






学习目标
-
什么是微服务架构?
-
服务应该如何拆分?
-
微服务架构带来了哪些问题?以及如何去解决这些问题。
典型架构图

微服务架构知识内容:
-
应用由多个服务构成。
-
服务独享自身数据。
-
服务会共享配置,使用配置中心来支持。
-
服务还会共享中间件,主要缓存、消息队列、搜索、日志等。
-
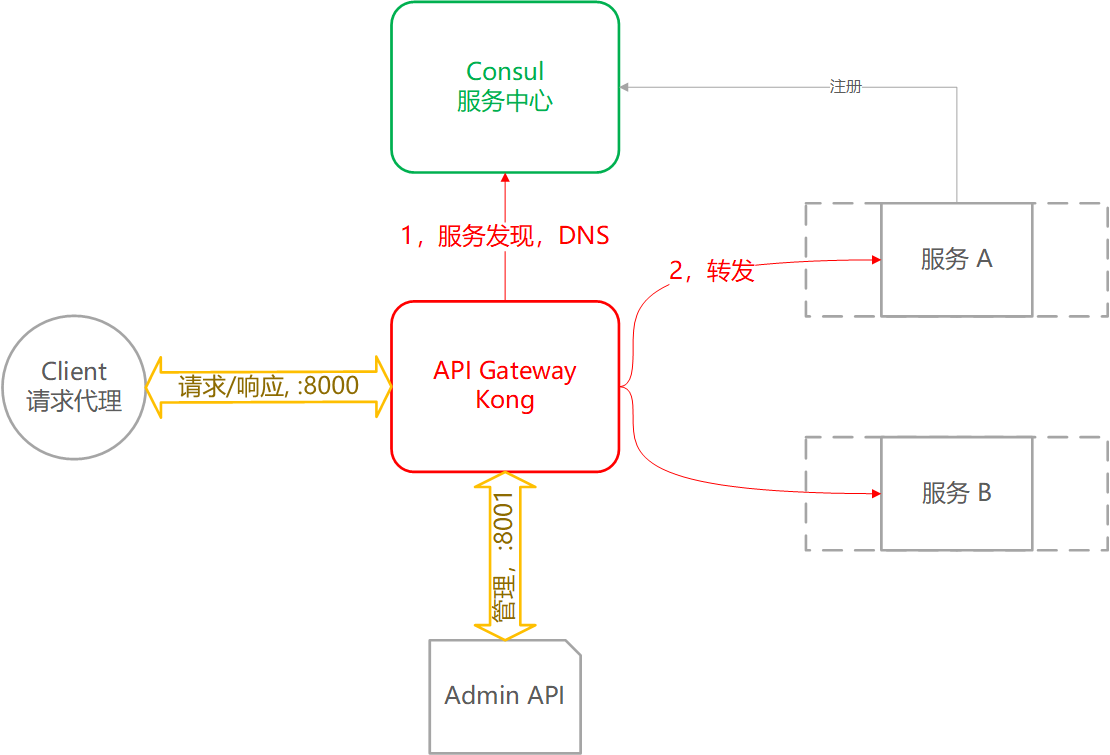
服务间需要通信,第一步需要找到目标服务。需要服务注册中心,提供服务注册和发现。
-
服务需要通信,规范通信协议,典型的协议:gRPC,RestFul API,HTTP、MQ。
-
应用要响应外部的请求,并将请求转发给目标服务。需要API网关技术。
-
服务请求需要被控制的管理,使用负载均衡、限流、熔断、降级等控制。
-
服务间数据一致性的问题,通常需要分布式事务、分布式锁、分布式 Session。
-
服务需要被监控、需要链路追踪、监控平台、日志分析。
课程依赖
-
Go 核心语法,我们需要用 go 编写测试用例。
-
Linux 基础操作,需要的程序软件大都安装在 linux 上。
-
Web 相关编程技术,需要使用 http 请求响应相关操作。
什么是微服务架构?
巨石架构
早期,大部分的应用程序是将全部的功能模块作为一个整体进行打包、发布、运行。这样程序会越来越大,像一块大石头一样,因此称为巨石架构(the monolithic architecture)。例如,一个商城系统可能包含:分类、商品、购物车、订单、支付、物流、评价、售后、会员、推广、商户等功能模块。那么程序的架构就是:
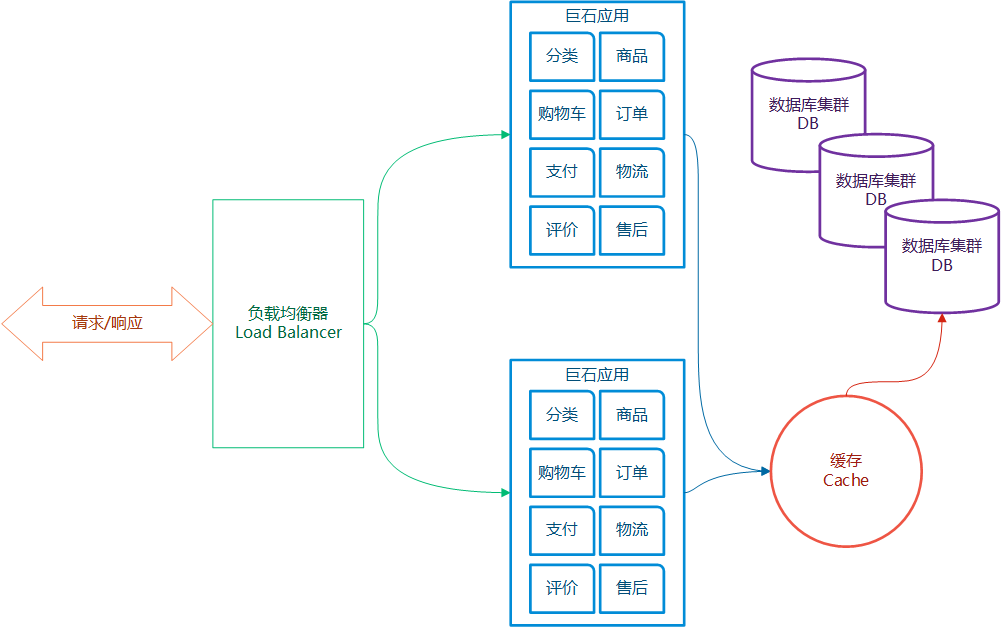
巨石应用的劣势:
-
更新局部,需要重新部署整体
-
整体发布时间过长,包括编译、发布等
-
回归测试周期过长
-
不利于新技术应用,否则需要重构整体应用
巨石应用也有自己的优势,例如部署容易,整体打包,整体部署即可;IDE 友好,测试容易、监控方便。
微服务架构
微服务架构(MicroServices Architecture Pattern)的目的是将大型的、复杂的、长期运行的应用程序(巨石应用)构建为一组相互配合的服务,每个服务都可以很容易得局部改良。Micro 意味着服务应该足够小,服务的大小应该从业务逻辑上衡量,而不是用代码量。符合 SRP (单一职责原则)的才叫微服务。
微服务是去中心化的分布式软件架构。微服务通常是无状态服务。
微服务架构的优势:
-
服务可以使用不同技术栈研发
-
每个微服务都可以独立优化,部署或扩展
-
更好的故障处理和错误检测
-
服务复用性强
-
服务扩展性强
单体应用拆解成大量的微服务,带来的新问题是服务间通信和一致性等问题,通常需要通过服务注册发现、服务网格、分布式锁、分布式事务来解决。
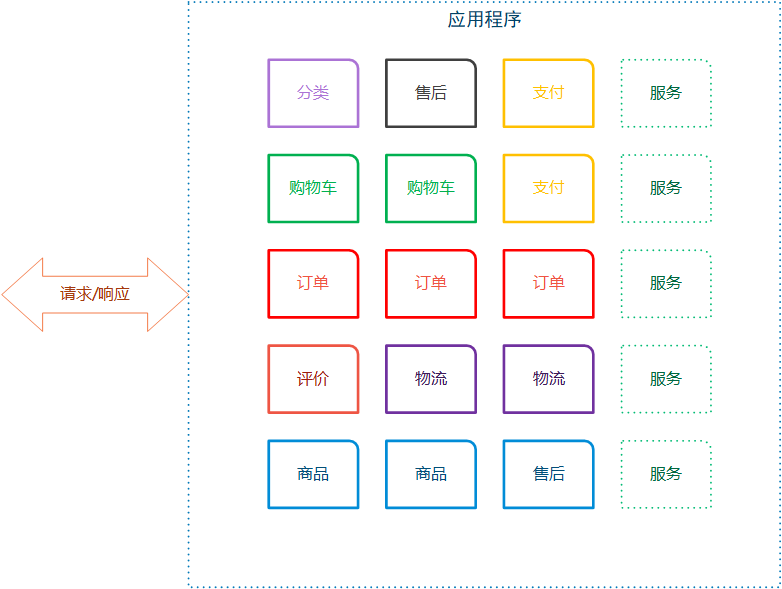
上面的应用,拆分之后:
SOA 与 微服务
SOA(Service-Oriented Architecture,面向服务的架构)是一种在计算机环境中设计、开发、部署和管理离散模型的方法。在 SOA 模型中,所有的功能都被定义成了独立的服务,所有的服务通过企业服务总线(ESB, Enterprise Service Bus)或流程管理器来连接。
带有 ESB 的架构典型如下:
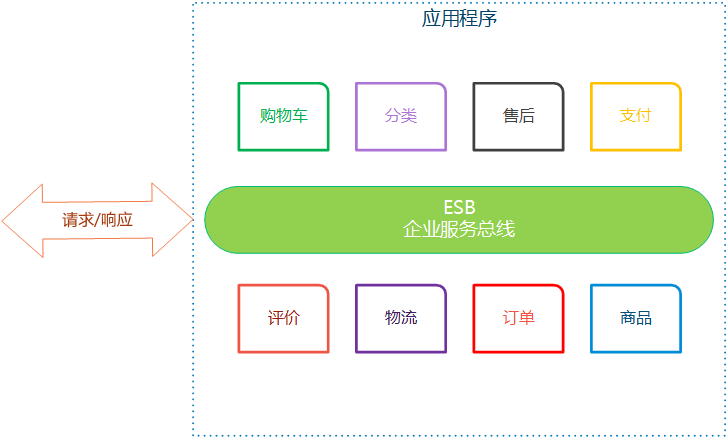
微服务架构与 SOA 架构最重要的区别是:
-
微服务架构是去中心化的分布式架构
-
SOA 是中心化的分布式架构。
云原生中的微服务
微服务是云原生技术的核心部分,在微服务架构上运行的现代云原生应用程序依赖于以下关键组件:
-
容器化,通过将服务分成多个进程来进行有效的管理和部署,例如 Docker 类平台。
-
编排,用于配置、分配和管理服务的可用系统资源,例如 Kubernetes 类平台。
-
服务网格,通过服务代理网格进行服务间通信,连接,管理和保护微服务,例如 Istio 类平台。
以上三个是微服务架构在云原生中最重要的组件,这些组件允许云原生中的应用程序在负载下扩展,甚至在故障期间也能执行。
拆分原则
微服务是化整为零、分而治之的思想。
拆分原则一览:
业务拆分:
业务逻辑拆分,单一职责,服务自身可治理数据库。
独立功能用例拆分,独立的二方或三方用例,通常拆分为独立服务。例如二方的账号服务和三方的支付服务。
技术拆分:
服务的并发性,考虑持续并发、瞬时并发,拆分服务独立。
服务处理的数据,考虑数据量、读写操作的数据、冷热数据量、边长定长数据类型,将服务拆分。
服务的安全等级,考虑服务业务、数据的安全等级、采用不同的安全策略,来进行拆分。
服务需要的资源,考虑服务需要计算、I/O、网络、存储等资源、来进行拆分。
服务扩展性,考虑服务中技术、业务等的更新率、扩展率,进行拆分。
架构的稳定性,考虑单体服务的技术架构稳定性。
便于测试,测试可集成、可回溯。
便于监控,便于日志分析、指标监控等。
项目拆分:
团队(开发、测试、运维)小而美。小指的是规模,团队通常 10 人左右;美指的是团队可自治,与其他团队人员协调尽量少。
成本因素,考虑技术(学习)成本、人力成本、时间成本、设施成本,来拆分服务。
AKF 扩展立方体
立方体图:
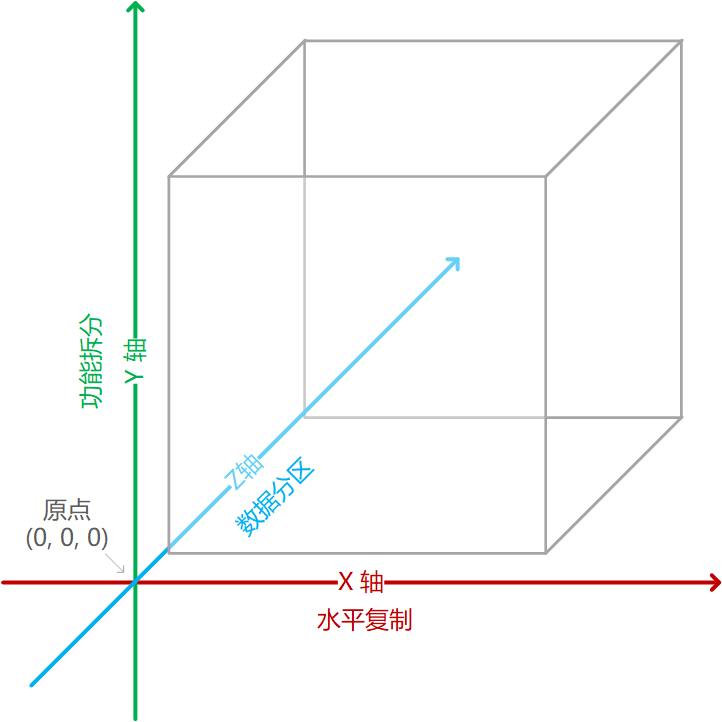
X 轴,克隆扩展(水平复制)
X轴,代表无差别服务和数据的克隆,也称水平扩展。它指的是,相同的服务部署多个,通过负载均衡器在多个应用间做选择。
图例:
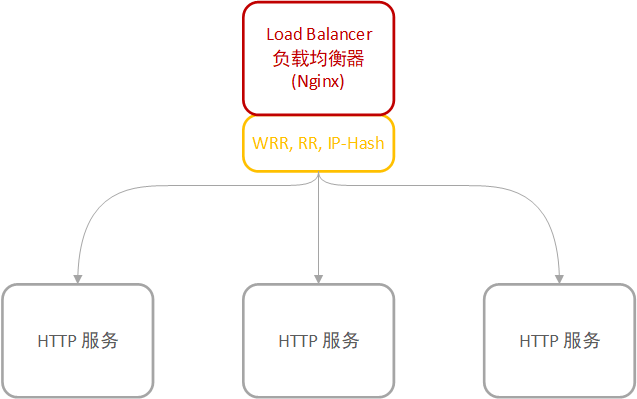
Y 轴,功能拆分扩展
Y轴,代表依据资源、服务或功能进行拆分。指的是把任何特定功能的操作以及操作所需的数据资源从整体(或其他操作)中分离出来。X 轴体现的是相同功能的复制,而 Y 轴体现的是多个不同功能的组合。
如图:用户购买商品,需要浏览商品信息、购买、订单管理、支付等操作,依据功能将应用拆分为:
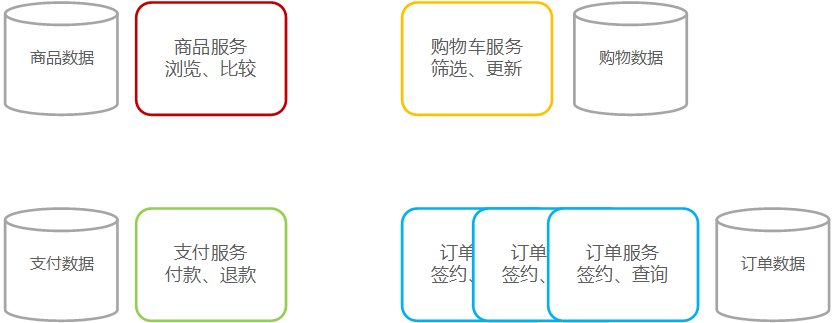
这种拆分,就是典型微服务架构中业务逻辑的拆分方案,每个服务负责具体的某个特定功能,整体应用由多个服务组成。
同样,若某个服务需要更多的资源,也可以采用 X 轴扩展模式,例如上图中的订单服务。
Z 轴,数据拆分扩展
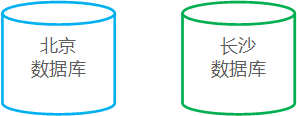
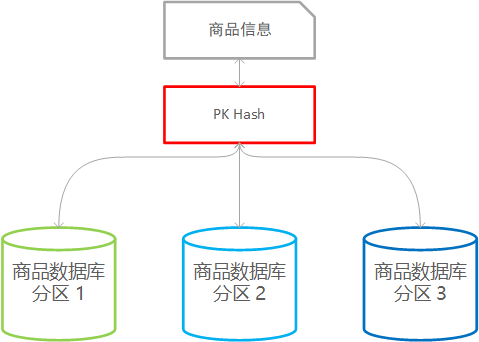
当业务基于 X、Y 做了克隆或拆分后,数据存储的压力需要通过 Z 轴扩展解决。Z 轴扩展通常指的是数据库拆分。数据库拆分如依据地域划分、依据不同功能的表划分或将表中的记录依据主键hash(或其他分区算法)划分等。
地域:
基于功能:

记录划分:
原点
坐标原点 (0, 0, 0) 表示应用系统的最小扩展性。
SRP 单一职责原则
单一职责原则,应该表达最朴素的一个原则了,顾名思义,就是一个服务负责单独的一个职责,就意味着我们的设计满足单一职责。
SRP,Single Responsibility Principle,单一职责原则来自于面向对象设计的基本原则,是这么说的:
There should never be more than one reason for a class to change.
映射到我们微服务其实就是:对于服务而言,应该只有一个理由引起它的变化。
也就是,一个服务的功能要单一,只做与之相关的事情,在服务的设计过程中要按照职责进行设计。如果需要更多功能呢,那么就需要更多的服务,服务彼此互不干涉。
单一职责原则在使用时,要注意粒度,也就是我们应该将单体服务的规模设计多大。如果粒度过细,会导致在开发、测试、部署上都会带来额外的负担。同样若粒度过粗,那么特定功能的更新,直接会导致整体服务更新。因此,我们在拆分服务时,除了要考虑功能性,还要考虑和预测需求的变化点、变化率,以及数据增长点、并发热点等,相互结合,设计出相对平衡的独立服务。
例如,对于商品服务,商品的品牌、标签、属性、库存等,是否需要独立设计为一个服务呢?这个需要基于我们自身的业务逻辑进行设计。这个例子中,库存通常需要独立服务设计的,因为库存在订单生成和仓库管理时,会被高频率使用。而其他功能,通常隶属于商品服务的范畴。
SRP 原则通常也会被表述为服务设计的高内聚低耦合。内聚度是从功能角度来度量模块内的联系,一个好的内聚模块应当恰好只做一件事,高内聚就是一个类封装的很完善,每个类只完成一项任务,也就是常说的单一责任原则。 耦合度是对模块间关联程度的度量,模块间的耦合度是指模块之间的依赖关系,包括控制关系、调用关系、数据传递关系,模块间联系越多,耦合性越强,模块的独立性越差。
DDD 领域驱动设计
服务发现
什么是服务发现?
服务发现,Service Discovery 指的是若服务 A 需要与 服务 B 进行通信,那么如何知道服务 B 的地址?服务发现的作用,就是通过服务注册中心,来告知服务A,服务B 的地址在哪里。这里说的地址,通常就是 IP:Port/path 的形式。
基于这段描述,服务发现机制由三个角色构成:
-
服务的消费者,也就是服务A,其他服务的使用者。Consumer
-
服务的提供者,也就是服务B,为其他角色提供服务。Provider
-
服务注册中心,也称服务中介,存储已经注册的服务信息(地址),提供查找功能。
其思想也很清晰:若服务B需要为其他角色提供服务,那么服务B要将自身的信息(地址)注册到服务注册中心,这样其他服务(A),就可以在注册中心找到目标服务(B)。
如图所示:
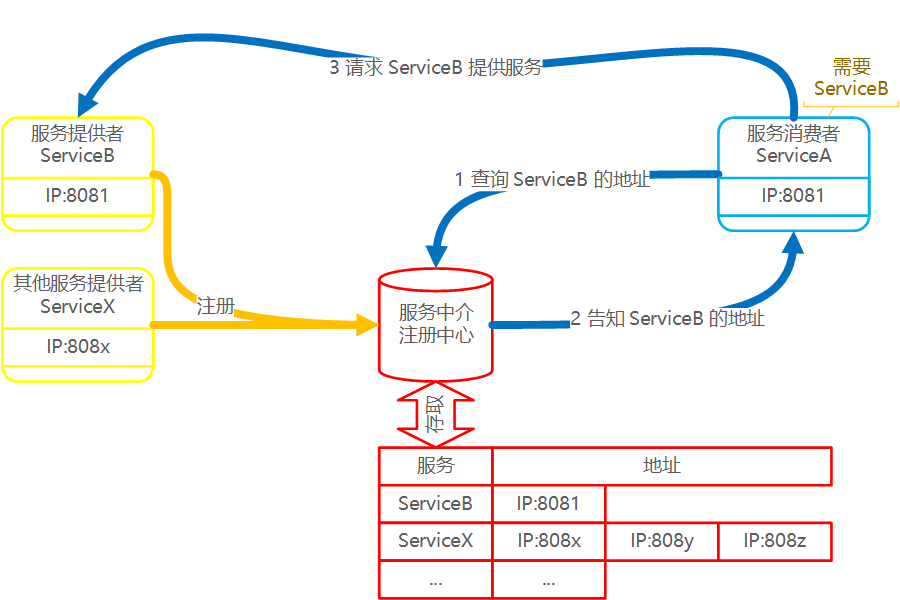
注册中心的核心是存储系统,通常就是 Key/Value 结构的存储系统,存储服务标识与服务地址(或更详细的信息的映射。实操时,同一个服务可能存在多个提供者,那么一个服务标识,就会对应一个地址(或信息)列表,此时通常需要负载均衡算法来选择。
服务注册:将某个服务的信息存储到服务注册中心,是 SET 操作。服务提供者需要完成。
服务发现:从注册中心获取某个服务的信息,是 GET 操作。服务的消费者需要完成。
本例中,ServiceB 作为服务提供者,需要完成服务注册操作。之后 ServiceA 需要 Service B 的功能,需要三步走:
-
查询 ServiceB 的信息
-
注册中心告知 ServiceA:ServiceB 的信息
-
ServiceA 请求 ServiceB 的服务。
以上就是服务发现的介绍。可见,只要支持 Key/Value 存储机制的产品,都可以作为服务中心来使用,来提供服务注册和发现功能。
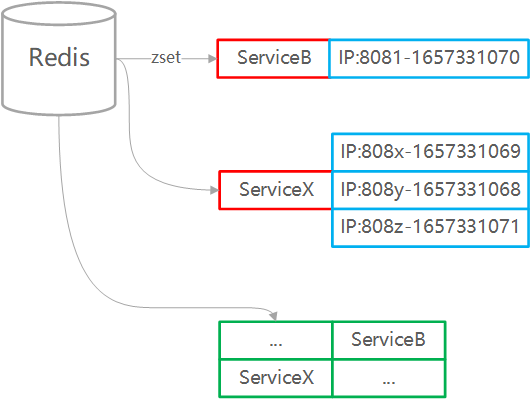
早期,我就使用过 Redis 来实现服务注册中心。
-
多个 zset 项存储服务信息
-
zset 的 key 为服务标识 ,zset 的成员为服务地址作,成员的 score 存储服务心跳时间戳,用于对服务做健康检测。
-
服务注册基于 ZADD 命令实现
-
服务发现基于 ZRANDMEMBER 命令实现
-
服务移除基于 ZREM 命令实现
-
还会使用一个集合记录全部的服务标识,可以是 List 或 Set。
如图所示:
除了存储之外,还要提供客户端供程序使用。客户端需要提供服务心跳、服务更新通知、负载均衡等功能。这里就不再深入了,大家如果对这个例子感兴趣,可以移步 https://github.com/han-joker/DiscoveryOnRedis.git。
现在有完善的注册中心产品,例如 Consul,Etcd,ZooKeeper 等,不需要我们自己来实现了。
微服务需要什么样的服务发现?
微服务系统需要一个分布式的服务注册中心来实现服务发现。分布式的注册中心可以保证不会出现单点失效的严重问题。
由于微服务架构的服务数量会很多,因此服务的健康检查就很重要,可以及时将无效服务从注册中心剔除。
最好有一个服务管理工具,便于我们观察集群、服务状态等。
基于以上原因,我们会从 Consul,Etcd,ZooKeeper 中做选择,因为以上三个,都是基于分布式存储系统构建的服务发现器。
Consul 作为服务发现
Consul 简介
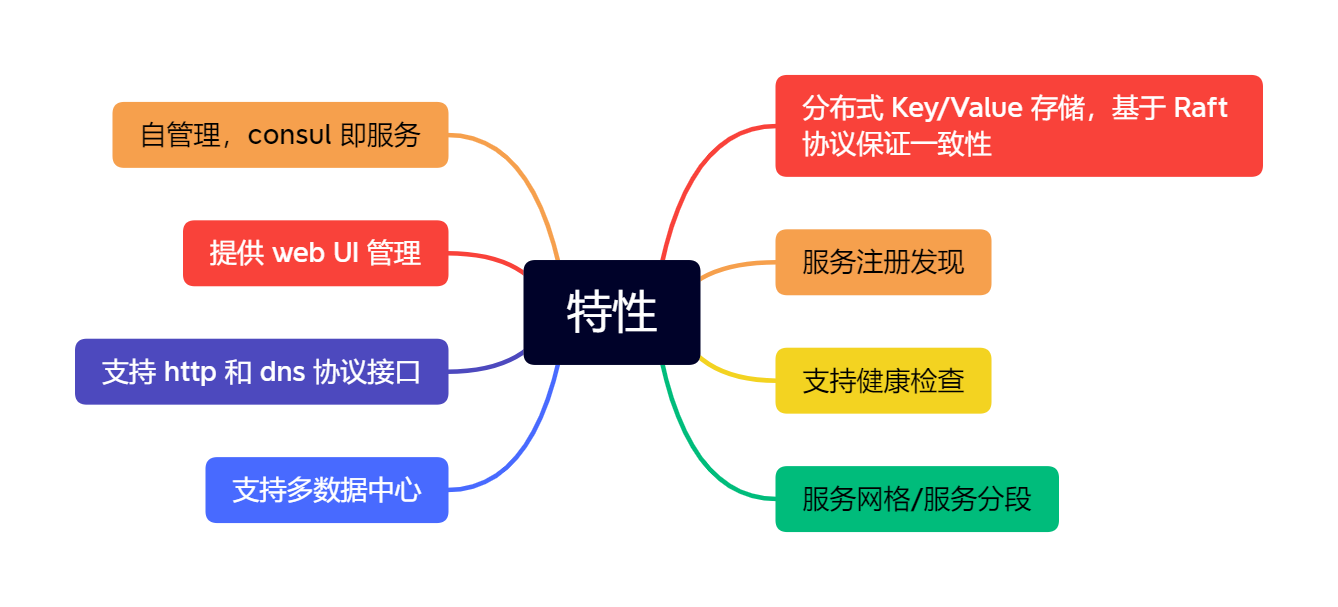
Consul 是一个 HashiCorp 公司开源的网络工具,承诺永久免费,可提供功能齐全的服务网格和服务发现支持。
特性如下:
附件:HashiCorp
世界级开源公司 HashiCorp,估值52亿美元(2021年)。
HashiCorp 是由 Mitchell Hashimoto (米切尔 桥本)和 Armon Dadgar (阿蒙达加)联合创办,总部位于美国旧金山,致力于为企业提供服务,通过数据中心管理技术研发,让开发者通过工具构建完整的开发环境,提高开发效率。2012年11月,HashiCorp 成立。
除了早期开源项目是使用python、ruby等动态语言开发的,HashiCorp公司的后期主流产品均基于Go语言开发。
2021年7月22日,Mitchell 正式宣布卸任 CTO 职位,离开公司高管团队,成为一名全职个人贡献者。“一切因为热爱”,“你以为的创业是每天为自己的热情奋斗,可现实是,你每天需要激励别人为你的热情而奋斗。”
知名产品:
-
Vagrant,一个基于Ruby 的工具,用于创建和部署虚拟化开发环境。它 使用Oracle的开源VirtualBox虚拟化系统,使用 Chef创建自动化虚拟环境。
-
Terraform,Terraform 是一种声明式编码工具,可以让开发人员用 HCL(HashiCorp 配置语言)高级配置语言来描述用于运行应用程序的“最终状态”云或本地基础架构。
-
Vault, 一种用于在现代应用程序体系结构中安全地管理机密信息的流行工具。
-
Consul,是一个网络工具,可提供功能齐全的服务网格和服务发现。
-
Nomad,是一个管理机器集群并在集群上运行应用程序的工具。

安装
Consul 下载页
Install | Consul | HashiCorp Developer
CentOS/RHEL yum
-
安装 yum 工具包
-
配置yum增加consul(hashicorp)镜像源
-
安装consul
sudo yum install -y yum-utils sudo yum-config-manager --add-repo https://rpm.releases.hashicorp.com/RHEL/hashicorp.repo sudo yum -y install consul
测试安装结果
$ consul
Usage: consul [--version] [--help] <command> [<args>]
Available commands are:
acl Interact with Consul's ACLs
agent Runs a Consul agent
catalog Interact with the catalog
config Interact with Consul's Centralized Configurations
connect Interact with Consul Connect
debug Records a debugging archive for operators
event Fire a new event
exec Executes a command on Consul nodes
force-leave Forces a member of the cluster to enter the "left" state
info Provides debugging information for operators.
intention Interact with Connect service intentions
join Tell Consul agent to join cluster
keygen Generates a new encryption key
keyring Manages gossip layer encryption keys
kv Interact with the key-value store
leave Gracefully leaves the Consul cluster and shuts down
lock Execute a command holding a lock
login Login to Consul using an auth method
logout Destroy a Consul token created with login
maint Controls node or service maintenance mode
members Lists the members of a Consul cluster
monitor Stream logs from a Consul agent
operator Provides cluster-level tools for Consul operators
reload Triggers the agent to reload configuration files
rtt Estimates network round trip time between nodes
services Interact with services
snapshot Saves, restores and inspects snapshots of Consul server state
tls Builtin helpers for creating CAs and certificates
validate Validate config files/directories
version Prints the Consul version
watch Watch for changes in Consul
Ubuntu/Debian apt
wget -O- https://apt.releases.hashicorp.com/gpg | gpg --dearmor | sudo tee /usr/share/keyrings/hashicorp-archive-keyring.gpg echo "deb [signed-by=/usr/share/keyrings/hashicorp-archive-keyring.gpg] https://apt.releases.hashicorp.com $(lsb_release -cs) main" | sudo tee /etc/apt/sources.list.d/hashicorp.list sudo apt update && sudo apt install consul
Federa dnf
sudo dnf install -y dnf-plugins-core sudo dnf config-manager --add-repo https://rpm.releases.hashicorp.com/fedora/hashicorp.repo sudo dnf -y install consul
Amazon Linux yum
sudo yum install -y yum-utils sudo yum-config-manager --add-repo https://rpm.releases.hashicorp.com/AmazonLinux/hashicorp.repo sudo yum -y install consul
Homebrew
brew tap hashicorp/tap brew install hashicorp/tap/consul
Linux 二进制
选择合适的版本下载:
https://releases.hashicorp.com/consul/1.12.2/consul_1.12.2_linux_386.zip
https://releases.hashicorp.com/consul/1.12.2/consul_1.12.2_linux_amd64.zip
https://releases.hashicorp.com/consul/1.12.2/consul_1.12.2_linux_arm.zip
https://releases.hashicorp.com/consul/1.12.2/consul_1.12.2_linux_arm64.zip
Linux 源码
https://github.com/hashicorp/consul
git clone https://github.com/hashicorp/consul cd consul make tool make linux
macOS
brew
brew tap hashicorp/tap brew install hashicorp/tap/consul
二进制
选择合适的版本:
https://releases.hashicorp.com/consul/1.12.2/consul_1.12.2_darwin_amd64.zip
https://releases.hashicorp.com/consul/1.12.2/consul_1.12.2_darwin_arm64.zip
FreeBSD
选择合适的二进制版本:
https://releases.hashicorp.com/consul/1.12.2/consul_1.12.2_freebsd_386.zip
https://releases.hashicorp.com/consul/1.12.2/consul_1.12.2_freebsd_amd64.zip
Solaris
选择合适的二进制版本:
https://releases.hashicorp.com/consul/1.12.2/consul_1.12.2_solaris_amd64.zip
Windows
选择32或64位下载:
https://releases.hashicorp.com/consul/1.12.2/consul_1.12.2_windows_386.zip
https://releases.hashicorp.com/consul/1.12.2/consul_1.12.2_windows_amd64.zip
下载后,解压即可。内包含直接可运行的执行程序:
consul_1.12.2_windows_amd64> dir Mode LastWriteTime Length Name ---- ------------- ------ ---- ------ 6/3/2022 7:53 PM 118531040 consul.exe
测试运行:
consul_1.12.2_windows_amd64> .\consul.exe
Usage: consul [--version] [--help] <command> [<args>]
Available commands are:
acl Interact with Consul's ACLs
agent Runs a Consul agent
catalog Interact with the catalog
config Interact with Consul's Centralized Configurations
connect Interact with Consul Connect
debug Records a debugging archive for operators
event Fire a new event
exec Executes a command on Consul nodes
force-leave Forces a member of the cluster to enter the "left" state
info Provides debugging information for operators.
