






 本文详细讲解了正则表达式的使用,包括数字匹配、范围指定、分组、边界查找、内部约束等,并通过实例展示了如何在Python中应用正则表达式进行文本处理,例如查找电话号码、手机号码以及特定模式的字符串。同时,介绍了正则表达式的各种匹配方法(如search、match、findall、finditer)以及替换操作和分割功能。
本文详细讲解了正则表达式的使用,包括数字匹配、范围指定、分组、边界查找、内部约束等,并通过实例展示了如何在Python中应用正则表达式进行文本处理,例如查找电话号码、手机号码以及特定模式的字符串。同时,介绍了正则表达式的各种匹配方法(如search、match、findall、finditer)以及替换操作和分割功能。
正则使用详讲——个人向:
一定要注意!正则内不能随便加空格 能不加就不加
{a,b}:表示从a到b的范围 a,b都包括 最好只用两个数字
()--代表一组
[]-- 匹配一个范围中的任意一个 或者具体几个 方括号内的 ^ 表示取反
~
import re
text = '名字: 136, 身高: 598,学号:17569, 136'
print(re.findall(r'136', text))
['136', '136']
~
print(re.findall(r'\d', text)) #匹配单个数字 findall是查找全部
['1', '3', '6', '5', '9', '8', '1', '7', '5', '6', '9', '1', '3', '6']
~
'''
找出所有的数字 连着的 不用分开
\d+: +号是修饰前面的正则的 表示有一个或多个 都需要匹配
\d+: 意思就是 1、是数字 2、这个数字有一个或多个
'''
print(re.findall(r'\d+', text))
['136', '598', '17569', '136']
~
'''
找出座机号码
分析得知 座机号码是: 3位或4位数字 + ‘-’ + 7位或8位数字
'''
text1 = '幸运数字:4564654546546,手机号:17516375901, 座机号码:0571-2855946'
print(re.findall(r'\d{3,4}-\d{5,7}', text1))
['0571-2855946']
~
'''
匹配多种情况 手机号 和 坐机号 '或者':在正则表达式里用 | 表示
手机号:1开头
'''
print(re.findall(r'\d{3,4}-\d{7,8}|1\d{10}', text1))
['17516375901', '0571-2855946']
~
'''
限定匹配位置
手机号要么出现在最前面 要么出现在最后面
^ 放在正则前面 表示正则匹配开头 $放在后面 表示结尾匹配
只匹配出现在最前面的手机号 和 出现在最后面的座机号
'''
