- 抽象类–运动员类
//抽象运动员类
public abstract class Player extends Person{
public Player() {
}
public Player(String name, int age) {
super(name, age);
}
public abstract void study();
}
- 抽象类–教练类
//抽象教练类
public abstract class Coach extends Person{
public Coach() {
}
public Coach(String name, int age) {
super(name, age);
}
public abstract void teach();
}
- 具体类–乒乓球运动员类
//具体的乒乓球运动员类
public class PingPangPlayer extends Player implements SpeakEnglish {
public PingPangPlayer() {
}
public PingPangPlayer(String name, int age) {
super(name, age);
}
@Override
public void study() {
System.out.println("乒乓球运动员学习如何发球和旋球");
}
@Override
public void eat() {
System.out.println("乒乓球运动员吃大白菜喝小米粥");
}
@Override
public void speak() {
System.out.println("乒乓球运动员说英语");
}
}
- 具体类–篮球运动员类
//具体的篮球运动员类
public class BasketballPlayer extends Player{
public BasketballPlayer() {
}
public BasketballPlayer(String name, int age) {
super(name, age);
}
@Override
public void study() {
System.out.println("篮球运动员学习如何运球和投篮");
}
@Override
public void eat() {
System.out.println("篮球运动员吃牛肉喝牛奶");
}
}
- 具体类–乒乓球教练类
//具体乒乓球教练类
public class PingPangCoach extends Coach implements SpeakEnglish{
public PingPangCoach() {
}
public PingPangCoach(String name, int age) {
super(name, age);
}
@Override
public void teach() {
System.out.println("乒乓球教练教如何发球和旋球");
}
@Override
public void eat() {
System.out.println("乒乓球教练吃小白菜喝大米粥");
}
@Override
public void speak() {
System.out.println("乒乓球教练说英语");
}
}
- 具体类–篮球教练类
//具体篮球教练类
public class BasketballCoach extends Coach{
public BasketballCoach() {
}
public BasketballCoach(String name, int age) {
super(name, age);
}
@Override
public void teach() {
System.out.println("篮球教练教如何运球和投篮");
}
@Override
public void eat() {
System.out.println("篮球教练吃羊肉喝羊汤");
}
}
- 具体类–测试类
//测试类
public class PersonDemo {
public static void main(String[] args) {
//创建运动员和教练对象
PingPangPlayer ppp1 = new PingPangPlayer();//无参
ppp1.setName("小白");
ppp1.setAge(20);
System.out.println(ppp1.getName()+","+ppp1.getAge());
ppp1.speak();
ppp1.eat();
ppp1.study();
System.out.println("--------");
PingPangPlayer ppp2 = new PingPangPlayer("大黑",25);//带参
System.out.println(ppp2.getName()+","+ppp2.getAge());
ppp2.speak();
ppp2.eat();
ppp2.study();
System.out.println("--------");
BasketballPlayer bp1 = new BasketballPlayer();//无参
bp1.setName("小黑");
bp1.setAge(30);
System.out.println(bp1.getName()+","+bp1.getAge());
bp1.eat();
bp1.study();
System.out.println("--------");
BasketballPlayer bp2 = new BasketballPlayer("大白",35);//带参
System.out.println(bp2.getName()+","+bp2.getAge());
bp2.eat();
bp2.study();
System.out.println("--------");
BasketballCoach bc = new BasketballCoach();
bc.setName("小明");
bc.setAge(50);
System.out.println(bc.getName()+","+bc.getAge());
bc.teach();
bc.eat();
System.out.println("--------");
PingPangCoach ppc = new PingPangCoach();
ppc.setName("小红");
ppc.setAge(55);
System.out.println(ppc.getName()+","+ppc.getAge());
ppc.speak();
ppc.teach();
ppc.eat();
System.out.println("--------");
System.out.println("测试完毕");
}
}
内部类
内部类就是在一个类中定义一个类
内部类的访问特点:
- 内部类可以直接访问外部类的成员,包括私有
- 外部类要访问内部类的成员,必须创建对象
内部类根据在类中定位的位置不同,可以分为:
- **成员内部类:**在类的成员位置,外界创建对象使用的方法:
外部类名.内部类名 对象名 = 外部类对象.内部类对象 - **局部内部类:**在方法中定义的类,所以外界无法直接使用,需要在方法内创建对象并使用。该类可以直接访问外部类的成员,也可以访问方法内的局部变量
匿名内部类(一种特殊的局部内部类):
- 前提:存在一个类或者接口,这里的类可以是具体类也可以是抽象类
- 本质:是一个继承了该类或者实现了该接口的子类匿名对象
- 匿名内部类在开发中的使用:省去重新定义类的繁琐
用static修饰的内部类和Inner Class有很大的不同,它不再依附于Outer的实例,而是一个完全独立的类,因此无法引用Outer.this,但它可以访问Outer的private静态字段和静态方法。如果把StaticNested移到Outer之外,就失去了访问private的权限。
//运行结果:Hello, OUTER
public class Main{
public static void main(String[] args){
outer.StaticNested sn = new Outer.StaticNested();
sn.hello();
}
}
class Outer{
private static String NAME = "OUTER";
private String name;
Outer(String name){
this.name = name;
}
static class StaticNested{
void hello(){
System.out.println("Hello," + Outer.NAME);
}
}
}
常用API
没有构造方法,要看类的成员是否都是静态的,如果是,通过类名就可以直接调用
- Math类
包含执行基本数字运算的方法
public static int abs(int a) //返回参数的绝对值
public static double ceil(double a) //返回大于或等于参数的最小double值。等于一个整数
public static double floor(double a) //返回小于或等于参数的最小double值。等于一个整数
public static int round(float a) //按照四舍五入返回最接近参数的int
public static int max(int a,int b) //返回两个int值中的较大值
public static int min(int a,int b) //返回两个int值中的较小值
public static double pow(double a,double b) //返回a的b次幂的值
public static double random() //返回值为double的正值,[0.0,1.0)
- System类
包含两个有用的类字段和方法,不能被实例化
public static void exit(int status) //终止当前运行的Java虚拟机,非零表示异常终止
public static long currentTimeMillis() //返回当前时间(以毫秒为单位),可以作为一个计时器用
- Object类
Object是类层次的根,每个类都可以将Object作为超类。所有类都直接或者间接的继承该类构造方法:public Object()
为什么说子类的构造方法默认访问的是父类的无参构造方法? 因为它们的顶级父类只有无参构造方法