intention Interact with Connect service intentions
join Tell Consul agent to join cluster
keygen Generates a new encryption key
keyring Manages gossip layer encryption keys
kv Interact with the key-value store
leave Gracefully leaves the Consul cluster and shuts down
lock Execute a command holding a lock
login Login to Consul using an auth method
logout Destroy a Consul token created with login
maint Controls node or service maintenance mode
members Lists the members of a Consul cluster
monitor Stream logs from a Consul agent
operator Provides cluster-level tools for Consul operators
reload Triggers the agent to reload configuration files
rtt Estimates network round trip time between nodes
services Interact with services
snapshot Saves, restores and inspects snapshots of Consul server state
tls Builtin helpers for creating CAs and certificates
validate Validate config files/directories
version Prints the Consul version
watch Watch for changes in Consul
Docker 镜像 (课堂)
docker 拉取 consul 镜像
sudo docker pull consul
$ sudo docker pull consul Using default tag: latest latest: Pulling from library/consul df9b9388f04a: Pull complete 7aa48d4bd8bb: Pull complete fa3ef9b012a5: Pull complete d239fc798a4c: Pull complete 199124be58be: Pull complete 5c3ccfe93b8b: Pull complete Digest: sha256:ee0735e34f80030c46002f71bc594f25e3f586202da8784b43b4050993ef2445 Status: Downloaded newer image for consul:latest docker.io/library/consul:latest
本课程中的示例全部采用 Docker 的方式管理,需要大家准备好 docker 环境。若需要和讲师的环境一致,请参考“CentOS 7.x 在 vmware 虚拟机中的安装“ 和 ”Docker 在 CentOS 7.x 上的安装” 和“Putty 的安装"的附件章节(在笔记最后)。
运行
示例:开发模式
sudo docker run --rm -it -p 8500:8500 --name=ConsulDevServer consul agent -dev -client=0.0.0.0
访问 UI :
http://<IP>:8500/ui
Consul 的基本架构
整体架构
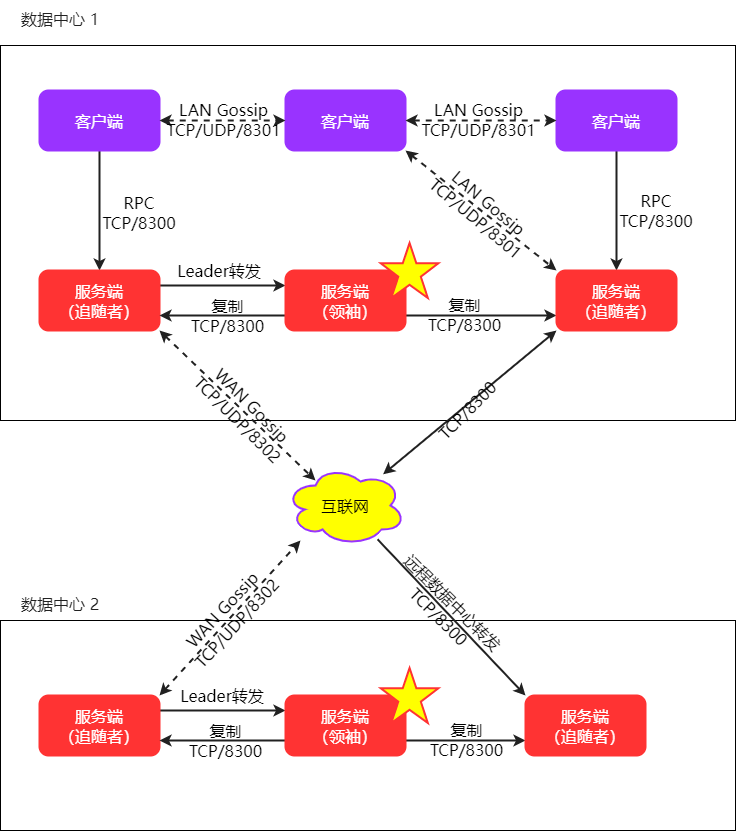
架构图翻译自:Consul Architecture | Consul | HashiCorp Developer
下面对 consul 架构做一个介绍:
-
Consul 节点,Consul agent 命令启动一个 consul 分布式节点。consul agent 是 consul 的核心管理进程。服务负责完成维护成员信息、注册服务、运行检查、响应查询等工作。agent 分为客户端 client 和服务端 server 两种模式的节点。其中:
-
服务端节点,consul 分布式集群的核心节点,数据存储在 Server 上,功能全部由 Server 对外提供。Server 节点还需要负责分布式架构中一致性的实现。规模应该适中,建议奇数个,3,5,7 台,规模的增大,会导致共识一致性的效率降低,这个规模通常会在可用性和性能之间取得了平衡。
-
客户端节点,consul 分布式集群的代理节点,负责将操作转发到 Server 节点上,本身不提供核心功能。客户端节点是构成集群大部分的轻量级进程,它们与服务器节点交互以进行大多数操作,并保持非常少的自身状态。客户端的主要目的与大量的外部请求进行交互,避免外部请求直接请求少量的Server,降低 Server 节点的 I/O 压力。规模任意,建议在任何的服务上都部署客户端节点,这样服务可以直接访问客户端节点完成服务发现。
-
-
全部节点间采用 Gossip 协议(八卦协议)进行消息扩散。该协议主要负责下面几个功能:
-
客户端自动发现服务端
-
健康检查是分布式检查,不仅仅依赖于服务节点检查。
-
事件的高效传递,例如服务端选举产生了新 Leader,可以快速通知到全部的节点上
-
LAN Gossip 负责局域网内的消息传递
-
WAN Gossip 负责外网间的消息传递,也就是多个数据中心间的消息传递
-
-
服务节点基于 Raft 协议完成一致性,Raft 协议通过 Leader 选举和日志复制方案,快速达到一致性
-
Consul 支持多数据中心的部署
端口说明
-
8300:集群内数据的读写和复制
-
8301:单个数据中心 gossip 协议通讯
-
8302:跨数据中心 gossip 协议通讯
-
8500:提供 HTTP API 服务;提供 UI 服务
-
8600:采用 DNS 协议提供服务发现功能
示例:部署 3 Servers 和 3 Clients(分布式部署,单数据中心)
快速命令:
sudo docker run --rm -d -p 8500:8500 -p 8600:8600 --name=ConsulServerA consul agent -server -ui -node=ServerA -bootstrap-expect=3 -client=0.0.0.0 sudo docker run --rm -d -p 8501:8500 -p 8601:8600 --name=ConsulServerB consul agent -server -ui -node=ServerB -bootstrap-expect=3 -client=0.0.0.0 -join=172.17.0.2 sudo docker run --rm -d -p 8502:8500 -p 8602:8600 --name=ConsulServerC consul agent -server -ui -node=ServerC -bootstrap-expect=3 -client=0.0.0.0 -join=172.17.0.2 sudo docker run --rm -d -p 8503:8500 -p 8603:8600 --name=ConsulClient1 consul agent -node=Client1 -ui -client=0.0.0.0 -join=172.17.0.2 sudo docker run --rm -d -p 8504:8500 -p 8604:8600 --name=ConsulClient2 consul agent -node=Client2 -ui -client=0.0.0.0 -join=172.17.0.3 sudo docker run --rm -d -p 8505:8500 -p 8605:8600 --name=ConsulClient3 consul agent -node=Client3 -ui -client=0.0.0.0 -join=172.17.0.4
启动 ServerA
sudo docker run --rm -it -p 8500:8500 -p 8600:8600 --name=ConsulServerA consul agent -server -ui -node=ServerA -bootstrap-expect=3 -client=0.0.0.0
-
docker run --rm,容器退出时自动删除容器。便于我们测试,可以重复执行上面的命令
-
docker run -it, 容器以交互模式运行,便于我们观察服务日志
-
docker run -p 8500:8500,容器端口映射,8500 是 UI 服务端口
-
docker run -p 8600:8600
-
consul agent -server,Server 类型的 Agent 节点
-
consul agent -ui,启动 UI 服务
-
consul agent -node=ServerA,agent 节点的名字
-
consul agent -bootstrap-expect=3,需要3个节点才能启动
-
consul agent -client=0.0.0.0,允许任意客户端连接
执行结果:
$ sudo docker run -it -p 8500:8500 --name=ConsulServerA consul agent -server -ui -node=ServerA -bootstrap-expect=3 -client=0.0.0.0
[sudo] password for joker:
==> Starting Consul agent...
Version: '1.12.2'
Node ID: '94930c39-68c5-5563-148b-54787c3ec3e8'
Node name: 'ServerA'
Datacenter: 'dc1' (Segment: '<all>')
Server: true (Bootstrap: false)
Client Addr: [0.0.0.0] (HTTP: 8500, HTTPS: -1, gRPC: -1, DNS: 8600)
Cluster Addr: 172.17.0.2 (LAN: 8301, WAN: 8302)
Encrypt: Gossip: false, TLS-Outgoing: false, TLS-Incoming: false, Auto-Encrypt-TLS: false
==> Log data will now stream in as it occurs:
2022-07-07T03:37:38.252Z [WARN] agent: bootstrap_expect > 0: expecting 3 servers
2022-07-07T03:37:38.257Z [WARN] agent.auto_config: bootstrap_expect > 0: expecting 3 servers
2022-07-07T03:37:38.263Z [INFO] agent.server.raft: initial configuration: index=0 servers=[]
2022-07-07T03:37:38.264Z [INFO] agent.server.raft: entering follower state: follower="Node at 172.17.0.2:8300 [Follower]" leader=
2022-07-07T03:37:38.265Z [INFO] agent.server.serf.wan: serf: EventMemberJoin: ServerA.dc1 172.17.0.2
2022-07-07T03:37:38.265Z [INFO] agent.server.serf.lan: serf: EventMemberJoin: ServerA 172.17.0.2
2022-07-07T03:37:38.265Z [INFO] agent.router: Initializing LAN area manager
2022-07-07T03:37:38.265Z [INFO] agent.server.autopilot: reconciliation now disabled
2022-07-07T03:37:38.265Z [INFO] agent.server: Adding LAN server: server="ServerA (Addr: tcp/172.17.0.2:8300) (DC: dc1)"
2022-07-07T03:37:38.266Z [INFO] agent.server: Handled event for server in area: event=member-join server=ServerA.dc1 area=wan
2022-07-07T03:37:38.266Z [WARN] agent: [core]grpc: addrConn.createTransport failed to connect to {dc1-172.17.0.2:8300 ServerA <nil> 0 <nil>}. Err: connection error: desc = "transport: Error while dialing dial tcp <nil>->172.17.0.2:8300: operation was canceled". Reconnecting...
2022-07-07T03:37:38.267Z [INFO] agent: Started DNS server: address=0.0.0.0:8600 network=udp
2022-07-07T03:37:38.267Z [INFO] agent: Started DNS server: address=0.0.0.0:8600 network=tcp
2022-07-07T03:37:38.267Z [INFO] agent: Starting server: address=[::]:8500 network=tcp protocol=http
2022-07-07T03:37:38.267Z [INFO] agent: started state syncer
2022-07-07T03:37:38.267Z [INFO] agent: Consul agent running!
2022-07-07T03:37:44.776Z [WARN] agent.server.raft: no known peers, aborting election
2022-07-07T03:37:45.473Z [ERROR] agent.anti_entropy: failed to sync remote state: error="No cluster leader"
留意 ServerA 的 IP 是 172.17.0.2,在开启其他 Server 或 Client 时需要。
若以 -d 的方式启动容器,可以通过 docker inspect <container-id> 的方式查看网络信息。
以 docker 方式运行的,需要找到容器的 IP 才可以。docker inspect <Container>
$ sudo docker inspact <container>
"Networks": {
"bridge": {
"IPAMConfig": null,
"Links": null,
"Aliases": null,
"NetworkID": "4aa470fd3c2904d86072b47b3cb702fcda69ee3c328f3cc109fac0fbe29c0fa0",
"EndpointID": "3dd695784883439e21f11b6e7c8ed44459fda85e4b89793ef372d7a2cdf2e03a",
"Gateway": "172.17.0.1",
"IPAddress": "172.17.0.2",
"IPPrefixLen": 16,
"IPv6Gateway": "",
"GlobalIPv6Address": "",
"GlobalIPv6PrefixLen": 0,
"MacAddress": "02:42:ac:11:00:02",
"DriverOpts": null
}
启动 ServerB 和 ServerC,并加入Cluster
sudo docker run --rm -d -p 8501:8500 -p 8601:8600 --name=ConsulServerB consul agent -server -ui -node=ServerB -bootstrap-expect=3 -client=0.0.0.0 -join=172.17.0.2 sudo docker run --rm -d -p 8502:8500 -p 8602:8600 --name=ConsulServerC consul agent -server -ui -node=ServerC -bootstrap-expect=3 -client=0.0.0.0 -join=172.17.0.2
-
docker run -d,容器以守护进程方式后台执行
-
consul agent -join=172.17.0.2,加入172.17.0.2 组成 cluster。使用任意已加入 Cluster 的 Server IP 即可。
启动 Cient1
sudo docker run --rm -it -p 8503:8500 -p 8603:8600 --name=ConsulClient1 consul agent -node=Client1 -ui -client=0.0.0.0 -join=172.17.0.2
使用 client1 的 -it 交换,便于观察日志。
启动 Client2 和 Client 3
sudo docker run --rm -d -p 8504:8500 -p 8604:8600 --name=ConsulClient2 consul agent -node=Client2 -ui -client=0.0.0.0 -join=172.17.0.3 sudo docker run --rm -d -p 8505:8500 -p 8605:8600 --name=ConsulClient3 consul agent -node=Client3 -ui -client=0.0.0.0 -join=172.17.0.4
加入集群,指定任意的节点 IP 即可。
检查结果
UI,我们在六个节点上都使用了 -ui,因此以下任意 URL 都可以访问:
http://<IP>:8500/ui http://<IP>:8501/ui http://<IP>:8502/ui http://<IP>:8503/ui http://<IP>:8504/ui http://<IP>:8505/ui
Command,命令 consule members 可以查看集群中的成员:
$ sudo docker exec 1a5f4ee5325dc9 consul members Node Address Status Type Build Protocol DC Partition Segment ServerA 172.17.0.2:8301 alive server 1.12.2 2 dc1 default <all> ServerB 172.17.0.3:8301 alive server 1.12.2 2 dc1 default <all> ServerC 172.17.0.4:8301 alive server 1.12.2 2 dc1 default <all> Client1 172.17.0.5:8301 alive client 1.12.2 2 dc1 default <default> Client2 172.17.0.6:8301 alive client 1.12.2 2 dc1 default <default> Client3 172.17.0.7:8301 alive client 1.12.2 2 dc1 default <default>
停止由 consul 镜像创建的容器
sudo docker stop $(sudo docker ps -aq --no-trunc -f ancestor=consul)
服务注册
有三种方式完成服务注册:
-
consul services 命令完成服务的注册和注销
-
consul agent 在启动时,同时完成服务的注册
-
HTTP API 完成服务操作,包括注册和其他(查询、注销)
无论采用那种方案,我们需要对服务进行定义。
服务定义
服务定义,指的是对服务的熟悉进行配置,例如名字、ID、地址、标签等。
一个基本的服务定义示例:
~/consul/config/service-some.json
{
"service": {
"id": "someService-01",
"name": "someService",
"tags": ["someTag"],
"address": "127.0.0.1",
"port": 8080,
"meta": {
"info": "some service"
},
"checks": []
}
}
一个完整的服务定义文件如下,JSON 格式。
{
"service": {
"id": "redis",
"name": "redis",
"tags": ["primary"],
"address": "",
"meta": {
"meta": "for my service"
},
"tagged_addresses": {
"lan": {
"address": "192.168.0.55",
"port": 8000,
},
"wan": {
"address": "198.18.0.23",
"port": 80
}
},
"port": 8000,
"socket_path": "/tmp/redis.sock",
"enable_tag_override": false,
"checks": [
{
"args": ["/usr/local/bin/check_redis.py"],
"interval": "10s"
}
],
"kind": "connect-proxy",
"proxy_destination": "redis", // Deprecated
"proxy": {
"destination_service_name": "redis",
"destination_service_id": "redis1",
"local_service_address": "127.0.0.1",
"local_service_port": 9090,
"local_service_socket_path": "/tmp/redis.sock",
"mode": "transparent",
"transparent_proxy": {
"outbound_listener_port": 22500
},
"config": {},
"upstreams": [],
"mesh_gateway": {
"mode": "local"
},
"expose": {
"checks": true,
"paths": [
{
"path": "/healthz",
"local_path_port": 8080,
"listener_port": 21500,
"protocol": "http2"
}
]
}
},
"connect": {
"native": false,
"sidecar_service": {}
"proxy": { // Deprecated
"command": [],
"config": {}
}
},
"weights": {
"passing": 5,
"warning": 1
},
"token": "233b604b-b92e-48c8-a253-5f11514e4b50",
"namespace": "foo"
}
}
也支持 HCL 格式。
几个常用的属性:
| 属性 | 必须 or 可选 | 意义 | 类型 | 默认值 |
|---|---|---|---|---|
| name | 必须 | 服务名称 | string | None |
| id | 可选 | 服务 ID | string | id = name |
| tags | 可选 | 标签 | []string | [] |
| address | 可选 | IP 地址或主机名 | string | 节点的 IP 地址 |
| port | 可选,但指定 address 应该同时指定 port | 端口 | int | None |
| meta | 可选 | 服务 k/v 型元数据 | object | none |
| socket_path | 可选,当服务监听 Unix Domain Socket 时指定 | Unix socket 地址 | string | None |
| checks | 可选 | 服务的健康检查定义 | []Object | none |
| weights |
完整选项说明:https://www.consul.io/docs/discovery/services#service
通常我们将服务配置在 .json 文件中,利用 consul agent 或 consul services 的参数指定配置文件。
consul services register 注册服务
consul agent 启动后,通过 CLI 注册即可,命令如下:
consul services register <service-config.json>
docker 环境下,我们需要将配置文件映射到容器中,再注册:
编辑配置文件:
$ mkdir consul/services -p $ vi consul/services/service-some.json
# 将配置文件目录映射到容器中 sudo docker run --rm -it -p 8500:8500 -p 8605:8600 --name=ConsulDevServer -v ~/consul/services:/consul/services consul agent -dev -client=0.0.0.0
sudo docker exec -it ConsulDevServer consul services register /consul/services/service-some.json
consul agent 启动时注册
启动时,通过指定配置文件,可以在启动时完成 service 的注册。
consul agent 命令的参数 -config-file 和 -config-dir 是用来指定配置文件的,-config-file 独立的配置文件,-config-dir 配置文件所在目录,可以同时加载目录中的多个配置文件。
命令:
consul agent -config-file=<config.json> -config-dir=<configDir>
docker 环境下,会自动加载容器中 /consul/config 中的配置文件,我们需要将配置卷映射到容器中:
sudo docker run --rm -it -p 8500:8500 -v ~/consul/services:/consul/config --name=ConsulDevServer consul agent -dev -client=0.0.0.0
Tip: 除了服务的配置文件,agent 启动时其他选项也可以在配置文件中配置。详细参考 Consul 课程。
HTTP API 注册服务
consul 暴露的 8500 端口负责接收 HTTP API 请求。
注册服务的接口是:
PUT /agent/service/register
查询字符串 Query String:
replace-existing-check:替换已经存在的健康检查
请求主体荷载 JSON 数据,Body Payload:
{
"ID": "redis1",
"Name": "redis",
"Tags": ["primary", "v1"],
"Address": "127.0.0.1",
"Port": 8000,
"Meta": {
"redis_version": "4.0"
},
"EnableTagOverride": false,
"Check": {
"DeregisterCriticalServiceAfter": "90m",
"Args": ["/usr/local/bin/check_redis.py"],
"Interval": "10s",
"Timeout": "5s"
},
"Weights": {
"Passing": 10,
"Warning": 1
}
}
内容服务定义一致。
演示:postman
自定义服务通过 API 注册
HTTP API 的方式允许我们通过 PUT 请求的方案注册服务,那也就意味着我们研发的服务在启动时,可以直接注册到 Consul 中,便于其他服务发现使用。下面就编写 go 程序,将服务注册到 Consul 中。
github.com/hashicorp/consul/api 包,是 consul 提供的对于其 HTTP API 操作的包,我们基于这个包,完成请求 HTTP API 。
产品服务示例代码,代码流程:
-
采用 net/http 包定义服务
-
定义测试路由及处理器。/info
-
使用 consul/api 包完成服务注册
-
启动服务监听
package main
import (
"flag"
"fmt"
"github.com/google/uuid"
"github.com/hashicorp/consul/api"
"log"
"net/http"
)
//main
func main() {
// 接收命令行参数作为服务对外的地址和端口
addr := flag.String("addr", "127.0.0.1", "The address of the listen. The default is 127.0.0.1.")
port := flag.Int("port", 8080, "The port of the listen. The default is 8080.")
flag.Parse()
// 定义服务
server := http.NewServeMux()
// 服务的第一个接口, /info
server.HandleFunc("/info", func(writer http.ResponseWriter, request *http.Request) {
_, err := fmt.Fprintf(writer, "Product Service.")
if err != nil {
log.Fatalln(err)
}
})
// consul 客户端初始化
config := api.DefaultConfig()
config.Address = "192.168.177.131:8500"
client, err := api.NewClient(config)
if err != nil {
log.Fatalln(err)
}
// 定义服务
serviceRegistration := new(api.AgentServiceRegistration)
serviceRegistration.Name = "product"
serviceRegistration.ID = "product-" + uuid.NewString()
serviceRegistration.Address = *addr
serviceRegistration.Port = *port
serviceRegistration.Tags = []string{"product"}
// 注册服务
if err := client.Agent().ServiceRegister(serviceRegistration); err != nil {
log.Fatalln(err)
}
log.Println("Service register was completed.")
// 产品服务启动
address := fmt.Sprintf("%s:%d", *addr, *port)
log.Printf("Service is listening on %s.\n", address)
log.Fatalln(http.ListenAndServe(address, server))
}
服务发现
当我们需要某个服务时,需要使用服务发现。核心就是在 consul 中查询目标服务的地址。consul 提供了俩个方案,完成服务查询:
-
HTTP API
-
DNS 查询
HTTP API
查询服务可以分为基于过滤条件的列表查询,和基于 ID 的单服务信息查询,接口分别:
-
列表查询:GET /v1/agent/services
-
单服务查询:GET /v1/agent/service/:service_id
其中,单服务查询,仅提供服务ID即可,而列表查询需要通过查询字符串filter参数进行过滤,最常见的基于服务的名字查询多个该服务,之后选择其中一个实例使用。
单服务查询 API
GET /v1/agent/service/:service_id
postman 演示
GET http://192.168.177.131:8500/v1/agent/service/redis1
{
"ID": "redis1",
"Service": "redis",
"Tags": [
"primary",
"v1"
],
"Meta": {
"redis_version": "4.0"
},
"Port": 8000,
"Address": "127.0.0.1",
"TaggedAddresses": {
"lan_ipv4": {
"Address": "127.0.0.1",
"Port": 8000
},
"wan_ipv4": {
"Address": "127.0.0.1",
"Port": 8000
}
},
"Weights": {
"Passing": 1,
"Warning": 1
},
"EnableTagOverride": false,
"ContentHash": "6cfc2fbe8597402a",
"Datacenter": "dc1"
}
Go 编码演示
orderService.go
package main
import (
"flag"
"fmt"
"github.com/hashicorp/consul/api"
"log"
"net/http"
)
func main() {
// 处理命令行参数
addr := flag.String("addr", "127.0.0.1", "The Address for listen. Default is 127.0.0.1")
port := flag.Int("port", 8080, "The Port for listen. Default is 8080.")
flag.Parse()
// 定义业务逻辑服务,假设为产品服务
service := http.NewServeMux()
service.HandleFunc("/info", func(writer http.ResponseWriter, request *http.Request) {
_, err := fmt.Fprintf(writer, "Order Service.")
if err != nil {
log.Fatalln(err)
}
})
// 连接 consul ,作为客户端连接 consul
consulApiConfig := api.DefaultConfig()
consulApiConfig.Address = "192.168.177.131:8500"
consulClient, err := api.NewClient(consulApiConfig)
if err != nil {
log.Fatalln(err)
}
// 发出 GET 注册请求
serviceRedis, _, err := consulClient.Agent().Service("redis1", nil)
if err != nil {
log.Fatalln(err)
}
log.Println(serviceRedis.Address, serviceRedis.Port)
// 启动监听
address := fmt.Sprintf("%s:%d", *addr, *port)
fmt.Printf("Order service is listening on %s.\n", address)
log.Fatalln(http.ListenAndServe(address, service))
}
服务信息列表
接口为:GET /v1/agent/services
查询字符串 filter 的格式为字符串,常用的检索支持:
| 选择器 | 支持的运算 | ||
|---|---|---|---|
Address | 地址 | Equal, Not Equal, In, Not In, Matches, Not Matches | ==, !=, |
Port | 端口 | Equal, Not Equal | |
Service | 服务名 | Equal, Not Equal, In, Not In, Matches, Not Matches | |
Tags | 标签 | In, Not In, Is Empty, Is Not Empty | |
ID | ID | Equal, Not Equal, In, Not In, Matches, Not Matches | |
| Kind | 类型 | Equal, Not Equal, In, Not In, Matches, Not Matches | |
| Meta | 元信息 | Is Empty, Is Not Empty, In, Not In | |
| Meta.<any> | 具体的元信息 | Equal, Not Equal, In, Not In, Matches, Not Matches |
完整的 filter 支持请参考:Service - Agent - HTTP API | Consul | HashiCorp Developer
其中运算符语法为:// 是否相等
<Selector> == "<Value>" <Selector> != "<Value>" // 是否为空 <Selector> is empty <Selector> is not empty // 包含 // 子串检查 "<Value>" in <Selector> "<Value>" not in <Selector> <Selector> contains "<Value>" <Selector> not contains "<Value>" // 正则匹配 <Selector> matches "<Value>" <Selector> not matches "<Value>"
同时支持使用逻辑运算连接多个条件:
// Or <Expression 1> or <Expression 2> // And <Expression 1 > and <Expression 2> // Not not <Expression 1> // 分组 ( <Expression 1> ) // Inspects data to check for a match <Matching Expression 1>
Postman 演示
基于名字查找:
GET http://192.168.177.131:8500/v1/agent/services?filter=Service==Product
{
"product-c5d3ced5-b733-4ecf-a762-526aeee55177": {
"ID": "product-c5d3ced5-b733-4ecf-a762-526aeee55177",
"Service": "Product",
"Tags": [
"test"
],
"Meta": {},
"Port": 8081,
"Address": "127.0.0.1",
"TaggedAddresses": {
"lan_ipv4": {
"Address": "127.0.0.1",
"Port": 8081
},
"wan_ipv4": {
"Address": "127.0.0.1",
"Port": 8081
}
},
"Weights": {
"Passing": 1,
"Warning": 1
},
"EnableTagOverride": false,
"Datacenter": "dc1"
},
"product-e771836e-0622-4309-ba7e-b366f1ea2944": {
"ID": "product-e771836e-0622-4309-ba7e-b366f1ea2944",
"Service": "Product",
"Tags": [
"test"
],
"Meta": {},
"Port": 8080,
"Address": "127.0.0.1",
"TaggedAddresses": {
"lan_ipv4": {
"Address": "127.0.0.1",
"Port": 8080
},
"wan_ipv4": {
"Address": "127.0.0.1",
"Port": 8080
}
},
"Weights": {
"Passing": 1,
"Warning": 1
},
"EnableTagOverride": false,
"Datacenter": "dc1"
}
}
ID 包含:
GET http://192.168.177.131:8500/v1/agent/services?filter=ID contains "product-"
ID 前缀:
GET http://192.168.177.131:8500/v1/agent/services?filter=ID matches "^product-"
Tag 包含:
GET http://192.168.177.131:8500/v1/agent/services?filter="test" in Tags
逻辑运算:
GET http://192.168.177.131:8500/v1/agent/services?filter="test" in Tags or Tags is empty
Go 编码演示
其他部分与单服务信息一致,调用的方法为 Agent().ServicesWithFilter():
// 查询基于 filter 过滤的多个服务信息
filter := "Service==Product"
services, err := consulClient.Agent().ServicesWithFilter(filter)
if err != nil {
log.Fatalln(err)
}
for id, sev := range services {
log.Println(id, sev.Address, sev.Port)
}
Agent().Services() 查询全部。
查询到一组服务,是ID对应服务信息的结构。查询之后,通常需要使用负载均衡策略,选择其中之一。常见的负载均衡策略为:
-
rr:Round Robin, 循环
-
wrr : Weighted round robin,加权循环
-
p2c : Power of two choices,随机选2个,再从中选1个效率高的
-
random : Random,随机
-
wr: Weighted Random, 加权随机
DNS 查询
另一种方案就是使用 DNS 查询。consul 实现了一个 DNS 服务器,并将注册其中的服务都分配了对应的域名。

例如:
-
consul.service.consul
-
product.service.consul
格式就是 <service-name>.service[.datacenter-name].consul。其中数据中心可以缺省,表示当前数据中心。
默认情况下,consul 的 DNS 服务监听在 127.0.0.1:8600 上。也就意味着,只要我们解析域名时,指定 DNS 服务为 consul 的地址和端口,就可以完成注册服务的域名解析了。
以 dig 为例,完成注册服务的域名解析工作。( Dig是一个在类Unix命令行模式下查询DNS包括NS记录,A记录,MX记录等相关信息的工具。安装过程见附件。)
dig 语法:
dig @DNS服务器地址 -p DNS服务器端口 带查询的域名
dns 服务的默认端口为:53。而 consul 暴露的端口是 8600。
演示的时候,为了方便在教师机(老师的widows)上也可以访问到该DNS服务器,将docker容器的网络与宿主机网络绑定:--net=host:
$ sudo docker run --rm -it --net=host --name=ConsulDevServer consul agent -dev -client=0.0.0.0
示例,默认 A 类型(IP地址)查询:
$ dig @192.168.177.131 -p 8600 consul.service.consul # 综述,一共几个查询,有几个回复 ; <<>> DiG 9.11.4-P2-RedHat-9.11.4-26.P2.el7_9.9 <<>> @192.168.177.131 -p 8600 consul.service.consul ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 62462 ;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; WARNING: recursion requested but not available # 查询部分 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 4096 ;; QUESTION SECTION: ;consul.service.consul. IN A # 响应部分 ;; ANSWER SECTION: consul.service.consul. 0 IN A 127.0.0.1 # 查询信息 ;; Query time: 2 msec ;; SERVER: 192.168.177.131#8600(192.168.177.131) ;; WHEN: Sun Jul 10 15:19:57 EDT 2022 ;; MSG SIZE rcvd: 66
+short 表示 获取基本短信息:
$ dig @192.168.177.131 -p 8600 +short consul.service.consul 127.0.0.1
带有端口信息,SRV 类型查询
$ dig @192.168.177.131 -p 8600 +short consul.service.consul SRV 1 1 8300 localhost.localdomain.node.dc1.consul.
多个地址的域名解析:
$ dig @192.168.177.131 -p 8600 +short product.service.consul SRV 1 1 8081 7f000001.addr.dc1.consul. 1 1 8083 7f000001.addr.dc1.consul. 1 1 8082 7f000001.addr.dc1.consul. $ dig @192.168.177.131 -p 8600 +short product.service.consul SRV 1 1 8081 7f000001.addr.dc1.consul. 1 1 8082 7f000001.addr.dc1.consul. 1 1 8083 7f000001.addr.dc1.consul. $ dig @192.168.177.131 -p 8600 +short product.service.consul SRV 1 1 8083 7f000001.addr.dc1.consul. 1 1 8082 7f000001.addr.dc1.consul. 1 1 8081 7f000001.addr.dc1.consul.
多次执行,大家会发现响应的结果是随机排序的,这也是 consul DNS 服务给我们实现的简易负载均衡器。
支持 DNS 直接查询域名,也就是我们在使用某个服务地址时,直接使用域名即可,而不是必须要使用 IP 或其他信息了。例如:
product: address: 192.168.1.123:8081
对比
product: address: product.service.consul
域名这种配置,就几乎不用改变。
注意,要支持 DNS 方式,就需要将服务查询所在机器的 DNS 地址,指向 consul 的服务地址8600端口。例如可以通过转发 cousul. 域下的全部域名解析。
服务注销
服务支持 HTTP API 和命令行的方式注销。
HTTP API
| Method | Path | Produces |
|---|---|---|
PUT | /v1/agent/service/deregister/:service_id | application/json |
postman 演示:
服务不存在也没有关系,不会发生任何操作。
API 代码:
func (a *Agent) ServiceDeregister(serviceID string)
consul services deregister
支持 ID 注销
$ consul services deregister -id=web
$ sudo docker exec -it ConsulDevServer consul services deregister -id=product-f7ceb87d-9658-4d91-aaa9-04da54f7d12c Deregistered service: product-f7ceb87d-9658-4d91-aaa9-04da54f7d12c
支持配置文件注销:
$ cat web.json
{
"Service": {
"Name": "web"
}
}
$ consul services deregister web.json
services deregister 命令只能主要 service register 注册的服务,而不能注销 agent 通过配置文件加载的服务。agent 配置文件加载的服务需要通过修改配置文件,重新加载配置文件来实现。
健康检查
服务注册中的另一个主要的功能就是健康检查,健康检查可以针对服务,称为应用级别,也可以针对系统,称为系统级别,例如内存、CPU用量的检查。
Consul 支持多种类型的检查:
-
Script + Interval,周期性脚本
-
HTTP + Interval,周期性 HTTP
-
TCP + Interval,周期性 TCP
-
Time to Live (TTL),TTL
-
Docker + Interval,周期性 Docker
-
gRPC + Interval,周期性 gRPC
-
H2ping + Interval, 周期性 H2
-
Alias,别名
我们常常通过周期性脚本检查来监控系统的状态;通过周期性 HTTP、gRPC、TCP 来检查服务的状态,这取决于我们提供何种类型的服务。
一个服务可以定义多个检查,全部检查都通过,才意味着服务是健康的。
TCP 检查
示例:对 redis 服务做 tcp 检测。
我们通过服务的配置文件完成该示例,首先准备好 redis,我们采用 Docker 的方式部署 redis:
sudo docker pull redis sudo docker run --rm --name RedisDev --net=host -d redis
redis 默认的暴露的是:127.0.0.1:6379
我们配置 redis 服务,注册到 consul,并同时增加健康检测:
redis 服务的配置 json:
{
"service": {
"id": "redis-01",
"name": "Redis",
"tags": ["primary"],
"address": "127.0.0.1",
"port": 6379,
"meta": {
"info": "Memory Cache by Redis."
},
"checks": [
{
"id": "redis-01-check",
"name": "Redis-01-check",
"tcp": "127.0.0.1:6379",
"interval": "5s",
"timeout": "1s"
}
]
}
}
可以使用 consul services register 命令或 HTTP API 完成注册:
HTTP API 示例,postman,注意 Body 的 Payload 要大小写问题:
PUT http://192.168.177.131:8500/v1/agent/service/register
{
"ID": "redis-01",
"Name": "Redis",
"Tags": ["primary"],
"Address": "127.0.0.1",
"Port": 6379,
"Meta": {
"info": "Memory Cache by Redis."
},
"Checks": [
{
"CheckID": "redis-01-check",
"Name": "Redis-01-check",
"TCP": "127.0.0.1:6379",
"Interval": "5s",
"Timeout": "1s"
}
]
}
服务的 HTTP 检查
我们以周期性 HTTP 为例,定义一个检查:
{
"check": {
"id": "check-id",
"name": "The Name of Health Check on HTTP Service",
"http": "https://localhost:8080/health",
"tls_server_name": "",
"tls_skip_verify": false,
"method": "GET",
"header": { "Content-Type": ["application/json"] },
"body": "{\"method\":\"health\"}",
"interval": "5s",
"timeout": "1s"
}
}
可以在 consul services register 注册服务时,在服务是配置文件中指定,也可以在 HTTP API 注册服务时设置。甚至可以利用 HTTP API 单独注册健康检查。
我们以最常用的定义服务时,同时定义健康检查为例,演示:
Product 服务,需要注册时提供健康检查:
productService.go 其他代码与之前保持一致:
func main() {
// 定义 http 检测接口,响应 2xx 都表示检测通过,其他状态码,表示失败
service.HandleFunc("/health", func(writer http.ResponseWriter, request *http.Request) {
log.Println("Consul Check.")
