







实验环境
Linux Ubuntu 16.04
前提条件:
1)Java 运行环境部署完成
2)Hadoop 的单点部署完成
实验内容
在上述前提条件下,学习HDFS IO序列化与反序列化的实验。
实验步骤
1.点击桌面的"命令行终端",打开新的命令行窗口
2.启动HDFS
启动HDFS,在命令行窗口输入下面的命令:
/apps/hadoop/sbin/start-dfs.sh运行后显示如下,根据日志显示,分别启动了NameNode、DataNode、Secondary NameNode:
dolphin@tools:~$ /apps/hadoop/sbin/start-dfs.sh
Starting namenodes on [localhost]
localhost: Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts.
Starting datanodes
Starting secondary namenodes [tools.hadoop.fs.init]
tools.hadoop.fs.init: Warning: Permanently added 'tools.hadoop.fs.init,172.22.0.2' (ECDSA) to the list of known hosts.3.查看HDFS相关进程
在命令行窗口输入下面的命令:
jps运行后显示如下,表明NameNode、DataNode、Secondary NameNode已经成功启动
dolphin@tools:~$ jps
484 DataNode
663 SecondaryNameNode
375 NameNode
861 Jps4.启动Eclipse
点击桌面的Eclipse图标,打开Eclipse
运行后,会弹出Workspace Launcher对话框,此时workspace我们默认就行,点击OK
5.创建项目
进入Eclipse后,会默认进入Welcome标签页,点击标签的叉号,退出Welcome标签。
点击左上角工具栏File,点击New下面的Java Project。
此时弹出了New Java Project对话框,我们填写Project Name为 Example,再点击Finish后,项目创建完成。
6.创建Java类
如下图所示,找到左上角Example项目下src目录后,右击,选择New,在点击Class。
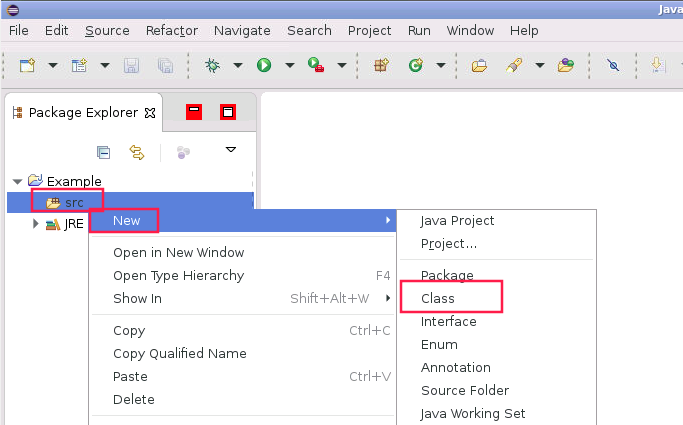
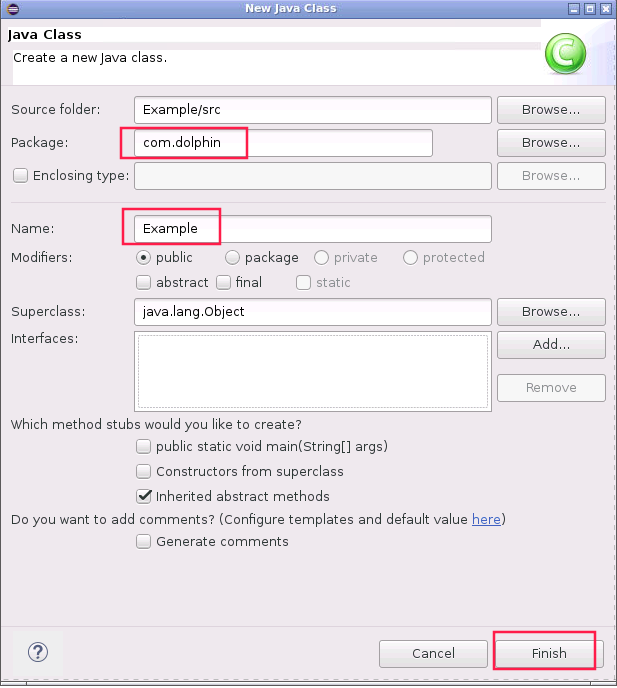