text2 = '17516375901幸运数字:4564654546546,手机号:17516375901,座机号码:0571-2855948 座机号码:0571-28559'
print(re.findall(r'^1\d{9,11}|\d{4}-\d{5,7}$', text2))
['17516375901', '0571-28559']
~
'''
内部约束:
找到前三个字母与后三个字母相同的字符串 如:barbar deadea
\1 表示与前面的组一样
\w 表示任意字符
有组--也就是正则有() 返回值 也是组的形式
'''
text3 = 'barvar, ssderder, dasdwaf, ketkets'
print(re.findall(r'(\w{3})(\1)', text3))
[('der', 'der'), ('ket', 'ket')]
~
'''
以251-2645468-235415151为例子
1、判断有几个子模式 :\d-\d-\d --- 三个
2、各子模式的字符是什么:\d
3、各自模式如何重复\d{3}.....
4、是否有外部限制 -- 位置限制
5、是否有内部制约 -- barbar
5、多种情况用 |
'''
text4 = 'assefb,asdas'
print(re.findall(r'a.+b', text4))
['assefb']
~
'''
重点:: 如果想找abc多次连续重复的需要(正则)(\d){需要重复的次数-1}
'''
text5 = 'dabcabcabc, asdclaclaclaaswfg'
print(re.findall(r'(\w{3})(\1){2}', text5))
[('abc', 'abc'), ('cla', 'cla')]
~
'''
单词边界取值
\b放在前面表示 单词的前边界 \b()
下面是提取数字
'''
text6 = '1wan, 2wan, 3wan'
print(re.findall(r'\b\d', text6))
['1', '2', '3']
~
'''
?<=密码表示密码一定要出现在 :123之前
'''
text7 = 'dsadasdasda,密码:123'
print(re.findall(r'(?<=密码.)\d+', text7))
['123']
~
'''
标记 flags=
'''
text8 = 'aba, Aba, ABA'
print(re.findall(r'abA', text8, flags=re.I)) #RE.I对大小写不铭感
m = re.finditer(r'abA', text8, flags=re.I)
for m in m:
print(m)
['aba', 'Aba', 'ABA']
~
'''
查找:
search - 只返回一个 - match
match - 只返回一个 从头匹配 - match
findall - 返回全部