_, err := fmt.Fprintf(writer, "Product Service is health")
if err != nil {
log.Fatalln(err)
}
})
// 定义注册中心的服务
id := uuid.NewString()
serviceReg := new(api.AgentServiceRegistration)
serviceReg.Name = "Product"
serviceReg.ID = "product-" + id
serviceReg.Address = *addr
serviceReg.Port = *port
serviceReg.Tags = []string{"test"}
// 定义服务检测
serviceReg.Checks = api.AgentServiceChecks{
&api.AgentServiceCheck{
CheckID: "product-check-" + id,
Name: "Product-Check",
Interval: "3s",
Timeout: "1s",
HTTP: fmt.Sprintf("http://%s/health", address),
Method: "GET",
SuccessBeforePassing: 0,
FailuresBeforeWarning: 0,
FailuresBeforeCritical: 0,
DeregisterCriticalServiceAfter: "",
},
}
}
通过 consul ui 查看健康检查状态!
HTTP 检查根据响应状态码判定结果,2xx 表示通过,health 为 passing 状态;429 Too ManyRequests 表示请求过多, health 为 warning 状态,其他表示未通过,health 为 critical 状态。
再看一个 gRPC 的健康检查示例:
{
"check": {
"id": "mem-util",
"name": "Service health status",
"grpc": "127.0.0.1:12345",
"grpc_use_tls": true,
"interval": "10s"
}
}
若使用脚本检查系统状态,根据脚本的返回值来确定健康状态。也是三种:
-
Exit code 0 - passing
-
Exit code 1 - warning
-
Any other code - failing
健康状态
consul 对服务的健康状态有三种描述:
-
passing,检查通过
-
warning,警告状态
-
critical,危急状态,服务失效
为了防止健康检查的抖动,进而限制它们对集群造成的负载,健康检查可以配置为仅在指定数量的连续检查返回通过/关键后才变为通过/警告/关键。在达到配置的阈值之前,状态不会转换状态。默认都是0,表示状态立即改变。有三个配置:
-
success_before_passing,通过前的成功次数
-
failures_before_warning,警告前的失败次数
-
failures_before_critical,危急前的失败次数
定义的健康检测的初始状态默认为 critical,这可以有效防止无效服务的注册。若需要更改,可以通过选项 status 来调整初始状态。
处于 critical 状态的服务,可能被 consul 自动注销。当服务的状态超过 deregister_critical_service_after 所指定的时长后,consul 会自动注销该服务。
服务健康状态查询
当我们使用服务发现查询服务时,DNS 方式会自动过滤状态未通过的全部服务,而 HTTP API 方式需要我们主动去查询。
DNS 方式:
dig @192.168.177.131 -p 8600 +short product.service.consul 192.168.177.1 127.0.0.1
仅仅列出了 check 通过的服务。
HTTP API 方式:
GET /v1/agent/services 的方式和 GET /v1/agent/service/<service-id> 的方式都可以获取服务信息,不论该服务的check是否通过。
我们需要接口:
| Method | Path | Produces |
|---|---|---|
GET | /agent/health/service/name/:service_name | application/json |
GET | /agent/health/service/name/:service_name?format=text | text/plain |
GET | /agent/health/service/id/:service_id | application/json |
GET | /agent/health/service/id/:service_id?format=text | text/plain |
来基于名字或ID获取服务的健康状态。
注意,基于名字来获取服务状态如果使用 text 格式,那么必须全部服务都通过,状态才为通过,否则为紧急。
postman演示。
服务通信
服务间通讯通常有,HTTP、RPC、消息队列、事件驱动几种方式。其中 HTTP 是最常见的方式,当前推荐使用 Restful API。除了不同的协议之外,服务间的通信还可以分类为同步通信和异步通信,一般来说,HTTP 的是典型的同步方案,而消息队列和事件驱动是典型的异步方案。同步方案服务间的耦合度相对较高,而异步通信服务间的耦合度相对较低。列表如下:
协议分类:
-
HTTP,超文本传输协议
-
旧式风格,GET、POST 完成全部请求,URI 上标识对资源的操作
-
Restful API,HTTP API 的一种风格
-
-
RPC,远程过程调用,通常使用 gRPC
-
消息队列,Message Queue
-
事件驱动
同步异步:
-
同步
-
HTTP,很多客户端也支持异步HTTP通讯了
-
RPC
-
-
异步
-
消息队列
-
事件驱动
-
HTTP,很多客户端也支持异步HTTP通讯了
-
目前主流的微服务架构,通常会采用服务对外是 HTTP (推荐 Restful API) 通讯,而对内是基于 gRPC 的 RPC 通讯。使用消息队列完成异步消息通讯。如图所示:
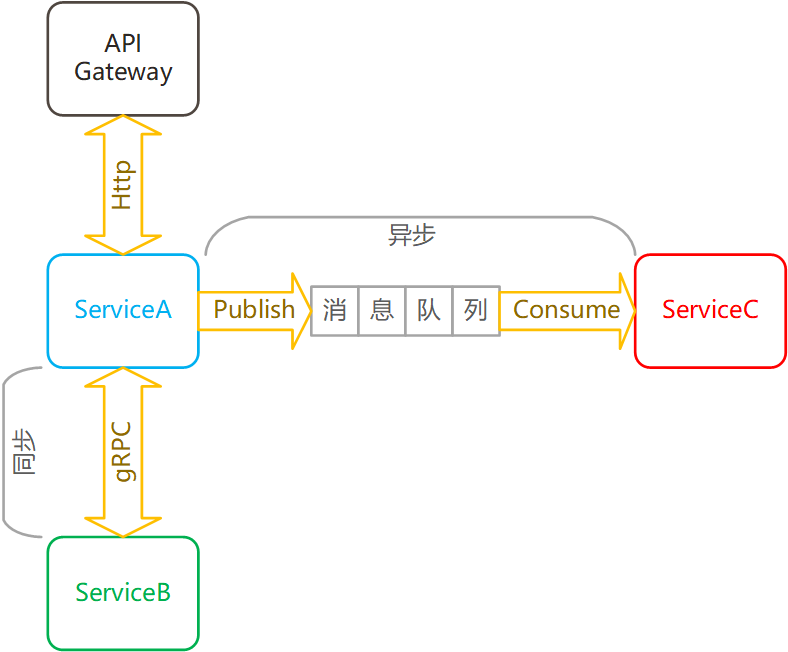
HTTP 之 RestfulApi
Restful API 介绍
Restful API,一种通用、流行的 API 设计风格,至少基于 HTTP/1.1,因为1.1中增加了若干请求方式,包含 PUT、DELETE等。其中:
-
REST 是 Representational State Transfer, 表述性状态转移的缩写,如果一个架构符合 REST 原则,就称它为 RESTful 架构
-
RESTful 架构可以充分的利用 HTTP 协议的各种功能,是 HTTP 协议的最佳实践
-
RESTful API 是一种软件架构风格、设计风格,可以让软件更加清晰,更简洁,更有层次,可维护性更好
例如若需要对文章 Article 资源做操作,Restful 风格的 API 会处理以下请求:
| Operation | Method | URI | Body |
|---|---|---|---|
| 添加 | POST | /articles | 全部 Article 对象属性 |
| 查询集合 | GET | /articles?filter | null |
| 查询特定 | GET | /articles/article-id | null |
| 删除特定 | DELETE | /articles/article-id | null |
| 删除集合 | DELETE | /articles?filter | null |
| 更新整体 | PUT | /articles/article-id | 全部 Article 对象属性 |
| 更新部分 | PATCH | /articles/article-id | 部分 Article 对象属性 |
一言蔽之,对某个资源操作采用动作加资源标识的形式。动作,使用 HTTP 的请求方式标识,资源标识用特定的URI标识,通常为复数形式。若操作的是批量数据,使用 Query String 中的过滤器 filter 或 关键字 keyword 进行过滤,若操作的是特定资源,在 URI 上使用资源 ID 进行标识。在添加、更新时,需要在请求主体中携带资源信息,现在通常是 json 格式。
对比旧式的 API 风格,相同功能的 API 旧式风格如下:
| Operation | Method | URI | Body |
|---|---|---|---|
| 添加 | POST | /add-articles | 全部 Article 对象属性 |
| 查询集合 | GET | /get-articles?filter | null |
| 查询特定 | GET | /get-articles/article-id | null |
| 删除特定 | GET | /delete/articles/article-id | null |
| 删除集合 | GET | /delete/articles?filter | null |
| 更新整体 | POST | /update/articles/article-id | 全部 Article 对象属性 |
| 更新部分 | POST | /update-part-articles/article-id | 部分 Article 对象属性 |
核心要点就是请求方式由是否需要携带主体数据确定,需要携带就是 POST 请求,不需要就是 GET 请求。同时,在 URI 上提供对资源的操作动词。这种方案流行的好多年,是因为大家对 HTTP 协议的理解和各大浏览器厂商对请求协议的支持不完善引起的。
对比 Restful API,旧式风格明显 URI 显得更复杂,而且没有充分利用 HTTP Method,不够清晰。
除了规范请求API之外,Restful API 风格还规范,尽量使用标准的响应状态码 Response Status Code 来表示请求结果。常用的响应如下表:
| Method | URI | 响应状态码 |
|---|---|---|
| POST | /articles | 201 Created |
| GET | /articles?filter | 200 OK |
| GET | /articles/article-id | 200 OK |
| DELETE | /articles/article-id | 204 No Content |
| DELETE | /articles?filter | 204 No Content |
| PUT | /articles/article-id | 200 OK |
| PATCH | /articles/article-id | 200 OK |
除了以上资源的操作响应状态之外,其他的操作都应该响应合适的状态码,大类如下:
-
1xx 相关信息
-
2xx 操作成功
-
3xx 重定向
-
4xx 客户端错误
-
5xx 服务器错误
例如,我们在做限流操作时,如果客户端请求被限,则会响应:429 Too Many Requests 表示客户端请求过多。
除了状态要规范,响应主体通常也是 JSON 的格式进行规范。
一言以蔽之,就是充分利用 HTTP 协议规范我们的请求响应,做到通用、规范、简洁的方法管理我们的请求响应。
REST 是 Representational State Transfer, 表述性状态转移的缩写,如果一个架构符合 REST 原则,就称它为 RESTful 架构。该原则具有如下特点:
-
表述性(Representational)是指客户端请求一个资源,服务器拿到的这个资源,就是表述
-
资源是REST系统的核心概念,所有的设计都是以资源为中心的
-
资源的地址在Web中就是URL统一资源定位符
-
对资源的操作不会改变标识符
Restful API Go 编码示例
官方的 net/http 包不支持基于 Method 定义路由,仅仅支持 Path 方式。但 web 框架中都支持基于 Method 的路由,例如 gin, kratos, go-micro 等。
我们以一个简单的路由包为例,展示 Restful API 的定义,我们使用的是 gorilla/mux 包,在 Github 上有 17.1 k 的 Star(2022/08/04)。
先 get:
go get -u github.com/gorilla/mux
示例代码:
package main
import (
"fmt"
"github.com/gorilla/mux"
"log"
"net/http"
)
func articlesList(writer http.ResponseWriter, request *http.Request) {
fmt.Fprintf(writer, "Article Service: List articles")
}
func articlesRetrieve(writer http.ResponseWriter, request *http.Request) {
fmt.Fprintf(writer, "Article Service: Retrieve articles")
}
func articlesCreate(writer http.ResponseWriter, request *http.Request) {
fmt.Fprintf(writer, "Article Service: Create articles")
}
func articlesDelete(writer http.ResponseWriter, request *http.Request) {
fmt.Fprintf(writer, "Article Service: Delete articles")
}
func articlesUpdate(writer http.ResponseWriter, request *http.Request) {
fmt.Fprintf(writer, "Article Service: Update articles")
}
func articlesUpdatePartial(writer http.ResponseWriter, request *http.Request) {
fmt.Fprintf(writer, "Article Service: Update Partial articles")
}
func main() {
// 定义路由
router := mux.NewRouter()
// Restful API
router.HandleFunc("/articles", articlesList).Methods("GET")
router.HandleFunc("/articles/{id}", articlesRetrieve).Methods("GET")
router.HandleFunc("/articles", articlesCreate).Methods("POST")
router.HandleFunc("/articles/{id}", articlesDelete).Methods("DELETE")
router.HandleFunc("/articles/{id}", articlesUpdate).Methods("PUT")
router.HandleFunc("/articles/{id}", articlesUpdatePartial).Methods("PATCH")
log.Fatal(http.ListenAndServe(":8088", router))
}
postman 测试
HTTP 之 H2 vs H1
现阶段,我们所说的 HTTP 请求,通常表示 HTTP/1.1 版本的请求。HTTP/1.1 于1997年1月发布,目前最流行的版本。
HTTP/1.1 的典型特点:
-
Host 标头,通过 Host 标头可以区分虚拟主机
-
支持持久连接,persistent connection,默认开启
Connection: keep-alive,即 TCP 连接默认不关闭,可以被多个请求复用 -
范围请求,在请求头引入了
range头域,它允许只请求资源的某个部分,即返回码是206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接,支持断点续传 -
缓存处理,引入了更多的缓存控制策略:
Cache-Control、Etag/If-None-Match等
2015年5月HTTP/2标准正式发表,就是 RFC 7540。H2 标准带来了如下的特征:
-
二进制分帧,frame,HTTP/1.1的头信息是文本(ASCII编码),数据体可以是文本,也可以是二进制;HTTP/2 头信息和数据体都是二进制,统称为“帧”:头信息帧和数据帧。帧是 HTTP/2 数据通信的最小单位。
-
数据流,stream,HTTP/2 的数据包是不按顺序发送的,同一个连接里面连续的数据包,可能属于不同的请求或响应。HTTP/2 将每个请求或响应的所有数据包,称为一个数据流(stream)。每个数据流都有一个独一无二的编号。数据包发送的时候,都必须标记数据流 ID,用来区分它属于哪个数据流。
-
多路复用,双工通信,通过单一的 HTTP/2 连接发起多重的请求-响应消息,即在一个连接里,客户端可以同时发送和接收多个请求和响应
-
HTTP/2 不再依赖多 TCP 连接实现多流并行
-
同域名下所有通信都在单个连接上完成,同个域名只需要占用一个 TCP 连接,消除了因多个 TCP 连接而带来的延时和内存消耗
-
单个连接可以承载任意数量的双向数据流,单个连接上可以并行交错的请求和响应,之间互不干扰
-
数据流以消息的形式发送,而消息又由一个或多个帧组成,多个帧之间可以乱序发送,因为根据帧首部的流标识可以重新组装。
-
-
首部压缩,HTTP/2对消息头采用 HPACK 算法进行压缩传输,能够节省消息头占用的网络的流量。压缩是使用了首部表策略
-
服务端推送,server push,HTTP/2 允许服务器未经请求,主动向客户端发送资源,这叫做服务器推送
当我们的服务支持 H2 后,意味着我们可以高效的在服务间进行基于 HTTP 的数据传递了。Go 中最常用的 RPC 实现 gRPC 底层也是基于 HTTP/2 的。
gRPC 通信
RPC 介绍
RPC, Remote Procedure Call,远程过程调用。与 HTTP 一致,也是应用层协议。该协议的目标是实现:调用远程过程(方法、函数)就如调用本地方法一致。
如图所示:
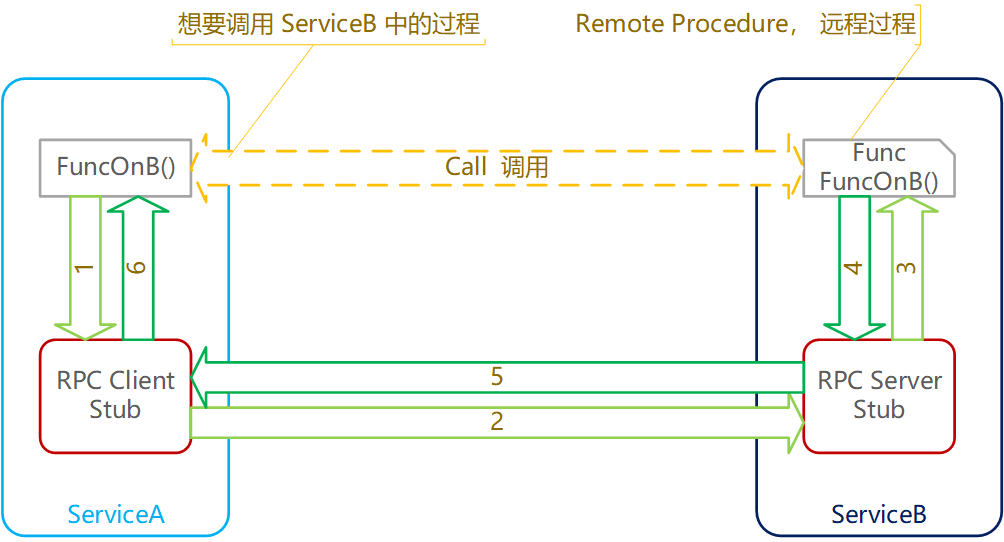
说明:
-
ServiceA 需要调用 ServiceB 的 FuncOnB 函数,对于 ServiceA 来说 FuncOnB 就是远程过程
-
RPC 的目的是让 ServiceA 可以像调用 ServiceA 本地的函数一样调用远程函数 FuncOnB,也就是 ServieA 上代码层面使用:
serviceB.FuncOnB()即可完成调用 -
RPC 是 C/S 模式,调用方为 Client,远程方为 Server
-
RPC 把整体的调用过程,数据打包、网络请求等,封装完毕,在 C、S 两端的 Stub 中。Stub(代码存根)
-
调用流程如下
-
ServiceA 将调回需求告知 Client Sub
-
Client Sub 将调用目标(Call ID)、参数数据(params)等调用信息进行打包(序列化),并将打包好的调用信息通过网络传输给 Server Sub
-
Server Sub 将根据调用信息,调用相应过程。期间涉及到数据的拆包(反序列化)等操作。
-
远程过程 FuncOnB 运行,并得到结果,将结果告知 Server Sub
-
Server Sub 将结果打包,并传输回给 Client Sub
-
Client Sub 将结果拆包,把最终函数调用的结果告知 ServiceA
-
以上就是典型 RPC 的流程。
RPC 协议没有对网络层做规范,那也就意味着具体的 RPC 实现可以基于 TCP,也可以基于其他协议,例如 HTTP,UDP 等。RPC 也没有对数据传输格式做规范,也就是逻辑层面,传输 JSON、Text、protobuf 都可以。这些都要看具体的 RPC 产品的实现。广泛使用的 RPC 产品有 gRPC,Thrift 等。
gRPC 介绍
gPRC 官网(https://grpc.io/)上的 Slogan 是:A high performance, open source universal RPC framework。就是:一个高性能、开源的通用 RPC 框架。
支持多数主流语言:C#、C++、Dart、Go、Java、Kotlin、Node、Objective-C、PHP、Python、Ruby。其中 Go 支持 Windows, Linux, Mac 上的 Go 1.13+ 版本。
gRPC 是一个 Google 开源的高性能远程过程调用 (RPC) 框架,可以在任何环境中运行。它可以通过对负载平衡、跟踪、健康检查和身份验证的可插拔支持有效地连接数据中心内和跨数据中心的服务。它也适用于分布式计算的最后一步,将设备、移动应用程序和浏览器与后端服务接。

在 gRPC 中,客户端应用程序可以直接调用不同机器上的服务器应用程序的方法,就像它是本地对象一样,使您更容易创建分布式应用程序和服务。与许多 RPC 系统一样,gRPC 基于定义服务的思想,指定可以远程调用的方法及其参数和返回类型。在服务端,服务端实现这个接口并运行一个 gRPC 服务器来处理客户端调用。在客户端,客户端有一个存根(在某些语言中仅称为客户端),它提供与服务器相同的方法。
技术上,gRPC 基于 HTTP/2 通信,采用 Protocol Buffers 作数据序列化。
准备 gRPC 环境
使用 gRPC 需要:
-
Go
-
Protocol Buffer 编译器,
protoc,推荐版本3 -
Go Plugin,用于 Protocol Buffer 编译器
安装 protoc:
可以使用 yum 或 apt 包管理器安装,但通常版本会比较滞后。因此更建议使用预编译的二进制安装。
下载地址:
https://github.com/protocolbuffers/protobuf/releases
基于系统和版本找到合适的二进制下载并安装。
CentOS 演示:
# 下载特定版本,当前(2022年08月)最新 21.4 $ curl -LO https://github.com/protocolbuffers/protobuf/releases/download/v21.4/protoc-21.4-linux-x86_64.zip # 解压到特定目录 $ sudo unzip protoc-21.4-linux-x86_64.zip -d /usr/local # 如果特定目录中的bin不在环境变量 path 中,手动加入 path # 测试安装结果,注意版本应该是 3.x $ protoc --version libprotoc 3.21.4
Win 演示,下载,解压到指定目录,在 CMD 中运行:
# 解压到指定目录即可,要保证 protoc/bin 位于环境变量 path 中,可以随处调用 > protoc.exe --version libprotoc 3.21.4
安装 Go Plugin:
# 下载特定版本,当前(2022年08月)最新 v1.28.1 > go install google.golang.org/protobuf/cmd/protoc-gen-go@latest # 下载特定版本,当前(2022年08月)最新 v1.2.0 > go install google.golang.org/grpc/cmd/protoc-gen-go-grpc@latest # 安装完毕后,要保证 $GOPATH/bin 位于环境变量 path 中 # 测试安装结果 > protoc-gen-go --version protoc-gen-go.exe v1.28.1 > protoc-gen-go-grpc --version protoc-gen-go-grpc 1.2.0
Protocol Buffer 的基础使用
默认情况下,gRPC 使用 Protocol Buffers,这是 Google 用于序列化结构化数据的成熟开源机制(尽管它可以与 JSON 等其他数据格式一起使用)。
Protocol Buffers 的文档:https://developers.google.com/protocol-buffers/docs/overview
使用 Protocol Buffers 的基本步骤是:
-
使用 protocol buffers 语法定义消息,消息是用于传递的数据
-
使用 protocol buffers 语法定义服务,服务是 RPC 方法的集合,来使用消息
-
使用 Protocol Buffer编 译工具
protoc来编译,生成对应语言的代码,例如 Go 的代码
使用 Protocol Buffers 的第一步是在 .proto 文件中定义序列化的数据的结构,.proto 文件是普通的文本文件。Protocol Buffers 数据被结构化为消息,其中每条消息都是一个小的信息逻辑记录,包含一系列称为字段的 name-value 对。
除了核心内容外,.proto 文件还需要指定语法版本,目前主流的也是最新的 proto3 版本。在 .proto 文件的开头指定。
一个简单的产品信息示例:
product.proto
syntax = "proto3";
// 定义 Product 消息
message Product {
string name = 1;
int64 id = 2;
bool is_sale = 3;
}
第二步是在 .proto 文件中定义 gRPC 服务,将 RPC 方法参数和返回类型指定为 Protocol Buffers 消息,继续编辑 product.proto :
syntax = "proto3";
// 为了生成 go 代码,需要增加 go_package 属性,表示代码所在的包。protoc 会基于包构建目录
option go_package = "./proto-codes";
// 定义 ProductInfo 消息
message ProductInfoResponse {
string name = 1;
int64 int64 = 2;
bool is_sale = 3;
}
// rpc 方法 ProductInfo 需要的参数消息
message ProductInfoRequest {
int64 int64 = 1;
}
// 定义 Product 服务
service Product {
// 获取产品信息
rpc ProductInfo (ProductInfoRequest) returns (ProductInfoResponse) {}
}
第三步是使用 protoc 工具将 .proto 定义的消息和包含 rpc 方法的服务编译为目标语言的代码,我们选择 Go 代码。
$ protoc --go_out=. --go-grpc_out=. product.proto # --go_out *.pb.go 目录 # --go-grpc_out *_grpc.pb.go 目录
其中:
-
*.pb.go包含消息类型的定义和操作的相关代码 -
*_grpc.pb.go包含客户端和服务端的相关代码
生成的代码主要是结构上的封装,在继续使用时,还需要继续充实业务逻辑。
基于 gRPC 的服务间通信示例
示例说明,存在两个服务,订单服务和产品服务。其中:
-
订单服务提供 HTTP 接口,用于完成订单查询。订单中包含产品信息,要利用 grpc 从产品服务获取产品信息
-
产品服务提供 grpc 接口,用于响应微服务内部产品信息查询
本例中,对于 grpc 来说,产品服务为服务端、订单服务为客户端。
同时不考虑其他业务逻辑,例如产品服务也需要对外提供 http 接口等,仅在乎 grpc 的通信示例。同时不考虑服务发现和网关等。
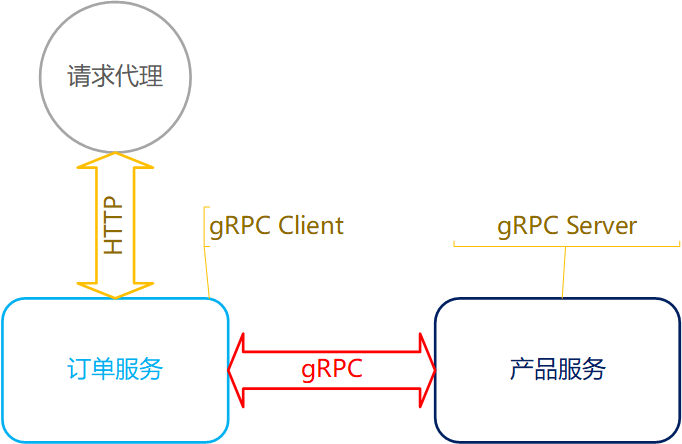
编码实现:
一:基于之前定义的 .proto 文件生成 pb.go 文件
注意,客户端和服务端,都需要使用生成的 pb.go 文件
二:实现订单服务
orderService/httpService.go
package main
import (
"context"
"encoding/json"
"flag"
"fmt"
"google.golang.org/grpc"
"google.golang.org/grpc/credentials/insecure"
"log"
"net/http"
"orderService/protos/codes"
"time"
)
var (
// 目标 grpc 服务器地址
gRPCAddr = flag.String("grpc", "localhost:50051", "the address to connect to")
// http 命令行参数
addr = flag.String("addr", "127.0.0.1", "The Address for listen. Default is 127.0.0.1")
port = flag.Int("port", 8080, "The Port for listen. Default is 8080.")