此时会弹出New Java Class对话框,如下图,填写Package为com.dolphin,填写Name为Example,再点击右下角Finish。此时Example类已经创建完成。
7.导入Hadoop Jar包
右击左上角Example项目,找到Build Path,点击下面的Configure Build Path…
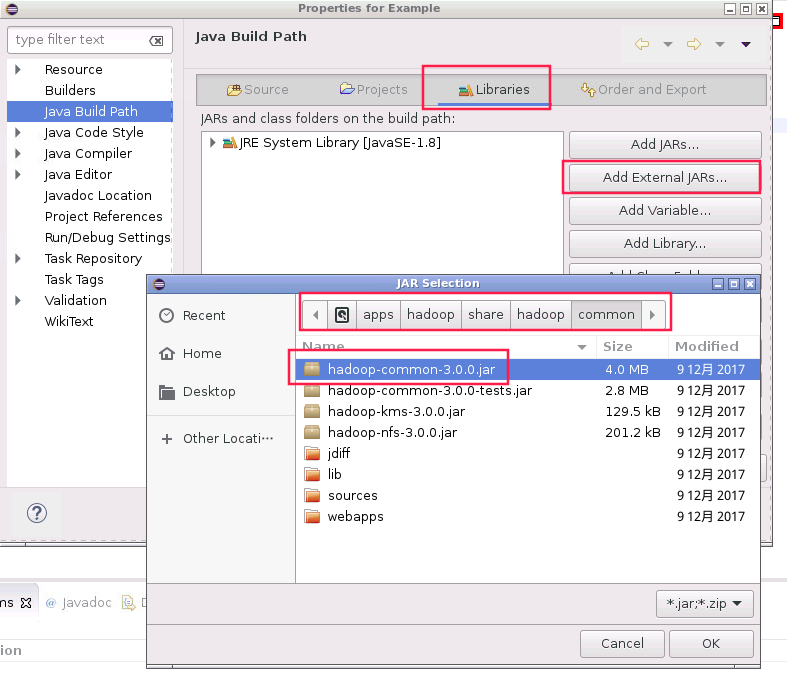
点击后会弹出Properties for Example对话框,如下图所示,点击Libraries后,再点击Add External JARs… 此时弹出JAR Selection对话框,找到根目录下/apps/hadoop/share/hadoop/common目录,选中hadoop-common-3.0.0.jar后,再点击OK
再次点击Add External JARs…,此时弹出JAR Selection对话框,找到根目录下/apps/hadoop/share/hadoop/common/lib目录,按住Ctrl + A,选中该目录下所有jar包后,点击OK。
再点击OK,此时Jar包已经导入完成。
8.编写代码
右击桌面的Example.txt文件,使用编辑器打开,按住Ctrl + A,再按住Ctrl + C复制全部内容后,回到Eclipse,编辑Example.java文件,按住Ctrl + A,再按住Ctrl + V,粘贴代码,再按住Ctrl + S保存文件。
9.运行代码
点击上方绿色的Run Example按钮,开始运行代码。运行后Eclipse控制台显示如下:
0
0
0
-93
[B@73a8dfcc
163
16310.运行内容
首先理解序列化与反序列化的概念:
序列化:将内存中的对象转换成字节序列用于存储或者网络传输。
反序列化:把从磁盘或者网络拿到的字节序列还原对象,提供给程序使用Hadoop为什么使用自己的序列化:Jdk本身提供了serializable接口实现序列化操作,但是它序列化的结果太笨重,不适用于在集群网络中有大量对象传输的场景。hadoop提供了Writable接口实现序列化。
代码中,是先对一个Int类型的变量进行序列化,打印序列化后的二进制数据。 再反序列化原来的数据,最后打印出来。
此外,用户可以自定义序列化自己的对象,只要让这个类继承Writable接口即可。
至此,本实验结束啦。开始下一个实验吧。















 1047
1047











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