public StringtoString() //返回对象的字符串表示形式。建议所有子类重写该方法,自动生成
public boolean equals(Object obj) //比较对象是否相等。默认比较地址,重写可以比较内容,自动生成
- Array类
包含关于操作数组的各种方法
public static StringtoString(int[] a) //返回数组的字符串表示形式
public static void sort(int[] a) //按照数字顺序排列指定的数组
工具类的设计思想:
构造方法用private修饰:防止外界创建对象;成员用public static修饰,让外界用类名访问
- 基本类型包装类
将基本数据类型封装成对象的好处在于可以在对象中定义更多的功能方法操作该数据
常见的操作之一:用于基本数据类型与字符串之间的转换
int转换为String
public static String valueOf(int i) //返回int参数的字符串表示形式,该方法是String类中的方法
String转换为int:
public static parseInt(String s) //将字符串解析为int类型,该方法是Integer类中的方法
//基本数据类型有:
byte short int long float double char boolean
//对应的包装类分别为:
Byte Short Integer Long Float Double Character Boolean
自动装箱和拆箱:
装箱:把基本数据类型转换为对应的包装类型
拆箱:把包装类类型转换为对应的基本数据类型
在使用包装类类型的时候,如果做操作,最好先判断是否为null。只要是对象,在使用前就必须进行不为null的判断
- 日期类
date类:代表了一个特定的时间,精确到毫秒
public Date() //分配一个Date对象,并初始化,以便它代表它被分配的时间,精确到毫秒
public Date(long date) //分配一个Date对象,并将其初始化为表示从标准基准时间起指定的毫秒数
public long getTime() //获取的是日期对象从1970年1月1日00:00:00到现在的毫秒值
public void setTime(long time) //设置时间,给的是毫秒值
**SimpleDataFormat类:**是一个具体的类,用于以区域设置敏感的方式格式化和解析日期。日期和时间格式由日期和时间模式字符串指定,在日期和时间模式字符串中,从’A’到’Z’以及从’a’到’z’引号的字母被解释为表示日期或时间字符串的组件的模式字母
常用的模式字母及对应关系如下:
y----年
M----月
d----日
H----时
m----分
s----秒
public SimpleDateFormat() //构造一个SimpleDateFormat,使用默认模式和日期格式
public SimpleDateFormat(String pattern) //构造一个SimpleDateFormat使用给定的模式和默认的日期格式
public final String format(Date date) //格式化(从Date到String):将日期格式化成日期/时间字符串
public Date parse(String source) //解析(从String到Date):从给定的字符串的开始解析文本以生成日期
Calendar类:
为某一时刻和一组日历字段之间的转换提供了一些方法,并为操作日历字段提供了一些方法
Calendar提供了一个类方法**getinstance()**用于获取Calendar对象,其日历字段已使用当前日期和时间初始化
public int get(int field) //返回给定日历字段的值
public abstract void add(int field,int amount) //根据日历的规则,将指定的时间量添加或减去给定的日历字段
public final void set(int year,int month,int date) //设置当前的年月日
异常
异常:就是程序出现了不正常的情况

Error:严重问题,不需要处理
Exception:称为异常类,它表示程序本身可以处理的问题
- RuntimeException:在编译期是不检查的,出现问题后,需要我们回来修改代码
- 非RuntimeException:编译期就必须处理的,否则程序不能通过编译,就更不能正常运行了
JVM的默认处理方案:
如果程序出现了问题,我们没有做任何处理,最终JVM会做默认的处理:
- 把异常的名称,异常原因以及异常出现的位置等信息输出在了控制台
- 程序停止执行
Throwable的成员方法:
public String getMessage() //返回次throwable的详细消息字符串
public String toString() //返回次可抛出的简短描述
public void printStackTrace() //把异常的错误信息输出在控制台
编译时异常和运行时异常的区别:
Java中的异常被分为两大类:编译时异常和运行时异常,也被称为受检异常和非受检异常。所有的RuntimeException类及其子类被称为运行时异常,其他的异常都是编译时异常
- 编译时异常:必须显示处理,否则程序就会发生错误,无法通过编译
- 运行时异常:无需显示处理,也可以和编译时异常一样处理
异常处理:
- try…catch…
格式:
try {
//可能出现异常的代码;
} catch(异常类名 变量名){
//异常的处理代码;
}
-
执行流程:
- 程序从try里面的代码开始执行
- 出现异常,会自动生成一个异常类对象,该异常对象将被提交给Java运行时系统
- 当Java运行时系统接收到异常对象时,会到catch中去找匹配的异常类,找到后进行异常的处理
- 执行完毕之后,程序还可以继续往下执行
-
throws(仅仅只是抛出异常,并没有处理异常)
并不是所有的情况我们都有权限进行异常的处理,当出现的异常是我们处理不了的时候,Java提供了throws的处理方法
格式:throws 异常类名;(这个格式是在方法的括号后面的)
编译时异常必须要进行处理,两种处理方案:try…catch…或者throws,如果采用throws这种方案,将来谁调用谁处理
运行时异常可以不处理,出现问题后,需要我们回来修改代码
throws和throw的区别:
throws:用在方法生命后面,跟的是异常类名;
表示抛出异常,由该方法的调用者来处理;
表示出现异常的一种可能性,并不一定会发生这些异常。
throw: 用在方法体内,跟的是异常对象名;
表示抛出异常,由方法体内的语句处理;
执行throw一定抛出了某种异常。
集合进阶

Collection
Collection集合概述:
- 是单列集合的顶层接口,它表示一组对象,这些对象也称为Collection的元素
- JDK不提供此接口的任何直接实现,它提供更具体的子接口(如Set和List)实现
Collection集合常用方法:
boolean add(E e) //添加元素
boolean remove(Object o) //从集合中移除指定的元素
void clear() //清空集合中的元素
boolean contains(Objecct o) //判断集合总是否存在指定的元素
boolean isEmpty() //判断结合是否为空
int size() //集合的长度,也就是集合中元素的个数
Collection集合的遍历:
Iterator:迭代器,集合的专用遍历方式
- Iterator iterator():返回此集合中元素的迭代器,通过集合的iterator()方法得到
- 迭代器是通过集合的iterator()方法得到的,所以说它是依赖于集合而存在的
Iterator中的常用方法:
- E next():返回迭代的下一个元素
- boolean hasNext():如果迭代具有更多元素,则返回true
集合的使用步骤:
public static void main(String[] args){
Collection<String> c = new ArrayList<String>(); //步骤1:创建集合对象
//步骤2:添加元素
String s = "hello world"; //步骤2.1:创建元素
c.add(s); //步骤2.2:添加元素到集合
c.add("hello world"); //合并:添加元素到集合
//步骤3:遍历集合
Iterator<String> it = c.iterator(); //步骤3.1:通过集合对象获取迭代器对象
while(it.hasNext()){ //步骤3.2:通过迭代器对象的hasNext()方法判断是否还有元素
String s = it.next(); //步骤3.3:通过迭代器对象的next()方法获取下一个元素
System.out.println(s);
}
}
List
List集合概述:
- 有序集合(也称为序列),用户可以精确控制列表中每个元素的插入位置。用户可以通过整数索引访问元素,并搜索列表中的元素。
- 与Set集合不同,列表通常允许重复的元素。
List集合特点:
- 有序:存储和取出的元素顺序一致
- 可重复:存储的元素可以重复
List集合常用方法:
void add(int index, E element) //在此集合中的指定位置插入指定的元素
E remove(int index) //删除指定索引处的元素,返回被删除的元素
E set(int index,E element) //修改指定索引处的元素,返回被修改的元素
E get(int index) //返回被指定索引处的元素
并发修改异常:
- ConcurrentModificationExpection
- 产生原因:迭代器在遍历的过程中,通过集合对象修改了集合中元素的长度,造成了迭代器获取元素中判断预期修改值和实际修改值不一致
- 解决方案:用for循环遍历,然后用集合对象做对应的操作即可
List列表迭代器:
-
通过List集合的listIterator()方法得到,所以说它是List集合特有的迭代器
-
用于允许程序员沿任一方向遍历列表的列表迭代器,在迭代期间修改列表,并获取列表中迭代器的当前位置
-
常用方法:
E next() //返回迭代中的下一个元素 boolean hasNext() //如果迭代具有更多元素,则返回true E previous() //返回列表中的上一个元素 boolean hasPrevious() //如果此列表迭代器在相反方向遍历列表时具有更多元素,则返回true void add(E e) //将指定的元素插入列表
增强for循环:
增强for:简化数组和Collection集合的遍历