)
func main() {
flag.Parse()
// 连接 grpc 服务器
conn, err := grpc.Dial(*gRPCAddr, grpc.WithTransportCredentials(insecure.NewCredentials()))
if err != nil {
log.Fatalf("did not connect: %v", err)
}
defer conn.Close()
// 实例化 grpc 客户端
c := codes.NewProductClient(conn)
// 定义业务逻辑服务,假设为产品服务
service := http.NewServeMux()
service.HandleFunc("/orders", func(writer http.ResponseWriter, request *http.Request) {
// 调用 grpc 方法,完成对服务器资源请求
ctx, cancel := context.WithTimeout(context.Background(), time.Second)
defer cancel()
r, err := c.ProductInfo(ctx, &codes.ProductInfoRequest{
Int64: 42,
})
if err != nil {
log.Fatalln(err)
}
resp := struct {
ID int `json:"id"`
Quantity int `json:"quantity"`
Products []*codes.ProductInfoResponse `json:"products"`
}{
9527, 1,
[]*codes.ProductInfoResponse{
r,
},
}
respJson, err := json.Marshal(resp)
if err != nil {
log.Fatalln(err)
}
writer.Header().Set("Content-Type", "application/json")
_, err = fmt.Fprintf(writer, "%s", string(respJson))
if err != nil {
log.Fatalln(err)
}
})
// 启动监听
address := fmt.Sprintf("%s:%d", *addr, *port)
fmt.Printf("Order service is listening on %s.\n", address)
log.Fatalln(http.ListenAndServe(address, service))
}
三,实现产品服务
productService/grpcService.go
package main
import (
"context"
"flag"
"fmt"
"google.golang.org/grpc"
"log"
"net"
"productService/protos/compiles"
)
//grpc 监听端口
var port = flag.Int("port", 50051, "The server port")
// ProductServer 实现 UnimplementedProductServer
type ProductServer struct {
compiles.UnimplementedProductServer
}
func (ProductServer) ProductInfo(ctx context.Context, pr *compiles.ProductInfoRequest) (*compiles.ProductInfoResponse, error) {
return &compiles.ProductInfoResponse{
Name: "马士兵 Go 云原生",
Int64: 42,
IsSale: true,
}, nil
}
func main() {
flag.Parse()
//设置 tcp 监听器
lis, err := net.Listen("tcp", fmt.Sprintf(":%d", *port))
if err != nil {
log.Fatalf("failed to listen: %v", err)
}
// 新建 grpc Server
s := grpc.NewServer()
// 将 ProductServer 注册到 grpc Server 中
compiles.RegisterProductServer(s, ProductServer{})
log.Printf("server listening at %v", lis.Addr())
// 启动监听
if err := s.Serve(lis); err != nil {
log.Fatalf("failed to serve: %v", err)
}
}
测试,访问 order 的 http 接口。获取订单信息中,包含产品信息。
gRPC 核心概念
服务定义
与许多 RPC 系统一样,gRPC 基于定义服务的思想,指定可以远程调用的方法及其参数和返回类型。默认情况下,gRPC 使用 Protocol Buffer 作为接口定义语言 (IDL) 来描述服务接口和有效负载消息的结构。
service HelloService {
rpc SayHello (HelloRequest) returns (HelloResponse);
}
message HelloRequest {
string greeting = 1;
}
message HelloResponse {
string reply = 1;
}
gRPC 支持定义四种服务方法:
-
一元 RPC,其中客户端向服务器发送单个请求并获得单个响应,就像正常的函数调用一样。
rpc SayHello(HelloRequest) returns (HelloResponse);
-
服务器流式 RPC,其中客户端向服务器发送请求并获取流以读回一系列消息。客户端从返回的流中读取,直到没有更多消息为止。 gRPC 保证单个 RPC 调用中的消息顺序。
rpc LotsOfReplies(HelloRequest) returns (stream HelloResponse);
-
客户端流式 RPC,其中客户端写入一系列消息并将它们发送到服务器,再次使用提供的流。一旦客户端完成了消息的写入,它就会等待服务器读取它们并返回它的响应。 gRPC 再次保证了单个 RPC 调用中的消息顺序。
rpc LotsOfGreetings(stream HelloRequest) returns (HelloResponse);
-
双向流式 RPC,双方使用读写流发送一系列消息。这两个流独立运行,因此客户端和服务器可以按照他们喜欢的任何顺序读取和写入:例如,服务器可以在写入响应之前等待接收所有客户端消息,或者它可以交替读取消息然后写入消息,或其他一些读取和写入的组合。保留每个流中消息的顺序。
rpc BidiHello(stream HelloRequest) returns (stream HelloResponse);
使用 API
从 .proto 文件中的服务定义开始,gRPC 提供了生成客户端和服务器端代码的 Protocol Buffer 编译器插件。 gRPC 用户通常在客户端调用这些 API,并在服务器端实现相应的 API。
-
在服务端,服务端实现服务声明的方法,并运行一个 gRPC 服务器来处理客户端调用。 gRPC 基础架构解码传入请求、执行服务方法并编码服务响应。
-
在客户端,客户端有一个称为存根的本地对象(对于某些语言,首选术语是客户端),它实现与服务相同的方法。然后客户端可以在本地对象上调用这些方法,将调用的参数包装在适当的协议缓冲区消息类型中——gRPC 负责将请求发送到服务器并返回服务器的协议缓冲区响应。
同步与异步
在接收到服务端响应之前阻塞的同步 RPC 调用最接近 RPC 所希望的过程调用的抽象。另一方面,网络本质上是异步的,在许多情况下,能够在不阻塞当前线程的情况下启动 RPC 是很有用的。
大多数语言中的 gRPC 编程 API 有同步和异步两种风格。
gRPC 生命周期
生命周期指的是 gRPC 客户端调用 gRPC 服务端方法的过程。区别于不同的4种服务定义,过程如下:
一元 RPC
首先考虑最简单的 RPC 类型,其中客户端发送单个请求并返回单个响应。
-
一旦客户端调用了一个存根方法,服务器就会被通知该 RPC 已被调用,其中包含该调用的客户端元数据、方法名称和指定的截止日期(如果适用)。
-
然后,服务器可以立即发回自己的初始元数据(必须在任何响应之前发送),或者等待客户端的请求消息。首先发生的是特定于应用程序的。
-
一旦服务器收到客户端的请求消息,它就会执行任何必要的工作来创建和填充响应。然后将响应连同状态详细信息(状态代码和可选状态消息)和可选尾随元数据一起返回(如果成功)给客户端。
-
如果响应状态为 OK,则客户端得到响应,从而完成客户端的调用。
服务器流式 RPC
服务器流式 RPC 类似于一元 RPC,除了服务器返回消息流以响应客户端的请求。发送所有消息后,服务器的状态详细信息(状态代码和可选状态消息)和可选的尾随元数据将发送到客户端。这样就完成了服务器端的处理。客户端在拥有所有服务器消息后完成。
客户端流式 RPC
客户端流式 RPC 类似于一元 RPC,不同之处在于客户端向服务器发送消息流而不是单个消息。服务器响应一条消息(连同其状态详细信息和可选的尾随元数据),通常但不一定是在它收到所有客户端的消息之后。
双向流式 RPC
在双向流式 RPC 中,调用由调用方法的客户端和接收客户端元数据、方法名称和截止日期的服务器发起。服务器可以选择发回其初始元数据或等待客户端开始流式传输消息。
客户端和服务器端流处理是特定于应用程序的。由于这两个流是独立的,客户端和服务器可以以任意顺序读写消息。例如,服务器可以等到它收到客户端的所有消息后再写入它的消息,或者服务器和客户端可以玩 “ping-pong”——服务器收到请求,然后发回响应,然后客户端发送基于响应的另一个请求,依此类推。
截止日期/超时
gRPC 允许客户端指定在 RPC 因 DEADLINE_EXCEEDED 错误而终止之前,他们愿意等待 RPC 完成多长时间。在服务器端,服务器可以查询特定的 RPC 是否已超时,或者还剩多少时间来完成 RPC。
指定期限或超时是特定于语言的:一些语言 API 根据超时(持续时间)工作,而一些语言 API 根据期限(固定时间点)工作,可能有也可能没有默认期限。
RPC 终止
在 gRPC 中,客户端和服务器都对调用是否成功做出独立的本地判断,并且它们的结论可能不匹配。这意味着,例如,您可能有一个 RPC 在服务器端成功完成(“我已经发送了所有响应!”)但在客户端失败(“响应在我的截止日期之后到达!”)。服务器也可以在客户端发送所有请求之前决定完成。
取消 RPC
客户端或服务器都可以随时取消 RPC。取消会立即终止 RPC,以便不再进行任何工作。
Protocol buffer 语法参考
消息类型定义
以一个简单的请求消息为例:
syntax = "proto3";
message SearchRequest {
string query = 1;
int32 page_number = 2;
int32 result_per_page = 3;
}
首先指定版本 proto3,否则编译器默认为 proto2。版本指定为文件的第一非空白、非注释行。
message 关键字用于定义消息,需要指定消息类型的名称。
消息由多个名称/值对组成,称为字段,每个字段要指定名字和类型。string、int32 是典型的标量类型,除了标量类型 protobuf 还支持构造类型,例如枚举或其他消息类型。
应该为每个字段分配唯一的字段序号,用于在二进制编码中标识该字段。序号范围1-15会消耗1个字节的存储,16-2047 会消耗2个字节。因此应该将常用的字段分配1-15字段序号。编号全部的范围是1到2^29-1,其中19000到19999是 proto编译器保留序号,不要使用。
消息的字段分为单一和重复两种规则:
-
单一 Singular,proto3 中字段的默认规则。一个消息中仅可以包含0或1个该字段,就是字段不能重复。
-
重复的 repeated,该规则说明此字段可以重复多次(包含0次)。重复值的顺序是保留的。
message SearchRequest {
// 同上略
repeated string keywords = 4
}
.proto 文件支持 C/C++ 风格的注释 // 和 /* ... */
标量类型
标量消息字段可以具有以下类型之一。该表显示了 .proto 文件中指定的类型,以及自动生成的类中的相应类型:
| .proto Type | 说明 | Go Type |
|---|---|---|
| double | float64 | |
| float | float32 | |
| int32 | 变长编码,对负数进行编码效率低下。若字段可能有负值,请改用 sint32 | int32 |
| int64 | 变长编码,对负数进行编码效率低下。若字段可能有负值,请改用 sint64 | int64 |
| uint32 | 变长编码 | uint32 |
| uint64 | 变长编码 | uint64 |
| sint32 | 变长编码,带符号的 int 值。这些比常规 int32 更有效地编码负数 | int32 |
| sint64 | 变长编码,带符号的 int 值。这些比常规 int64 更有效地编码负数 | int64 |
| fixed32 | 固定4个字节,如果值通常大于 2^28,则比 uint32 更有效 | uint32 |
| fixed64 | 固定8个字节,如果值通常大于 2^56,则比 uint64 更有效 | uint64 |
| sfixed32 | 固定4个字节 | int32 |
| sfixed64 | 固定8个字节 | int64 |
| bool | bool | |
| string | 始终包含 UTF-8 编码或 7 位 ASCII 文本,并且长度不能超过 2^32 | string |
| bytes | 可以包含不超过 2^32 的任意字节序列 | []byte |
解析消息时,如果编码的消息不包含特定元素,则解析对象中的相应字段将设置为该字段的默认值。这些默认值是基于类型的:
-
对于字符串,默认值为空字符串。
-
对于字节,默认值为空字节。
-
对于布尔值,默认值为 false。
-
对于数字类型,默认值为零。
-
对于枚举,默认值是第一个定义的枚举值,必须为 0。
-
对于消息字段,未设置该字段。它的确切值取决于语言。有关详细信息,请参阅生成的代码指南。
-
重复字段的默认值为空(通常是相应语言的空列表)。
枚举值
在定义消息类型时,您可能希望其字段之一仅具有预定义的值列表之一。例如,假设您要为每个 SearchRequest 添加一个 corpus 字段,其中值可以是 UNIVERSAL、WEB、IMAGES、LOCAL、NEWS、PRODUCTS 或 VIDEO。您可以通过在消息定义中添加一个枚举来非常简单地做到这一点,每个可能的值都有一个常量。
message SearchRequest {
// 同上略
enum Corpus {
UNIVERSAL = 0;
WEB = 1;
IMAGES = 2;
LOCAL = 3;
NEWS = 4;
PRODUCTS = 5;
VIDEO = 6;
}
Corpus corpus = 4;
}
枚举值列表的第一常量值必须为0,这样可以更好的处理默认值。(也为了向下兼容)
也可以为同一个枚举值分配不同的常量,称为别名。需要使用选项 option allow_alias = true 来启用别名设置:
message MyMessage1 {
enum EnumAllowingAlias {
option allow_alias = true;
UNKNOWN = 0;
STARTED = 1;
RUNNING = 1;
}
}
保留值
当某些字段不再使用时,例如更新消息类型时移除了某些字段,为了防止其他人重新使用了之前的字段名或字段序号而导致逻辑混乱的问题,可以把这些不用的字段设置为保留字段,关键字 reserved 用来设置:
enum Foo {
reserved 2, 15, 9 to 11, 40 to max;
reserved "FOO", "BAR";
}
这样,以上的序号和字段名就不能后续使用了,避免了逻辑混乱。
使用其他消息类型
可以使用其他消息类型作为字段类型。例如:
message SearchResponse {
repeated Result results = 1;
}
message Result {
string url = 1;
string title = 2;
repeated string snippets = 3;
}
可以将不同类型的消息定义在不同的 .proto 文件中,需要时导入进来:
import "myproject/other_protos.proto";
未知字段
未知字段是格式良好的 Protocol Buffer 序列化数据,表示解析器无法识别的字段。例如,当旧二进制文件用新字段解析新二进制文件发送的数据时,这些新字段将成为旧二进制文件中的未知字段。
最初,proto3 消息在解析过程中总是丢弃未知字段,但在 3.5 版本中,我们重新引入了保留未知字段以匹配 proto2 行为。在 3.5 及更高版本中,未知字段在解析期间保留并包含在序列化输出中。
Any
Any 消息类型允许您将消息用作嵌入类型,而无需定义它们的 .proto。 Any 包含作为 Bytes 的任意序列化消息,以及充当全局唯一标识符并解析为该消息类型的 URL。要使用 Any 类型,您需要导入 google/protobuf/any.proto。
import "google/protobuf/any.proto";
message ErrorStatus {
string message = 1;
repeated google.protobuf.Any details = 2;
}
Oneof
如果您有一条包含多个字段的消息,并且最多同时设置一个字段,您可以强制执行此行为并使用 oneof 功能节省内存。
message SampleMessage {
oneof test_oneof {
string name = 4;
SubMessage sub_message = 9;
}
}
Map
如果您想创建关联映射作为数据定义的一部分,protocol buffers 提供了一种方便的快捷语法:
map<key_type, value_type> map_field = N;
例如:
map<string, Project> projects = 3;
Packages
您可以将可选的 package 说明符添加到 .proto 文件中,以防止协议消息类型之间的名称冲突。
package foo.bar;
message Open { ... }
在 GO 中,该软件包被用作 GO 软件包名称,除非您在 .proto 文件中明确提供 option go_package。
服务定义
如果您想在 RPC(远程过程调用)系统中使用您的消息类型,您可以在 .proto 文件中定义一个 RPC 服务接口,并且协议缓冲区编译器将以您选择的语言生成服务接口代码和存根。因此,例如,如果您想使用获取 SearchRequest 并返回 SearchResponse 的方法定义 RPC 服务,您可以在 .proto 文件中定义它,如下所示:
service SearchService {
rpc Search(SearchRequest) returns (SearchResponse);
}
与 Proto Buffers 一起使用的最直接的 RPC 系统是 gRPC:由 Google 开发的一种语言和平台中立的开源 RPC 系统。 gRPC 特别适用于协议缓冲区,并允许您使用特殊的协议缓冲区编译器插件直接从 .proto 文件生成相关的 RPC 代码。
选项
.proto 文件中支持定义选项。全部的选项定义在 google/protobuf/descriptor.proto 中。
例如我们使用 option go_package 选项来控制生成的 go 代码所在的 package。
Protocol buffer 语法指导
消息队列
事件驱动
API 网关
API 网关介绍
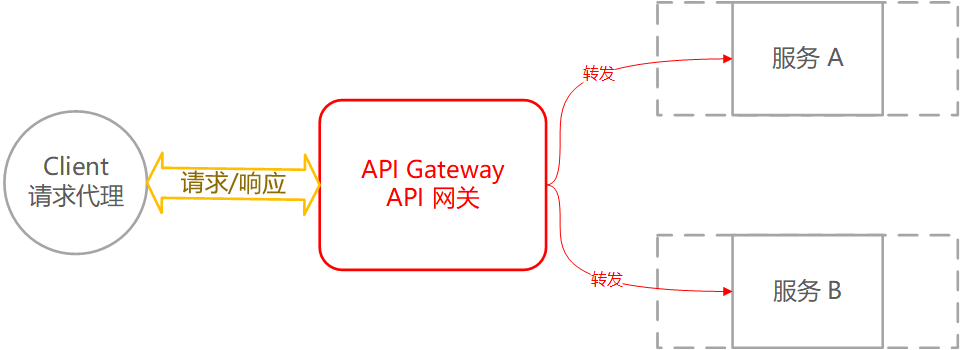
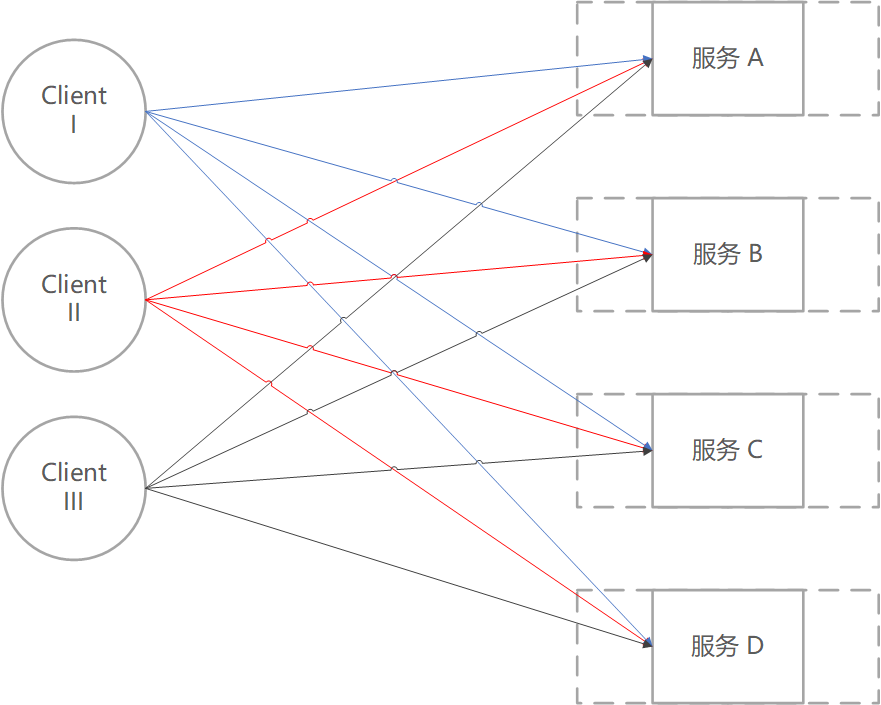
API 网关是客户端访问服务的统一入口,API 网关封装了后端服务。核心功能是转发请求,基于客户端请求的 Host、Method、Path 将请求转发到目标服务上。可以解决客户端直接访问后端服务的入口不统一的问题,尤其是在微服务时代,网关尤其重要,否则如下图所示:
现代的 API 网关,除了具备基本的转发功能外,通常还具有:
-
多协议支持:tcp,http、https、websock、gRPC
-
负载均衡
-
身份验证
-
监控、日志
-
缓存
-
熔断、限流
等核心功能。目前市场上比较知名的 API 网关有:
-
Netflix Zuul,spring cloud 的一个推荐组件,java 系首选
-
Kong 是基于Nginx+Lua 进行二次开发的实现,社区比较活跃
-
Tyk Go编写,社区版相对薄弱
Kong Gateway 介绍

The fastest, most-adopted API gateway is just the start.
以上是 Kong 官网的口号。最快、使用最多的 API 网关仅是个开始。
网址:Kong Docs
Kong 是一个可扩展的开源 API 平台(也称为 API 网关或 API 中间件)。Kong 最初由 Kong Inc.(以前称为 Mashape)构建,用于为其 API Marketplace 保护,管理和扩展超过15,000 个微服务,每月产生数十亿个请求。
在积极开发下,Kong 现在被用于数百个组织的生产,从初创公司到大型企业和政府,包括:纽约时报,Expedia,Healthcare.gov,卫报,康泰纳仕,奥克兰大学,法拉利,乐天,思科,SkyScanner,Yahoo!Japan,Giphy 等。
Kong 是一个在 Nginx 中运行的 Lua 应用程序,可以通过 lua-nginx 模块实现。但是 Kong 不是用这个模块编译 Nginx 的,而是与 OpenRestry 一起发布,OpenRestry 已经包含了 lua-nginx-module。OpenRestry 是Nginx 的一组扩展功能模块。
Github 上 Kong 很受欢迎:

其特性如下:
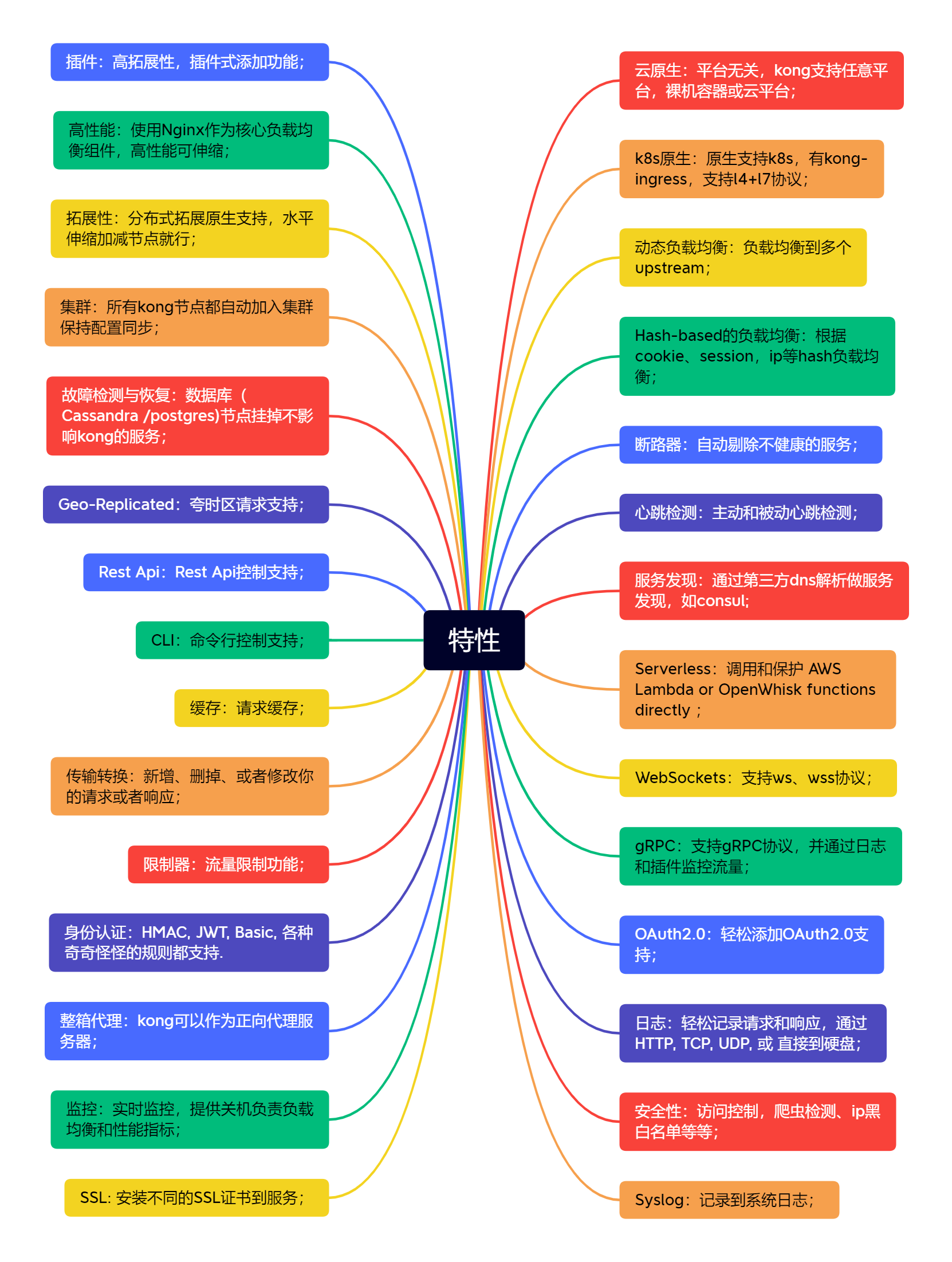
主要的说:
-
云原生:平台无关,支持任意平台,裸机容器或云平台
-
服务发现:通过第三方 DNS 解析做服务发现,如consul
-
各种协议支持:ws、wss、gRPC、HTTP、HTTPs、RestAPI
-
支持分布式集群部署、节点恢复等
-
支持多种负载均衡实现:Hash-Based(cookie、ip),多个 upstream
-
日志、监控
-
SSL 证书
-
支持多种认证机制:OAuth2.0、JWT、HMAC、Basic 等
-
性能高,基于 Nginx,支持缓存等
-
支持服务检测,心跳、断路、限流等
-
支持插件功能扩展
Kong Docker 方式安装运行
Kong Gateway 可以运行在数据库模式和无数据库模式下,区别是:
-
数据库模式:使用数据库存储 Kong 的配置,可以使用 Admin API 和 声明式配置文件来配置 Kong Gateway。
-
无数据库模式:Kong 的配置存储在内存中。只能使用声明式配置文件来配置 Kong,同时 Admin API 是只读的。
获取镜像:
sudo docker pull kong # OR sudo docker pull kong/kong-gateway
非数据库环境启动
推荐先创建配置文件:
~/kong/declarative/kong.yml
_format_version: "1.1"
_transform: true
services:
- host: mockbin.org
name: example_service
port: 80
protocol: http
routes:
- name: example_route
paths:
- /mock
strip_path: true
启动容器:
$ sudo docker run -it --rm --net=host --name kongDev \
-v ~/kong/declarative/:/kong/declarative/ \
-e "KONG_DECLARATIVE_CONFIG=/kong/declarative/kong.yml" \
-e "KONG_DATABASE=off" \
-e "KONG_PROXY_ACCESS_LOG=/dev/stdout" \
-e "KONG_ADMIN_ACCESS_LOG=/dev/stdout" \
-e "KONG_PROXY_ERROR_LOG=/dev/stderr" \
-e "KONG_ADMIN_ERROR_LOG=/dev/stderr" \
-e "KONG_DNS_RESOLVER=127.0.0.1:8600" \
-e "KONG_ADMIN_LISTEN=0.0.0.0:8001, 0.0.0.0:8444 ssl" \
-p 8000:8000 \
-p 8443:8443 \
-p 8001:8001 \
-p 8444:8444 \
kong
说明:
-
-e "KONG_DATABASE=off",无数据库 -
-e "KONG_PROXY_ACCESS_LOG=/dev/stdout",代理访问日志 -
-e "KONG_ADMIN_ACCESS_LOG=/dev/stdout",Admin 访问日志 -
-e "KONG_PROXY_ERROR_LOG=/dev/stderr",代理错误日志 -
-e "KONG_ADMIN_ERROR_LOG=/dev/stderr", Admin 错误日志 -
-e "KONG_DNS_RESOLVER=127.0.0.1:8600",DNS 解析服务器 -
-e "KONG_ADMIN_LISTEN=0.0.0.0:8001, 0.0.0.0:8444 ssl",Admin 监听 -
暴露端口,我们使用 --net=host 模式,可以忽略端口映射
测试:
# 首页信息 curl http://localhost:8001/ # 全部服务 curl http://localhost:8001/services
数据库环境启动(推荐)
当前支持 Cassandra 和 Postgres,推荐 Postgres。Cassandra 的支持会被 Kong 移除。
1.先启动 PostGreSQL 容器:
sudo docker pull postgres sudo docker run --rm -d --name kongDatabaseDev \ --net=host \ -p 5432:5432 \ -e "POSTGRES_USER=kong" \ -e "POSTGRES_DB=kong" \ -e "POSTGRES_PASSWORD=kong" \ postgres
说明:
-
-p 5432:5432,暴露 Postgres 默认端口,-net=host 模式忽略 -
-e "KONG_PG_HOST=localhost", 数据库信息,host、user、password -
-e "KONG_PG_USER=kong" -
"KONG_PG_PASSWORD=kong"
注意,本测试网络采用了 host,因此不需要暴露端口了,容器会忽略。
2.再初始化 Kong 数据库:
运行 migration bootstrap,用于完成基本数据结构的初始化工作。
sudo docker run --rm \ --net=host \ -e "KONG_DATABASE=postgres" \ -e "KONG_PG_HOST=localhost" \ -e "KONG_PG_USER=kong" \ -e "KONG_PG_PASSWORD=kong" \ kong kong migrations bootstrap
说明:
-
-e "KONG_DATABASE=postgres",postgres 数据库 -
-e "KONG_PG_HOST=localhost", 数据库信息,host、user、password -
-e "KONG_PG_USER=kong" -
"KONG_PG_PASSWORD=kong"
3.启动 Kong:
$ sudo docker run -it --rm --name kongDev \
--net=host \
-p 8000:8000 \
-p 8443:8443 \
-p 8001:8001 \
-p 8444:8444 \
-e "KONG_DATABASE=postgres" \
-e "KONG_PG_HOST=localhost" \
-e "KONG_PG_USER=kong" \
-e "KONG_PG_PASSWORD=kong" \
-e "KONG_PROXY_ACCESS_LOG=/dev/stdout" \
-e "KONG_ADMIN_ACCESS_LOG=/dev/stdout" \
-e "KONG_PROXY_ERROR_LOG=/dev/stderr" \
-e "KONG_ADMIN_ERROR_LOG=/dev/stderr" \
-e "KONG_DNS_RESOLVER=127.0.0.1:8600" \
-e "KONG_ADMIN_LISTEN=0.0.0.0:8001, 0.0.0.0:8444 ssl" \
kong
说明:
-
-e "KONG_DATABASE=postgres",postgres 数据库 -
-e "KONG_PG_HOST=localhost", 数据库信息,host、user、password -
-e "KONG_PG_USER=kong" -
"KONG_PG_PASSWORD=kong" -
-e "KONG_PROXY_ACCESS_LOG=/dev/stdout",代理访问日志 -
-e "KONG_ADMIN_ACCESS_LOG=/dev/stdout",Admin 访问日志 -
-e "KONG_PROXY_ERROR_LOG=/dev/stderr",代理错误日志 -
-e "KONG_ADMIN_ERROR_LOG=/dev/stderr", Admin 错误日志 -
-e "KONG_DNS_RESOLVER=127.0.0.1:8600",DNS 解析服务器 -
-e "KONG_ADMIN_LISTEN=0.0.0.0:8001, 0.0.0.0:8444 ssl",Admin 监听 -
暴露端口,我们使用 --net=host 模式,可以忽略端口映射
4.测试:
#首页信息 curl http://localhost:8001/ # 全部服务 curl http://localhost:8001/services
Kong 默认端口
-
8000: 用于监听 Client 的 HTTP 请求,通常会转发给某服务。 -
8001: Admin API 的 HTTP 监听端口。 -
8443: 用于监听 Client 的 HTTPS 请求,功能与 8000 类似。可以在配置中禁用。 -
8444: Admin API 的 HTTPS 监听端口。
Kong快速配置基于Consul的转发服务
利用 Kong 的 Admin API 来配置服务,完成对 product 服务的转发:
添加一个服务 service
kong 的服务,就是网关需要转发的目标。通过 Admin API (:8001) 可以完成:
curl -i -X POST \ --url http://localhost:8001/services/ \ --data 'name=product-service' \ --data 'url=http://product.service.consul'
Response:
HTTP/1.1 201 Created
Content-Type: application/json
Connection: keep-alive
{
"id": "c6b7d155-bb2e-4f5f-8dc8-20ebcb255316",
"name": "product-service",
"tags": null,
"ca_certificates": null,
"host": "product.service.consul",
"protocol": "http",
"enabled": true,
"retries": 5,
"created_at": 1657524752,
"updated_at": 1657524752,
"port": 80,
"client_certificate": null,
"connect_timeout": 60000,
"tls_verify_depth": null,
"write_timeout": 60000,
"path": null,
"tls_verify": null,
"read_timeout": 60000
}
添加一个路由 route
kong 的路由,是用来解析客户端请求,并进行转发的,转发的目标就是上面所定义的服务。
curl -i -X POST \ --url http://localhost:8001/services/product-service/routes \ --data 'paths[]=/product'
Response:
HTTP/1.1 201 Created
Content-Type: application/json
Connection: keep-alive
{
"id": "a0973810-9e03-4a7e-9fb8-aba7a4751bb8",
"name": null,
"tags": null,
"regex_priority": 0,
"hosts": null,
"headers": null,
"request_buffering": true,
"response_buffering": true,
"paths": [
"/product"
],
"methods": null,
"sources": null,
"created_at": 1657525072,
"updated_at": 1657525072,
"preserve_host": false,
"path_handling": "v0",
"service": {
"id": "c6b7d155-bb2e-4f5f-8dc8-20ebcb255316"
},
"strip_path": true,
"https_redirect_status_code": 426,
"snis": null,
"destinations": null,
"protocols": [
"http",
"https"
]
}
启动 consul 服务中心,注册 product 服务
(参考服务发现章节)
sudo docker run --rm -it \ --net host \ -p 8500:8500 \ -p 8600:8600 \ --name consulDev \ consul agent -dev -client=0.0.0.0
注册多个product服务:
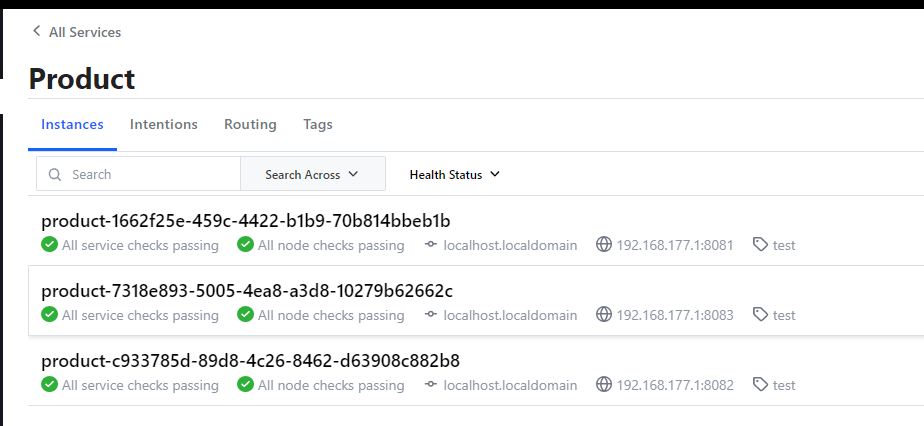
转发测试
请求:
curl -i -X GET \ --url http://localhost:8000/product/info
响应应该与:
curl -i -X GET \ --url http://product.service.consul/info # 或 curl -i -X GET \ --url http://localhost:8081/info
一致。
我们存在多个 product 服务,同时 DNS 支持 Random 负载均衡,因此可以负载到不同的 product 服务上。
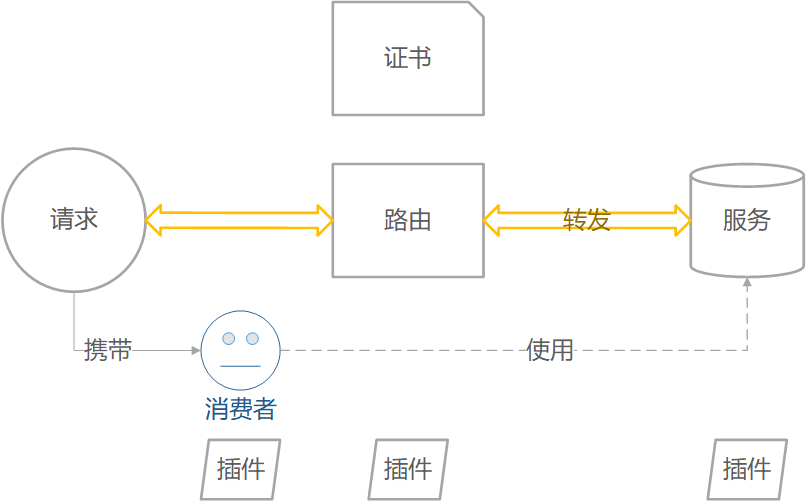
Kong 核心对象
-
Service,服务,后端某服务
-
Route,路由,接收前端请求
-
Consumer,消费者,服务的使用者
-
Plugin,插件,附加在消费者、路由、服务上的扩展功能
-
Certificate,证书
-
SNI,服务器名称指示
-
Upstream,虚拟主机名,可用于通过多个服务(目标)对传入请求进行负载均衡
-
Target,目标IP地址/主机名,其端口表示后端服务的实例。每个 upstream 都可以有多个target,支持负载均衡。
对应关系:
-
service : route -> 1 : n
-
service, route, consumer : plugin -> 1 : n
-
service : upstream -> 1 : 1
-
upstream : target -> 1 : n
全部的对象支持 Admin API 管理,同时 API 为 Restful 风格。
Kong 管理 Consumer
Consumer 对象代表服务的消费者或用户。您可以依赖 Kong 作为主数据存储,也可以将使用者列表与数据库映射,以保持 Kong 和现有主数据存储之间的一致性。
消费者可以被标签标记和过滤。
Consumer 结构:
{
"id": "ec1a1f6f-2aa4-4e58-93ff-b56368f19b27",
"created_at": 1422386534,
"username": "my-username",
"custom_id": "my-custom-id",
"tags": ["user-level", "low-priority"]
}
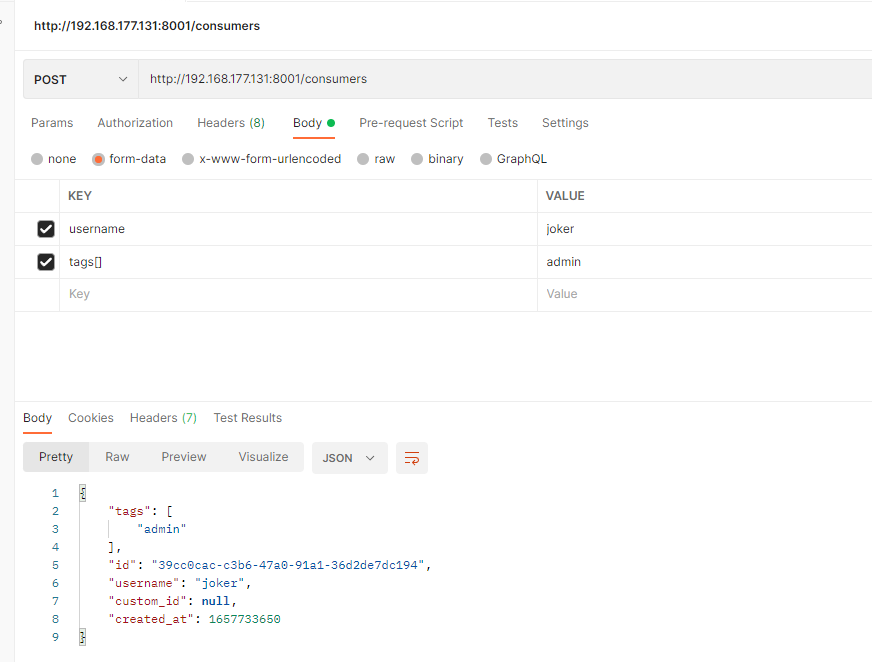
添加 Consumer
创建 Consumer
POST /consumers
请求主体
| ATTRIBUTES | DESCRIPTION |
|---|---|
username semi-optional | 消费者的唯一用户名。您必须随请求发送此字段或 custom_id。 |
custom_id semi-optional | 用于存储消费者现有唯一 ID 的字段 - 对于将 Kong 与现有数据库中的用户映射很有用。您必须随请求发送此字段或用户名。 |
tags optional | 与消费者关联的一组可选字符串,用于分组和过滤。 |
响应
HTTP 201 Created
{
"id": "ec1a1f6f-2aa4-4e58-93ff-b56368f19b27",
"created_at": 1422386534,
"username": "my-username",
"custom_id": "my-custom-id",
"tags": ["user-level", "low-priority"]
}
示例:
列出 Consumers
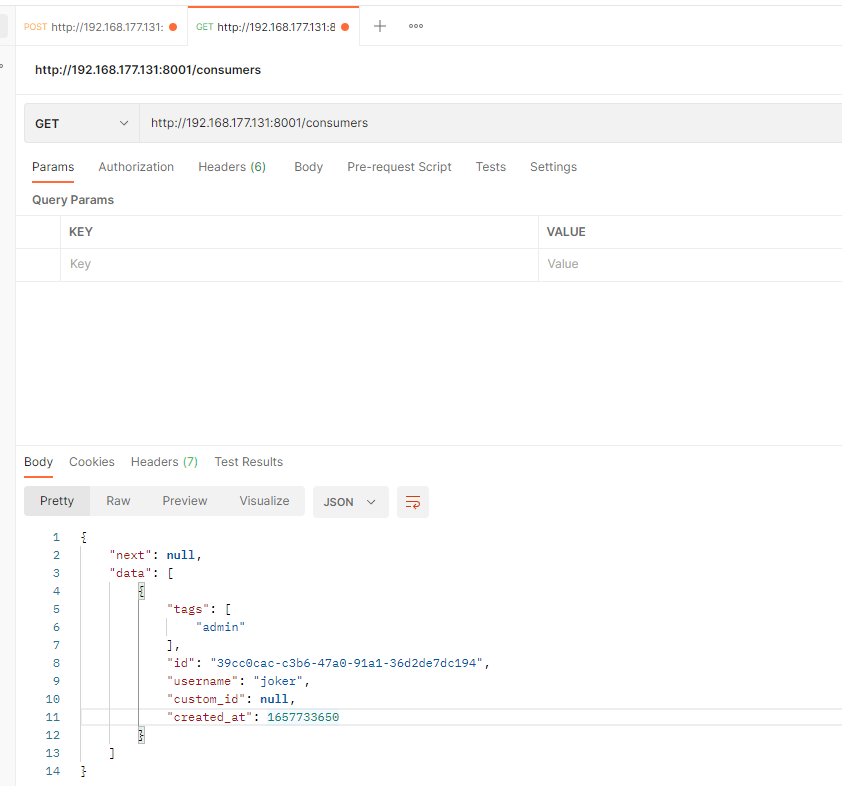
列出全部 Consumers
GET /consumers
响应
HTTP 200 OK
{
"data": [{
"id": "a4407883-c166-43fd-80ca-3ca035b0cdb7",
"created_at": 1422386534,
"username": "my-username",
"custom_id": "my-custom-id",
"tags": ["user-level", "low-priority"]
}],
"next": "http://localhost:8001/consumers?offset=6378122c-a0a1-438d-a5c6-efabae9fb969"
}
检索 Consumer
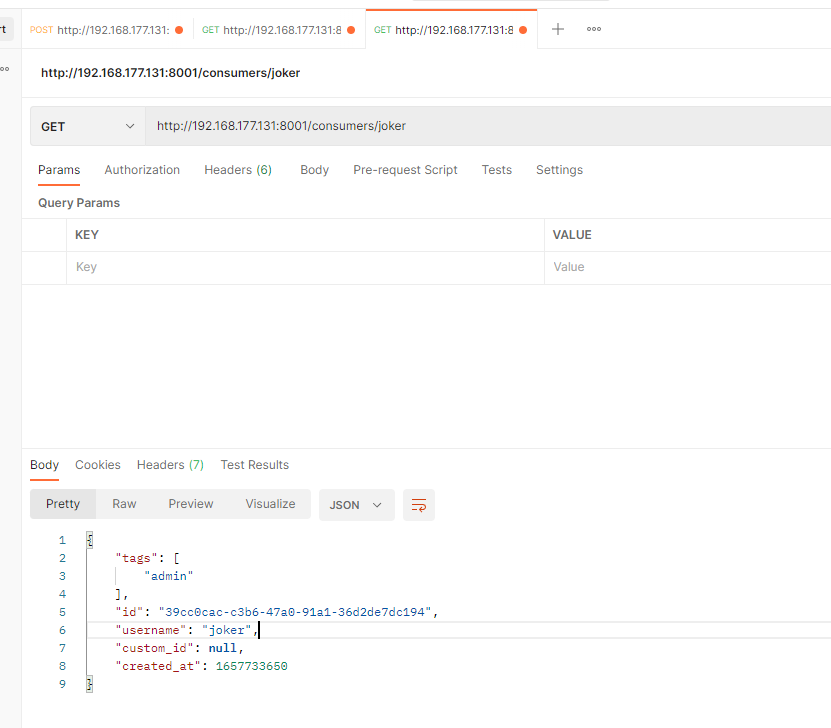
检索 Consumer
GET /consumers/{consumer username or id}
| ATTRIBUTES | DESCRIPTION |
|---|---|