finditer - 一次返回一个的 match迭代器对象
match对象想要读值 需要.group -- group还可以分别取组
替换:
sub
subn - 替换完后 返回几个字符被替换掉了
分割
split
'''
text8 = 'aba, Aba, ABA'
m = re.search(r'aba', text8, flags=re.I)
print(m, m.group())
<re.Match object; span=(0, 3), match='aba'>
<re.Match object; span=(5, 8), match='Aba'>
<re.Match object; span=(10, 13), match='ABA'>
<re.Match object; span=(0, 3), match='aba'> aba
~
text1 = '幸运数字:4564654546546,手机号:17516375901, 座机号码:0571-2855946'
m = re.search(r'(\d{4})-(\d{7})', text1)
print(m.group(1))
0571
~
#替换
result = re.replace(r'1', '***', text1, flags=re.I) #第二个参数是你要替换成什么
print(result)
幸运数字:4564654546546,手机号:***75***637590***, 座机号码:057***-2855946
~
result_subn = re.sub(r'1', '***', text1, flags=re.I)
print(result_subn)
幸运数字:4564654546546,手机号:***75***637590***, 座机号码:057***-2855946
~
#分割 -- 重点
'''
由于分隔符号不固定 所以需要利用正则表达式
split(r'表达分隔符的正则', 需要分割的文本)
\s空格[,;/]三个符号任选一个\s空格*0个或者多个
'''
text9 = 'fpp,bar ; baz'
print(re.split(r'\s*[,;/]\s*', text9))
['fpp', 'bar', 'baz']
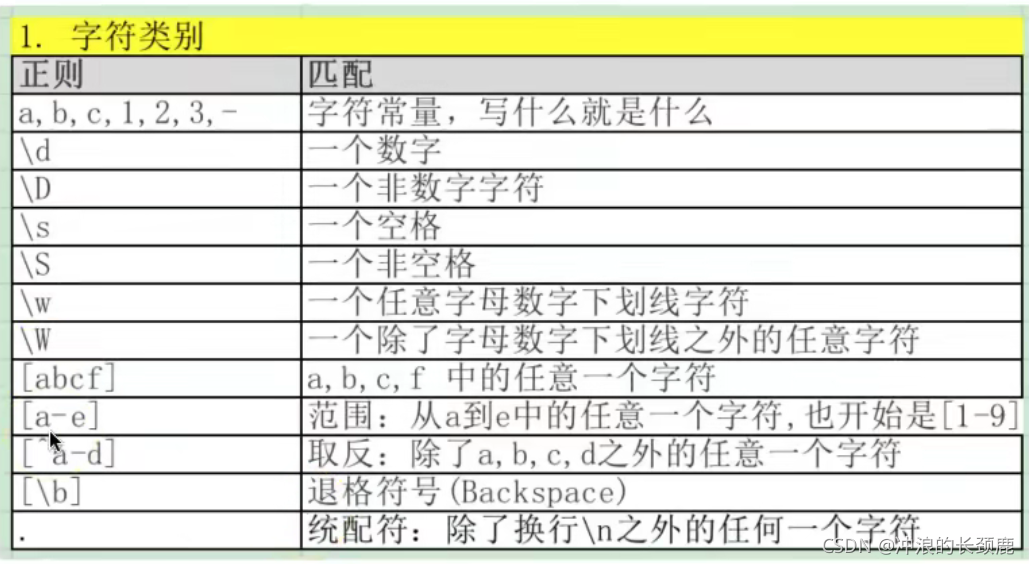
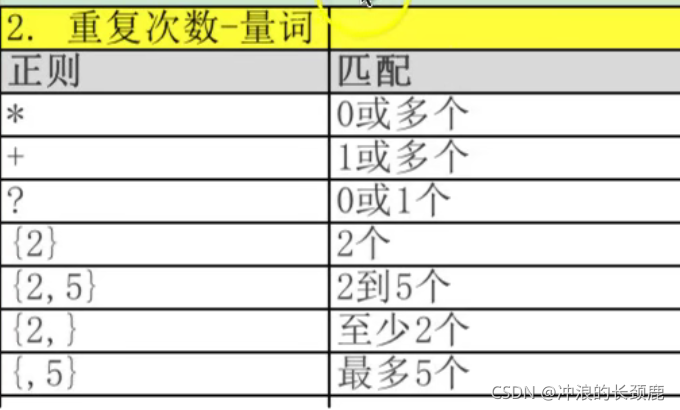
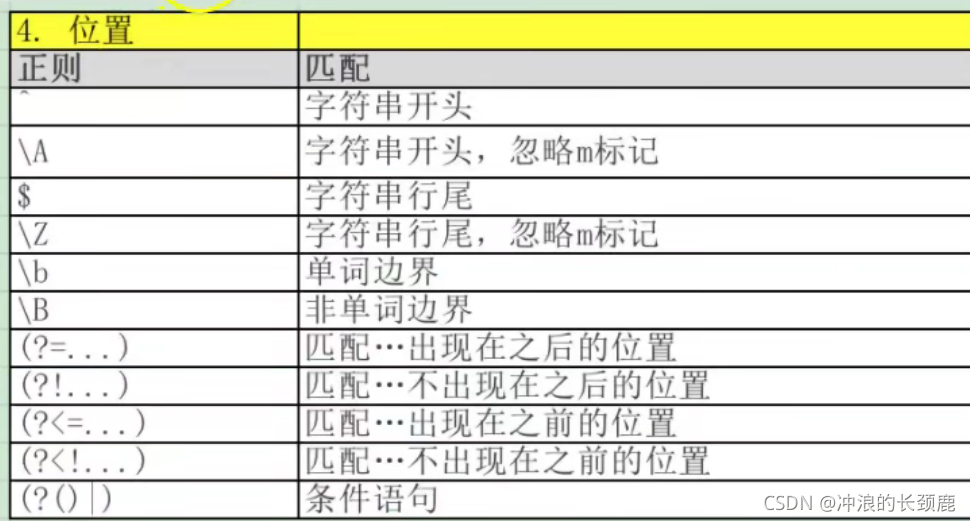
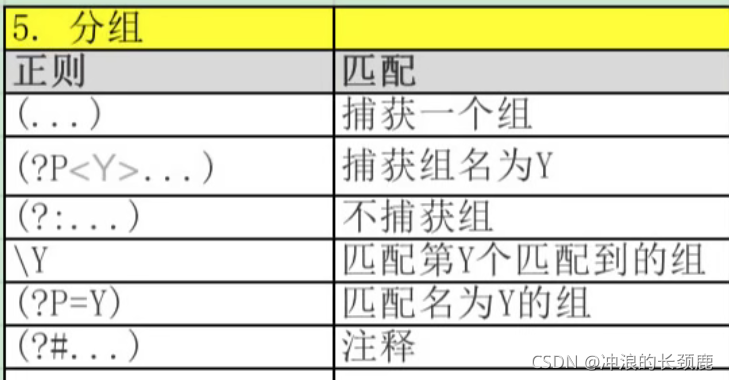
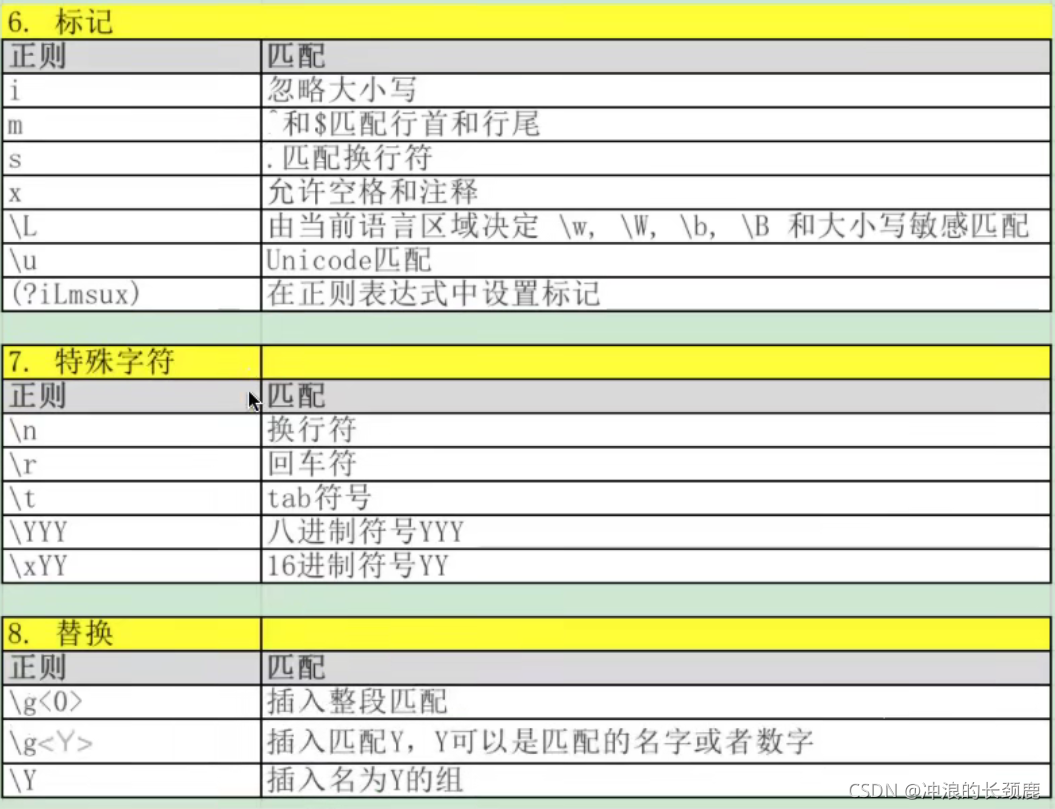
正则总览和例子:




















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









