






在处理数据时遇到一个问题:
python在读取txt文件时,利用split()函数分割空格后,获得的数据列表中都包含有单引号

content内容如下:可以看到是只有数字
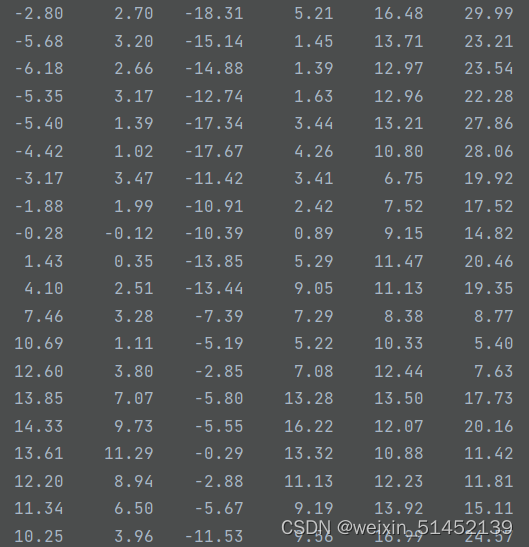
但经过split()函数进行分割空格后,每个数字都被添加了引号

通过输出其中的类型可以看到是字符串类型![]()
因此需要将其转为所需要的形式,这里是float:
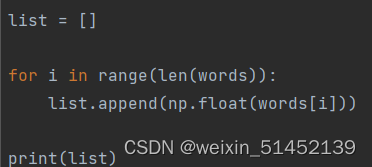
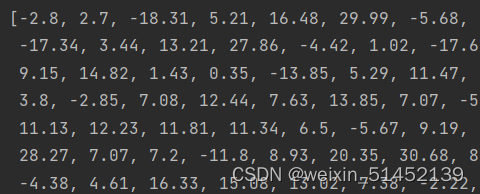
可以看到处理过的已经是不带引号的float类型了,就可以进行后续处理
注意:这个引号是字符串自带的,不能依靠切片方法进行去除;
在更换类型的时候,可以新建一个空的,也直接更改原始的列表;















 431
431

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