consumer username or id required | 要检索的消费者的唯一标识符或用户名。 |
检索与特定 Plugin 关联的 Consumer
GET /plugins/{plugin id}/consumer
| ATTRIBUTES | DESCRIPTION |
|---|---|
plugin id required | 与要检索的消费者关联的插件的唯一标识符。 |
响应
HTTP 200 OK
{
"id": "ec1a1f6f-2aa4-4e58-93ff-b56368f19b27",
"created_at": 1422386534,
"username": "my-username",
"custom_id": "my-custom-id",
"tags": ["user-level", "low-priority"]
}
更新 Consumer
更新 Consumer
PATCH /consumers/{consumer username or id}
| ATTRIBUTES | DESCRIPTION |
|---|---|
consumer username or id required | 要检索的消费者的唯一标识符或用户名。 |
更新与特定 Plugin 关联的 Consumer
PATCH /plugins/{plugin id}/consumer
| ATTRIBUTES | DESCRIPTION |
|---|---|
plugin id required | 与要检索的消费者关联的插件的唯一标识符。 |
请求主体与添加一致
响应
HTTP 200 OK
{
"id": "ec1a1f6f-2aa4-4e58-93ff-b56368f19b27",
"created_at": 1422386534,
"username": "my-username",
"custom_id": "my-custom-id",
"tags": ["user-level", "low-priority"]
}
更新或创建 Consumer
更新或创建 Consumer
PUT /consumers/{consumer username or id}
| ATTRIBUTES | DESCRIPTION |
|---|---|
consumer username or id required | 要检索的消费者的唯一标识符或用户名。 |
更新或创建与特定 Plugin 关联的 Consumer
PUT /plugins/{plugin id}/consumer
| ATTRIBUTES | DESCRIPTION |
|---|---|
plugin id required | 与要检索的消费者关联的插件的唯一标识符。 |
请求主体与添加一致
响应
HTTP 201 Created or HTTP 200 OK
{
"id": "ec1a1f6f-2aa4-4e58-93ff-b56368f19b27",
"created_at": 1422386534,
"username": "my-username",
"custom_id": "my-custom-id",
"tags": ["user-level", "low-priority"]
}
删除 Consumer
删除 Consumer
DELETE /consumers/{consumer username or id}
| ATTRIBUTES | DESCRIPTION |
|---|---|
consumer username or id required | 要删除的消费者的唯一标识符或用户名。 |
Kong 管理 Service
顾名思义,服务实体是您自己的每个 upstream 服务的抽象。服务的示例可能是数据转换微服务、计费 API 等。
Service 的主要属性是它的 URL(Kong 应该将流量代理到的地方),可以将其设置为单个字符串或通过单独指定其 protocol、host、port 和 path。
服务与路由相关联(一个服务可以有许多与之关联的路由)。路由是 Kong 的入口点,定义了匹配客户端请求的规则。一旦路由匹配,Kong 将请求代理到其关联的服务。
服务可以通过标签进行标记和过滤。
以下是一个 Service 的结构示例:
{
"id": "9748f662-7711-4a90-8186-dc02f10eb0f5",
"created_at": 1422386534,
"updated_at": 1422386534,
"name": "my-service",
"retries": 5,
"protocol": "http",
"host": "example.com",
"port": 80,
"path": "/some_api",
"connect_timeout": 60000,
"write_timeout": 60000,
"read_timeout": 60000,
"tags": ["user-level", "low-priority"],
"client_certificate": {"id":"4e3ad2e4-0bc4-4638-8e34-c84a417ba39b"},
"tls_verify": true,
"tls_verify_depth": null,
"ca_certificates": ["4e3ad2e4-0bc4-4638-8e34-c84a417ba39b", "51e77dc2-8f3e-4afa-9d0e-0e3bbbcfd515"],
"enabled": true
}
注意,url 不是服务的属性,url 被拆解成 protocol、host、port 和 path。
添加服务
创建服务:
POST /services
创建与特定证书关联的服务:
POST /certificates/{certificate name or id}/services
请求主体:
| 属性 | 说明 |
|---|---|
name 可选 | 服务名 |
retries 可选 | 代理失败时重试执行的次数。默认值:5。 |
protocol | 用于与upstream通信的协议。接受的值为:“grpc”、“grpcs”、“http”、“https”、“tcp”、“tls”、“tls_passthrough”、“udp”。默认值:“http”。 |
host | upstream服务器的主机。请注意,主机值区分大小写。 |
port | upstream服务器端口。默认值:80。 |
path 可选 | 在对upstream服务器的请求中使用的路径。 |
connect_timeout 可选 | 与upstream服务器建立连接的超时时间(以毫秒为单位)。默认值:60000。 |
write_timeout 可选 | 将请求传输到upstream服务器的两次连续写入操作之间的超时时间(以毫秒为单位)。默认值:60000。 |
read_timeout 可选 | 将请求传输到upstream服务器的两次连续读取操作之间的超时时间(以毫秒为单位)。默认值:60000。 |
tags 可选 | 与服务关联的一组可选字符串,用于分组和过滤。 |
client_certificate 可选 | 在与upstream服务器进行 TLS 握手时用作客户端证书的证书。对于表单编码,表示法是 client_certificate.id=<client_certificate id>。对于 JSON,请使用“"client_certificate":{"id":"<client_certificate id>"}。 |
tls_verify 可选 | 是否启用upstream服务器 TLS 证书的验证。如果设置为 null,则遵循 Nginx 默认值。 |
tls_verify_depth 可选 | 验证upstream服务器的 TLS 证书时的最大链深度。如果设置为 null,则遵循 Nginx 默认值。默认值:null。 |
ca_certificates 可选 | CA 证书对象 UUID 数组,用于在验证upstream服务器的 TLS 证书时构建信任库。如果在遵守 Nginx 默认值时设置为 null。如果未指定 Nginx 中的默认 CA 列表并启用 TLS 验证,则与upstream服务器的握手将始终失败(因为没有 CA 是可信的)。对于表单编码,表示法是 ca_certificates[]=4e3ad2e4-0bc4-4638-8e34-c84a417ba39b&ca_certificates[]=51e77dc2-8f3e-4afa-9d0e-0e3bbbcfd515。对于 JSON,使用数组。 |
enabled | 服务是否处于活动状态。如果设置为 false,代理行为将就好像任何附加到它的路由都不存在 (404)。默认值:true。默认值:true。 |
url shorthand-attribute | 一次设置协议、主机、端口和路径的简写属性。此属性是只写的(Admin API 从不返回 URL)。 |
响应
HTTP 201 Created
{
"id": "9748f662-7711-4a90-8186-dc02f10eb0f5",
"created_at": 1422386534,
"updated_at": 1422386534,
"name": "my-service",
"retries": 5,
"protocol": "http",
"host": "example.com",
"port": 80,
"path": "/some_api",
"connect_timeout": 60000,
"write_timeout": 60000,
"read_timeout": 60000,
"tags": ["user-level", "low-priority"],
"client_certificate": {"id":"4e3ad2e4-0bc4-4638-8e34-c84a417ba39b"},
"tls_verify": true,
"tls_verify_depth": null,
"ca_certificates": ["4e3ad2e4-0bc4-4638-8e34-c84a417ba39b", "51e77dc2-8f3e-4afa-9d0e-0e3bbbcfd515"],
"enabled": true
}
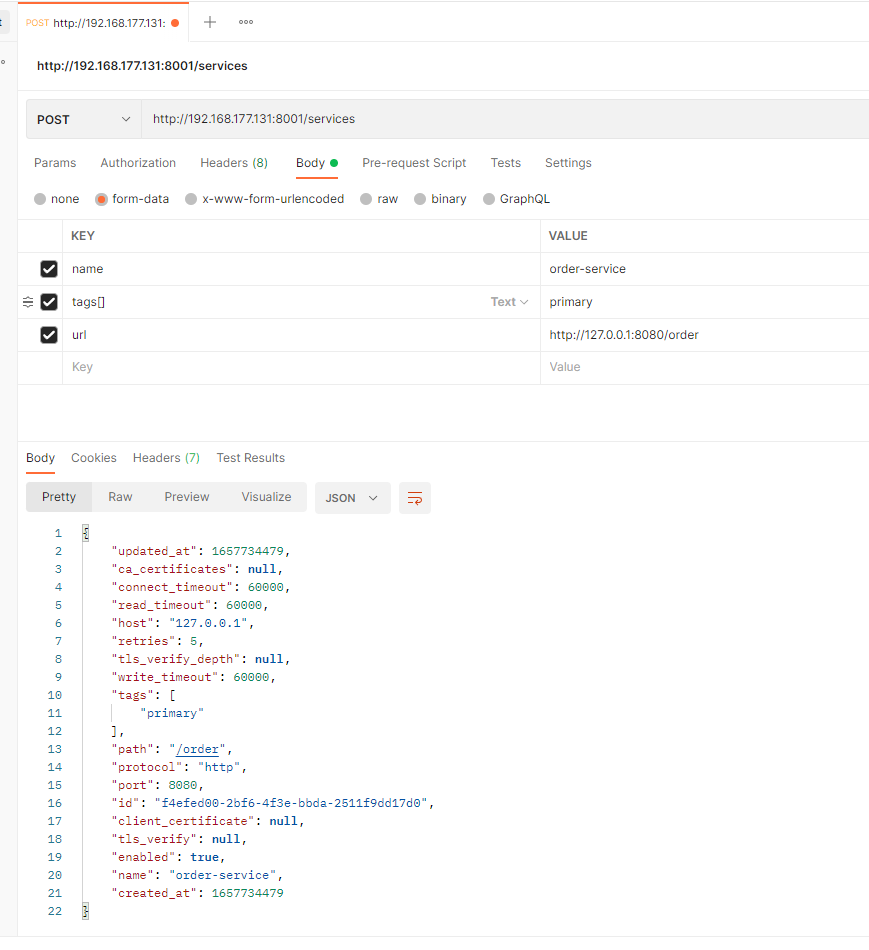
列出服务
列出全部服务
GET /services
列出与特定证书关联的服务
/certificates/{certificate name or id}/services
响应
HTTP 200 OK
{
"data": [{
"id": "a5fb8d9b-a99d-40e9-9d35-72d42a62d83a",
"created_at": 1422386534,
"updated_at": 1422386534,
"name": "my-service",
"retries": 5,
"protocol": "http",
"host": "example.com",
"port": 80,
"path": "/some_api",
"connect_timeout": 60000,
"write_timeout": 60000,
"read_timeout": 60000,
"tags": ["user-level", "low-priority"],
"client_certificate": {"id":"51e77dc2-8f3e-4afa-9d0e-0e3bbbcfd515"},
"tls_verify": true,
"tls_verify_depth": null,
"ca_certificates": ["4e3ad2e4-0bc4-4638-8e34-c84a417ba39b", "51e77dc2-8f3e-4afa-9d0e-0e3bbbcfd515"],
"enabled": true
}, {
"id": "fc73f2af-890d-4f9b-8363-af8945001f7f",
"created_at": 1422386534,
"updated_at": 1422386534,
"name": "my-service",
"retries": 5,
"protocol": "http",
"host": "example.com",
"port": 80,
"path": "/another_api",
"connect_timeout": 60000,
"write_timeout": 60000,
"read_timeout": 60000,
"tags": ["admin", "high-priority", "critical"],
"client_certificate": {"id":"4506673d-c825-444c-a25b-602e3c2ec16e"},
"tls_verify": true,
"tls_verify_depth": null,
"ca_certificates": ["4e3ad2e4-0bc4-4638-8e34-c84a417ba39b", "51e77dc2-8f3e-4afa-9d0e-0e3bbbcfd515"],
"enabled": true
}],
"next": "http://localhost:8001/services?offset=6378122c-a0a1-438d-a5c6-efabae9fb969"
}
检索服务
检索服务
GET /services/{service name or id}
| ATTRIBUTES | DESCRIPTION |
|---|---|
service name or id 必选 | 要检索的服务的唯一标识符或名称。 |
检索与特定证书关联的服务
GET /certificates/{certificate id}/services/{service name or id}
| ATTRIBUTES | DESCRIPTION |
|---|---|
certificate id 必选 | 要检索的证书的唯一标识符。 |
service name or id 必选 | 要检索的服务的唯一标识符或名称。 |
检索与特定路由关联的服务
GET /routes/{route name or id}/service
| ATTRIBUTES | DESCRIPTION |
|---|---|
route name or id 必选 | 与要检索的服务关联的路由的唯一标识符或名称。 |
检索与特定插件关联的服务
GET /plugins/{plugin id}/service
| ATTRIBUTES | DESCRIPTION |
|---|---|
plugin id 必选 | 与要检索的服务关联的插件的唯一标识符。 |
响应
HTTP 200 OK
{
"id": "9748f662-7711-4a90-8186-dc02f10eb0f5",
"created_at": 1422386534,
"updated_at": 1422386534,
"name": "my-service",
"retries": 5,
"protocol": "http",
"host": "example.com",
"port": 80,
"path": "/some_api",
"connect_timeout": 60000,
"write_timeout": 60000,
"read_timeout": 60000,
"tags": ["user-level", "low-priority"],
"client_certificate": {"id":"4e3ad2e4-0bc4-4638-8e34-c84a417ba39b"},
"tls_verify": true,
"tls_verify_depth": null,
"ca_certificates": ["4e3ad2e4-0bc4-4638-8e34-c84a417ba39b", "51e77dc2-8f3e-4afa-9d0e-0e3bbbcfd515"],
"enabled": true
}
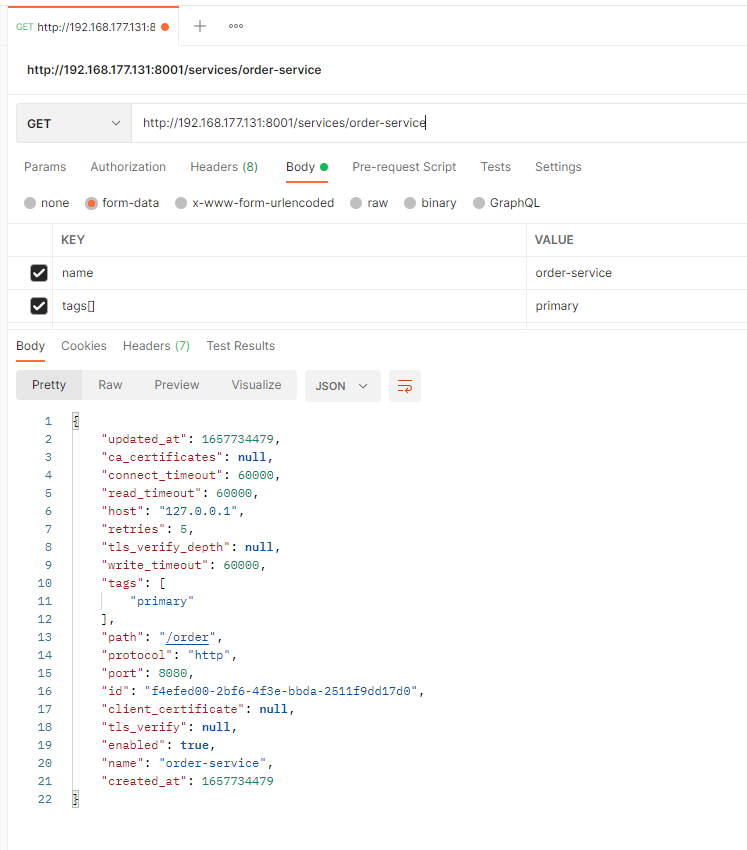
更新服务
更新服务
PATCH /services/{service name or id}
| ATTRIBUTES | DESCRIPTION |
|---|---|
service name or id 必选 | 要更新的服务的唯一标识符或名称。 |
更新与特定证书关联的服务
PATCH /certificates/{certificate id}/services/{service name or id}
| ATTRIBUTES | DESCRIPTION |
|---|---|
certificate id 必选 | 要更新的证书的唯一标识符。 |
service name or id 必选 | 要更新的服务的唯一标识符或名称。 |
更新与特定路由关联的服务
PATCH /routes/{route name or id}/service
| ATTRIBUTES | DESCRIPTION |
|---|---|
route name or id 必选 | 与要更新的服务关联的路由的唯一标识符或名称。 |
更新与特定插件关联的服务
PATCH /plugins/{plugin id}/service
| ATTRIBUTES | DESCRIPTION |
|---|---|
plugin id 必选 | 与要更新的服务关联的插件的唯一标识符。 |
请求主体与添加一致
响应
HTTP 200 OK
{
"id": "9748f662-7711-4a90-8186-dc02f10eb0f5",
"created_at": 1422386534,
"updated_at": 1422386534,
"name": "my-service",
"retries": 5,
"protocol": "http",
"host": "example.com",
"port": 80,
"path": "/some_api",
"connect_timeout": 60000,
"write_timeout": 60000,
"read_timeout": 60000,
"tags": ["user-level", "low-priority"],
"client_certificate": {"id":"4e3ad2e4-0bc4-4638-8e34-c84a417ba39b"},
"tls_verify": true,
"tls_verify_depth": null,
"ca_certificates": ["4e3ad2e4-0bc4-4638-8e34-c84a417ba39b", "51e77dc2-8f3e-4afa-9d0e-0e3bbbcfd515"],
"enabled": true
}
更新或创建服务
创建或更新服务
PUT /services/{service name or id}
| ATTRIBUTES | DESCRIPTION |
|---|---|
service name or id 必选 | 要创建或更新的服务的唯一标识符或名称。 |
创建或更新与特定证书关联的服务
PATCH /certificates/{certificate id}/services/{service name or id}
| ATTRIBUTES | DESCRIPTION |
|---|---|
certificate id 必选 | 要更新的证书的唯一标识符。 |
service name or id 必选 | 要更新的服务的唯一标识符或名称。 |
创建或更新与特定路由关联的服务
PATCH /routes/{route name or id}/service
| ATTRIBUTES | DESCRIPTION |
|---|---|
route name or id 必选 | 与要更新的服务关联的路由的唯一标识符或名称。 |
创建或更新与特定插件关联的服务
PATCH /plugins/{plugin id}/service
| ATTRIBUTES | DESCRIPTION |
|---|---|
plugin id 必选 | 与要更新的服务关联的插件的唯一标识符。 |
请求主体与添加一致
使用正文中指定的定义在请求的资源下插入(或替换)服务。服务将通过名称或 id 属性进行标识。
当 name 或 id 属性具有 UUID 的结构时,被插入/替换的 Service 将由其 id 标识。否则,它将通过其名称来识别。
当创建一个没有指定 id 的新服务时(在 URL 和正文中都没有),那么它将自动生成。
请注意,不允许在 URL 中指定名称而在请求正文中指定不同的名称。
响应
HTTP 201 Created or HTTP 200 OK
删除服务
删除服务
DELETE /services/{service name or id}
| ATTRIBUTES | DESCRIPTION |
|---|---|
service name or id 必选 | 要创建或更新的服务的唯一标识符或名称。 |
删除与特定证书关联的服务
DELETE /certificates/{certificate id}/services/{service name or id}
| ATTRIBUTES | DESCRIPTION |
|---|---|
certificate id 必选 | 要更新的证书的唯一标识符。 |
service name or id 必选 | 要更新的服务的唯一标识符或名称。 |
响应
HTTP 204 No Content
Kong 管理 Route
路由实体定义规则以匹配客户端请求。每个 Route 都与一个 Service 相关联,一个 Service 可能有多个 Route 与之关联。每个匹配给定路由的请求都将被代理到其关联的服务。
Routes 和 Services 的组合(以及它们之间的关注点分离)提供了一个强大的路由机制,通过它可以在 Kong 中定义细粒度的入口点,从而导致基础设施的不同upstream服务。
您至少需要一个匹配规则,该规则适用于路由匹配的协议。根据配置为由 Route 匹配的协议(由协议字段定义),这意味着必须至少设置以下属性之一:
-
对于 http,至少
methods,hosts,headersorpaths中的一个; -
对于 https,至少
methods,hosts,headers,pathsorsnis中的一个; -
对于 tcp,至少
sourcesordestinations中的一个; -
对于 tls,至少
sources,destinationsor snis 中的一个; -
对于 tls_passthrough,设置
snis; -
对于 grpc,至少
hosts,headersorpaths中的一个; -
对于 grpcs,至少
hosts,headers,pathsorsnis;
一条路由不能同时具有 tls 和 tls_passthrough 协议。
路径处理算法
“v0”是 Kong 0.x 和 2.x 中使用的行为。它将 service.path、route.path 和请求路径视为 URL 的片段。它总是通过斜杠加入它们。给定服务路径 /s、路由路径 /r 和请求路径 /re,连接的路径将是 /s/re。如果生成的路径是单斜杠,则不会对其进行进一步的转换。如果它更长,则删除尾部斜杠。
“v1”是 Kong 1.x 中使用的行为。它将 service.path 视为前缀,并忽略请求和路由路径的初始斜线。给定服务路径 /s、路由路径 /r 和请求路径 /re,连接的路径将是 /sre。
两个版本的算法在组合路径时检测“双斜杠”,用单斜杠替换它们。
下表显示了路径处理版本、条带路径和请求的可能组合:
SERVICE.PATH | ROUTE.PATH | REQUEST | ROUTE.STRIP_PATH | ROUTE.PATH_HANDLING | REQUEST PATH | UPSTREAM PATH |
|---|---|---|---|---|---|---|
/s | /fv0 | req | false | v0 | /fv0/req | /s/fv0/req |
/s | /fv0 | blank | false | v0 | /fv0 | /s/fv0 |
/s | /fv1 | req | false | v1 | /fv1/req | /sfv1/req |
/s | /fv1 | blank | false | v1 | /fv1 | /sfv1 |
/s | /tv0 | req | true | v0 | /tv0/req | /s/req |
/s | /tv0 | blank | true | v0 | /tv0 | /s |
/s | /tv1 | req | true | v1 | /tv1/req | /s/req |
/s | /tv1 | blank | true | v1 | /tv1 | /s |
/s | /fv0/ | req | false | v0 | /fv0/req | /s/fv0/req |
/s | /fv0/ | blank | false | v0 | /fv0/ | /s/fv01/ |
/s | /fv1/ | req | false | v1 | /fv1/req | /sfv1/req |
/s | /fv1/ | blank | false | v1 | /fv1/ | /sfv1/ |
/s | /tv0/ | req | true | v0 | /tv0/req | /s/req |
/s | /tv0/ | blank | true | v0 | /tv0/ | /s/ |
/s | /tv1/ | req | true | v1 | /tv1/req | /sreq |
/s | /tv1/ | blank | true | v1 | /tv1/ | /s |
路由既可以被标记也可以被标记过滤。
路由对象的属性:
{
"id": "d35165e2-d03e-461a-bdeb-dad0a112abfe",
"created_at": 1422386534,
"updated_at": 1422386534,
"name": "my-route",
"protocols": ["http", "https"],
"methods": ["GET", "POST"],
"hosts": ["example.com", "foo.test"],
"paths": ["/foo", "/bar"],
"headers": {"x-another-header":["bla"], "x-my-header":["foo", "bar"]},
"https_redirect_status_code": 426,
"regex_priority": 0,
"strip_path": true,
"path_handling": "v0",
"preserve_host": false,
"request_buffering": true,
"response_buffering": true,
"tags": ["user-level", "low-priority"],
"service": {"id":"af8330d3-dbdc-48bd-b1be-55b98608834b"}
}
添加路由
创建路线
POST /routes
创建与特定服务关联的路由
POST /services/{service name or id}/routes
| ATTRIBUTES | DESCRIPTION |
|---|---|
service name or id required | 应该与新创建的路由相关联的服务的唯一标识符或 name 属性。 |
请求主体
| ATTRIBUTES | DESCRIPTION |
|---|---|
name 可选 | 路线的名称。路由名称必须是唯一的,并且区分大小写。例如,可以有两个不同的路由,分别命名为“test”和“Test”。 |
protocols | 此路由应允许的协议数组。当设置为仅 “https” 时,HTTP 请求会以升级错误得到响应。当设置为仅 “http” 时,HTTPS 请求会得到错误响应。默认值:["http", "https"]。 |
methods 半可选 | 与此路由匹配的 HTTP 方法列表。 |
hosts semi-optional | 与此路由匹配的域名列表。请注意,主机值区分大小写。对于表单编码,表示法是 hosts[]=example.com&hosts[]=foo.test。对于 JSON,使用数组。 |
paths semi-optional | 与此路由匹配的 path 列表。对于表单编码,表示法是路径 []=/foo&paths[]=/bar。对于 JSON,使用数组。 |
headers semi-optional | 一个或多个由标头名称索引的值列表,如果存在于请求中,将导致此 Route 匹配。Host 标头不能与此属性一起使用:应使用 hosts 属性指定主机。 |
https_redirect_status_code | 当 Route 的所有属性除协议外都匹配时,即请求的协议是 HTTP 而不是 HTTPS,Kong 响应的状态码 。如果字段设置为 301、302、307 或 308,则 Location标头由 Kong 注入。接受的值为:426、301、302、307、308。默认值:426。 |
regex_priority optional | 当多个路由同时使用正则表达式匹配给定请求时,用于选择哪个路由解析给定请求的数字。当两条路由匹配路径并具有相同的 regex_priority 时,使用较旧的(最低 created_at)。请注意,非正则表达式路由的优先级不同(较长的非正则表达式路由在较短的路由之前匹配)。默认值:0。 |
strip_path | 通过其中一个 path 匹配 Route 时,从upstream请求 URL 中去除匹配的前缀。默认值:true。 |
path_handling optional | 控制向upstream发送请求时如何组合服务路径、路由路径和请求路径。有关每种行为的详细说明,请参见上文。可接受的值为:“v0”、“v1”。默认值:“v0”。 |
preserve_host | 通过 host 域名之一匹配路由时,在upstream请求标头中使用请求主机标头。如果设置为 false,则 upstream Host 标头将是 service 的 host 的标头。 |
request_buffering | 是否启用请求正文缓冲。在 HTTP 1.1 中,在使用分块传输编码接收数据的服务上关闭此功能可能是有意义的。默认值:true。 |
response_buffering | 是否启用响应正文缓冲。对于 HTTP 1.1,在使用分块传输编码发送数据的服务上关闭此功能可能是有意义的。默认值:true。 |
snis semi-optional | 使用流路由时匹配此路由的 SNI 列表。 |
sources semi-optional | 使用流路由时与此路由匹配的传入连接的 IP 源列表。每个条目都是一个具有“ip”(可选地以 CIDR 范围表示法)和/或“端口”字段的对象。 |
destinations semi-optional | A list of IP destinations of incoming connections that match this Route when using stream routing. Each entry is an object with fields “ip” (optionally in CIDR range notation) and/or “port”. |
tags optional | 与路由关联的一组可选字符串,用于分组和过滤。 |
service optional | 此路由关联的服务。这是 Route 代理流量的地方。对于表单编码,表示法是 service.id=<service id> 或 service.name=<service name>。对于 JSON,使用 “"service":{"id":"<service id>"} 或 "service":{"name":"<service name>"}。 |
响应
HTTP 201 Created
{
"id": "d35165e2-d03e-461a-bdeb-dad0a112abfe",
"created_at": 1422386534,
"updated_at": 1422386534,
"name": "my-route",
"protocols": ["http", "https"],
"methods": ["GET", "POST"],
"hosts": ["example.com", "foo.test"],
"paths": ["/foo", "/bar"],
"headers": {"x-another-header":["bla"], "x-my-header":["foo", "bar"]},
"https_redirect_status_code": 426,
"regex_priority": 0,
"strip_path": true,
"path_handling": "v0",
"preserve_host": false,
"request_buffering": true,
"response_buffering": true,
"tags": ["user-level", "low-priority"],
"service": {"id":"af8330d3-dbdc-48bd-b1be-55b98608834b"}
}
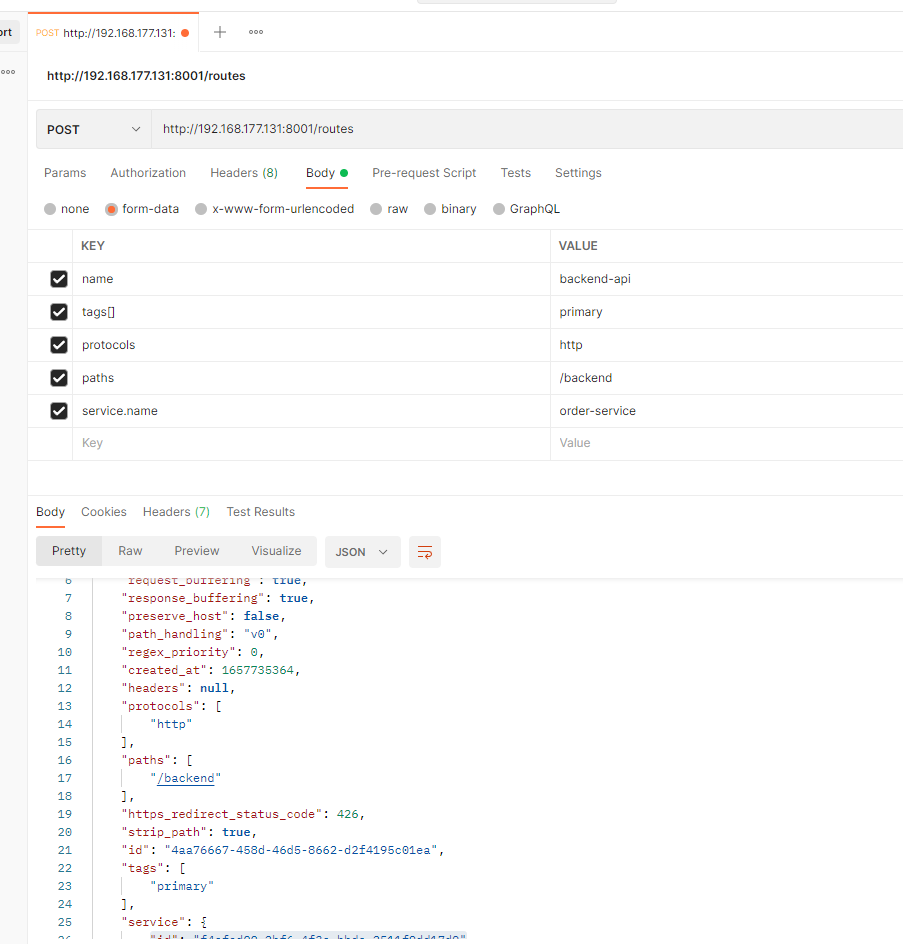
列出路由
列出全部路由
GET /routes
列出与特定服务关联的路由
GET /services/{service name or id}/routes
| ATTRIBUTES | DESCRIPTION |
|---|---|
service name or id required | 要检索其路由的服务的唯一标识符或 name属性。使用此端点时,只会列出与指定服务关联的路由。 |
响应
HTTP 200 OK
{
"data": [{
"id": "a9daa3ba-8186-4a0d-96e8-00d80ce7240b",
"created_at": 1422386534,
"updated_at": 1422386534,
"name": "my-route",
"protocols": ["http", "https"],
"methods": ["GET", "POST"],
"hosts": ["example.com", "foo.test"],
"paths": ["/foo", "/bar"],
"headers": {"x-another-header":["bla"], "x-my-header":["foo", "bar"]},
"https_redirect_status_code": 426,
"regex_priority": 0,
"strip_path": true,
"path_handling": "v0",
"preserve_host": false,
"request_buffering": true,
"response_buffering": true,
"tags": ["user-level", "low-priority"],
"service": {"id":"127dfc88-ed57-45bf-b77a-a9d3a152ad31"}
}],
"next": "http://localhost:8001/routes?offset=6378122c-a0a1-438d-a5c6-efabae9fb969"
}
检索路由
检索路由
GET /routes/{route name or id}
| ATTRIBUTES | DESCRIPTION |
|---|---|
route name or id required | 要检索的 Route 的唯一标识符或名称。 |
检索与特定服务关联的路由
GET /services/{service name or id}/routes/{route name or id}
| ATTRIBUTES | DESCRIPTION |
|---|---|
service name or id required | 要检索的服务的唯一标识符或名称。 |
route name or id required | 要检索的 Route 的唯一标识符或名称。 |
检索与特定插件关联的路由
GET /plugins/{plugin id}/route
| ATTRIBUTES | DESCRIPTION |
|---|---|
plugin id required | 与要检索的路由关联的插件的唯一标识符。 |
响应
HTTP 200 OK
{
"id": "d35165e2-d03e-461a-bdeb-dad0a112abfe",
"created_at": 1422386534,
"updated_at": 1422386534,
"name": "my-route",
"protocols": ["http", "https"],
"methods": ["GET", "POST"],
"hosts": ["example.com", "foo.test"],
"paths": ["/foo", "/bar"],
"headers": {"x-another-header":["bla"], "x-my-header":["foo", "bar"]},
"https_redirect_status_code": 426,
"regex_priority": 0,
"strip_path": true,
"path_handling": "v0",
"preserve_host": false,
"request_buffering": true,
"response_buffering": true,
"tags": ["user-level", "low-priority"],
"service": {"id":"af8330d3-dbdc-48bd-b1be-55b98608834b"}
}
更新路由
更新路由
PATCH /routes/{route name or id}
| ATTRIBUTES | DESCRIPTION |
|---|---|
route name or id required | 要更新的路由的唯一标识符或名称。 |
更新与特定服务关联的路由
PATCH /services/{service name or id}/routes/{route name or id}
| ATTRIBUTES | DESCRIPTION |
|---|---|
service name or id required | 要检索的服务的唯一标识符或名称。 |
route name or id required | 要检索的 Route 的唯一标识符或名称。 |
更新与特定插件关联的路由
PATCH /plugins/{plugin id}/route
| ATTRIBUTES | DESCRIPTION |
|---|---|
plugin id required | 与要检索的路由关联的插件的唯一标识符。 |
请求主体与添加路由一致
响应
HTTP 200 OK
{
"id": "d35165e2-d03e-461a-bdeb-dad0a112abfe",
"created_at": 1422386534,
"updated_at": 1422386534,
"name": "my-route",
"protocols": ["http", "https"],
"methods": ["GET", "POST"],
"hosts": ["example.com", "foo.test"],
"paths": ["/foo", "/bar"],
"headers": {"x-another-header":["bla"], "x-my-header":["foo", "bar"]},
"https_redirect_status_code": 426,
"regex_priority": 0,
"strip_path": true,
"path_handling": "v0",
"preserve_host": false,