- 实现
Iterable接口的类允许其对象成为增强型for语句的目标 - 它是JDK5之后出现的,其内部原理是一个Iterator迭代器
增强for的格式:
for(元素数据类型 变量名:数组或者Collection集合){
//在此处使用变量即可,该变量就是元素
}
//范例:
int[] arr = {1,2,3,4,5};
for(int i:arr){
System.out.println(i);
}
List集合子类特点:
List集合常用子类:ArrayList,LinkedList
-
ArrayList:底层数据结构是数组,查询快,增删慢
-
LinkedList:底层数据结构是链表,查询慢,增删快
LinkedList集合的特有方法:
public void addFirst(E e) //在该列表开头插入指定的元素
public void addLast(E e) //将指定的元素追加到此列表的末尾
public E getFirst() //返回此列表中的第一个元素
public E getLast() //返回此列表中的最后一个元素
public E removeFirst() //从此列表中删除并返回第一个元素
public E removeLast() //从列表中删除并返回最后一个元素
数据结构
数据结构是计算机存储、组织数据的方式,是指相互之间存在一种或多种特定关系的数据元素的集合
通常情况下,精心选择的数据结构可以带来更高的运行或者存储效率





Set
Set集合概述和特点:
- 不包含重复元素的集合
- 没有带索引的方法,所以不能使用普通for循环遍历
哈希值:
哈希值是JDK根据对象的地址或者字符串或者数字算出来的int类型的数值
Object类中有一个方法可以获取对象的哈希值:
public int hashCode() //返回对象的哈希码值
对象的哈希值特点:
- 同一个对象多次调用hashCode()方法返回的哈希值是相同的
- 默认情况下,不同对象的哈希值是不同的。而重写hashCode()方法,可以实现让不同对象的哈希值相同
HashSet集合概述和特点:
- 底层数据结构是哈希表
- 对集合的迭代顺序不作任何保证,也就是说不保证存储和取出的元素顺序一致
- 没有带索引的方法,所以不能使用普通for循环遍历
- 由于是Set集合,所以是不包含重复元素的集合
HashSet集合保证元素唯一性:

LinkedHashSet集合概述和特点:
- 哈希表和链表实现的Set接口,具有可预测的迭代次序
- 由链表保证元素有序,也就是说元素的存储和取出顺序是一致的
- 由哈希表保证元素唯一,也就是说没有重复的元素
TreeSet集合概述和特点:
- 元素有序,这里的顺序不是指存储和取出的顺序,而是按照一定的规则进行排序,具体排序方式取决于构造方法
- TreeSet():根据其元素的自然排序进行排序
- TreeSet(Comparator comparator):根据指定的比较器进行排序
- 没有带索引的方法,所以不能使用普通for循环遍历
- 由于是Set集合,所以不包含重复元素的集合
自然排序Comparable的使用:
- 用TreeSet集合存储自定义对象,无参构造方法使用的是自然排序对元素进行排序的
- 自然排序,就是让元素所属的类实现Comparable接口,重写compareTo(To)方法
- 重写方法时,一定要注意排序规则必须按照要求的主要条件和次要条件来写
比较器排序Comparator的使用:
- 用TreeSet集合存储自定义对象,带参构造方法使用的是比较器排序对元素进行排序的
- 比较器排序,就是让集合构造方法接收Comparator的实现类对象,重写compareTo(To1,To2)方法
- 重写方法时,一定要注意排序规则必须按照要求的主要条件和次要条件来写
泛型
泛型概述:
泛型:是JDK5中引入的特性,它提供了编译时类型安全监测机制,该机制允许在编译时检测到非法的类型。它的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。一提到参数,最熟悉的就是定义方法时有形参,然后调用此方法时传递实参。那么参数化类型怎么理解呢?顾名思义,就是将类型由原来的具体的类型参数化,然后在使用/调用时传入具体的类型。这种参数类型可以用在类、方法和接口中,分别被称为泛型类、泛型方法、泛型接口
泛型定义格式:
- <类型>:指定一种类型的格式。这里的类型可以看成是形参
- <类型1,类型2…>:指定多种类型的格式,多种类型之间用逗号隔开。这里的类型可以看成是形参
- 将来具体调用时候给定的类型可以看成是实参,并且实参的类型只能是引用数据类型
泛型的好处:
- 把运行时期的问题提前到了编译期间
- 避免了强制类型转换
泛型类:
- 格式:修饰符 class 类名 <类型> {}
- 范例:
public class Generic <T> {}- 此处T可以随便写为任意标识,常见的如T、E、K、V等形式的参数常用于表示泛型
泛型方法:
- 格式:修饰符 <类型> 返回值类型 方法名(类型 变量名){ }
- 范例:
public <T> void show(T t){ }
泛型接口:
- 格式:修饰符 interface 接口名 <类型> { }
- 范例:
public interface Generic <T> { }
类型通配符:
为了表示各种泛型List的父类,可以使用类型通配符
- 类型通配符:<?>
- List<?>:表示元素类型未知的List,它的元素可以匹配任何的类型
- 这种带通配符的List仅表示它是各种泛型List的父类,并不能把元素添加到其中
如果说我们不希望List<?>是任何泛型的父类,只希望它代表某一类泛型List的父类,可以使用类型通配符的上限
- 类型通配符上限:<?extends 类型>
- List<? extends Number>:它表示的类型是Number或者其子类型
除了可以指定类型通配符的上限,我们也可以指定类型通配符的下限
- 类型通配符的下限:<? super 类型>
- List<? super Number>:它表示的类型是Numbe或者父类型
可变参数:
可变参数又称参数个数可变,用作方法的形参出现,那么方法参数个数就是可变的了
- 格式:修饰符 返回值类型 方法名(数据类型… 变量名){ }
- 范例:
public static int sum(int... a){ }
可变参数注意事项:
- 这里的变量其实是一个数组
- 如果一个方法有多个参数,包含可变参数,可变参数要放在最后
可变参数的使用:
//Arrays工具类中有一个静态方法
public static <T> List<T> aList(T... a) //返回由指定数组支持的固定大小的列表,返回的集合不能做增删操作,可以做修改操作
//List接口中有一个静态方法
public static <E> List<E> of(E... elements) //返回包含任意数量元素的不可变列表,返回的集合不能做增删操作
//Set接口中有一个静态方法
public static <E> Set<E> of(E... elements) //返回一个包含任意数量元素的不可变集合,在给元素的时候,不能给重复的元素,返 回的集合不能做增删操作,没有修改的方法
Map
Map集合概述:
Interface Map<K,V>K:键的类型;V:值的类型- 将键映射到值的对象;不能包含重复的键;每个键可以映射到最多一个值
Map集合的基本功能:
V put(K key,V value) //添加元素
V remove(Object key) //根据键删除键值对元素
void clear() //移除所有的键值对元素
boolean containsKey(Object key) //判断集合是否包含指定的键
boolean containsValue(Object value) //判断结合是否包含指定的值
boolean isEmpty() //判断集合是否为空
int size() //集合的长度,也就是集合中键值对的个数
Map集合的获取功能:
V get(Object key) //根据键获取值
Set<K> keySet() //获取所有键的集合
Collection<V> values() //获取所有值的集合
Set<Map.Entry<K,V>> entrySet() //获取所有键值对对象的集合
Collections
Collections的概述:
是针对集合操作的工具类
Collections类的常用方法:
public static <T extends Comparable<? super T>> void sort(List<T> list) //将指定的列表按升序排列
public static void reverse(List<?> list) //反转指定列表中元素的顺序
public static void shuffle(List<?> list) //使用默认的随机源随机排列指定的列表
项目实战–模拟斗地主
/*
需求:
通过程序实现斗地主过程中的洗牌,发牌和看牌。要求:对牌进行排序
思路:
1.创建HashMap,键是编号,值是牌
2.创建ArrayList,存储编号
3.创建花色数组和点数数组
4.从0开始往HashMap里面存储编号,并存储对应的牌。同时往ArrayList里面存编号
5.洗牌(洗的是编号),用Collections的shuffle()方法实现
6.发牌(发的也是编号,为了保证编号是排序的,创建TreeSet集合接收)
7.定义方法看牌(遍历TreeSet集合,获取编号,到HashMap集合找对应的牌)
8.调用看牌方法
*/
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
import java.util.TreeSet;
public class PokerDemo {
public static void main(String[] args) {
//创建HashMap,键是编号,值是牌
HashMap<Integer, String> hm = new HashMap<Integer, String>();
//创建ArrayList,存储编号
ArrayList<Integer> array = new ArrayList<Integer>();
//创建花色数组和点数数组
String[] colors = {"♦", "♣", "♠", "♥"};
String[] numbers = {"3", "4", "5", "6", "7", "8", "9", "10", "J", "Q", "K", "A", "2"};
