







前言与介绍
本文章介绍了如何在Pycharm上用python语言简单的对连接百度ai开放平台的语音识别功能api端口的调用,并在代码里实现了现录音识别内容。
平台与相关工具
windows10、Pycharm、Python3.9
百度智能云官网为:百度ai开放平台官网
操作流程
-
注册百度智能云账号并打开控制台
百度ai平台有许多现有的功能端口可以使用 -
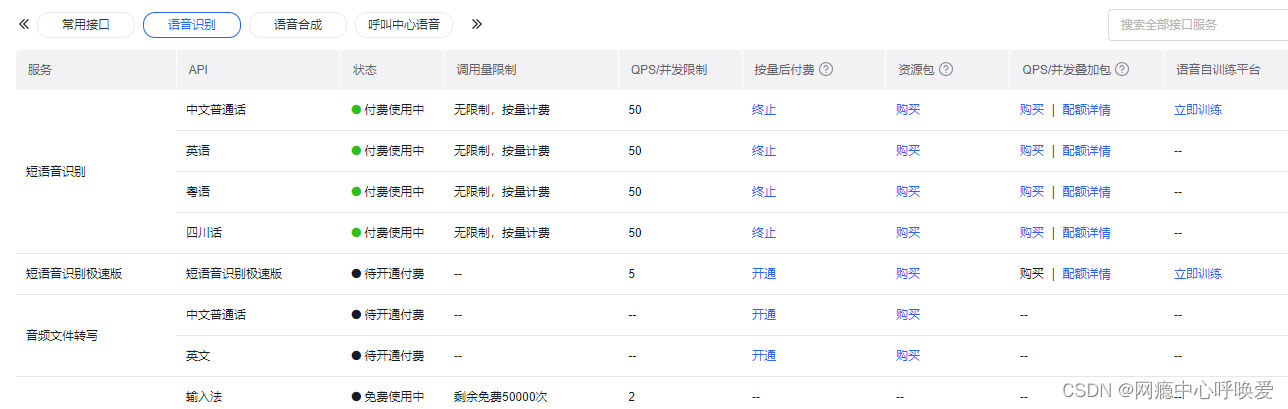
创建自己的应用并按需求开通端口

比如我这里开启了短语音识别的四种语言端口
-
创建应用后在应用中心可以查询应用的API KEY与Secret Key(这两个最重要且在后续需要用到)

-
为自己的账户充一点点钱(一两块就行),每次调用端口会有一点点的消费
-
通过代码调用端口
# encoding:utf-8
import wave
import requests
import time
import base64
from pyaudio import PyAudio, paInt16
import webbrowser
framerate = 16000 # 采样率
num_samples = 2000 # 采样点
channels = 1 # 声道
sampwidth = 2 # 采样宽度 2bytes
FILEPATH = 'speech.wav' # 设置语音文件保存位置
base_url = "https://openapi.baidu.com/oauth/2.0/token?grant_type=client_credentials&client_id=%s&client_secret=%s"
APIKey = "这里填入自己的"
SecretKey = "这里填入自己的"
HOST = base_url % (APIKey, SecretKey)
def getToken(host):
res = requests.post(host) #获取 access_token
return res.json()['access_token']
def save_wave_file(filepath, data):
wf = wave.open(filepath, 'wb')
wf.setnchannels(channels)
wf.setsampwidth(sampwidth)
wf.setframerate(framerate)
wf.writeframes(b''.join(data))
wf.close()
def my_record():
pa = PyAudio()
stream = pa.open(format=paInt16, channels=channels,rate=framerate, input=True, frames_per_buffer=num_samples)
my_buf = []
# count = 0
t = time.time()
print('正在录音...')
while time.time() < t + 5: # 秒
string_audio_data = stream.read(num_samples)
my_buf.append(string_audio_data)
print('录音结束.')
save_wave_file(FILEPATH, my_buf)
stream.close()
def get_audio(file):
with open(file, 'rb') as f:
data = f.read()
return data
def speech2text(speech_data, token, dev_pid=1537):
FORMAT = 'wav'
RATE = '16000'
CHANNEL = 1
CUID = 'ag2s'
SPEECH = base64.b64encode(speech_data).decode('utf‐8')
data = {
'format': FORMAT,
'rate': RATE,
'channel': CHANNEL,
'cuid': CUID,
'len': len(speech_data),
'speech': SPEECH,
'token': token,
'dev_pid': dev_pid
}
url = "https://vop.baidu.com/server_api"
headers = {
'Content-Type': 'application/json',
'Accept': 'application/json'
}
# r=requests.post(url,data=json.dumps(data),headers=headers)
print('正在识别...')
r = requests.post(url, json=data, headers=headers)
Result = r.json()
if 'result' in Result:
return Result['result'][0]
else:
return Result
if __name__ == '__main__':
flag = 'y'
while flag.lower() == 'y':
print('请输入数字选择语言:')
devpid = input('1536:普通话(简单英文),1537:普通话(有标点),1737:英语,1637:粤语,1837:四川话\n')
my_record()
TOKEN = getToken(HOST)
speech = get_audio(FILEPATH)
result = speech2text(speech, TOKEN, int(devpid))
print(result)
flag = input('Continue?(y/n):')
代码运行后结果如下: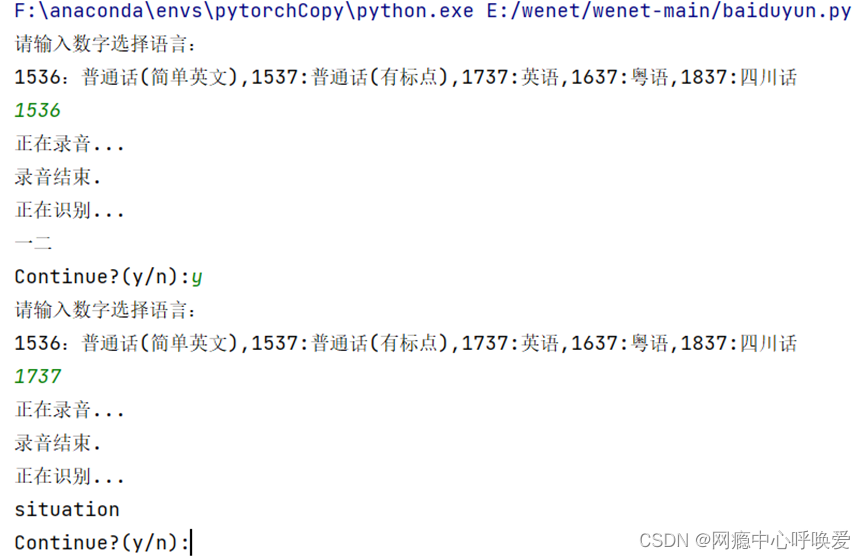
dev_pid表格如下:
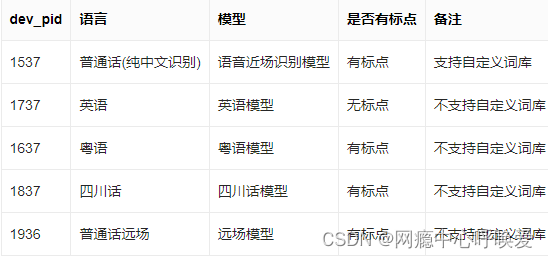
注意:百度短语音识别之接受60秒以下的音频识别成文字,并有音频格式和编码的要求,如果输入的音频不符合要求需要进行转换(具体方法请查看官方提供的api文档)官方音频转换方式

















 2855
2855











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