"request_buffering": true,
"response_buffering": true,
"tags": ["user-level", "low-priority"],
"service": {"id":"af8330d3-dbdc-48bd-b1be-55b98608834b"}
}
更新或创建路由
更新或创建路由
PUT /routes/{route name or id}
| ATTRIBUTES | DESCRIPTION |
|---|---|
route name or id required | 要更新的路由的唯一标识符或名称。 |
更新或创建与特定服务关联的路由
PUT /services/{service name or id}/routes/{route name or id}
| ATTRIBUTES | DESCRIPTION |
|---|---|
service name or id required | 要检索的服务的唯一标识符或名称。 |
route name or id required | 要检索的 Route 的唯一标识符或名称。 |
更新或创建与特定插件关联的路由
PUT /plugins/{plugin id}/route
| ATTRIBUTES | DESCRIPTION |
|---|---|
plugin id required | 与要检索的路由关联的插件的唯一标识符。 |
请求主体与添加路由一致
使用正文中指定的定义插入(或替换)请求资源下的 Route。 Route 将通过 name 或 id 属性来标识。
当 name 或 id 属性具有 UUID 的结构时,被插入/替换的 Route 将由其 id 标识。否则,它将通过其名称来识别。
当创建一个没有指定 id 的新路由时(既不在 URL 也不在正文中),那么它将自动生成。
请注意,不允许在 URL 中指定名称而在请求正文中指定不同的 name。
响应
HTTP 201 Created or HTTP 200 OK
删除路由
删除路由
DELETE /routes/{route name or id}
| ATTRIBUTES | DESCRIPTION |
|---|---|
route name or id required | 要更新的路由的唯一标识符或名称。 |
删除与特定服务关联的路由
DELETE /services/{service name or id}/routes/{route name or id}
| ATTRIBUTES | DESCRIPTION |
|---|---|
service name or id required | 要检索的服务的唯一标识符或名称。 |
route name or id required | 要检索的 Route 的唯一标识符或名称。 |
响应
HTTP 204 No Content
Kong 管理插件
插件实体表示将在 HTTP 请求/响应生命周期中执行的插件配置。这是您如何向在 Kong 后面运行的服务添加功能的方式,例如身份验证或速率限制。您可以通过访问 Kong Hub (Kong Plugin Hub | Kong Docs)找到有关如何安装以及每个插件所采用的值的更多信息。
将插件配置添加到服务时,客户端对该服务的每个请求都将运行该插件。如果插件需要针对某些特定的消费者调整为不同的值,您可以通过创建一个单独的插件实例来实现,该实例通过服务和消费者字段指定服务和消费者。
插件可以通过标签进行标记和过滤。
插件结构定义:
{
"id": "ce44eef5-41ed-47f6-baab-f725cecf98c7",
"name": "rate-limiting",
"created_at": 1422386534,
"rou
优先级
插件将始终运行一次,并且每个请求仅运行一次。但是它将运行的配置取决于它所配置的实体。
可以为各种实体、实体组合甚至全局配置插件。这很有用,例如,当您希望以某种方式为大多数请求配置插件,但使经过身份验证的请求的行为略有不同时。
因此,当插件应用于具有不同配置的不同实体时,存在运行插件的优先顺序。经验法则是:插件在配置多少实体方面越具体,它的优先级就越高。
多次配置插件时的完整优先顺序是:
-
在以下组合上配置的插件:Route、Service 和 Consumer。 (消费者表示请求必须经过身份验证)。
-
在 Route 和 Consumer 的组合上配置的插件。 (消费者表示请求必须经过身份验证)。
-
在服务和消费者的组合上配置的插件。 (消费者表示请求必须经过身份验证)。
-
在路由和服务的组合上配置的插件。
-
在消费者上配置的插件。 (消费者表示请求必须经过身份验证)。
-
在路由上配置的插件。
-
在服务上配置的插件。
-
配置为全局运行的插件。
示例:如果限速插件被应用了两次(使用不同的配置):对于服务(插件配置 A)和消费者(插件配置 B),那么验证此消费者的请求将运行插件配置 B 并忽略 A。但是,未对此使用者进行身份验证的请求将回退到运行插件配置 A。请注意,如果配置 B 被禁用(其启用标志设置为 false),则配置 A 将应用于本来与配置 B 匹配的请求。
添加插件
创建插件
POST /plugins
创建与特定路由关联的插件
POST /routes/{route name or id}/plugins
| ATTRIBUTES | DESCRIPTION |
|---|---|
route name or id required | 应该与新创建的插件关联的路由的唯一标识符或名称属性。 |
创建与特定服务关联的插件
POST /services/{service name or id}/plugins
| ATTRIBUTES | DESCRIPTION |
|---|---|
service name or id required | 应该与新创建的插件相关联的服务的唯一标识符或名称属性。 |
创建与特定消费者关联的插件
POST /consumers/{consumer name or id}/plugins
| ATTRIBUTES | DESCRIPTION |
|---|---|
consumer name or id required | 应该与新创建的插件相关联的消费者的唯一标识符或名称属性。 |
请求主体
| ATTRIBUTES | DESCRIPTION |
|---|---|
name | 要添加的插件的名称。目前,插件必须单独安装在每个 Kong 实例中。 |
route optional | 如果设置,插件将仅在通过属于指定服务的路由之一接收请求时激活。无论匹配的服务如何,都不要设置插件以激活。默认值:null。使用表单编码时,表示法是 service.id=<service id> 或 service.name=<service name>。对于 JSON,使用 “"service":{"id":"<service id>"} 或 "service":{"name":"<service name>"}。 |
service optional | 如果设置,插件将仅针对指定已通过身份验证的请求激活。 (请注意,某些插件不能以这种方式仅限于消费者。)。无论经过身份验证的消费者如何,都不要设置插件以激活。默认值:null。使用表单编码时,表示法是 consumer.id=<consumer id> 或 consumer.username=<consumer username>。对于 JSON,请使用 “"consumer":{"id":"<consumer id>"} 或 "consumer":{"username":"<consumer username>"}。 |
consumer optional | If set, the plugin will activate only for requests where the specified has been authenticated. (Note that some plugins can not be restricted to consumers this way.). Leave unset for the plugin to activate regardless of the authenticated Consumer. Default:null.With form-encoded, the notation is consumer.id=<consumer id> or consumer.username=<consumer username>. With JSON, use “"consumer":{"id":"<consumer id>"} or "consumer":{"username":"<consumer username>"}. |
config optional | 插件的配置属性可以在 Kong Hub 的插件文档页面上找到。 |
protocols | 将触发此插件的请求协议列表。默认值以及此字段允许的可能值可能会根据插件类型而改变。例如,仅在流模式下工作的插件将仅支持 “tcp”和 “tls”。默认值:[“grpc”、“grpcs”、“http”、“https”]。 |
enabled | 是否应用插件。默认值:true。 |
tags optional | 与插件关联的一组可选字符串,用于分组和过滤。 |
响应
HTTP 201 Created
{
"id": "ce44eef5-41ed-47f6-baab-f725cecf98c7",
"name": "rate-limiting",
"created_at": 1422386534,
"route": null,
"service": null,
"consumer": null,
"config": {"minute":20, "hour":500},
"protocols": ["http", "https"],
"enabled": true,
"tags": ["user-level", "low-priority"]
}
列出插件
列出全部插件
GET /plugins
列出与特定路由关联的插件
GET /routes/{route name or id}/plugins
| ATTRIBUTES | DESCRIPTION |
|---|---|
route name or id required | 要检索其插件的路由的唯一标识符或名称属性。使用此端点时,只会列出与指定路由关联的插件。 |
列出与特定服务关联的插件
GET /services/{route name or id}/plugins
| ATTRIBUTES | DESCRIPTION |
|---|---|
service name or id required | 要检索其插件的服务的唯一标识符或名称属性。使用此端点时,只会列出与指定服务关联的插件。 |
列出与特定消费者关联的插件
GET /consumers/{consumer name or id}/plugins
| ATTRIBUTES | DESCRIPTION |
|---|---|
consumer name or id required | 要检索其插件的消费者的唯一标识符或名称属性。使用此端点时,只会列出与指定使用者关联的插件。 |
响应
HTTP 200 OK
{
"data": [{
"id": "02621eee-8309-4bf6-b36b-a82017a5393e",
"name": "rate-limiting",
"created_at": 1422386534,
"route": null,
"service": null,
"consumer": null,
"config": {"minute":20, "hour":500},
"protocols": ["http", "https"],
"enabled": true,
"tags": ["user-level", "low-priority"]
}],
"next": "http://localhost:8001/plugins?offset=6378122c-a0a1-438d-a5c6-efabae9fb969"
}
检索插件
检索插件
GET /plugins/{plugin id}
| ATTRIBUTES | DESCRIPTION |
|---|---|
plugin id required | 要检索的插件的唯一标识符。 |
检索与特定路由关联的插件
GET /routes/{route name or id}/plugins/{plugin id}
| ATTRIBUTES | DESCRIPTION |
|---|---|
route name or id required | 要检索的 Route 的唯一标识符或名称。 |
plugin id required | 要检索的插件的唯一标识符。 |
检索与特定服务关联的插件
GET /services/{service name or id}/plugins/{plugin id}
| ATTRIBUTES | DESCRIPTION |
|---|---|
service name or id required | 要检索的服务的唯一标识符或名称。 |
plugin id required | 要检索的插件的唯一标识符。 |
检索与特定消费者关联的插件
GET /consumers/{consumer username or id}/plugins/{plugin id}
| ATTRIBUTES | DESCRIPTION |
|---|---|
consumer username or id required | 要检索的消费者的唯一标识符或用户名。 |
plugin id required | 要检索的插件的唯一标识符。 |
响应
HTTP 200 OK
{
"id": "ce44eef5-41ed-47f6-baab-f725cecf98c7",
"name": "rate-limiting",
"created_at": 1422386534,
"route": null,
"service": null,
"consumer": null,
"config": {"minute":20, "hour":500},
"protocols": ["http", "https"],
"enabled": true,
"tags": ["user-level", "low-priority"]
}
更新插件
更新插件
PATCH /plugins/{plugin id}
| ATTRIBUTES | DESCRIPTION |
|---|---|
plugin id required | 要检索的插件的唯一标识符。 |
更新与特定路由关联的插件
PATCH /routes/{route name or id}/plugins/{plugin id}
| ATTRIBUTES | DESCRIPTION |
|---|---|
route name or id required | 要检索的 Route 的唯一标识符或名称。 |
plugin id required | 要检索的插件的唯一标识符。 |
更新与特定服务关联的插件
PATCH /services/{service name or id}/plugins/{plugin id}
| ATTRIBUTES | DESCRIPTION |
|---|---|
service name or id required | 要检索的服务的唯一标识符或名称。 |
plugin id required | 要检索的插件的唯一标识符。 |
更新与特定消费者关联的插件
PATCH /consumers/{consumer username or id}/plugins/{plugin id}
| ATTRIBUTES | DESCRIPTION |
|---|---|
consumer username or id required | 要检索的消费者的唯一标识符或用户名。 |
plugin id required | 要检索的插件的唯一标识符。 |
请求主体,与添加插件请求主体相同
响应
HTTP 200 OK
{
"id": "ce44eef5-41ed-47f6-baab-f725cecf98c7",
"name": "rate-limiting",
"created_at": 1422386534,
"route": null,
"service": null,
"consumer": null,
"config": {"minute":20, "hour":500},
"protocols": ["http", "https"],
"enabled": true,
"tags": ["user-level", "low-priority"]
}
更新或创建插件
更新或创建插件
PUT /plugins/{plugin id}
| ATTRIBUTES | DESCRIPTION |
|---|---|
plugin id required | 要检索的插件的唯一标识符。 |
更新或创建与特定路由关联的插件
PUT /routes/{route name or id}/plugins/{plugin id}
| ATTRIBUTES | DESCRIPTION |
|---|---|
route name or id required | 要检索的 Route 的唯一标识符或名称。 |
plugin id required | 要检索的插件的唯一标识符。 |
更新或创建与特定服务关联的插件
PUT /services/{service name or id}/plugins/{plugin id}
| ATTRIBUTES | DESCRIPTION |
|---|---|
service name or id required | 要检索的服务的唯一标识符或名称。 |
plugin id required | 要检索的插件的唯一标识符。 |
更新或创建与特定消费者关联的插件
PUT /consumers/{consumer username or id}/plugins/{plugin id}
| ATTRIBUTES | DESCRIPTION |
|---|---|
consumer username or id required | 要检索的消费者的唯一标识符或用户名。 |
plugin id required | 要检索的插件的唯一标识符。 |
请求主体,与添加插件请求主体相同
使用正文中指定的定义插入(或替换)请求资源下的插件。插件将通过 name 或 id 属性进行标识。
当 name 或 id 属性具有 UUID 的结构时,被插入/替换的插件将由其 id 标识。否则,它将通过其名称来识别。
当创建一个没有指定 id 的新插件时(无论是在 URL 中还是在正文中),它都会自动生成。
请注意,不允许在 URL 中指定名称而在请求正文中指定不同的名称。
响应
HTTP 201 Created or HTTP 200 OK
{
"id": "ce44eef5-41ed-47f6-baab-f725cecf98c7",
"name": "rate-limiting",
"created_at": 1422386534,
"route": null,
"service": null,
"consumer": null,
"config": {"minute":20, "hour":500},
"protocols": ["http", "https"],
"enabled": true,
"tags": ["user-level", "low-priority"]
}
删除插件
删除插件
DELETE /plugins/{plugin id}
| ATTRIBUTES | DESCRIPTION |
|---|---|
plugin id required | 要检索的插件的唯一标识符。 |
删除与特定路由关联的插件
DELETE /routes/{route name or id}/plugins/{plugin id}
| ATTRIBUTES | DESCRIPTION |
|---|---|
route name or id required | 要检索的 Route 的唯一标识符或名称。 |
plugin id required | 要检索的插件的唯一标识符。 |
删除与特定服务关联的插件
DELETE /services/{service name or id}/plugins/{plugin id}
| ATTRIBUTES | DESCRIPTION |
|---|---|
service name or id required | 要检索的服务的唯一标识符或名称。 |
plugin id required | 要检索的插件的唯一标识符。 |
删除与特定消费者关联的插件
DELETE /consumers/{consumer username or id}/plugins/{plugin id}
| ATTRIBUTES | DESCRIPTION |
|---|---|
consumer username or id required | 要检索的消费者的唯一标识符或用户名。 |
plugin id required | 要检索的插件的唯一标识符。 |
请求主体,与添加插件请求主体相同
响应
HTTP 204 No Content
检索启用的插件
检索 Kong 节点上安装的全部插件列表
GET /plugins/enabled
响应
HTTP 200 OK
{
"enabled_plugins": [
"jwt",
"acl",
"cors",
"oauth2",
"tcp-log",
"udp-log",
"file-log",
"http-log",
"key-auth",
"hmac-auth",
"basic-auth",
"ip-restriction",
"request-transformer",
"response-transformer",
"request-size-limiting",
"rate-limiting",
"response-ratelimiting",
"aws-lambda",
"bot-detection",
"correlation-id",
"datadog",
"galileo",
"ldap-auth",
"loggly",
"statsd",
"syslog"
]
}
Kong 负载均衡 Load Balance
API Gateway 层通常需要提供负载均衡,Kong 支持基于 DNS 服务的负载均衡和不需要 DNS 服务的环均衡器。
DNS-based 负载均衡
使用包含主机名(而不是 IP 地址)的 host 定义的服务,若主机名被解析为多个 IP 地址,那么将自动使用 DNS-based 的负载均衡。前提是主机名不解析为 upstream 名称或主机名在您的 DNS 主机文件中(/etc/hosts)。
DNS 记录 ttl 设置项(生存时间)决定了信息的刷新频率。当使用 0 的 ttl 时,每个请求都将使用其自己的 DNS 查询来解析。显然这会降低性能,但更新/更改的延迟会非常低。
dig 结果的第二列,就是 ttl。
>dig @192.168.177.131 -p 8600 product.service.consul SRV ;; 略 ;; ANSWER SECTION: product.service.consul. 0 IN SRV 1 1 8081 c0a8b101.addr.dc1.consul. product.service.consul. 0 IN SRV 1 1 8083 c0a8b101.addr.dc1.consul. product.service.consul. 0 IN SRV 1 1 8082 c0a8b101.addr.dc1.consul. ;; 略
DNS 查询优先级:
-
先前解析的最后一个成功类型
-
SRV record,解析 IP + Port
-
A record,解析 IP
-
CNAME record,解析别名
意味着如果我们的服务通过 port 区分,则会先于 IP 进行处理。
DNS 注意事项:
-
每当刷新 DNS 记录时,都会生成一个列表以正确处理权重。尝试将权重保持为彼此的倍数以保持算法的性能,例如,17 和 31 的 2 个权重将导致具有 527 个条目的结构,而权重 16 和 32(或它们的最小相对对应物 1 和 2)将导致在只有 3 个条目的结构中,尤其是具有非常小(甚至 0)的 ttl 值的结构。
-
DNS 通过 UDP 承载,默认限制为 512 字节。如果要返回的条目很多,DNS 服务器将响应部分数据并设置截断标志,表示还有更多条目未发送。然后,包括 Kong 在内的 DNS 客户端将通过 TCP 发出第二个请求,以检索完整的条目列表。
-
默认情况下,某些 nameserver 不使用 truncate 标志响应,而是将响应修剪为低于 512 字节的 UDP 大小。
-
Consul 就是一个例子。 Consul 在其默认配置中仅返回前三个条目,并且不设置 truncate 标志以指示还有未发送的剩余条目。 Consul 包含一个启用截断标志的选项。
-
-
如果部署的 nameserver 不提供 truncate 标志,则 upstream 实例池的加载可能不一致。由于名称服务器提供的信息有限,Kong 节点实际上不知道某些实例。为了缓解这种情况,请使用不同的名称服务器,使用 IP 地址而不是名称,或者确保使用足够的 Kong 节点来保持所有 upstream 服务仍在使用中。
-
当 nameserver 返回
3 name error时,这就是 Kong 的有效响应。如果这是意外的,首先验证正在查询的名称是否正确,然后检查您的 nameserver 配置。 -
从 DNS 记录(A 或 SRV)中选择 IP 地址的初始选择不是随机的。因此,当使用
ttl为 0 的记录时,名称服务器应随机化记录条目。
环均衡器 Ring-balancer
使用 ring-balancer 时,后端服务的添加和删除将由 Kong 处理,不再需要 DNS 来更新服务信息。 Kong 将充当服务注册中心。可以通过单个 HTTP 请求添加/删除节点,并将立即开始/停止接收流量。
配置 ring-balancer 是通过 upstream 和 target 实体完成的。
-
target:IP 地址或主机名,带有后端服务所在的端口号,例如。 “192.168.100.12:80”。每个 target 都会获得一个额外的
weight,以指示它获得的相对负载。 IP 地址可以是 IPv4 和 IPv6 格式。 -
upstream:可以在 Route 的
host字段中使用的“虚拟主机名”,例如,名为weather.v2.service的 upstream 将获取来自具有host=weather.v2.service的服务的所有请求。
Upsteam
每个 upstream 都有自己的 Ring-balancer。每个upstream 可以附加许多 target 条目,并且代理到“虚拟主机名”的请求(可以在代理之前使用 upstream 的属性 host_header 覆盖)将在 target 上进行负载平衡。Ring-Balancer 具有最大预定义数量的插槽,并且基于 target 权重,插槽被分配给 upstream 的 target 。
添加和删除 target 可以通过 Admin API 上的简单 HTTP 请求来完成。这种手术相对便宜。更改 upstream 本身的成本更高,因为例如当插槽数量发生变化时需要重建平衡器。
在平衡器中有位置(从 1 到 slot 属性中定义的值),它们随机分布在环上。需要随机性以在运行时便宜地调用环平衡器。一个简单的轮盘循环(位置)将在 target 上提供一个分布良好的加权循环,同时在插入/删除 target 时也有便宜的操作。
Target
target 是带有标识后端服务实例的端口的 IP 地址/主机名。每个 upstream 可以有许多 target。
当非活动条目比活动条目多 10 倍时,将自动清理 target。清理将涉及重建平衡器,因此比仅添加 target条目更昂贵。
Target 也可以有主机名而不是 IP 地址。在这种情况下,名称将被解析,所有找到的条目将单独添加到环平衡器中,例如,添加 weight=100 的 api.host.com:123。名称 “api.host.com”解析为具有 2 个 IP 地址的 A 记录。然后将两个 ip 地址添加为 target,每个得到 weight=100 和端口 123。注意:权重用于单个条目,而不是整体!
它是否会解析为 SRV 记录,然后还会提取 DNS 记录中的端口和权重字段,并将否决给定的端口 123 和 weight = 100。
平衡器将遵守 DNS 记录的 ttl 设置,并在其过期时重新查询和更新平衡器。
例外:当 DNS 记录的 ttl=0 时,主机名将被添加为具有指定权重的单个 target。在对该 target的每个代理请求时,它将再次查询名称服务器。
平衡算法
Ring-balancer 支持以下负载平衡算法:round-robin, consistent-hashing, and least-connections。默认情况下,Ring-balancer 使用 round-robin 算法,该算法在目标上提供了一个分布良好的 weighted round-robin(加权循环)。
使用 consistent-hashing 算法时,散列的输入可以是 none、consumer、ip、header 或 cookie。当设置为 none 时,将使用 round-robin 方案,并且将禁用散列。 consistent-hashing 算法支持主散列和回退散列属性;如果主散列失败(例如,如果主散列设置给 consumer,但没有 consumer 认证通过),则使用回退属性。
支持的哈希属性有:
-
none:不使用consistent-hashing;改为使用round-robin(默认)。 -
consumer:使用消费者 ID 作为哈希输入。如果没有可用的消费者 ID,它将回退到认证 ID(例如,在 LDAP 等外部身份验证机制的情况下)。 -
ip:使用原始 IP 地址作为哈希输入。使用此选项时,请查看用于确定真实 IP 的配置设置。 -
header:使用指定的 header 作为哈希输入。标头名称在hash_on_header或hash_fallback_header中指定,具体取决于标头是主要属性还是回退属性。 -
cookie:使用指定路径的指定cookie作为哈希输入。 cookie 名称在hash_on_cookie字段中指定,路径在hash_on_cookie_path字段中指定。如果请求中不存在指定的 cookie,它将由响应设置。因此,如果 cookie 是主要散列机制,则 hash_fallback 设置无效。
consistent-hashing 算法基于一致性哈希(或 Ketama 原则),它确保当平衡器因目标更改(添加、删除、失败或更改权重)而被修改时,只有最小数量的哈希损失发生。这最大限度地提高了上游缓存命中。
Ring-balancer 还支持 least-connections 算法,该算法选择连接数最少的目标,由目标的权重属性加权。
应用位置
负载均衡应用在发现服务的位置,在微服务架构中,典型使用在:
-
API 网关转发到目标服务
-
服务间发现其他服务时,需要在服务内部实现,或者基于服务发现实现。
典型的负载均衡算法
-
rr:Round Robin, 循环
-
wrr : Weighted round robin,加权循环
-
p2c : Power of two choices,随机选2个,再从中选1个效率高的
-
random : Random,随机
-
wr: Weighted Random, 加权随机
-
Hash:基于特定输入命中
限流
应用系统中,由于 API 服务无法控制上游调用方的行为,因此当瞬时请求量突增时,会导致服务器占用过多资源,发生响应速度降低、超时、乃至宕机,甚至引发雪崩造成整个系统不可用。限流,Rate Limiting,就是对 API 的请求量进行限制。系统的吞吐量通常是可以被测算的,为了保证系统的稳定运行,对于超出限制部分的请求作出快速拒绝、快速失败、丢弃处理,以保证本服务以及下游资源系统的稳定。
常用的限流算法有:
-
计数法,也叫固定窗口计数法,Fixed Window
-
滑动窗口计数法,Sliding Window
-
漏桶算法,Leaky Bucket
-
令牌桶算法,Token Bucket
计数法,固定窗口计数法
计数法的思路是控制单位时间内的请求数量:
-
将时间划分为固定的窗口大小,例如1s
-
在窗口时间段内,每来一个请求,对计数器加1
-
当计数器达到设定限制后,该窗口时间内的之后的请求都被丢弃处理。
-
该窗口时间结束后,计数器清零,从新开始计数

计数法的优点是实现容易,同时资源使用率低。
计数法的缺点是会出现突刺现象,也就是在不到窗口时间段的某时间段内请求数量到达了限定。下面两种典型情况:
-
不超过窗口时间段的一段时间内,服务不可用。如下一图。
-
瞬间流量超过临界值问题,就是窗口切换时可能会产生两倍于阙值的请求。如下二图。
一图:
二图:
滑动窗口计数法
滑动窗口计数法是固定窗口计数法的改进,解决了固定窗口切换时可能会产生两倍于阈值流量请求的缺点。TCP 协议中数据包的传输,同样也是采用滑动窗口来进行流量控制。
滑动窗口与固定窗口不同,滑动窗口的窗口时间段是随着时间向下滑动的,而滑动的时间段就是滑动周期。如图:
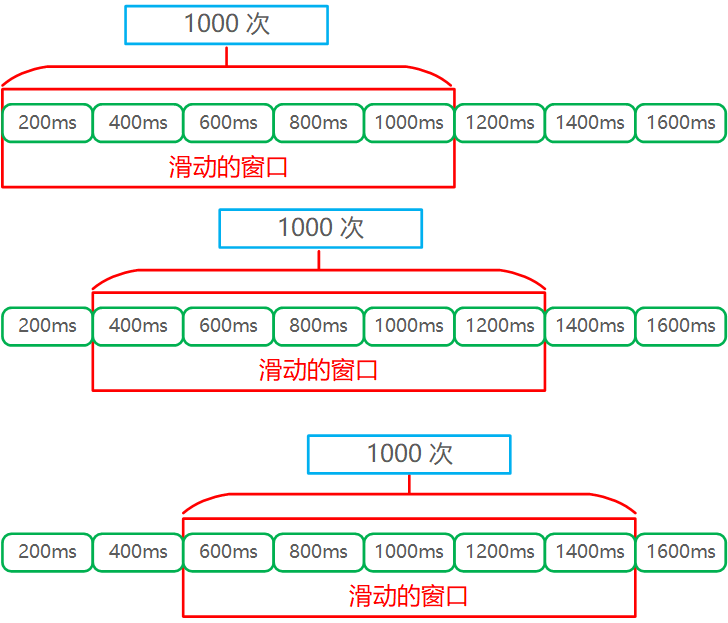
上图中,我们将 1s 划分为5个小窗口,而5个连续的小窗口组成一个滑动窗口,随着时间推移,滑动窗口向前推移。也就是从1s开始每隔 200ms 窗口向前移动一次,也就是统计包括现在的200ms在内,过去5个小区间(200ms)的请求次数。可见,子窗口划分的越多,则限流越精准,也称越平滑。
每个小区间单独统计请求次数,滑动窗口的次数为全部子区间次数之和。若超过最大限制,则本窗口后续请求会被限制。随着时间推移,进入下一个窗口期,重新计算全部子区间之和。
实操时,超限后的请求往往会被缓存起来,后边慢慢处理,而不是直接丢弃,来提升应用可用性。
滑动窗口如何解决瞬间流量超过临界值两倍问题的?
如上图所示,若 800 至 1000 ms 周期内请求为 1000,达到了临界值,时间进入到 1000-1200ms周期,窗口向前滑动,这个周期就不能再开放请求了,因为 800-1000ms周期内的请求计数也在该滑动窗口,因此可以规避瞬间流量超过临界值两倍问题。需要等待滑动窗口滑出800-1000ms小区间,才会重新开放请求。
漏桶算法
漏桶算法的主要目的是平滑请求流量。漏桶,一个带有漏洞的水桶。漏洞的大小是可控的(固定的),那就意味着从桶中漏出(流出)的水量是固定的,而不论桶里存在多少水和以多快的速度向桶中装水。这里水就是网络流量,装水就是接收外部请求,而漏水就是将请求流量转发给特定服务。如图所示:
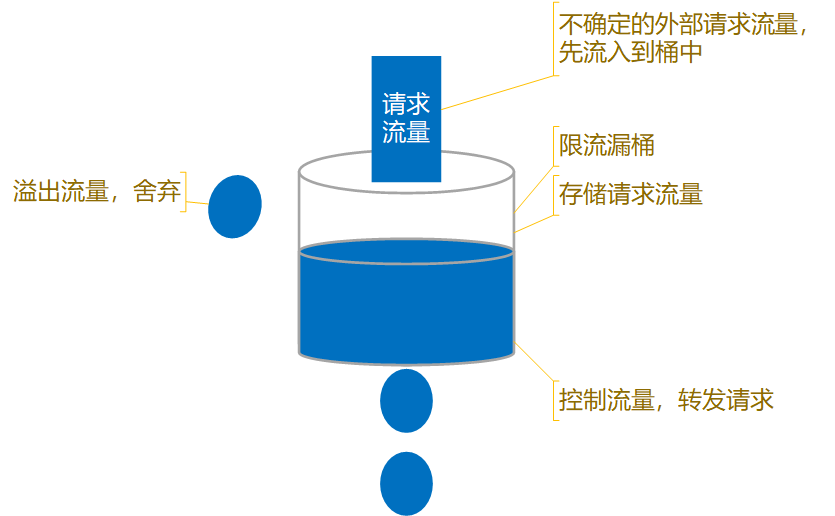
令牌桶算法
令牌桶,一个装有请求放行令牌的桶。这里的请求放行令牌的作用是:只有拿到请求放行令牌的请求,才会被转发到目标上。拿不到令牌,只能舍弃或等待。令牌的产生由我们后端程序称为令牌工厂来控制,产生多少令牌,产生的频率如何等。相当于根据服务的处理的能力,发放令牌数量,比单纯的时间窗口要灵活。如图:
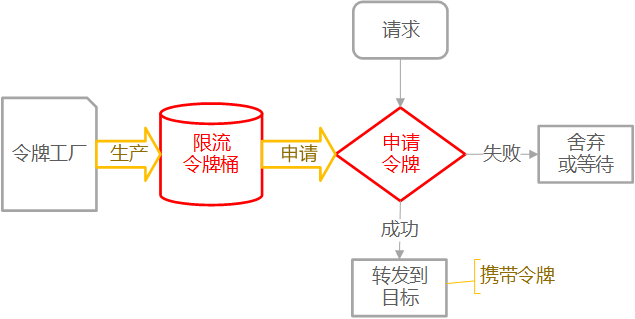
令牌桶算法既能够将所有的请求平均分布到时间区间内,又能接受服务器能够承受范围内的突发请求,因此是目前使用较为广泛的一种限流算法。
Kong 限流示例
Kong 使用 Rate Limiting 插件完成基于计数器算法(固定窗口)的限流。
速率限制在给定的秒、分钟、小时、天、月或年的时间段内可以处理多少 HTTP 请求。该限制是使用 Rate Limiting 插件实现的。
限流可针对服务、路由和消费者进行配置,通过 Admin API 完成限流的配置。
针对路由示例:
$ curl -X POST http://localhost:8001/routes/ROUTE_NAME|ROUTE_ID/plugins \
--data "name=rate-limiting" \
--data "config.second=5" \
--data "config.hour=10000" \
--data "config.policy=local"
将 ROUTE_NAME|ROUTE_ID 替换为此插件配置将针对的路由的 ID 或名称。
若达到了限定,则直接响应 429 Too Many Requests。
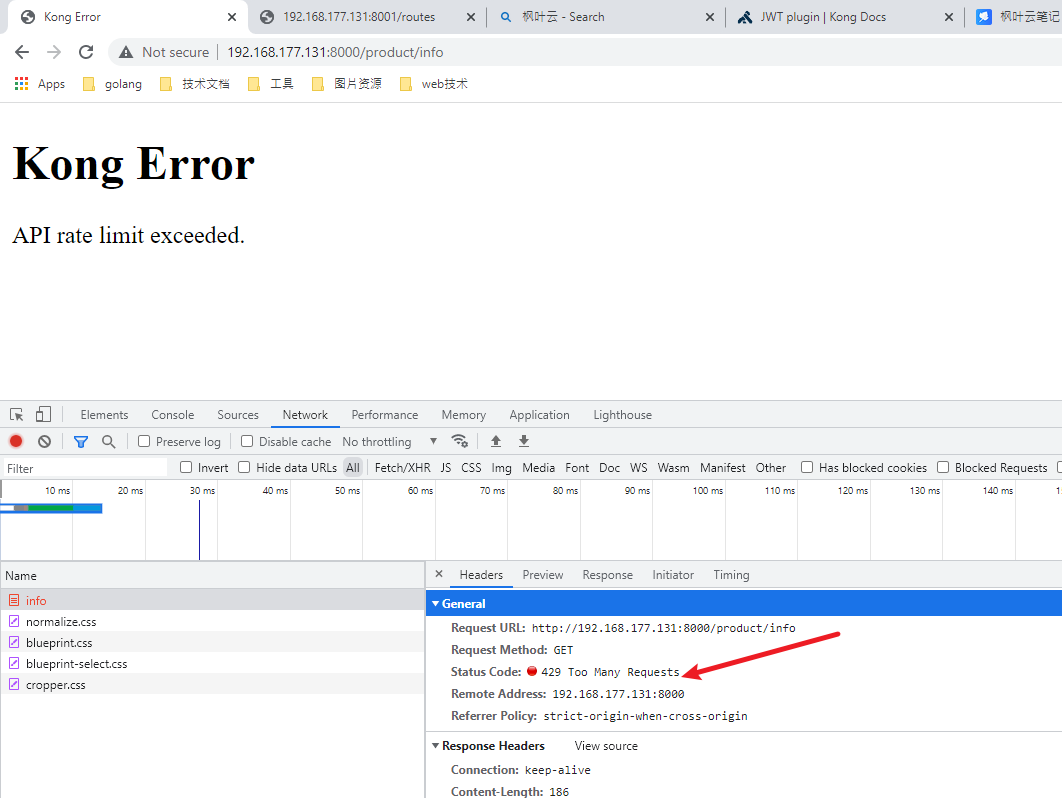
针对服务示例:
curl -X POST http://localhost:8001/services/SERVICE_NAME|SERVICE_ID/plugins \
--data "name=rate-limiting" \
--data "config.second=5" \
--data "config.hour=10000" \
--data "config.policy=local"
将 SERVICE_NAME|SERVICE_ID 替换为此插件配置将针对的服务的 ID 或名称。
针对消费者配置:
$ curl -X POST http://localhost:8001/consumers/CONSUMER_NAME|CONSUMER_ID/plugins \
--data "name=rate-limiting" \
--data "config.second=5" \
--data "config.hour=10000" \
--data "config.policy=local"
将 CONSUMER_NAME|CONSUMER_ID 替换为此插件配置将针对的消费者的 ID 或名称。
您可以将 consumer.id、service.id 或 route.id 组合在同一个请求中,以进一步缩小插件的范围。
全局启用,每个请求都会被 limit。
$ curl -X POST http://localhost:8001/plugins/ \
--data "name=rate-limiting" \
--data "config.second=5" \
--data "config.hour=10000" \
--data "config.policy=local"
Kong 还提供了企业版插件:Rate Limiting Advanced 来支持更高级的请求速率控制,主要是实现了滑动窗扣计数法。
Kong 不但可以限制请求数量,还可以限制请求数据尺寸,使用插件:Kong Request Size Limiting 可以限制。
Kong 熔断和降级
熔断,利用熔断器阻止流量通过。熔断器,相当于一个开关,在需要阻止流量进入时,通过打开熔断器来实现。当某个服务不可用时,应该阻止流量继续进入该服务,也就是需要熔断该服务。通常熔断器会返回调用端一个预设的响应状态。
在微服务架构中,尤其需要使用熔断技术。因为微服务间的调用容易出现调用链,A 调用 B,B 调用 C 这种情况,如果 C 不可用,如果不阻止对 C 的调用,那么调用就会堆积到 B,进而导致 A、B、C 都不可用,这就是服务雪崩效应。
除了意外情之外,熔断还会主动被开启,例如当访问故障或升级时,需要阻止对该访问的使用,我们需要主动熔断。
熔断发生在对服务的访问过程前,因此在 API 网关转发请求到服务,和微服务间相互调用时,都可能用到熔断技术。例如 DNS 的服务发现,在服务不可用(健康检查未通过时)就不会响应该失败服务的地址,进而阻止对该服务的调用,这种就是基于健康检查的熔断。
Kong 主动熔断示例
Kong 提供了 Request Terminal 插件来主动完成熔断。
此插件使用指定的状态代码和消息终止传入请求。这允许(暂时)停止服务或路由上的流量,甚至阻止消费者。
熔断可以针对于服务、路由、消费者进行配置。
针对服务配置:
curl -X POST http://localhost:8001/services/SERVICE_NAME|SERVICE_ID/plugins \
--data "name=request-termination" \
--data "config.status_code=403" \
--data "config.message=So long and thanks for all the fish!"