//从0开始往HashMap里面存储编号,并存储对应的牌。同时往ArrayList里面存编号
int index = 0;
for (String number : numbers) {
for (String color : colors) {
hm.put(index, color + number);
array.add(index);
index++;
}
}
hm.put(index, "小王");
array.add(index);
index++;
hm.put(index, "大王");
array.add(index);
//洗牌(洗的是编号),用Collections的shuffle()方法实现
Collections.shuffle(array);
//发牌(发的也是编号,为了保证编号是排序的,创建TreeSet集合接收)
TreeSet<Integer> hyfSet = new TreeSet<Integer>();
TreeSet<Integer> zxxSet = new TreeSet<Integer>();
TreeSet<Integer> ggsqSet = new TreeSet<Integer>();
TreeSet<Integer> dpSet = new TreeSet<Integer>();
for (int i = 0; i < array.size(); i++) {
int x = array.get(i);
if (i >= array.size() - 3) {
dpSet.add(x);
} else if (i % 3 == 0) {
hyfSet.add(x);
} else if (i % 3 == 1) {
zxxSet.add(x);
} else if (i % 3 == 2) {
ggsqSet.add(x);
}
}
//调用看牌方法
lookPoker("胡一菲", hyfSet, hm);
lookPoker("曾小贤", zxxSet, hm);
lookPoker("关谷神奇", ggsqSet, hm);
lookPoker("底牌", dpSet, hm);
}
//定义方法看牌(遍历TreeSet集合,获取编号,到HashMap集合找对应的牌)
public static void lookPoker(String name, TreeSet<Integer> ts, HashMap<Integer, String> hm) {
System.out.print(name + "的牌是:");
for (Integer key : ts) {
String poker = hm.get(key);
System.out.print(poker + "");
}
System.out.println();
}
}

File
File概述和构造方法
File:它是文件和目录路径名的抽象表示
- 文件和目录是可以通过File封装成对象的
- 对于File而言,其封装的并不是一个真正存在的文件,仅仅是一个路径名而已。它可以是存在的,也可以是不存在的。将来是要通过具体的操作把这个路径的内容转换为具体存在的
File(String pathname) //通过给定的路径名字字符串转换为抽象路径名来创建新的File实例
File(String parent,String child) //从父路径名字符串和子路径名字符串创建新的File实例
File(File parent,String child) //从父抽象路径名和子路径名字符串创建新的File实例
File类创建功能:
public boolean createNewFile() //当具有该名称的文件不存在时,创建一个由该抽象路径命名的新空文件
public boolean mkdir() //创建由此抽象路径名命名的目录
public boolean mkdirs() //创建由此抽象路径名命名的目录,包括任何必需但不存在的父目录
File类判断和获取功能:
public boolean isDirectory() //测试此抽象路径名表示的File是否为目录
public boolean isFile() //测试此抽象路径名表示的File是否为文件
public boolean exists() //抽象路径名表示的File是否存在
public String getAbsolutePath() //返回此抽象路径名的绝对路径名字符串
public String getPath() //将此抽象路径名转换为路径名字符串
public String getName() //返回由此抽象路径名表示的文件或目录的名称
public String[] list() //返回此抽象路径名表示的目录中的文件和目录的名称字符串数组
public File[] listFiles() //返回此抽象路径名表示的目录中的文件和目录的File对象数组
File类删除功能:
public boolean delete() //删除由此抽象路径名表示的文件或目录
绝对路径和相对路径的区别
- 绝对路径:完整的路径名,不需要任何其他信息就可以定位它所表示的文件
- 相对路径:必须使用取自其他路径名的信息进行解释
删除目录时的注意事项:如果一个目录中有内容(目录,文件),不能直接删除。应该先删除目录中的内容,然后才能删除目录。
递归:
递归概述:以编程的角度来看,递归指的是方法定义中调用方法本身的现象
递归解决问题的思路:把一个复杂的问题层层转化为一个与原问题相似的规模较小的问题来求解。递归策略只需少量的程序就可描述处解题过程所需要的多次重复运算
递归解决问题要找到两个内容:
- 递归出口:否则会出现内存溢出
- 递归规则:与原问题相似的规模较小的问题
字节流
IO流概述和分类:
IO流分类:
- 按照数据的流向 输入流:读数据;输出流,写数据
- 按照数据类型来分 字节流和字符流
一般来说我们说IO流的分类是按照数据类型来分的。
如果数据通过windows自带的记事本软件打开我们还可以读懂里面的内容,就使用字符流,否则使用字节流。如果不知道使用哪种类型的流,就使用字节流。
字节流写数据:
字符流抽象基类
InputStream:这个抽象类是表示字节输入流的所有类的超类OutputStream:这个抽象类是表示字节输出流的所有类的超类- 子类名特点:子类名称都是以其父类名作为子类名的后缀
字节流抽象基类
InputStream:这个抽象类是表示字节输入流一的所有类的超类OutputStream:这个抽象类是表示字节输出流的所有类的超类- 子类名特点:子类名称都是以其父类名作为子类名的后缀
FileOutputStream:文件输出流用于将数据写入File
FileOutputStream(String name):创建文件输出流以指定的名称写入文件
使用字节输出流写数据的步骤:
- 创建字节输出流对象(调用系统功能创建了文件,创建字节输出流对象,让字节输出流对象指向文件)
- 调用字节输出流对象的写数据方法
- 释放资源(关闭此文件输出流并释放与此流相关联的任何系统资源)
void write(int b) //将指定的字节写入此文件输出流,一次写一个字节数据
void write(byte[] b) //将b.length字节从指定的字节数组写入此文件输出流,一次写一个字节数组数据
void write(byte[] b,int off,int len) //将len字节从指定的字节数组开始,从偏移量off开始写入此文件输出流一次写一个字节数组 的部分数据
字节流写数据的两个小问题:
字节流写数据实现换行的方法:写完数据后,加换行符 windows:\r\n,Linux:\n,mac:\r
字节流写数据如何实现追加写入呢
public FileOutputStream(String name,boolean append)- 创建文件输出流以指定的名称写入文件。如果第二个参数为true,则字节将写入文件的末尾而不是开头
字节流读数据:
/*
需求:把文件fos.txt中的内容读取出来在控制台输出
FileInputStream(String name):通过打开与实际文件的连接来创建一个FileInputStream,该文件由文件系统中的路径名name命名
使用字节输入流读数据的步骤:
(1)创建字节输入流对象
(2)调用字节输入流对象的读数据方法
(3)释放资源
*/
byte[] bys = new byte[1024]; //1024及其整数倍
int len;
while((len=fis.read(bys))!=-1){
System.out.println(new String(bys,0,len));
}
字节缓冲流:
- BufferOutputStream:该类实现缓冲输出流。通过设置这样的输出流,应用程序可以向底层输出流写入字节,而不必为写入的每个字节导致底层系统的调用
- BufferedInputStream:创建
BufferedInputStream将创建一个内部缓冲区数组。当从流中读取或跳过字节时,内部缓冲区将根据需要从所包含的输入流中重新填充,一次很多字节
构造方法:
- 字节缓冲输出流:
BufferedOutputStream(OutputStream out) - 字节缓冲输入流:
BufferedInputStream(InputStream in)
为什么构造方法需要的是字节流,而不是具体的文件或者路径呢?
- 字节缓冲流仅仅提供缓冲区,而真正的读写数据还得依靠基本的字节流对象进行操作
字符流
**为什么会出现字符流:**由于字节流操作中文不是特别的方便,所以Java就提供字符流
- 字符流 = 字节流 + 编码表
用字节流复制文本文件时,文本文件也会有中文,但是没有问题,原因是最终底层操作会自动进行字节拼接成中文,识别是中文的方法:汉字在存储的时候,无论选择哪种编码存储,第一个字节都是负数
编码表:
基础知识:计算机中存储的信息都是用二进制数表示的;我们在屏幕上看到的英文、汉字等字符都是二进制数转换之后的结果。按照某种规则,将字符存储到计算机中,称为编码。反之,将存储在计算机中的二进制数按照某种规则解析显示出来,称为解码。
字符集:
- 是一个系统支持的所有字符的集合,包括国家文字、标点符号、图形符号、数组等
- 计算机要准确的存储和识别各种字符集符号,就需要进行字符编码,一套字符集
ASCIl字符集:
- ASCII(American Standard Code for Information Interchange,美国信息交换标准代码):是基于拉丁字母的一套电脑编码系统,用于显示现代英语,主要包括控制字符(回车键、退格、换行键等)和可显示字符(英文大小写字符、阿拉伯数字和西文符号)
