






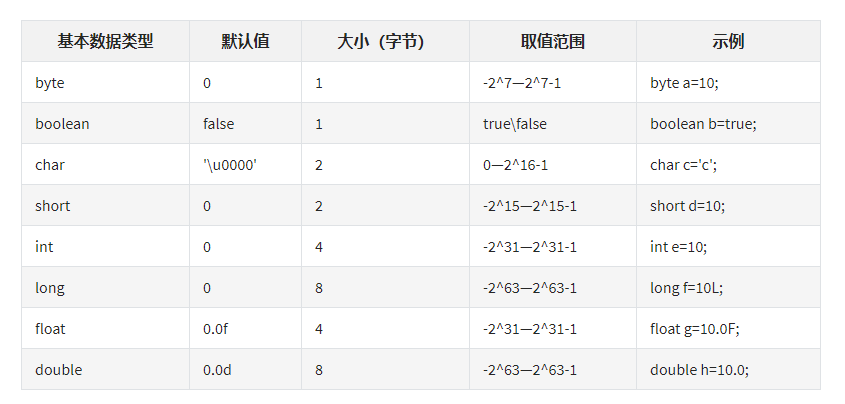
1、java的八种基本数据类型。基本类型与引用类型的区别?
-
基本数据类型:
byte、short、int、long、float、double、char、boolean -
引用类型:类(class)、接口(interface)、数组(array)
基本类型保存的是
值,引用类型保存的是对象的地址
所有基本类型赋值是按
值传递(拷贝赋值),引用类型赋值是按引用传递。
2、HashMap底层的数据类型与扩容原理?引
HaspMap 的基本数据结构
HashMap继承了Map抽象类,实现了Map,Cloneable,Serializable接口
- 1.7 数组 + 链表
- 1.8 数组 + (链表 | 红黑树)
- HashMap类中的元素是Node类,翻译过来就是节点,是定义在HashMap中的一个内部类
HashMap的扩展原理是HashMap用一个新的数组替换原来的数组。重新计算原数组的所有数据并插入一个新数组,然后指向新数组。如果阵列在容量扩展前已达到最大值,阈值将直接设置为最大整数返回。
在put方法中,扩容会进行一个拆树的操作
3、线程有哪些基本状态?各种状态之间如何转换?引
1.新建状态-就绪状态
调用线程的start方法,该线程进入可运行线程池中,获取到CPU之后就可以运行。
2.就绪状态-运行状态
获取到了CPU时间片。
3.运行状态-就绪状态
时间片用完了,或者调用了yield方法。
4.运行状态-阻塞状态
调用sleep,join,wait,或者I/O请求。
5.阻塞状态-运行状态
sleep,join,wait,I/O结束。
6.运行状态-死亡状态
线程执行结束,或者因为异常退出run方法。
4、什么是CAS?CAS有什么缺陷?如何解决?引
- CAS 是 compare and awap 的缩写,即我们所说的比较和交换。
- CAS 是一种基于锁的操作,而且是乐观锁。
ABA 问题
比如说一个线程 one 从内存位置 V 中取出 A ,这时另外一个线程 two 也从内存中取出 A ,并且 two 进行了一些操作变成了 B ,然后 two 又将 V 位置的数据变成 A,这时线程 one 进行 CAS 操作发现内存中仍然是 A,然后 one 操作成功,但是,A 已经不再是原来的 A ,可能存在一些潜在的问题。
从Java1.5 开始 JDK 的 atomic 包里提供一个类:AtomicStampedReference 来解决 ABA 问题。
循环时间长开销大
对于资源竞争严重(线程冲突严重)的情况,CAS 自旋的概率比较大,从而浪费更多的 CPU 资源,效率低于 synchronized。
只能保证一个共享变量的原子操作
当对一个共享变量执行操作时,我们可以使用循环 CAS 的发方式来保证原子操作,但是对于多个共享变量操作时,循环 CAS j就无法保证操作的原子性,这个时候就可以用锁。
5、什么是乐观锁与悲观锁?引
1)乐观锁
首先来看乐观锁,顾名思义,乐观锁就是持比较乐观态度的锁。就是在操作数据时非常乐观,认为别的线程不会同时修改数据,所以不会上锁,但是在更新的时候会判断在此期间别的线程有没有更新过这个数据。
2)悲观锁
反之,悲观锁就是持悲观态度的锁。就在操作数据时比较悲观,每次去拿数据的时候认为别的线程也会同时修改数据,所以每次在拿数据的时候都会上锁,这样别的线程想拿到这个数据就会阻塞直到它拿到锁。
6、JVM加载class文件的原理机制引
[双亲委派]
7、InnoDB和MyISAM有什么区别?引
1、innodb支持事务,而myisam不支持事务。
2、innodb支持外键,而myisam不支持外键。
3、innodb默认表锁,使用索引检索条件时是行锁,而myisam是表锁(每次更新增加删除都会锁住表)。
4、innodb和myisam的索引都是基于b+树,但他们具体实现不一样,innodb的b+树的叶子节点是存放数据的,myisam的b+树的叶子节点是存放指针的。
5、innodb是聚簇索引,必须要有主键,一定会基于主键查询,但是辅助索引就会查询两次,myisam是非聚簇索引,索引和数据是分离的,索引里保存的是数据地址的指针,主键索引和辅助索引是分开的。
6、innodb不存储表的行数,所以select count( * )的时候会全表查询,而myisam会存放表的行数,select count(*)的时候会查的很快。
总结:mysql默认使用innodb,如果要用事务和外键就使用innodb,如果这张表只用来查询,可以用myisam。如果更新删除增加频繁就使用innodb。
8、简述Redis的常用数据类型引
1.String数据类型
string 是 redis 最基本的数据类型,最大能存储 512MB,一个 key 对应一个 value,是二进制安全的,意思是 redis 的 string 可以包含任何数据(比如jpg图片或者序列化的对象)。
2.List 数据类型
redis 列表是简单的字符串列表,按照插入顺序排序。可以添加一个元素到列表的头部(左边)或者尾部(右边).