将 SERVICE_NAME|SERVICE_ID 替换为此插件配置将针对的服务的 ID 或名称。
针对路由配置
$ curl -X POST http://localhost:8001/routes/ROUTE_NAME|ROUTE_ID/plugins \
--data "name=request-termination" \
--data "config.status_code=403" \
--data "config.message=So long and thanks for all the fish!"
将 ROUTE_NAME|ROUTE_ID 替换为此插件配置将针对的路由的 ID 或名称。
针对消费者配置
$ curl -X POST http://localhost:8001/consumers/CONSUMER_NAME|CONSUMER_ID/plugins \
--data "name=request-termination" \
--data "config.status_code=403" \
--data "config.message=So long and thanks for all the fish!"
将 CONSUMER_NAME|CONSUMER_ID 替换为此插件配置将针对的消费者的 ID 或名称。
您可以将 consumer.id、service.id 或 route.id 组合在同一个请求中,以进一步缩小插件的范围。
全局启用,每个请求都会被 terminal。
$ curl -X POST http://localhost:8001/plugins/ \
--data "name=request-termination" \
--data "config.status_code=403" \
--data "config.message=So long and thanks for all the fish!"
服务降级
服务降级一般是指在服务器压力剧增的时候,根据实际业务使用情况以及流量,对一些服务和页面有策略的不处理或者用一种简单的方式进行处理,从而释放服务器资源的资源以保证核心业务的正常高效运行。
服务降级是从整个系统的负荷情况出发和考虑的,对某些负荷会比较高的情况,为了预防某些功能(业务场景)出现负荷过载或者响应慢的情况,在其内部暂时舍弃对一些非核心的接口和数据的请求,而直接返回一个提前准备好的fallback(退路)错误处理信息。这样,虽然提供的是一个有损的服务,但却保证了整个系统的稳定性和可用性。
降级考虑的是资源如何更合理的分配到不同的服务中。
需要考虑的问题:
-
区分那些服务为核心?那些非核心
-
降级策略,针对非核心业务是采用限流还是熔断的策略完成降级?
-
自动降级还是手动降
对比限流、熔断、降级
限流:限制并发的请求访问量,超过阈值则拒绝;
熔断:依赖的下游服务故障触发熔断,避免引发本系统崩溃,断开对目标服务的访问;或者在自主维护期,主动熔断。
降级:从应用整体出发,将服务划分优先级,区分核心和非核心业务,牺牲非核心服务(非核心业务限流或熔断),保证核心服务稳定;
Kong 常用插件
Kong 的全部插件可以在:Kong Plugin Hub | Kong Docs 获取。其中:
认证类 Authentication
-
Portal Application Registration,Enterprise
-
Basic Authentication,
-
HMAC Authentication
-
JWT
-
Kong JWT Signer,Enterprise
-
Key Authentication
-
Key Authentication - Encrypted,Enterprise
-
LDAP Authentication
-
LDAP Authentication Advanced,Enterprise
-
Mutual TLS Authentication,Enterprise
-
OAuth 2.0 Authentication
-
OAuth 2.0 Introspection,Enterprise
-
OpenID Connect,Enterprise
-
Session
-
Vault Authentication,Enterprise
-
Okta
-
PASETO
-
Upstream HTTP Basic Authentication
安全类 Security
-
ACME
-
Bot Detection
-
CORS
-
IP Restriction
-
OPA,Enterprise
-
Cleafy plugin for Kong
-
Approov API Threat Protection
-
Kong Spec Expose
-
Kong Upstream JWT
-
Salt Security
-
Kong Path Allow
-
Signal Sciences
-
Wallarm
传输控制类 Traffic Control
-
ACL
-
Canary Release,Enterprise
-
Forward Proxy Advanced,Enterprise
-
GraphQL Proxy Caching Advanced,Enterprise
-
GraphQL Rate Limiting Advanced,Enterprise
-
Mocking,Enterprise
-
Proxy Cache
-
Proxy Caching Advanced,Enterprise
-
Rate Limiting
-
Rate Limiting Advanced,Enterprise
-
Request Size Limiting
-
Request Termination
-
Request Validator,Enterprise
-
Response Rate Limiting
-
Route By Header,Enterprise
-
Set Dynamic Upstream Host
-
Kong Response Size Limiting
-
Kong Service Virtualization
-
JWT to Header (Route by JWT Claim)
无服务 Serverless
-
AWS Lambda
-
Azure Functions
-
Apache OpenWhisk
-
Serverless Functions
分析 & 监控 Analytics & Monitoring
-
Datadog
-
Prometheus
-
Zipkin
-
ArecaBay MicroSensor
-
Moesif API Analytics
-
SignalFx
转换Transformations
-
Correlation ID
-
DeGraphQL,Enterprise
-
Exit Transformer,Enterprise
-
gRPC-gateway
-
gRPC-Web
-
jq,Enterprise
-
Kafka Upstream,Enterprise
-
Request Transformer
-
Request Transformer Advanced,Enterprise
-
Response Transformer
-
Response Transformer Advanced,Enterprise
-
Route Transformer Advanced,Enterprise
-
Inspur Request Transformer
-
Inspur Response Transform
-
API Transformer
-
Reedelk Transformer
-
Template Transformer
-
URL Rewrite
日志 Logging
-
File Log
-
HTTP Log
-
Kafka Log,Enterprise
-
Loggly
-
StatsD
-
StatsD Advanced,Enterprise
-
Syslog
-
TCP Log
-
UDP Log
-
Kong Google Cloud Logging
-
Moesif API Analytics
-
Kong Splunk Log
-
Google Analytics Log
发布 Deployment
-
Kong on AWS with Terraform
-
Kong on Microsoft Azure Certified
-
Kongverge
-
Microsoft Azure
-
Microsoft Azure Container Instances
-
KongMap
链路追踪
链路追踪介绍
在分布式系统,尤其是微服务系统中,一次外部请求往往需要内部多个模块,多个中间件,多台机器的相互调用才能完成。在这一系列的调用中,可能有些是串行的,而有些是并行的。在这种情况下,我们如何才能确定这整个请求调用了哪些应用?哪些模块?哪些节点?以及它们的先后顺序和各部分的性能如何呢?
链路追踪就是负责完成以上任务的。
如图所示:
有向无环图 DAG
有向无环图 DAG,Directed Acycling Graph,是图中没有回路(环)的有向图。
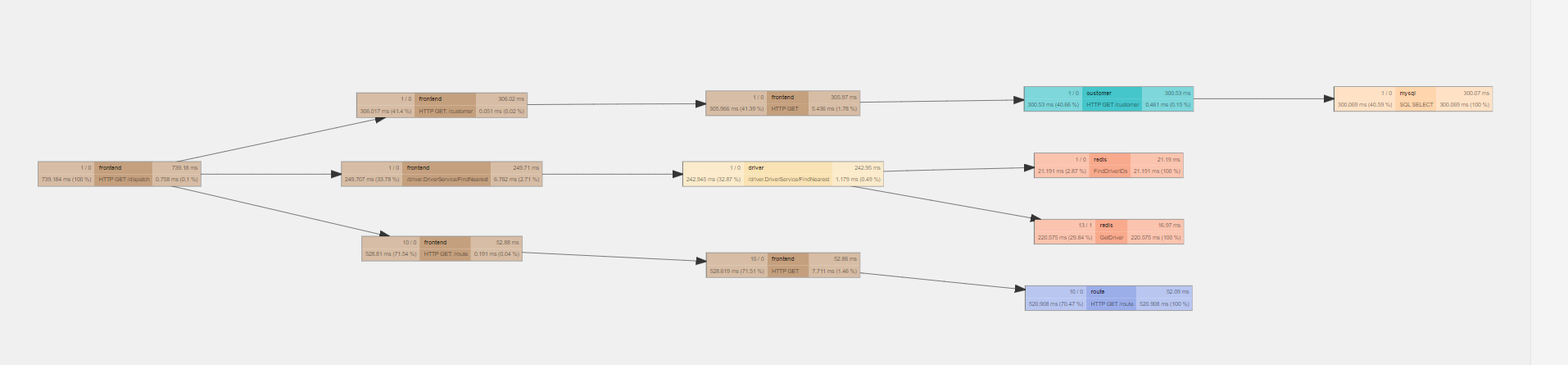
常用的链路追踪工具
链路监控软件,市场上典型的代表有:
-
Dapper,Google很早推出的追踪工具老大哥,OpenTracing兼容
-
jaeger,Uber 开源,Go 编写,支持 UDP/TCP 协议,支持多种语言的客户端,支持ES、Kafka、Cassandra、内存等多种存储,可侵入,OpenTracing兼容
-
elastic apm,Elastic stack 推出,Go 编写,OpenTracing兼容
-
SkyWalking,Java 编写,OpenTracing兼容
-
Zipkin,Java 编写,OpenTracing兼容
分布式调用链标准(OpenTracing)
OpenTracing 于 2016 年 10 月加入 CNCF (云原生计算基金会),是继 Kubernetes 和 Prometheus 之后,第三个加入 CNCF 的开源项目。它是一个中立的(厂商无关、平台无关)分布式追踪的 API 规范,提供统一接口,可方便开发者在自己的服务中集成一种或多种分布式追踪的实现。
OpenTracing 是一个轻量级的标准化层,它位于应用程序/类库和追踪或日志分析程序之间。它的出现是为了解决不同的分布式追踪系统 API 不兼容的问题。OpenTracing 通过提供与平台和厂商无关的 API,使得开发人员能够方便地添加追踪系统,就像单体架构下的AOP(切面编程)一样。
图片来自:OpenTracing: turning the lights on for microservices | CNCF
OpenTracing 的数据模型,主要有以下三个:
-
Trace:一个完整请求链路,每个调用链由多个 Span 组成
-
Span:一次调用过程,主要包含以下技术指标
-
操作名称
-
起始时间
-
结束时间
-
一组 KV 值,作为阶段的标签(Span Tags)
-
阶段日志(Span Logs)
-
阶段上下文(SpanContext),其中包含 Trace ID 和 Span ID
-
引用关系(References)
-
-
SpanContext:Trace 的全局上下文信息,如里面有traceId
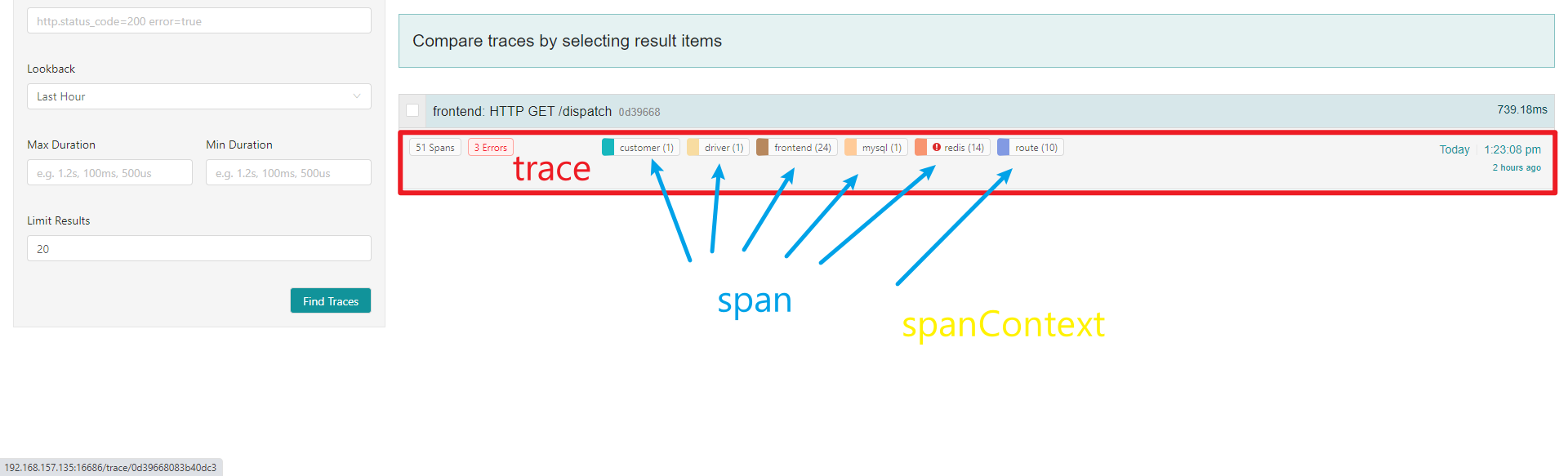
基本原理:
分布式追踪系统大体分为三个部分,数据采集、数据持久化、数据展示。数据采集是指在代码中埋点,设置请求中要上报的阶段,以及设置当前记录的阶段隶属于哪个上级阶段。数据持久化则是指将上报的数据落盘存储,例如 Jaeger 就支持多种存储后端,可选用 Cassandra 或者 Elasticsearch。数据展示则是前端根据 Trace ID 查询与之关联的请求阶段,并在界面上呈现。
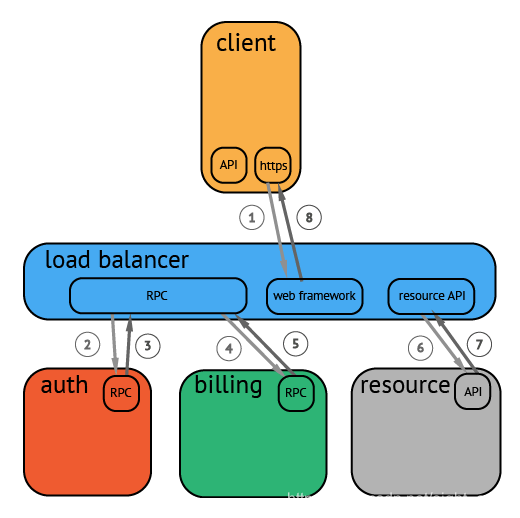
图片来自:https://opentracing.io/documentation/
Metrics,tracing,logging
与追踪类似的主要有三个概念:
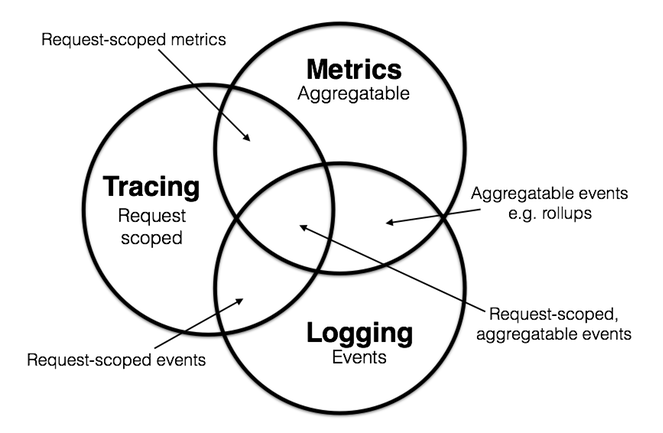
-
Logging:用于记录离散的事件,包含程序执行到某一点或某一阶段的详细信息。
-
Metrics:可聚合的数据,且通常是固定类型的时序数据,包括 Counter、Gauge、Histogram 等。
-
Tracing:记录单个请求的处理流程,其中包括服务调用和处理时长等信息。
同时这三种定义相交的情况也比较常见。
-
Logging & Metrics:可聚合的事件。例如分析某对象存储的 Nginx 日志,统计某段时间内
-
GET、PUT、DELETE、OPTIONS 操作的总数。 Metrics & Tracing:单个请求中的可计量数据。例如 SQL
-
执行总时长、gRPC 调用总次数。 Tracing & Logging:请求阶段的标签数据。例如在 Tracing 的信息中标记详细的错误原因。
针对每种分析需求,我们都有非常强大的集中式分析工具。
-
Logging:ELK,近几年势头最猛的日志分析服务,无须多言。
-
Metrics:Prometheus,第二个加入 CNCF 的开源项目,非常好用。
-
Tracing:OpenTracing 和 Jaeger,Jaeger 是 Uber 开源的一个兼容 OpenTracing 标准的分布式追踪服务。
Jaeger 示例
Jaeger: open source, distributed tracing platform
受Dapper和OpenZipkin启发的Jaeger是由Uber Technologies作为开源发布的分布式跟踪系统。它用于监视和诊断基于微服务的分布式系统,包括:
-
分布式上下文传播
-
分布式交易监控
-
根本原因分析
-
服务依赖性分析性能/延迟优化
特性(来自官网):
高扩展性
Jaeger后端的设计没有单点故障,可以根据业务需求进行扩展。例如,Uber上任何给定的Jaeger安装通常每天要处理数十亿个跨度。
原生支持OpenTracing
Jaeger后端,Web UI和工具库已完全设计为支持OpenTracing标准。
-
通过跨度引用将迹线表示为有向无环图(不仅是树)
-
支持强类型的跨度标签和结构化日志通过行李
-
支持通用的分布式上下文传播机制
多存储后端
Jaeger支持两个流行的开源NoSQL数据库作为跟踪存储后端:Cassandra 3.4+和Elasticsearch 5.x / 6.x / 7.x。正在进行使用其他数据库的社区实验,例如ScyllaDB,InfluxDB,Amazon DynamoDB。Jaeger还附带了一个简单的内存存储区,用于测试设置。
现代化的UI
Jaeger Web UI是使用流行的开源框架(如React)以Javascript实现的。v1.0中发布了几项性能改进,以允许UI有效处理大量数据,并显示具有成千上万个跨度的跟踪(例如,我们尝试了具有80,000个跨度的跟踪)。
原生部署
Jaeger后端作为Docker映像的集合进行分发。这些二进制文件支持各种配置方法,包括命令行选项,环境变量和多种格式(yaml,toml等)的配置文件。Kubernetes模板和Helm图表有助于将其部署到Kubernetes集群。
可观察性
默认情况下,所有Jaeger后端组件都公开Prometheus指标(也支持其他指标后端)。使用结构化日志库zap将日志写到标准输出。
安全
Jaeger的第三方安全审核可在https://github.com/jaegertracing/security-audits中获得。
与Zipkin的向后兼容性
尽管我们建议使用OpenTracing API来对应用程序进行检测并绑定到Jaeger客户端库,以从其他地方无法获得的高级功能中受益,但是如果您的组织已经使用Zipkin库对检测进行了投资,则不必重写所有代码。Jaeger通过在HTTP上接受Zipkin格式(Thrift或JSON v1 / v2)的跨度来提供与Zipkin的向后兼容性。从Zipkin后端切换只是将流量从Zipkin库路由到Jaeger后端的问题。
安装
最简单的 Docker 镜像使用 all in one
docker run -d --name jaeger \ -e COLLECTOR_ZIPKIN_HOST_PORT=:9411 \ -e COLLECTOR_OTLP_ENABLED=true \ -p 6831:6831/udp \ -p 6832:6832/udp \ -p 5778:5778 \ -p 16686:16686 \ -p 4317:4317 \ -p 4318:4318 \ -p 14250:14250 \ -p 14268:14268 \ -p 14269:14269 \ -p 9411:9411 \ jaegertracing/all-in-one
端口说明
| Port | Protocol | Component | Function |
|---|---|---|---|
| 6831 | UDP | agent | accept jaeger.thrift over Thrift-compact protocol (used by most SDKs) |
| 6832 | UDP | agent | accept jaeger.thrift over Thrift-binary protocol (used by Node.js SDK) |
| 5775 | UDP | agent | (deprecated) accept zipkin.thrift over compact Thrift protocol (used by legacy clients only) |
| 5778 | HTTP | agent | serve configs (sampling, etc.) |
| 16686 | HTTP | query | serve frontend |
| 4317 | HTTP | collector | accept OpenTelemetry Protocol (OTLP) over gRPC, if enabled |
| 4318 | HTTP | collector | accept OpenTelemetry Protocol (OTLP) over HTTP, if enabled |
| 14268 | HTTP | collector | accept jaeger.thrift directly from clients |
| 14250 | HTTP | collector | accept model.proto |
| 9411 | HTTP | collector | Zipkin compatible endpoint (optional) |
访问 Jaeger UI
浏览器中使用URL http://your-host:16686 来访问 Jaeger UI.
HotROD 示例
HotROD 是一个演示应用程序,由几个微服务组成,并演示了 OpenTracing API的用法。
使用 Docker 启动:
$ docker run --rm -it \ --link jaeger \ -p8080-8083:8080-8083 \ -e JAEGER_AGENT_HOST="jaeger" \ jaegertracing/example-hotrod \ all
使用源码启动(我们选择):
mkdir -p $GOPATH/src/github.com/jaegertracing cd $GOPATH/src/github.com/jaegertracing git clone https://github.com/jaegertracing/jaeger.git cd jaeger go run ./examples/hotrod/main.go all
访问应用:http://your-host:8080 。进行测试。
分布式事务数据一致性
分布式基本原则
CAP
BASE
配置中心
分布式锁
分布式 Session
分布式事务
事务介绍
事务是一组操作的组合,这组操作要么都成功,要么都失败。指的是若某个操作执行失败,那么全部的操作都要取消,回到这组操作执行前的状态。
事务具备 ACID 四基本特性:
-
A,Atomic,原子性,构成事务的所有操作,要么都执行完成,要么全部不执行,不可能出现部分成功部分失败的情况
-
C,Consistency,一致性,在事务执行前后,数据库的一致性约束没有被破坏
-
I,Isolation,隔离性,并发的两个事务的执行互不干扰
-
D,Durability,持久性,事务完成之后,该事务对数据的更改会持久化到数据库
事务分为本地事务和分布式事务:
-
本地事务,指发生在单一节点上的事务,通常是指基于本地数据库实现的事务。
-
数据库事务的过程
-
begin transaction -
commit -
rollback
-
-
-
分布式事务,在分布式系统环境下由不同的节点之间通过网络远程协作完成的事务称之为分布式事务。也就是事务的发起者、参与者、管理者、资源及资源管理者分别位于分布式系统的不同节点之上。分布式事务的作用就是用于保证不同节点中的数据一致性。
分布式事务介绍
在分布式系统环境下由不同的节点之间通过网络远程协作完成的事务称之为分布式事务。也就是事务的参与者、管理者、资源及资源管理者分别位于分布式系统的不同节点之上。分布式事务的作用就是用于保证不同节点中的数据一致性。
例如典型的创建订单业务逻辑由以下几个部分构成:
-
仓库服务:扣减特定商品库存数量
-
订单服务:生成订单

分布式事务的作用就是保证数据在订单服务和仓库服务这个整体上的一致性。不能说订单生成了,消耗了10件商品,而仓库服务中的库存说了没有一致性的改变。
分布式事务相关协议:
-
2PC,Two Phases Commit,二阶段提交
-
3PC,Three Phases Commit,三阶段提交
-
最终一致性
典型的分布式事务模式,依据一致性由强到弱排序如下:
-
XA,eXtended Architecture, 数据库层面的分布式事务规范,目前主流数据库基本都支持 XA 事务,已知方案中的最强的一致性方案
-
TCC,Try、Confirm、Cancel,应用(服务)层参与的 2PC 方案
-
事务消息,利用消息队列异步确保事务的一致性
-
Saga,将长事务拆分为多个本地短事务协调执行,若某个短事务失败,则反顺序调用补偿(undo)操作
-
最大努力通知,发起通知方通过一定的机制最大努力将事务结果通知到接收方,来保证一致性
还有几个事实模式,特定产品中实现的模式:
-
Seata 实现 AT 模式
-
DTM 推出的二阶段消息和 Workflow 模式
常见的实现分布式事务的产品(解决方案):
-
Seata,支持 TCC、Saga 和 AT(Seata(阿里团队)实现)模式,提供 Seata-go 支持 Go 技术栈
-
DTM,支持 XA,Saga、TCC、和 DTM 推出的 二阶段消息和 Workflow 模式,基于 Go 开发
分布式事务协议
2PC
二阶段提交协议(Two-phase Commit,即 2PC)是常用的分布式事务协议,即将事务的提交过程分为准备阶段和提交阶段两个阶段来进行处理。通过引入协调者(Coordinator)来协调参与者的行为,并最终决定这些参与者是否要真正执行事务。
2PC 中的两种角色:
-
事务协调者(事务管理器),Coordinator:事务的发起者
-
事务参与者(资源管理器), Resource Manager:事务的执行者
2PC 中的两个阶段:
-
准备阶段,Prepare
-
协调者向各个参与者发出准备执行事务指令
-
参与者执行但不提交事务,数据库中的体现就是将操作记录在 redo/undo 日志中
-
参与者将执行结果反馈给协调者,成功 yes,失败 no
-
-
提交阶段,Commit
-
若协调者收到全部的参与者的 yes 反馈,则向参与者发送 commit 指令
-
若协调者未收到全部参与者的 yes 反馈(有的反馈no,有的超时未反馈),则向参与者发送 rollback 指令
-
参与者根据收到的 commit 或 rollback 指令,完成事务的提交或者回滚
-
协调者收到全部参与者的 commit 或 rollback 的 ack,完成事务
-
prepare 阶段全部反馈为 yes 情况,如图所示:
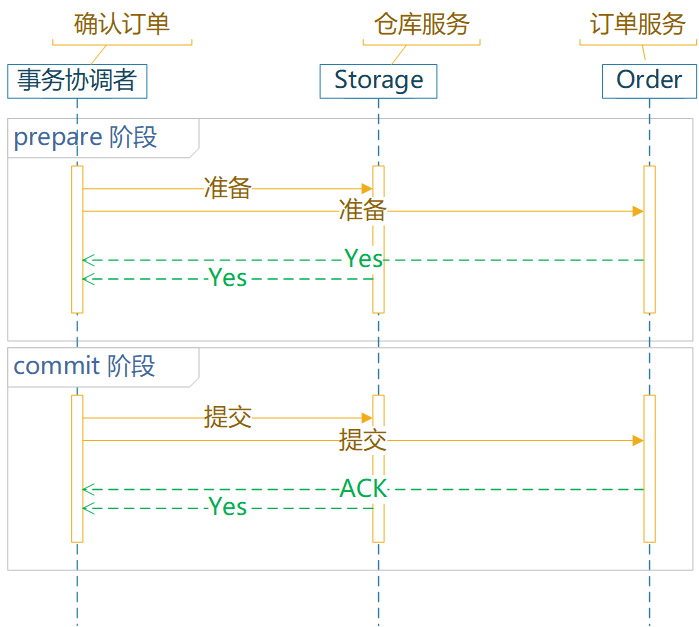
prepare 阶段未全部反馈为 yes 情况,如图所示:
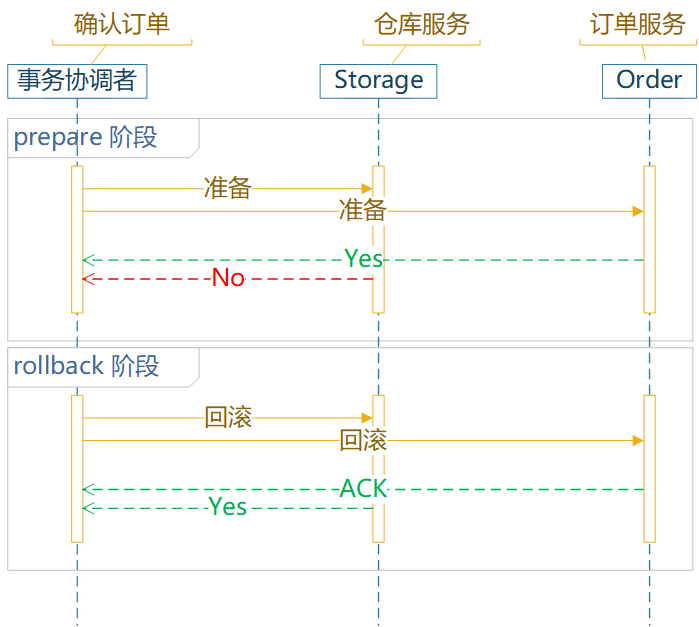
2PC 的中心思想就是将事务拆解为两步,先确认再提交,是当前实现分布式事务的核心思想。在数据库层面实现就是 XA 模式,在业务层面实现就是 Saga、TCC 模式,Seata 的 At 也是二阶段的思路。
3PC
三阶段提交协议(Three-phase Commit,即 3PC)是基于 2PC 的改造版本,主要的改动是将 2PC 中的 Prepare 阶段分为了 canCommit 和 PreCommit 两个阶段,那三个阶段就是:
-
CanCommit,提交检查阶段,询问参与者是否具备条件执行事务
-
协调者向全部参与者询问是否具备条件执行事务
-
参与者根据自身状态,反馈结果,具备 yes,不具备 no。通常是资源的检测。
-
-
PreCommit,预提交阶段,与 2PC 中的 Prepare 阶段类型,执行事务但不提交
-
若协调者收到全部的参与者的 yes 反馈,则向参与者发送 preCommit 指令
-
若协调者未收到全部参与者的 yes 反馈(有的反馈no,有的超时未反馈),则向参与者发送 abort 中断指令
-
参与者根据收到的 preCommit 或 abort 指令,选择执行但不提交事务,或中断
-
参与者将执行结果反馈给协调者,成功的 ack,或失败 no
-
若执行的是 abort 指令,那么不再继续,事务终止
-
-
DoCommit,提交阶段
-
若协调者收到全部的参与者关于 preCommit 指令的 yes 反馈,则向参与者发送 doCommit 指令
-
若协调者未收到全部参与者关于 preCommit 指令的 yes 反馈的 yes 反馈(有的反馈no,有的超时未反馈),则向参与者发送 abort 指令
-
参与者根据收到的 commit 或 abort 指令,完成事务的提交或者中断
-
协调者收到全部参与者的 commit 或 abort 的 ack,完成事务
-
canCommit、preCommit 阶段全部反馈 yes 的情况,如图:
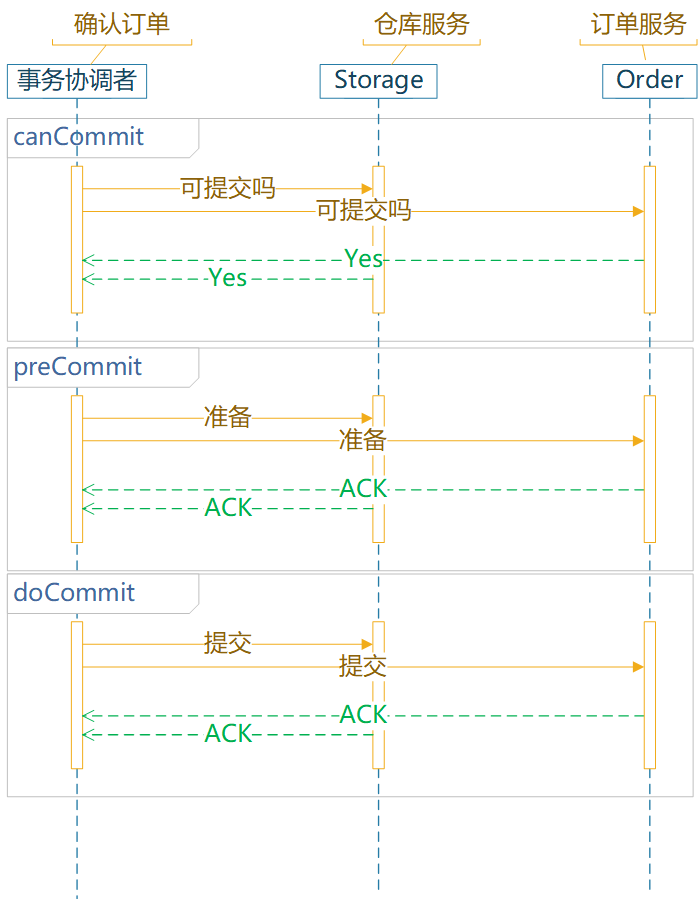
canCommit 未全部反馈 yes 的情况,如图:
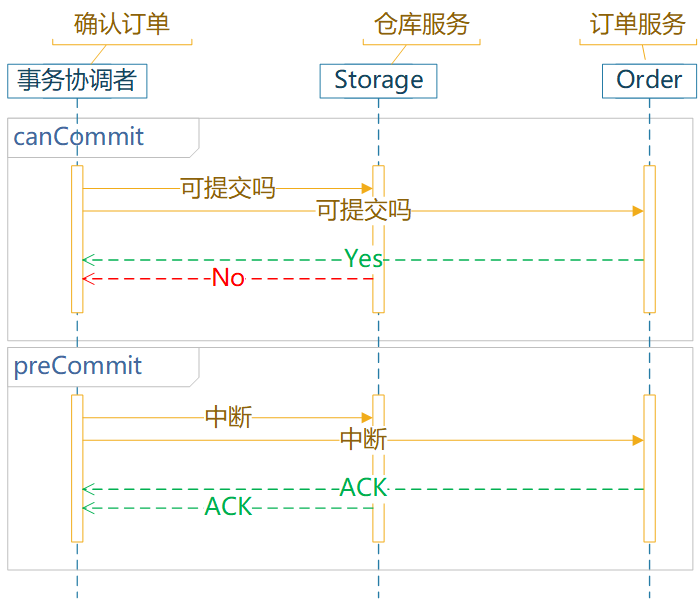
canCommit 全部反馈 yes,但 preCommit 未全部 ACK 的情况,如图:

3PC 增加了 canCommit 阶段,也就是在进入到事务执行阶段前,可以完成一些必要的检查,而不会像 2PC 那样直接进入事务执行而锁定资源。这样在一定成都上减少了资源的阻塞范围。但步骤多了,实现必然复杂了。
分布式事务模式
XA
XA,eXtended Architecture,是由 X/Open 组织提出的分布式事务的规范,XA 规范主要定义了事务管理器(TM)和资源管理器(RM)之间的接口。目前主流的数据库基本都支持XA事务,包括 mysql、oracle、sqlserver、postgre。
本地的数据库如 MySQL 在 XA 中扮演的是 RM 角色。而 XA 工具扮演的是 TM 的角色,例如 Seata 和 Dtm。通过 TM 与数据库RM的交互,完成分布式事务的调度控制。
XA 是 2PC 在数据库层面实现的一种规范,分为两阶段:
-
第一阶段(prepare):所有的参与者 RM 准备执行事务并锁住需要的资源。参与者 ready 时,向 TM 报告已准备就绪
-
第二阶段 (commit/rollback):当事务管理者(TM)确认所有参与者(RM)都 ready 后,向所有参与者发送 commit 命令或 rollback 命令
XA 模式在数据库层面实现,因此一致性非常严格,但同时并发性能较差。因此适合做那种要求强一致性的业务逻辑,例如转账、金融等。
MySQL 提供如下的语句实现 XA 事务:
# Begin
XA {START|BEGIN} xid [JOIN|RESUME]
# End
XA END xid [SUSPEND [FOR MIGRATE]]
# Prepare
XA PREPARE xid
# Commit
XA COMMIT xid [ONE PHASE]
# rollback
XA ROLLBACK xid
# recover
XA RECOVER [CONVERT XID]
MySQL 通过关联特定的 xid 来控制本地事务(子事务),TM 负责控制全局事务。
以确认订单为例:
-
确认订单业务逻辑
-
通知 TM 开启全局事务
-
注册订单服务创建订单本地事务接口
-
注册库存服务扣减库存本地事务接口
-
-
订单服务
-
实现创建订单本地事务接口
-
-
库存服务
-
实现扣减库存本地事务接口
-
全部 prepare 成功,如图所示:
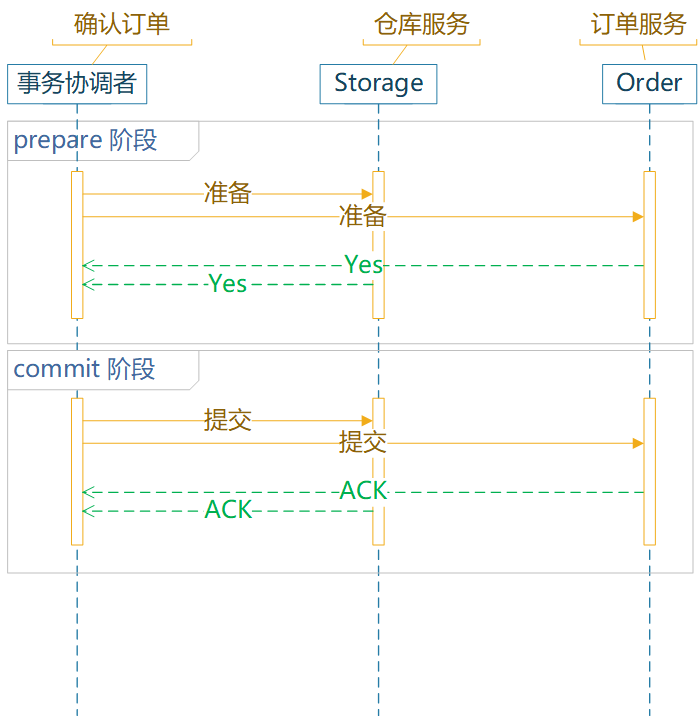
Saga
Saga 最初出现在1987年 Hector Garcaa-Molrna & Kenneth Salem 发表的论文《SAGAS》里。其核心思想是将长事务拆分为多个短事务,由 Saga 事务协调器协调,如果每个短事务都成功提交完成,那么全局事务就正常完成,如果某个步骤失败,则根据相反顺序一次调用补偿操作。
Saga 是业务逻辑层面实现的分布式事务管理。意味着任何一个事务内的操作,都要定义正向和反向(补偿)两个操作。正向就是常规业务逻辑,反向(补偿)就是取消正向业务逻辑带来的影响。总结就是,先使用资源,不行再退回去。
以确认订单为例:
-
订单服务
-
正向操作:创建订单和订单产品,同时订单为已确认状态。
-
反向(补偿)操作:更新订单状态为未确认
-
-
库存服务
-
正向操作:扣减库存
-
反向补偿操作:将扣减的库存退回去
-
实操时,我们需要在订单和库存服务中,分别实现正向和反向两个接口。而 Saga 事务管理器负责完成对接口的调用。
不需要补偿操作的情况,如图:
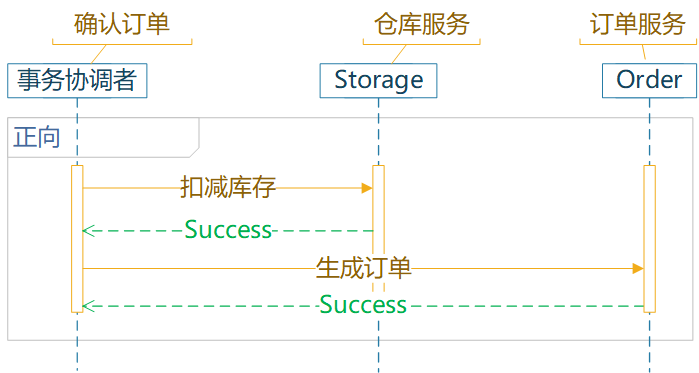
需要补偿操作的情况,如图:
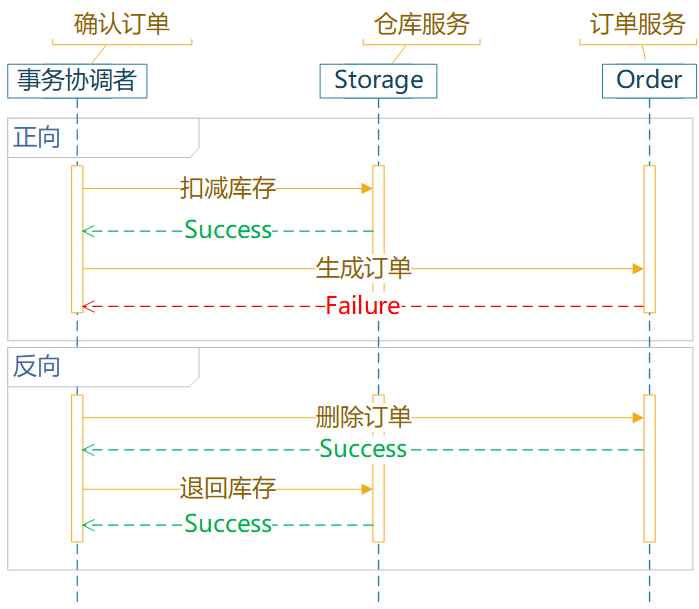
真正实现时,确认订单为主业务逻辑,负责与 Saga 事务协调器(Seata, Dtm) 通讯,将仓库和订单服务的正向和反向操作接口注册到 Saga 事务协调器中。Saga 事务协调器负责根据正向操作的结果觉得是否调用补偿操作。示例请参考 《DTM 的 Saga 示例》
TCC
TCC 是 Try、Confirm、Cancel 三个词语的缩写,最早是由 Pat Helland 于 2007 年发表的一篇名为《Life beyond Distributed Transactions:an Apostate’s Opinion》的论文提出。
TCC 是 2PC 在业务逻辑层面的实现,也就意味着脱离数据库,完成准备和提交阶段。在 TCC 中,采用的是先冻结资源,若全部节点冻结成功,则提交占有资源,若存在失败阶段,则释放冻结的资源。总结就是:先冻结,成功则占有否则释放。
TCC 分为3个操作,2个阶段
-
Try 操作,1阶段:尝试执行,完成所有业务检查(一致性), 预留必须业务资源(准隔离性),冻结资源
-
Confirm 操作,2阶段:如果所有分支的 Try 都成功了,则走到Confirm阶段。Confirm真正执行业务,不作任何业务检查,只使用 Try 阶段预留的业务资源
-
Cancel 操作,2阶段:如果所有分支的Try有一个失败了,则走到 Cancel 阶段。Cancel释放 Try 阶段预留的业务资源。
以确认订单为例:
-
Try 操作,1阶段
-
订单服务会生成确认中的订单
-
库存服务会冻结需要的库存
-
-
Confirm 操作,2阶段,库存服务都成功,则确认事务
-
订单状态更新为已确认
-
执行扣减库存
-
-
Cancel 操作,2阶段,若订单、库存服务存在失败的情况,则取消事务
-
释放冻结的库存
-
将订单状态更新为未确认状态
-
我们需要在订单服务和库存服务中,分别实现 Try、Confirm和Cancel 接口。而 分布式事务管理器(Seata、Dtm)服务完成调度,根据结果选则 Confirm 还是 Cancel。
执行 Confirm 情况,如图所示:
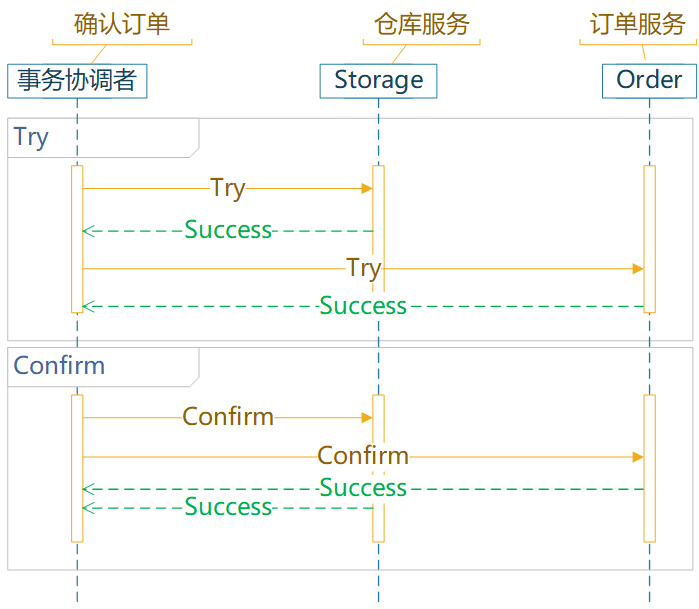
执行 Cancel 情况,如图所示:
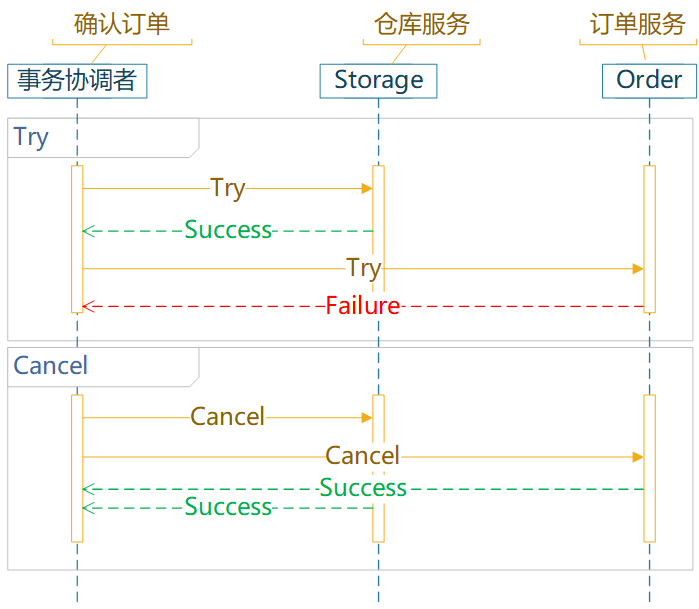
真正实现时,确认订单为主业务逻辑,负责与TCC事务协调器(Seata, Dtm)通讯,将仓库和订单服务的 Confirm 和 Cancel 接口注册到 TCC 事务协调器中。TCC 事务协调器负责根据 Try 的结果调用 Confirm 或 Cancel。
TCC vs Saga 思想:
-
Saga,先使用,不行再退回
-
TCC,先锁定(冻结),再选择占用或释放
事务消息
消息事务的原理是将两个事务通过消息中间件进行异步解耦。RocketMQ 实现的该方案。若服务 A、B要实现分布式事务,其思路是:
-
A 服务发布事务成功的 half 消息到 MQ。half 消息是消费者(服务 B)不可见的消息。
-
A 服务执行本地事务
-
事务提交,则通知 MQ 将 half 消息对消费者可见
-
事务回滚,则通知 MQ 将 half 消息删除
-
-
B 服务只有在 A 服务事务提交成功后,才会消费到消息,消费到消息后,B 服务完成自己的事务部分
-
若消费失败,服务 B 会不断重试,直到消费成功
-
RocketMQ 还要求 A 服务提供一个接口,用于查询关于这条 half 消息对应的事务是否成功,来控制 half 消息的状态。