- 基本的ASCII字符集,使用7位表示一个字符,共128字符。ASCII的扩展字符集使用8位表示一个字符,共256字符,方便支持欧洲常用字符。是一个系统支持的所有字符的集合,包括各国家文字、标点符号、图形符号、数字等
GBXXX字符集:
- GB2312:简体中文码表。一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,这样大约可以组合了包含7000多个简体汉字,此外数学符号、罗马希腊的字母、日文的假名等都编进去了,连在ASCII里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的"全角"字符,而原来在127号以下的那些就叫"半角"字符了
- GBK:最常用的中文码表。是在GB2312标准基础上的扩展规范,使用了双字节编码方案,共收录了21003个汉字,完全兼容GB2312标准,同时支持繁体汉字以及日韩汉字等
- GB18030:最新的中文码表。收录汉字70244个,采用多字节编码,每个字可以由1个、2个或4个字节组成。支持中国国内少数民族的文字,同时支持繁体汉字以及日韩汉字等
Unicode字符集:
-
为表达任意语言的任意字符而设计,是业界的一种标准,也称为统一码、标准万国码。它最多使用4个字节的数字来表达每个字母、符号,或者文字。有三种编码方案,UTF-8、UTF-16和UTF32。最为常用的UTF-8编码
-
UTF-8编码:可以用来表示Unicode标准中任意字符,它是电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码。互联网工程工作小组(IETF)要求所有互联网协议都必须支持UTF-8编码。它使用一至四个字节为每个字符编码
编码规则:
128个US-ASCIl字符,只需一个字节编码拉丁文等字符,需要二个字节编码
大部分常用字(含中文),使用三个字节编码
其他极少使用的Unicode辅助字符,使用四字节编码
字符串中的编码解码问题:
//编码:
byte[] getBytes() //使用平台的默认字符集将该String
byte[] getBytes(String charsetName) //使用指定的字符集将该String编码为一系列字节,将结果存储到新的字节数组中
//解码:
String(byte[] bytes) //通过使用平台的默认字符集解码指定的字节数组来构造新的String
String(byte[] bytes,String charsetName) //通过指定的字符集解码指定的字节数组来构造新的String
字符流中的编码解码问题:
字符流抽象基类:
Reader:字符输入流的抽象类Writer:字符输出流的抽象类
字符流中和编码解码问题相关的两个类:
InputStreamReaderOutputStreamWriter
字符流写数据的5种方式:
void write(int c) //写一个字符
void write(char[] cbuf) //写入一个字符数组
void write(cahr[] cbuf,int off,int len) //写入字符数组的一部分
void write(String str) //写一个字符串
void write(String str,int off,int len) //写一个字符串的一部分
flush():刷新流,还可以继续写数据
close():关闭流,释放资源,但是在关闭之前会先刷新流。一旦关闭,就不能再写数据
字符流读数据的两种方式:
int read() //一次读一个字符数据
int read(char[] cbuf) //一次读一个字符数组数据
字符流读数据和字节流读数据的格式是一样的,只不过一个是字符一个是字节而已
字符缓冲流:
- BufferedWriter:将文本写入字符输出流,缓冲字符,以提供单个字符,数组和字符串的高效写入,可以指定缓冲区大小,或者可以接受默认大小。默认值足够大,可用于大多数用途
- BufferedReader:从字符输入流读取文本,缓冲字符,以提供字符,数组和行的高效读取,可以指定缓冲区大小,或者可以使用默认大小。默认值足够大,可用于大多数用途
构造方法:
BufferedWriter(Writer out)BufferedReader(Reader in)
字符冲流特有功能:
//BufferedWriter:
void newLine() //写一行行分隔符,行分隔符字符串由系统属性定义
//BufferedReader:
public String readLine() //读一行文字。结果包含行的内容的字符串,不包括任何行终止字符,如果的结尾已经到达,则为null
复制文件的异常处理:

特殊操作流
标准输入输出流:
System类中有两个静态的成员变量:
public static final InputStream in //标准输入流,通常该流对应于键盘输入或由主机环境或用户指定的另一个输入源
public static final PrintStream out //标准输出流,通常该流对应于显示输出或由主机环境或用户指定的另一个输出目标
自己实现键盘录入数据:
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
//写起来太麻烦,Java就提供了一个类实现键盘录入
Scanner sc = new Scanner(System.in);
输出语句的本质是一个标准的字节输出流
打印流:
打印流分类:
- 字节打印流:PrintStream
- 字符打印流:PrintWriter
打印流的特点:
- 只负责输出数据,不负责读取数据
- 有自己的特有方法
字节打印流:
PrintStream(String fileName):使用指定的文件名创建新的打印流- 使用继承父类的方法写数据,查看的时候会转码;使用字节的特有方法写数据,查看的数据原样输出
字符打印流PrintWriter的构造方法:
PrintWriter(String fileName) //使用指定的文件名创建一个新的PrintWriter,而不需要自动执行刷新
PrintWriter(Writer out,boolean autoFlush) //创建一个新的PrintWriter out:字符输出流;autoFlush:一个布尔值,如果为 真,则println,printf,或format方法将刷新输出缓冲区
对象序列化流:
对象序列化:就是将对象保存到磁盘中,或者在网络中传输对象
这种机制就是使用一个字节列表示一个对象,该字节序列包含:对象的类型、对象的数据和对象中存储的属性等信息。字节序列写到文件之后,相当于文件中持久保存了一个对象的信息
反之,该字节序列还可以从文件中读取回去,重构对象,对它进行反序列化
对象序列化流:ObjectOutputStream
- 将Java对象的原始数据类型和图形写入OutputStream。可以使用ObjectInputStream读取(重构对象)。可以通过使用流的文件来实现对象的持久存储。如果流是网络套接字流,则可以在另一个主机上或另一个进程中重构对象
构造方法:
ObjectOutputStream(OutputStream out):创建一个写入指定的OutputStream的ObjectOutputStream
序列化对象的方法:
void writeObject(Object obj):将指定的对象写入ObjectOutputStream
注意:一个对象要想被序列化,该对象所属的类必须实现Serializable接口(Serializable是一个标记接口,实现该接口,不需要重写任何方法)
对象反序列化流:
ObjectInputStream反序列化先前使用ObjectOutputStream编写的原始数据和对象
构造方法:ObjectInputStream(InputStream in):创建从指定的InputStream读取的ObjectInputStream
反序列化对象的方法:Object readObject():从ObjectInputStream读取一个对象
用对象序列化流序列化一个对象后,假如我们修改了对象所属的类文件,读取数据会不会出问题呢?
- 会出问题,抛出InvalidClassException异常
如果出问题了,如何解决呢?
- 给对象所属的类加一个serialVersionUID:
private static final long serialVersionUID = 42L;
如果一个对象中的某个成员变量的值不想被序列化,又该如何实现呢?
- 给该成员变量加transient关键字修饰,该关键字标记的成员变量不参与序列化过程
Properties:
Properties是一个Map体系的集合类,可以保存到流中或从流中加载
Properties作为集合的特有方法:
Object setProperty(String key,String value) //设置集合的键和值,都是String类型,底层调用Hashtable方法put
String getProperty(String key) //使用此属性列表中指定的键搜索属性
Set<String> stringPropertyNames() //从该属性列表中返回一个不可修改的键集,其中键及其对应的值是字符串
Properties和IO流相结合的方法:
void load(InputStream inStream) //从输入字节流读取属性列表(键和元素对)
void load(Reader reader) //从输入字符流读取属性列表(键和元素对)
void store(OutputStream out,String comments) //将此属性列表(键和元素对)写入此Properties表中,以适合于使用 load(InpputStream)方法的格式写入输出字节流
void store(Writer writer,String comments) //将此属性列表(键和元素对)写入此Properties表中,以适合于使用 load(Reader)方法的格式写入输出字节流
多线程
进程和线程:
进程 正在运行的程序,是系统进行资源分配和调用的独立单位,每一个进程都有它自己的内存空间和系统资源
线程是进程中的单个顺序控制流,是一条执行路径。分为单线程:一个进程只有一条执行路径,和多线程:一个进程有多条执行路径
多线程实现方式之继承Thread类:
- 定义一个MyThread继承Thread类
- 在MyThread类中重写run()方法
- 创建MyThread类的对象
- 启动线程
为什么要重写run()方法?因为run()是用来封装被线程执行的代码
run()方法和start()方法的区别?
- run():封装线程执行的代码,直接调用,相当于普通方法的调用
- start():启动线程,然后由JVM调用此线程的run()方法
多线程实现方式之实现Runnable接口:
- 定义一个类MyRunnable实现Runnable接口
- 在MyRunnable类中重写run()方法
- 创建MyRunnable类的对象
- 创建Thread类的对象,把MyRunnable对象作为构造方法的参数
- 启动线程
相比继承Thread类,实现Runnable接口的好处:
- 避免了Java单继承的局限性
- 适合多个相同程序的代码去处理同一个资源的情况,把线程和程序的代码、数据有效分离,较好的体现了面向对象的设计思想
设置和获取线程名称:
Thread类中设置和获取线程名称的方法
void setName(String name):将此线程的名称更改为等于参数nameString getName():返回此线程的名称- 通过构造方法也可以设置线程名称
如何获取main方法所在的线程名称?
public static Thread currentThread() //返回对当前正在执行的线程对象的引用
线程调度:
- 分时调度模型:所有线程轮流使用CPU的使用权,平均分配每个线程占用CPU的时间片
- 抢占式调度模型:优先让优先级高的线程使用CPU,如果线程的优先级相同,那么会随机选择一个,优先级高的线程获取的CPU时间片相对多一些
Java使用的是抢占式调度模型
假如计算机只有一个CPU,那么CPU在某一时刻只能执行一条指令,线程只有得到CPU时间片,也就是使用权,才可以执行指令。所以多线程程序的执行是有随机性,因为谁抢到CPU的使用权是不一定的
Thread类中设置和获取线程优先级的方法:
public final int getPriority() //返回此线程的优先级
public final void setPriority(int newPriority) //更改此线程的优先级
/*
线程默认优先级是5;线程优先级的范围是:1-10
线程优先级高仅仅表示线程获取的CPU时间片的几率高,但是要在次数比较多,或者多次运行的时候才能看到你想要的效果
*/
线程控制:
static void sleep(long millis) //使当前正在执行的线程停留(暂停执行)指定的毫秒数
void join() //等待这个线程死亡
void setDaemon(boolean on) //将此线程标记为守护线程,当运行的线程都是守护线程时,Java虚拟机将退出
线程生命周期:
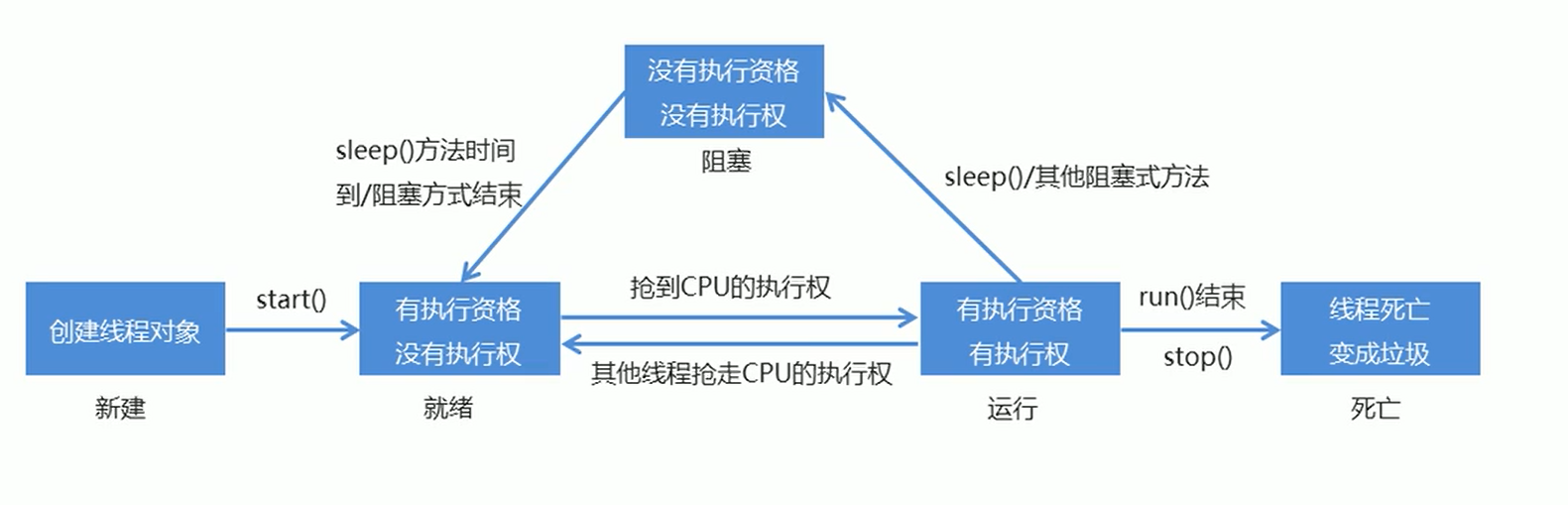
线程同步,数据安全问题:
判断多线程程序是否会有数据安全问题的标准:
- 是否是多线程环境
- 是否有共享数据
- 是否有多条语句操作共享数据
同步代码块:
锁多条语句操作共享数据,可以使用同步代码块实现
-
格式:
synchronized(任意对象){ //多条语句操作共享数据代码 } -
synchronized(任意对象):就相当于给代码枷锁了,任意对象就可以看成是一把锁
同步的好处和弊端
- 好处:解决了多线程的数据安全问题
- 弊端:当线程很多时,因为每个线程都会去判断同步上的锁,这是很耗费资源的,无形中会降低程序的运行效率
同步方法:
同步方法就是把synchronized关键字加到方法上,格式:修饰符 synchronized 返回值类型 方法名(方法参数) { }
同步方法的锁对象:this
同步静态方法:就是把synchronized关键字加到静态方法上,格式:
修饰符 static synchronized 返回值类型 方法名(方法参数) { }
同步静态方法的锁对象:类名.class
线程安全的类:
StringBuffer
- 线程安全,可变的字符序列
- 从版本JDK 5开始,被StringBuilder替代。通常应该使用StringBuilder类,因为它支持所有相同的操作,但它更快,因为它不执行同步
Vector
- 从Java 2平台v1.2开始,该类改进了List接口,使其成为JavaCollectionsFramework的成员。与新的集合实现不同,Vector被同步。如果不需要线程安全的实现,建议使用ArrayList代替Vector
Hashtable
- ·该类实现了一个哈希表,它将键映射到值。任何非null对象都可以用作键或者值
- 从Java 2平台v1.2开始,该类进行了改进,实现了Map接口,使其成为JavaCollections Framework的成员。与新的集合实现不同,Hashtable被同步。如果不需要线程安全的实现,建议使用HashMap代替Hashtable
Lock锁:
虽然我们可以理解同步代码块和同步方法的锁对象问题,但是我们并没有直接看到在哪里加上了锁,在哪里释放了锁,为了更清晰的表达如何加锁和释放锁,JDK5以后提供了一个新的锁对象Lock
Lock实现提供比使用synchronized方法和语句可以获得更广泛的锁定操作Lock中提供了获得锁和释放锁的方法
void lock() //获得锁
void unlock() //释放锁
Lock是接口不能直接实例化,这里采用它的实现类ReentrantLock来实例化ReentrantLock的构造方法:
ReentrantLock):创建一个ReentrantLock的实例
生产者消费者:
生产者消费者模式是一个十分经典的多线程协作的模式。所谓生产者消费者问题,实际上主要包含了两类线程:
- 一类是生产者线程用于生产数据
- 一类是消费者线程用于消费数据
为了解耦生产者和消费者的关系,通常会采用共享的数据区域,就像是一个仓库
- 生产者生产数据之后直接放置在共享数据区中,并不需要关系消费者的行为
- 消费者只需要从共享数据区中获取数据,并不需要关心生产者的行为
为了体现生产和消费过程中的等待和唤醒,Java提供了几个方法供我们使用,这几个方法在Object类中。Object类的等待和唤醒方法:
void wait() //导致当前线程等待,直到另一个线程调用该对象的notify()方法或notifyAll()方法
void notify() //唤醒正在等待对象监视器的单个线程
void notifyAll() //唤醒正在等待对象监视器的所有线程
网络编程
网络编程概述:在网络通信协议下,实现网络互连的不同计算机上运行的程序间可以进行数据交换
网络编程三要素:
IP地址
- 要想让网络中的订异D润E简机而IP地址就是这个标识号。也就是设备的标识据的计算机和识别发送的计算机,而IP地址就是这个标识号。也就是设备的标识
端口
- 网络的通信,本质上是两个应用程序的通信。每台计算机都有很多的应用程序,那么在网络通信时,如何区分这些应用程序呢?如果说IP地址可以唯一标识网络中的设备,那么端口号就可以唯一标识设备中的应用程序了。也就是应用程序的标识
协议
- 通过计算机网络可以使多台计算机实现连接,位于同一个网络中的计算机在进行连接和通信时需要遵守一定的规则,这就好比在道路中行驶的汽车一定要遵守交通规则一样。在计算机网络中,这些连接和通信的规则被称为网络通信协议,它对数据的传输格式、传输速率、传输步骤等做了统一规定,通信双方必须同时遵守才能完成数据交换。常见的协议有UDP协议和TCP协议
InetAddress的使用:
为了方便我们对IP地址的获取和操作,Java提供了一个类InetAddress供我们使用
InetAddress:此类表示Internet协议(IP)地址
static InetAddress getByName(String host) //确定主机的IP地址。主机名称可以是机器名称,也可以是IP地址
String getHostName() //获取此IP地址的主机名
String getHostAddress() //返回文本显示中的IP地址字符串
端口:
端口是设备上应用程序的唯一标识。端口号是用两个字节表示的整数,它的取值范围是065535。其中01023之间的端口号用于一些知名的网络服务和应用,普通的应用程序需要使用1024以上的端口号。如果端口号被另外一个服务或应用所占用,会导致当前程序启动失败
协议:
UDP协议
- 用户数据报协议(User Datagram Protocol)
- UDP是无连接通信协议,即在数据传输时,数据的发送端和接收端不建立逻辑连接。简单来说,当一台计算机向另外一台计算机发送数据时,发送端不会确认接收端是否存在,就会发出数据,同样接收端在收到数据时,也不会向发送端反馈是否收到数据。
- 由于使用UDP协议消耗资源小,通信效率高,所以通常都会用于音频、视频和普通数据的传输
- 例如视频会议通常采用UDP协议,因为这种情况即使偶尔丢失一两个数据包,也不会对接收结果产生太大影响。但是在使用UDP协议传送数据时,由于UDP的面向无连接性,不能保证数据的完整性,因此在传输重要数据时不建议使用UDP协议
TCP协议
- 传输控制协议(Transmission Control Protocol)
- TCP协议是面向连接的通信协议,即传输数据之前,在发送端和接收端建立逻辑连接,然后再传输数据,它提供了两台计算机之间可靠无差错的数据传输。在TCP连接中必须要明确客户端与服务器端,由客户端向服务端发出连接请求,每次连接的创建都需要经过“三次握手”
- 三次握手:TCP协议中,在发送数据的准备阶段,客户端与服务器之间的三次交互,以保证连接的可靠
- 第1次握手,客户端向服务器端发出连接请求,等待服务器确认
- 第2次握手,服务器端向客户端回送一个响应,通知客户端收到了连接请求
- 第3次握手,客户端再次向服务器端发送确认信息,确认连接
- 完成三次握手,连接建立后,客户端和服务器就可以开始进行数据传输了。由于这种面向连接的特性,TCP协议可以保证传输数据的安全,所以应用十分广泛。例如上传文件、下载文件、浏览网页等
UDP收发数据:
//发送数据的步骤
//(1)创建发送端的Socket对象(DatagramSocket)
DatagramSocket()
//(2)创建数据,并把数据打包
DatagramPacket(byte[] buf,int length,InetAddress address,int port)
//(3)调用DatagramSocket对象的方法发送数据
void send(DatagramPacket p)
//(4)关闭发送端
void close()
//接收数据的步骤
//(1)创建接收端的Socket对象(DatagramSocket)
DatagramSocket(int port)
//(2)创建一个数据包,用于接收数据
DatagramPacket(byte[] buf,int length)
//(3)调用DatagramSocket对象的方法接收数据
void receive(DatagramPacket p)
//(4)解析数据包,并把数据在控制台显示
byte[] getData()
int getLength()
//(5)关闭接收端
