






目录
数据集来源
黑色星期五数据集 - 飞桨AI Studio (baidu.com)
本人将数据集train.csv更名为BlackFriday.csv
准备工作
导入数据集与库
# 整体数据概览
"""
数据量、字段、缺失情况、数据取值情况等等
"""
import pandas as pd
# 导入数据
bf_df = pd.read_csv("data/BlackFriday.csv")查看数据
1.查看行列数量
# 查看数据行列
print(bf_df.shape) #(550068, 12)2.查看字段
# 产查看字段
print(bf_df.columns) # 列名
print(bf_df.head(2)) # 对应前两行3.重新命名
# rename
bf_df.columns = ["顾客ID", "商品ID", "性别", "年龄", "职业", "城市类别", "居住时间", "婚姻状况", "商品类别1", "商品类别2", "商品类别3", "购买金额"]
print(bf_df.head())
print(len(bf_df.columns))4.查看缺失值
# 查看缺失值
print(bf_df.info())运行结果
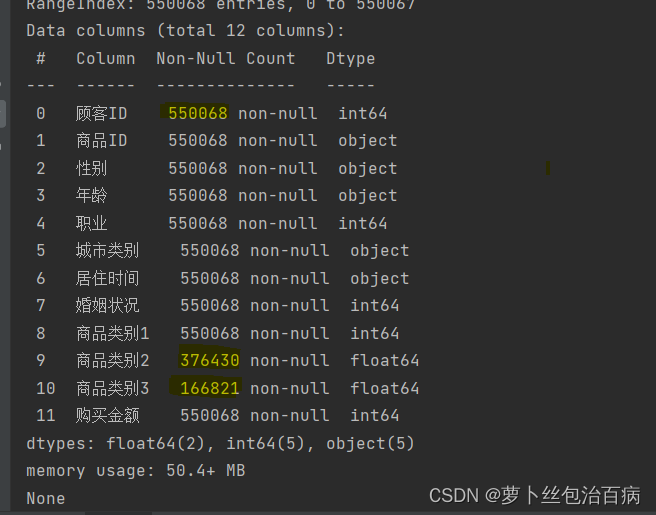
可以看到样本总量为550068,count表示记录了未缺失的,然而在商品类别2、商品类别3中数据总量仅为376430与166821,有数据缺失,因此下面我用0对缺失数据进行填充
5.用0进行缺失值填充
# 用0进行缺失值填充
bf_df=bf_df.fillna(0)
print(bf_df.info())
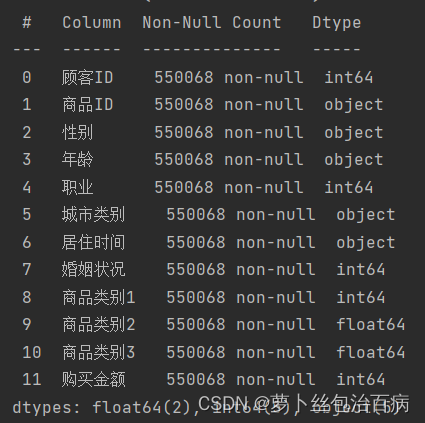
可以看到填充过后商品数量是齐全的
6.每个字段取值情况
# 每个字段的取值情况
# 离散型['F' 'M']
gender = bf_df["性别"].unique() # unqiue()去重。
print(gender)
age = bf_df["年龄"].unique()
occupation = bf_df["职业"].unique()
city = bf_df["城市类别"].unique()
stay_year = bf_df["居住时间"].unique()
marry_status = bf_df["婚姻状况"].unique()
cate_1 = bf_df["商品类别1"].unique()
print("年龄:", age)
print("职业:", occupation)
print("城市类别:", city)
print("居住时间:", stay_year)
print("婚姻状况:", marry_status)
print("商品类别1:", cate_1)整体代码
# 整体数据概览
"""
数据量、字段、缺失情况、数据取值情况等等
"""
import pandas as pd
# 导入数据
bf_df = pd.read_csv("data/BlackFriday.csv")
# 查看数据行列
# print(bf_df.shape) #(550068, 12)
# 产查看字段
# print(bf_df.columns) # 列名
# print(bf_df.head(2)) # 对应前两行
# rename
bf_df.columns = ["顾客ID", "商品ID", "性别", "年龄", "职业", "城市类别", "居住时间", "婚姻状况", "商品类别1", "商品类别2", "商品类别3", "购买金额"]
# print(bf_df.head())
# print(len(bf_df.columns))
# 查看缺失值
# print(bf_df.info())
# 用0进行缺失值填充
# bf_df=bf_df.fillna(0)
# print(bf_df.info())
# 每个字段的取值情况
# 离散型['F' 'M']
gender = bf_df["性别"].unique() # unqiue()去重。
# print(gender)
age = bf_df["年龄"].unique()
occupation = bf_df["职业"].unique()
city = bf_df["城市类别"].unique()
stay_year = bf_df["居住时间"].unique()
marry_status = bf_df["婚姻状况"].unique()
cate_1 = bf_df["商品类别1"].unique()
print("年龄:", age)
print("职业:", occupation)
print("城市类别:", city)
print("居住时间:", stay_year)
print("婚姻状况:", marry_status)
print("商品类别1:", cate_1)














 2875
2875











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