3.Hash数据类型(散列类型)
redis中的散列可以看成具有String key和String value的map容器,可以将多个key-value存储到一个key中。每一个Hash可以存储 2的32次方 -1个键值对。
4.set数据类型(无序集合)
redis 的 Set 是 string 类型的无序集合。
集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。
5.Sorted Set数据类型 (zset、有序集合)。
redis zset 和 set 一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。zset的成员是唯一的,但分数(score)却可以重复
9、RabbitMQ的常用工作模式引
1、简单队列:
一个生产者对应一个消费者!!
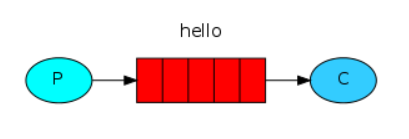
2、work 模式
一个生产者对应多个消费者,但是一条消息只能有一个消费者获得消息!!!
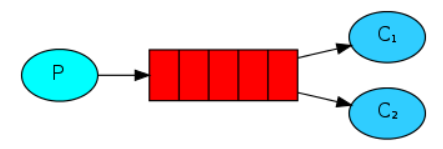
3、发布/订阅模式
一个消费者将消息首先发送到交换器,交换器绑定到多个队列,然后被监听该队列的消费者所接收并消费。
如果没有队列绑定交换机,则消息将丢失。因为交换机没有存储能力,消息只能存储在队列中
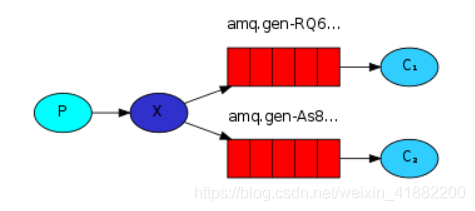
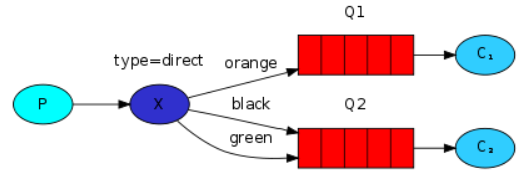
4、路由模式
生产者将消息发送到direct交换器,在绑定队列和交换器的时候有一个路由key,生产者发送的消息会指定一个路由key,那么消息只会发送到相应key相同的队列,接着监听该队列的消费者消费消息。
路由模式,是以路由规则为导向,引导消息存入符合规则的队列中。再由队列的消费者进行消费的。
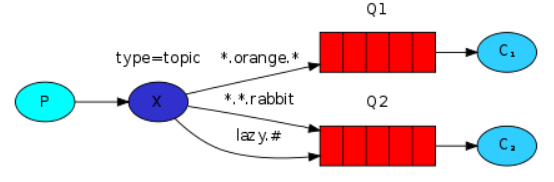
5、主题模式
符号“#”表示匹配一个或多个词,符号“*”表示匹配一个词.与路由模式相似,但是,主题模式是一种模糊的匹配方式。
工作模式总结
这五种工作模式,可以归为三类:
生产者,消息队列,一个消费者;
生产者,消息队列,多个消费者;
生产者,交换机,多个消息队列,多个消费者;
四种交换器
1、direct 如果路由键完全匹配的话,消息才会被投放到相应的队列。
2、fanout 当发送一条消息到fanout交换器上时,它会把消息投放到所有附加在此交换器上的队列。
3、topic 设置模糊的绑定方式,“*”操作符将“.”视为分隔符,匹配单个字符;“#”操作符没有分块的概念,它将任意“.”均视为关键字的匹配部分,能够匹配多个字符。
4、headers 交换器允许匹配 AMQP 消息的 header 而非路由键,除此之外,header 交换器和 direct 交换器完全一致,但是性能却差很多,因此基本上不会用到该交换器
10、RabbitMQ如何保证消息不丢失?引
1.消息持久化
2.ACK确认机制
3.设置集群镜像模式
4.消息补偿机制















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