该方案主要适用于不需要业务回滚的场景,如某些附加操作。例如注册成功后,领取礼品,发送邮件等。
最大努力通知
最大努力通知的方案适用于一些最终一致性要求较低的业务。
执行流程:
-
服务 A 本地事务执行完之后,发送个消息到 MQ;
-
最大努力通知调度器,消费该消息,同时调用服务 B 的接口完成事务
-
要是服务 B 执行失败了,那么最大努力通知调度器就定时尝试重新调用服务 B的事务几口, 反复 N 次,最后还是不行就放弃。
该方案主要适用于不需要业务回滚、一致性较低的场景,如某些附加操作。例如注册成功后,领取礼品,发送邮件等。
分布式事务异常
分布式系统最大的问题就是 NPC ,是 Network Delay, Process Pause, Clock Drift 的首字母缩写。指的是:
-
Network Delay,网络延迟
-
Process Pause,进程暂停。当基于某些需要,例如内存垃圾回收、CPU 排队、服务迁移等,某服务会暂时暂停。
-
Clock Drift,时钟漂移。分布式系统涉及大量的服务器,而不同服务器通常使用 NTP (Network Time Protocol)协议将本地设备的时间与时间服务器对齐对齐后,通常会导致本地时间跳跃。
由于分布式事务系统由于存在 NPC 问题,意味着分布式事务需要考虑:
-
空补偿,也叫空回滚,补偿操作在主动操作未执行前执行,系统设计应该允许空补偿。因此本地事务的补偿操作需要判定出来主动操作是否执行。补偿操作,可以理解成逆向操作或 rollback 操作,主动操作可以理解为正向操作或 prepare 操作,例如:
-
TCC 中,就是 cancel 操作的执行需要判定 try 是否执行
-
Sage 中,就是逆向补偿操作需要判定正向操作是否执行
-
-
悬挂,正向操作在执行时,补偿操作已经完成,因此本地事务的正向操作需要判定出补偿操作是否执行完成,例如:
-
TCC 中,就是 Try 操作执行时需要判定 cancel 操作是否执行完毕
-
Saga 中,就是正向操作执行时需要判定逆向补偿操作是否执行
-
以 Saga 模式的网络异常时序图为例:

仓储服务存在 NPC 问题,导致操作1 扣减库存 操作迟迟到达不了仓储服务,同时假设 2 操作的成功结果由于 NPC 问题到达不了调度器,这就导致:
-
空补偿:2 操作,因为超时而导致分布式事务失败,需要补偿。因此向仓储服务发出补偿操作请求。此时正向操作还未抵达仓储服务,因此是个空补偿操作。
-
悬挂:1 操作,当1 扣减库存这个正向操作到达仓储服务时,由于已经执行过补偿操作,因此 1 操作出现悬挂。
不论空补偿还是悬挂,都需要在业务逻辑层面做出判定。通常的做法是通过分布式事务事件日志的方案来标识操作状态,进而决定是否需要处理空补偿和防止悬挂。
上图中,2 操作超时而执行的补偿,若在仓库服务执行成功,但反馈的结果由于 NPC 问题不能到达事务调度器,那么事务调度器还有可能再次发送 3 超时而执行补偿操作。这就意味着仓库服务的补偿操作会被多次重复调用。我们必须保证分布式事务的全部操作分支保证幂等性。也就是重复调用操作分支,但不会产生叠加的影响。
在编程中一个幂等操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同。
DTM 示例
DTM 是一款开源的分布式事务管理器,解决跨数据库、跨服务、跨语言栈更新数据的一致性问题。
DTM 安装
Docker
$ sudo docker run \ --net host \ --rm -it \ --name dtmDev \ -p 36789:36789 \ -p 36790:36790 \ yedf/dtm:latest Unable to find image 'yedf/dtm:latest' locally latest: Pulling from yedf/dtm 530afca65e2e: Already exists cfc3c688efa0: Pull complete 4f4fb700ef54: Pull complete Digest: sha256:1b7f6da9d959ba62ea4aa995f92696158ff82f8472064c081c262a58a73be9b4
二进制安装包
地址:
https://github.com/dtm-labs/dtm/releases/latest
下载对应平台的版本,运行即可。
源码安装
源码为 Go,编译需要 Go 1.16+
$ git clone https://github.com/dtm-labs/dtm && cd dtm $ go build $ ./dtm
DTM 的 Saga 示例
完整代码位于:microService/dtm_saga
业务逻辑说明,共有三个服务:
-
bff/ensure_order.go,确认订单的聚合服务。负责开启 saga 事务
-
order/serviceOrder.go,订单服务,创建订单,当订单库存检测失败时,将订单状态更新为未确认
-
storage/serviceStorage.go,仓库服务,扣减库存,当库存不足时,错误。补偿接口完成库存回退
编码实现:
一:准备订单服务和仓库服务相关表:
drop table if exists saga.orders;
create table if not exists saga.orders (
id int unsigned primary key auto_increment,
tx_id varchar(255) unique,
status enum('confirming', 'confirmed', 'not confirmed'),
total int
);
drop table if exists saga.order_products;
create table if not exists saga.order_products (
order_id int unsigned,
product_id int unsigned,
quantity int,
price int,
primary key (order_id, product_id)
);
drop table if exists saga.storages; create table if not exists saga.storages ( id int unsigned primary key auto_increment, inventory int ); insert into saga.storages values (3, 108), (8, 10);
二:在各自服务的 MySQL 中执行以上 SQL,准备好基础数据:
# order $ sudo docker run \ --rm \ --net host \ --name mysqlSagaOrder \ -e MYSQL_TCP_PORT=3306 \ -e MYSQL_ROOT_PASSWORD=mashibing \ -e MYSQL_DATABASE=saga \ -d mysql:latest # login mysql && create table $ sudo docker exec -it mysqlSagaOrder mysql -hlocalhost -pmashibing # storage $ sudo docker run \ --rm \ --net host \ --name mysqlSagaStorage \ -e MYSQL_TCP_PORT=3307 \ -e MYSQL_ROOT_PASSWORD=mashibing \ -e MYSQL_DATABASE=saga \ -d mysql:latest # login mysql && create table && insert some rows. $ sudo docker exec -it mysqlSagaStorage mysql -hlocalhost -pmashibing
三:编写业务服务
聚合服务 bff/ensure_order.go
package main
import (
"github.com/dtm-labs/client/dtmcli"
"log"
)
// 业务请求数据对象
type Req struct {
Quantity int `json:"quantity"`
Id int `json:"id"`
TxId string `json:"tx_id"`
}
// 模拟创建订单的聚合业务逻辑
func main() {
// dtm 服务器地址
const dtmServer = "http://192.168.177.131:36789/api/dtmsvr"
// 关联的两个服务的地址
const orderServer = "http://192.168.177.1:8081"
const storageServer = "http://192.168.177.1:8082"
// dtm 生成 事务id
gid := dtmcli.MustGenGid(dtmServer)
// 伪造请求数据
req := Req{20, 3, gid}
// 启动 Saga 事务
saga := dtmcli.NewSaga(dtmServer, gid).
Add(orderServer+"/order-create", orderServer+"/order-create-compensate", req).
Add(storageServer+"/deduct", storageServer+"/deduct-compensate", req)
// 事务提交
err := saga.Submit()
log.Fatalln(err)
}
订单服务:
order/serviceOrder.go
package main
import (
"database/sql"
"github.com/gin-gonic/gin"
_ "github.com/go-sql-driver/mysql"
"log"
"net/http"
)
var DB *sql.DB
func init() {
db, err := sql.Open("mysql", "root:mashibing@tcp(192.168.177.131:3306)/saga?charset=utf8mb4&parseTime=True&loc=Local")
if err != nil {
log.Fatalln(err)
}
DB = db
}
type Req struct {
Quantity int `json:"quantity"`
Id int `json:"id"`
TxId string `json:"tx_id"`
}
func main() {
r := gin.Default()
r.POST("/order-create", func(c *gin.Context) {
req := &Req{}
if err := c.BindJSON(req); err != nil {
log.Fatalln(err)
}
// 创建订单和订单商品记录
query := "insert into orders values (null, ?, 'confirmed', 1024)"
result, err := DB.Exec(query, req.TxId)
if err != nil {
c.JSON(http.StatusOK, gin.H{"dtm_result": "FAILURE", "message": "order create failed"})
return
}
orderId, err := result.LastInsertId()
if err != nil {
c.JSON(http.StatusOK, gin.H{"dtm_result": "FAILURE", "message": "order create failed"})
return
}
query = "insert into order_products values (?, ?, ?, 99)"
if _, err := DB.Exec(query, orderId, req.Id, req.Quantity); err != nil {
c.JSON(http.StatusOK, gin.H{"dtm_result": "FAILURE", "message": "order products create failed"})
return
}
c.JSON(http.StatusOK, gin.H{"dtm_result": "SUCCESS"})
})
r.POST("/order-create-compensate", func(c *gin.Context) {
// 确认,生成订单信息,插入 orders 和 order_products 表记录,本例中,仅使用 order_products 表
req := &Req{}
if err := c.BindJSON(req); err != nil {
log.Fatalln(err)
}
// 将订单状态更新为未确认
query := "update orders set status='not confirmed' where tx_id=?"
if _, err := DB.Exec(query, req.TxId); err != nil {
c.JSON(http.StatusOK, gin.H{"dtm_result": "FAILURE", "message": "compensate order status failed"})
return
}
c.JSON(http.StatusOK, gin.H{"dtm_result": "SUCCESS"})
})
r.Run(":8081")
}
库存服务:
storage/serviceStorage.go
package main
import (
"database/sql"
"github.com/gin-gonic/gin"
_ "github.com/go-sql-driver/mysql"
"log"
"net/http"
)
var DB *sql.DB
func init() {
db, err := sql.Open("mysql", "root:mashibing@tcp(192.168.177.131:3307)/saga?charset=utf8mb4&parseTime=True&loc=Local")
if err != nil {
log.Fatalln(err)
}
DB = db
}
type Req struct {
Quantity int `json:"quantity"`
Id int `json:"id"`
TxId string `json:"tx_id"`
}
func main() {
r := gin.Default()
r.POST("/deduct", func(c *gin.Context) {
// 解析请求数据
req := &Req{}
if err := c.BindJSON(req); err != nil {
log.Fatalln(err)
}
// 执行 扣减库存
query := "update storages set inventory = inventory-? where id = ?"
if _, err := DB.Exec(query, req.Quantity, req.Id); err != nil {
c.JSON(http.StatusOK, gin.H{"dtm_result": "FAILURE", "message": "deduct inventory failed"})
return
}
// 判定库存是否为负数,负数失败
inventory := 0
query = "select inventory from storages where id=?"
if err := DB.QueryRow(query, req.Id).Scan(&inventory); err != nil {
log.Fatalln(err)
}
if inventory < 0 {
c.JSON(http.StatusOK, gin.H{"dtm_result": "FAILURE", "message": "inventory is not enough"})
return
}
c.JSON(http.StatusOK, gin.H{"dtm_result": "SUCCESS"})
})
r.POST("/deduct-compensate", func(c *gin.Context) {
req := &Req{}
if err := c.BindJSON(req); err != nil {
log.Fatalln(err)
}
// 执行 扣减库存的补偿操作
query := "update storages set inventory = inventory+? where id = ?"
if _, err := DB.Exec(query, req.Quantity, req.Id); err != nil {
c.JSON(http.StatusOK, gin.H{"dtm_result": "FAILURE", "message": "compensate inventory failed"})
return
}
c.JSON(http.StatusOK, gin.H{"dtm_result": "SUCCESS"})
})
r.Run(":8082")
}
启动 DTM,完成测试。通过数据库中的数据变化,体现分布式事务的实现。
幂等性问题解决:
构建记录操作表:
create table saga.tx_op (
tx_id varchar(255) primary key,
status enum('op_success', 'op_failed', 'opc_success', 'opc_failed')
) ;
op,标识正向操作
opc 标识补偿操作
如果存在某条 tx_id 为主键的记录,说明正向操作执行成功,那么在逆向时,才需要完成补偿操作。
代码实现:
storage/serviceStorageBad.go
DTM 的 TCC 示例
完整代码位于:microService/dtm_tcc
业务逻辑说明,共有三个服务:
-
bff/ensure_order.go,确认订单的聚合服务。负责开启全局 tcc 事务,dtm 自动完成 try、confirm和cancel 的调用
-
order/serviceOrder.go,订单服务,负责完成确认订单逻辑中订单服务的 try、confirm、cancel
-
try,生成 orders 表记录,状态为确认中 confirming
-
confirm,生成 order_products 表记录,订单状态更新为已确认 confirmed
-
cancel,删除 try 中生成的 order 表记录,订单状态更新为未确认 not confirmed
-
-
storage/serviceStorage.go,仓库服务,负责完成确认订单逻辑中仓库的 try、confirm、cancel
-
try,依据购买量检测库存是否够用,够用的话,冻结库存
-
confirm,扣减库存
-
cancel,取消冻结库存操作(若冻结操作存在的话)
-
编码实现:
一:准备订单服务使用订单和订单商品表
drop table if exists tcc.orders;
create table if not exists tcc.orders (
id int unsigned primary key auto_increment,
tx_id varchar(255) unique,
status enum('confirming', 'confirmed', 'not confirmed'),
total int
);
drop table if exists tcc.order_products;
create table if not exists tcc.order_products (
order_id int unsigned,
product_id int unsigned,
quantity int,
price int,
primary key (order_id, product_id)
);
仓库服务库存表及测试数据:
-
id 商品id
-
inventory 库存
-
frozen_inventory 冻结库存,用于事务逻辑判定,库存不能小于冻结库存。
drop table if exists tcc.storages;
create table if not exists tcc.storages (
id int unsigned primary key auto_increment,
inventory int,
frozen_inventory int
);
insert into tcc.storages values
(3, 108, 0),
(8, 10, 0);
二:在各自服务的 MySQL 中执行以上 SQL,准备好基础数据:
# order $ sudo docker run \ --rm \ --net host \ --name mysqlTccOrder \ -e MYSQL_TCP_PORT=3306 \ -e MYSQL_ROOT_PASSWORD=mashibing \ -e MYSQL_DATABASE=tcc \ -d mysql:latest # login mysql && create table $ sudo docker exec -it mysqlTccOrder mysql -hlocalhost -pmashibing # storage $ sudo docker run \ --rm \ --net host \ --name mysqlTccStorage \ -e MYSQL_TCP_PORT=3307 \ -e MYSQL_ROOT_PASSWORD=mashibing \ -e MYSQL_DATABASE=tcc \ -d mysql:latest # login mysql && create table && insert some rows. $ sudo docker exec -it mysqlTccStorage mysql -hlocalhost -pmashibing
三:编写业务服务
bff/ensure_order.go
package main
import (
"github.com/dtm-labs/client/dtmcli"
"github.com/go-resty/resty/v2"
"log"
)
// 业务请求数据对象
type Req struct {
Quantity int `json:"quantity"`
Id int `json:"id"`
TxId string `json:"tx_id"`
}
// 模拟创建订单的聚合业务逻辑
func main() {
// dtm 服务器地址
const dtmServer = "http://192.168.177.131:36789/api/dtmsvr"
// 关联的两个服务的地址
const orderServer = "http://192.168.177.1:8081"
const storageServer = "http://192.168.177.1:8082"
// dtm 生成 事务id
gid := dtmcli.MustGenGid(dtmServer)
// 启动全局 TCC 事务
err := dtmcli.TccGlobalTransaction(dtmServer, gid, func(tcc *dtmcli.Tcc) (*resty.Response, error) {
// 伪造请求数据
req := Req{20, 3, gid}
// 设置 order-create 操作的 try, confirm, cancel
resOrder, errOrder := tcc.CallBranch(req, orderServer+"/order-create-try", orderServer+"/order-create-confirm", orderServer+"/order-create-cancel")
if errOrder != nil {
return resOrder, errOrder
}
// 设置 deduct 操作的 try, confirm, cancel
resStorage, errStorage := tcc.CallBranch(req, storageServer+"/deduct-try", storageServer+"/deduct-confirm", storageServer+"/deduct-cancel")
if errStorage != nil {
return resStorage, errStorage
}
return nil, nil
})
log.Println(err)
}
四:编写 order 服务
order/serviceOrder.go
package main
import (
"database/sql"
"github.com/gin-gonic/gin"
_ "github.com/go-sql-driver/mysql"
"log"
"net/http"
)
var DB *sql.DB
func init() {
db, err := sql.Open("mysql", "root:mashibing@tcp(192.168.177.131:3306)/tcc?charset=utf8mb4&parseTime=True&loc=Local")
if err != nil {
log.Fatalln(err)
}
DB = db
}
type Req struct {
Quantity int `json:"quantity"`
Id int `json:"id"`
TxId string `json:"tx_id"`
}
func main() {
r := gin.Default()
r.POST("/order-create-try", func(c *gin.Context) {
req := &Req{}
if err := c.BindJSON(req); err != nil {
log.Fatalln(err)
}
// 完成业务逻辑校验
// 本例中不需要校验,在库存服务检测库存即可
// 我们选择,先生成订单记录。若分布式事务校验通过,则创建订单和商品关联记录,否则删除该订单记录
query := "insert into orders values (null, ?, 1024)"
if _, err := DB.Exec(query, req.TxId); err != nil {
c.JSON(http.StatusOK, gin.H{"dtm_result": "FAILURE"})
return
}
c.JSON(http.StatusOK, gin.H{"dtm_result": "SUCCESS"})
})
r.POST("/order-create-confirm", func(c *gin.Context) {
// 确认,生成订单信息,插入 orders 和 order_products 表记录,本例中,仅使用 order_products 表
req := &Req{}
if err := c.BindJSON(req); err != nil {
log.Fatalln(err)
}
orderId := 0
query := "select id from orders where tx_id=?"
if err := DB.QueryRow(query, req.TxId).Scan(&orderId); err != nil {
log.Fatalln(err)
}
query = "insert into order_products values (?, ?, ?, 99)"
if _, err := DB.Exec(query, orderId, req.Id, req.Quantity); err != nil {
c.JSON(http.StatusOK, gin.H{"dtm_result": "FAILURE"})
return
}
c.JSON(http.StatusOK, gin.H{"dtm_result": "SUCCESS"})
})
r.POST("/order-create-cancel", func(c *gin.Context) {
// 取消,删除订单记录
req := &Req{}
if err := c.BindJSON(req); err != nil {
log.Fatalln(err)
}
query := "delete from orders where tx_id = ?"
if _, err := DB.Exec(query, req.TxId); err != nil {
c.JSON(http.StatusOK, gin.H{"dtm_result": "FAILURE"})
return
}
c.JSON(http.StatusOK, gin.H{"dtm_result": "SUCCESS"})
})
r.Run(":8081")
}
package main
import (
"database/sql"
"github.com/gin-gonic/gin"
_ "github.com/go-sql-driver/mysql"
"log"
"net/http"
)
var DB *sql.DB
func init() {
db, err := sql.Open("mysql", "root:mashibing@tcp(192.168.177.131:3306)/tcc?charset=utf8mb4&parseTime=True&loc=Local")
if err != nil {
log.Fatalln(err)
}
DB = db
}
type Req struct {
Quantity int `json:"quantity"`
Id int `json:"id"`
TxId string `json:"tx_id"`
}
func main() {
r := gin.Default()
r.POST("/order-create-try", func(c *gin.Context) {
req := &Req{}
if err := c.BindJSON(req); err != nil {
log.Fatalln(err)
}
// 完成业务逻辑校验
// 本例中不需要校验,在库存服务检测库存即可
// 我们选择,先生成订单记录。若分布式事务校验通过,则创建订单和商品关联记录,否则删除该订单记录
query := "insert into orders values (null, ?, 1024)"
if _, err := DB.Exec(query, req.TxId); err != nil {
c.JSON(http.StatusOK, gin.H{"dtm_result": "FAILURE"})
return
}
c.JSON(http.StatusOK, gin.H{"dtm_result": "SUCCESS"})
})
r.POST("/order-create-confirm", func(c *gin.Context) {
// 确认,生成订单信息,插入 orders 和 order_products 表记录,本例中,仅使用 order_products 表
req := &Req{}
if err := c.BindJSON(req); err != nil {
log.Fatalln(err)
}
orderId := 0
query := "select id from orders where tx_id=?"
if err := DB.QueryRow(query, req.TxId).Scan(&orderId); err != nil {
log.Fatalln(err)
}
query = "insert into order_products values (?, ?, ?, 99)"
if _, err := DB.Exec(query, orderId, req.Id, req.Quantity); err != nil {
c.JSON(http.StatusOK, gin.H{"dtm_result": "FAILURE"})
return
}
c.JSON(http.StatusOK, gin.H{"dtm_result": "SUCCESS"})
})
r.POST("/order-create-cancel", func(c *gin.Context) {
// 取消,删除订单记录
req := &Req{}
if err := c.BindJSON(req); err != nil {
log.Fatalln(err)
}
query := "delete from orders where tx_id = ?"
if _, err := DB.Exec(query, req.TxId); err != nil {
c.JSON(http.StatusOK, gin.H{"dtm_result": "FAILURE"})
return
}
c.JSON(http.StatusOK, gin.H{"dtm_result": "SUCCESS"})
})
r.Run(":8081")
}
附件
CentOS 7.x 在 vmware 虚拟机中的安装
Docker 在 CentOS 7.x 上的安装
Putty 的安装
dig 的安装
若没有 dig 命令(CentOS 默认没有 dig 命令),下面的命令可以安装:
sudo yum -y install bind-utils


















 510
510

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