void close()
TCP通信:
TCP通信原理:
TCP通信协议是一种可靠的网络协议,它在通信的两端各建立一个Socket对象,从而在通信的两端形成网络虚拟链路,一旦建立了虚拟的网络链路,两端的程序就可以通过虚拟链路进行通信
Java对基于TCP协议的的网络提供了良好的封装,使用Socket对象来代表两端的通信端口,并通过Socket产生I0流来进行网络通信
Java为客户端提供了Socket类,为服务器端提供了ServerSocket类
TCP收发数据:
//发送数据的步骤
//(1)创建客户端的Socket对象(Socket)
Socket(String host,int port)
//(2)获取输出流,写数据
OutputStream getOutputStream()
//(3)释放资源
void close()
//接收数据的步骤
//(1)创建服务器端的Socket对象(ServerSocket)
ServerSocket(int port)
//(2)监听客户端连接,返回一个Socket对象
Socket accept()
//(3)获取输入流,读数据,并把数据显示在控制台
InputStream getInputStream()
//(4)释放资源
void close()
Lambda表达式
面向对象思想强调“必须通过对象的形式来做事情”,函数式思想则尽量忽略面向对象的复杂语法:“强调做什么,而不是以什么形式去做”。而Lambda表达式就是函数式思想的体现
Lambda表达式的格式:
new Thread(()->{
System.out.println("多线程程序启动了");
}).start();
分析:
- ():里面没有内容,可以看成是方法形式参数为空
- ->:用箭头指向后面要做的事情
- {}:包含一段代码,我们称之为代码块,可以看成是方法体总的内容
- 组成Lambda表达式的三要素:形式参数,箭头,代码块
Lambda表达式的格式:
- 格式:(形式参数)->{代码块}
- 形式参数:如果有多个参数,参数之间用逗号隔开;如果没有参数,留空即可
- ->:由英文中画线和大于符号组成,固定写法。代表指向动作
- 代码块:是我们具体要做的事情,也就是以前我们写的方法体内容
Lambda表达式的省略规则:
- 参数类型可以省略。但是有多个参数的情况下,不能只省略一个
- 如果参数有且仅有一个,那么小括号可以省略
- 如果代码块的语句只有一条,可以省略大括号和分好,如果语句中含有return,则return也必须省略
Lambda表达式的注意事项:
- 使用Lambda表达式必须要有接口,并且要求接口中有且仅有一个抽象方法
- 必须要有上下文环境,才能推导出Lambda对应的接口
- 根据局部变量的幅值得知Lambda对应的接口:Runnable r = () -> System.out.println(“Lambda表达式”);
- 根据调用方法的参数得知Lambda对应的接口:new Thread(() -> System.println.out(“Lambda表达式”)).start();
Lambda表达式和匿名内部类的区别:
- 所需类型不同
- 匿名内部类:可以是接口,也可以是抽象类,还可以是具体类
- Lambda表达式:只能是接口
- 使用限制不同
- 如果接口中有且仅有一个抽象方法,可以使用Lambda表达式,也可以使用匿名内部类
- 如果接口中多于一个抽象方法,只能使用匿名内部类,而不能使用Lambda表达式
- 实现原理不同
- 匿名内部类:编译之后,产生一个单独的.class字节码文件
- Lambda表达式:编译之后,没有一个单独的.class字节码文件。对应的字节码会在运行的时候动态生成
接口组成更新
接口的组成:
- 常量
public static final - 抽象方法
public abstract - 默认方法(Java8)
- 静态方法(Java8)
- 私有方法(Java9)
接口中默认方法:
接口中默认方法的定义格式:public default 返回值类型 方法名(参数列表) { }
注意事项:默认方法不是抽象方法,所以不强制被重写,但是可以被重写,重写的时候去掉default关键字;public可以省略,default不能省略
接口中静态方法:
接口中静态方法的定义格式:public static void 返回值类型 方法名(参数列表) { }
注意事项:静态方法只能通过接口名调用,不能通过实现类型或者对象名调用;public可以省略,static不能省略
接口中私有方法:
Java 9中新增了带方法体的私有方法,这其实在Java8中就埋下了伏笔: Java8允许在接口中定义带方法体的默认方法和静态方法。这样可能就会引发一个问题:当两个默认方法或者静态方法中包含一段相同的代码实现时,程序必然考虑将这段实现代码抽取成一个共性方法,而这个共性方法是不需要让别人使用的,因此用私有给隐藏起来,这就是Java 9增加私有方法的必然性
接口中私有方法的定义格式:
//格式1: private返回值类型方法名(参数列表){}
private void show) { }
//格式2: private static返回值类型方法名(参数列表){}
private static void method({}
/*
接口中私有方法的注意事项:
默认方法可以调用私有的静态方法和非静态方法
静态方法只能调用私有的静态方法
*/
方法引用
在使用Lambda表达式的时候,我们实际上传递进去的代码就是一种解决方案:拿参数做操作。如果我们在Lambda中所指定的操作方案,已经有地方存在相同方案,那就没有必要再写重复逻辑。我们通过方法引用来使用已经存在的方案
方法引用符:
-方法引用符 :: 该符号为引用运算符,而它所在的表达式被称为方法引用
回顾一下我们在体验方法引用中的代码
Lambda表达式:usePrintable(s-> System.out.printIn(s));
分析:拿到参数s 之后通过Lambda表达式,传递给System.out.println方法去处理
方法引用:usePrintable(System.out:printIn);
分析:直接使用System.out中的printIn方法来取代Lambda,代码更加的简洁
推导与省略
-
如果使用Lambda,那么根据“可推导就是可省略”的原则,无需指定参数类型,也无需指定的重载形式,它们都将被自动推导
-
如果使用方法引用,也是同样可以根据上下文进行推导
-
方法引用是Lambda的孪生兄弟
Lambda表达式支持的方法引用:
- 引用类方法:其实就是引用类的静态方法
- 格式:类名::静态方法
- 范例:Integer::parseInt Integer类的方法:public static int parseInt(String s)将此String转换为int类型数据
- Lambda表达式被类方法替代的时候,它的形式参数全部传递给静态方法作为参数
- 引用对象的实例方法:其实就是引用类中的成员方法
- 格式:对象::成员方法
- 范例:“HelloWorld”::toUpperCase String类中的方法:public String toUpperCase()将此String所有字符转换为大写
- Lambda表达式被对象的实例方法替代的时候,它的形式参数全部传递给该方法作为参数
- 引用类的实例方法:其实就是引用类中的成员方法
- 格式:类名::成员方法
- 范例:String::substring String类中的方法:public String substring(int beginindex, int endindex)从beginindex开始到endindex结束,截取字符串。返回一个子串,子串的长度为endindex-beginindex
- Lambda表达式被类的实例方法替代的时候,第一个参数作为调用者,后面的参数全部传递给该方法作为参数
- 引用构造器:其实就是引用构造方法
- 格式:类名::new
- 范例:Student::new
- Lambda表达式被构造器替代的时候,它的形式参数全部传递给构造器作为参数
函数式接口
函数式接口:有且仅有一个抽象方法的接口。Java中的函数式编程体现就是Lambda表达式,所以函数式接口就是可以适用于Lambda使用的接口。只有确保接口中有且仅有一个抽象方法,Java中的Lambda才能顺利地进行推导
监测一个接口是函数式接口的方法:
(注解)@FunctionalInterface,放在接口定义的上方:如果接口是函数式接口,编译通过;如果不是,编译失败
注意:我们自己定义函数式接口的时候,@FunctionalInterface是可选的,就算不写这个注解,只要保证满足函数式接口定义的条件,也照样是函数式接口。但是建议加上该注解
**函数式接口作为方法的参数:**如果方法的参数是一个函数式接口,我们可以使用Lambda表达式作为参数传递
**函数式接口作为方法的返回值:**如果方法的返回值是一个函数式接口,我们可以使用Lambda表达式作为结果返回
常用的函数式接口:
-
Supplier接口
Supplier:包含一个无参的方法
-
T get():获得结果
-
该方法不需要参数,它会按照某种实现逻辑(由Lambda表达式实现)返回一个数据
-
Supplier接口也被称为生产型接口,如果我们指定了接口的泛型是什么类型,那么接口中的get方法就会生产什么类型的数据供我们使用
-
-
Consumer接口
Consumer:包含两个方法
-
void accept(T t):对给定的参数执行此操作 -
default Consumer<T> andThen(Consumer after):返回一个组合的Consumer,依次执行此操作,然后执行after操作 -
Consumer接口也被称为消费型接口,它消费的数据的数据类型由泛型指定
-
-
Predicate接口
Predicate:常用的四个方法
-
boolean test(T t):对给定的参数进行判断(判断逻辑由Lambda表达式实现),返回一个布尔值 -
default Predicate<T> negate():返回一个逻辑的否定,对应逻辑非 -
default Predicate<T> and(Predicate other):返回一个组合判断,对应短路与 -
default Predicate<T> or(Predicate other):返回一个组合判断,对应短路或 -
Predicate<T>接口通常用于判断参数是否满足指定的条件
-
-
Function接口
Function<T,R>:常用的两个方法
-
R apply(Tt):将此函数应用于给定的参数 -
default <V> Function andThen(Function after):返回一个组合函数,首先将该函数应用于输入,然后将after函数应用于结果 -
