







KNN算法是机器有监督学习的一种算法,它既可以实现分类,也可以实现回归。
分类(KNeighborsClassifie):
假设现在已经有n个样本,并且该n个样本已经分好类别,现有新的样本X,要判断X属于哪一类别,通过计算与给定的**k值(默认5)**个已有样本的距离,来判断这k个样本所属最多的类别,则认为新样本X也属于这个类别

from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split,GridSearchCV
from sklearn.neighbors import KNeighborsClassifie
# 获取数据
iris load_iris()
x_train,x_test,y_train,y_test = train_test_split(iris.data,iris.target,test_size=0.3,random_state=2)
# 标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.fit_transform(x_test)
# 实例化分类器
estimator = KNeighborsClassifier(n_neighbors = 9)
# 交叉验证网格搜索
params_grid = {'n_neighbors': [1,3,5,7,9,11]}
estimator = GridSearchCV(estimator,param_grid = params_grid,cv=5)
# 模型训练
estimator.fit(X_train,y_train)
# 模型评估
y_pre = estimator.predict(x_test)
print(y_pre)
print(y_test)
# 准确率
ret = estimator.score(x_test,y_test)
print('准确率:',ret)
# 最好的模型,得分,结果
print('最好的模型:',estimator.best_estimator_)
print('最好的得分:',estimator.best_score_)
print('最好的结果:',estimator.cv_results_)
回归(KNeighborsRegressor):
KNN算法用于回归预测时,同样是寻找新来的预测实例的k近邻,然后对这k个样本的目标值去均值即可作为新样本的预测值:
KNN优缺点:
优点:精度高,对异常值不明显,无数据输入假定
缺点:计算复杂,计算量大,空间复杂度高
扩展:
KNN中常用的距离有三种:
曼哈顿距离:两点在南北方向上的距离加上在东西方向上的距离。 d(i,j) = | xi - xj | + | yi - yj |
欧几里得距离: 指在n维空间里两点之间的真实距离,或向量的自然长度。
闵可夫斯基距离: 假设n维空间中有两点坐标x, y,p为常数,闵式距离定义为:
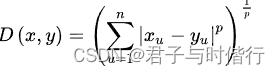















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