Function<T,R>接口通常用于对参数进行处理,转换(处理逻辑由Lambda表达式实现),然后返回一个新的值
-
Stream流
Stream流的使用:
- 生成流:通过数据源(集合、数组等)生成流,list.stream()
- 中间操作:一个流后面可以跟随零个或多个中间操作,其目的主要是打开流,做出某种程度的数据过滤/映射,然后返回一个新的流,交给下一个操作使用,filter()
- 终结操作:一个流只能有一个终结操作,当这个操作执行后,流就被使用“光了”,无法再被操作。所以这必定是流的最后一个操作,forEach()
Stream流的生成方式:
Stream流的常见生成方式
-
Collection体系的集合可以使用默认方法stream()生成流:
default Stream<E> stream() -
Map体系的集合间接的生成流·
-
数组可以通过Stream接口的静态方法of(T… values)生成流·
Stream流的常见中间操作方法:
Stream<T> filter(Predicate predicate) //用于对流中的数据进行过滤
//Predicate接口中的方法对给定的参数进行判断,返回一个布尔值 boolean test(T t)
Stream<T> limit(long maxSize) //返回此流中的元素组成的流,截取前指定参数个数的数据
Stream<T> skip(long n) //跳过指定参数个数的数据,返回由该流的剩余元素组成的流
static <T> Stream<T> concat(Stream a, Stream b) //合并a和b两个流为一个流
Stream<T> distinct() //返回由该流的不同元素(根据Objectequals(Object))组成的流
Stream<T> sorted() //返回由此流的元素组成的流,根据自然顺序排序
Stream<T> sorted(Comparator comparator) //返回由该流的元素组成的流,根据提供的Comparator进行排序
<R> Stream<R> map(Function mapper) //返回由给定函数应用于此流的元素的结果组成的流
//Function接口中的方法 R apply(T t)
IntStream mapToInt(ToIntFunction mapper) //返回一个IntStream其中包含将给定函数应用于此流的元素的结果 IntStream:表示原始int流
//TolntFunction接口中的方法 int applyAsInt(T value)
Stream流的常见终结操作方法:
void forEach(Consumer action) //对此流的每个元素执行操作 Consumer接口中的方法
//void accept(T t) 对给定的参数执行此操作
long count() //返回此流中的元素数
Stream流的收集操作:
对数据使用Stream流的方式操作完毕后,我想把流中的数据收集到集合中,该怎么办呢?
Stream流的收集方法
-
R collect(Collector collector) -
但是这个收集方法的参数是一个Collector接口
-
工具类Collectors提供了具体的收集方式
public static <T> Collector toList() //把元素收集到List集合中 public static <T> Collector toSet() //把元素收集到Set集合中 public static Collector toMap(Function keyMapper,Function valueMapper) //把元素收集到Map集合中
反射
类加载:
当程序要使用某个类时,如果该类还未被加载到内存中,则系统会通过类的加载,类的连接,类的初始化这三个步骤来对类进行初始化。如果不出现意外情况,JVM将会连续完成做三个步骤,所以有时也把这三个步骤统称为类加载或者类初始化
类的加载
-
就是指将class文件读入内存,并为之创建一个java.lang.Class对象
-
任何类被使用时,系统都会为之建立一个java.lang.Class对象
类的连接
-
验证阶段:用于检验被加载的类是否有正确的内部结构,并和其他类协调一致
-
准备阶段:负责为类的类变量分配内存,并设置默认初始化值
-
解析阶段:将类的二进制数据中的符号引用替换为直接引用
类的初始化
- 在该阶段,主要就是对类变量进行初始化
类的初始化步骤和时机:
类的初始化步骤:
-
假如类还未被加载和连接,则程序先加载并连接该类
-
假如该类的直接父类还未被初始化,则先初始化其直接父类
-
假如类中有初始化语句,则系统依次执行这些初始化语句
-
注意:在执行第2个步骤的时候,系统对直接父类的初始化步骤也遵循初始化步骤1-3
类的初始化时机:
-
创建类的实例
-
调用类的类方法
-
访问类或者接口的类变量,或者为该类变量赋值
-
使用反射方式来强制创建某个类或接口对应的java.lang.Class对象
-
初始化某个类的子类
-
直接使用java.exe命令来运行某个主类、
类加载器的作用:
-
负责将.class文件加载到内存中,并为之生成对应的java.lang.Class对象
-
虽然我们不用过分关心类加载机制,但是了解这个机制我们就能更好的理解程序的运行
JVM的类加载机制
-
全盘负责:就是当一个类加载器负责加载某个Class时,该Class所依赖的和引用的其他Class也将由该类加载器负责载入,除
非显式使用另外一个类加载器来载入 -
父类委托:就是当一个类加载器负责加载某个Class时,先让父类加载器试图加载该Class,只有在父类加载器无法加载该类
时才尝试从自己的类路径中加载该类 -
缓存机制:保证所有加载过的Class都会被缓存,当程序需要使用某个Class对象时,类加载器先从缓存区中搜索该Class,只
有当缓存区中不存在该Class对象时,系统才会读取该类对应的二进制数据,并将其转换成Class对象,存储到缓存区
内置类加载器:
ClassLoader:是负责加载类的对象
Java运行时具有以下内置类加载器
-
Bootstrap class loader:它是虚拟机的内置类加载器,通常表示为null,并且没有父null -
Platform class loader:平台类加载器可以看到所有平台类,平台类包括由平台类加载器或其祖先定义的Java SE平台API,其实现类和JDK特定的运行时类 -
System class loader:它也被称为应用程序类加载器,与平台类加载器不同。系统类加载器通常用于定义应用程序类路径,模块路径和JDK特定工具上的类 -
类加载器的继承关系: System的父加载器为Platform,而Platform的父加载器为Bootstrap
ClassLoader中的两个方法
static ClassLoader getSystemClassLoader() //返回用于委派的系统类加载器
ClassLoader getParent() //返回父类加载器进行委派
反射概述:
Java反射机制:是指在运行时去获取一个类的变量和方法信息,然后通过获取到的信息来创建对象,调用方法的一种机制。由于这种动态性,可以极大的增强程序的灵活性,程序不用在编译期就完成确定,在运行期仍然可以扩展。
获取Class类的对象:
我们要想通过反射去使用一个类,首先我们要获取到该类的字节码文件对象,也就是类型为Class类型的对象
这里我们提供三种方式获取Class类型的对象
-
使用
类的class属性来获取该类对应的Class对象。举例: Studentclass将会返回Student类对应的Class对象 -
调用对象的
getClass()方法,返回该对象所属类对应的Class对象.该方法是Object类中的方法,所有的Java对象都可以调用该方法 -
使用Class类中的静态方法
forName(String className),该方法需要传入字符串参数,该字符串参数的值是某个类的全路径,也就是完整包名的路径
反射获取构造方法并使用:
//Class类中用于获取构造方法的方法
Constructor<?>[] getConstructors() //返回所有公共构造方法对象的数组
Constructor<?>[] getDeclaredConstructors() //返回所有构造方法对象的数组
Constructor<T> getConstructor(Class<?>...parameterTypes) //返回单个公共构造方法对象
Constructor<T> getDeclaredConstructor(Class<?>...parameterTypes) //返回单个构造方法对象
//Constructor类中用于创建对象的方法
T newInstance(Object... initargs) //根据指定的构造方法创建对象
反射获取成员变量并使用:
//Class类中用于获取成员变量的方法
Field[] getFields() //返回所有公共成员变量对象的数组
Field[] getDeclaredFields() //返回所有成员变量对象的数组
Field getField(String name) //返回单个公共成员变量对象
Field getDeclaredField(String name) //返回单个成员变量对象
//Field类中用于给成员变量赋值的方法
void set(Object obj, Object value) //给obj对象的成员变量赋值为value
反射获取成员方法并使用:
//Class类中用于获取成员方法的方法
Method[] getMethods() //返回所有公共成员方法对象的数组,包括继承的
Method[] getDeclaredMethods() //返回所有成员方法对象的数组,不包括继承的
Method getMethod(String name, Class<?>... parameterTypes) //返回单个公共成员方法对象
Method getDeclaredMethod(String name, Class<?>... parameterTypes) //返回单个成员方法对象
//Method类中用于调用成员方法的方法
Object invoke(Object obj, Object..args) //调用obj对象的成员方法,参数是args,返回值是Object类型















 803
803











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









