







(一)完成
Hive的安装和配置Mysql接口。①下载并解压
Hive安装包
a. 压缩格式的文件apache-hive-3.1.2-bin.tar.gz已经下载并保存在“/home/hadoop/下载/”目录下。
b. 将apache-hive-3.1.2-bin.tar.gz解压到/usr/local中。
c. 将文件夹名改为hive并修改文件权限。
②配置环境变量
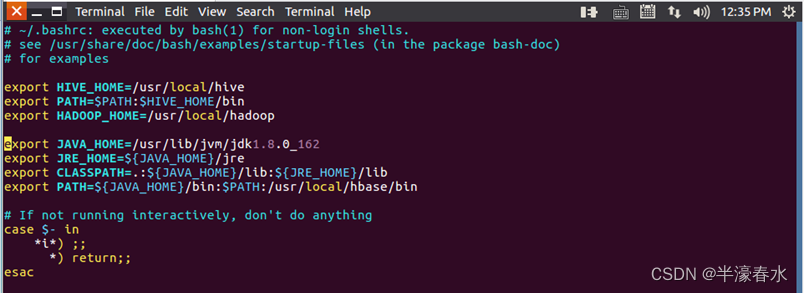
a. 为了方便使用,把hive命令加入到环境变量中去,使用vim编辑器打开.bashrc文件。在该文件最前面一行添加如下内容:


export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
export HADOOP_HOME=/usr/local/Hadoop
b. 保存退出后,运行如下命令使配置立即生效。
③ 修改/usr/local/hive/conf下的hive-site.xml
a. 执行如下命令,将hive-default.xml.template重命名为hive-default.xml。
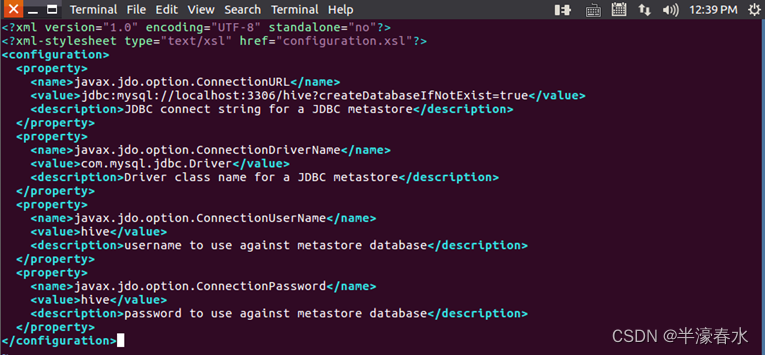
b. 然后使用vim编辑器新建一个配置文件hive-site.xml,在hive-site.xml中添加如下配置信息。
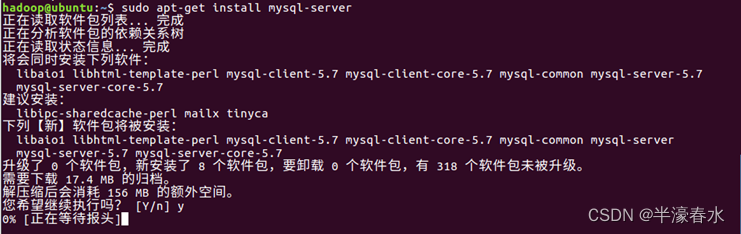
④Ubuntu系统下安装mysql
a. 安装mysql前先更新一下软件源以获得最新版本,安装过程会提示设置mysql root用户的密码,设置完成后等待自动安装即可。默认安装完成就启动了mysql。
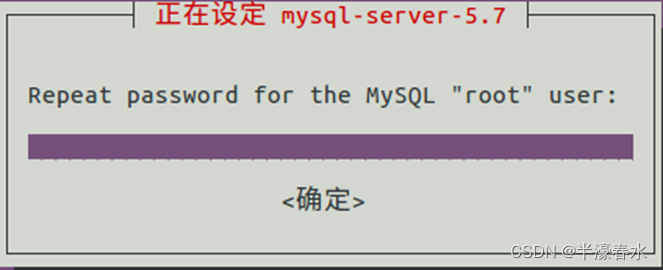
提示设置密码和确认密码




b. 启动和关闭mysql服务器。

c. 确认是否启动成功,
mysql节点处于LISTEN状态表示启动成功。
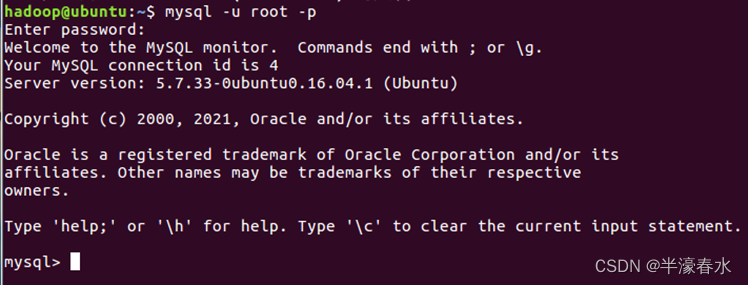
d. 进入mysql shell界面。
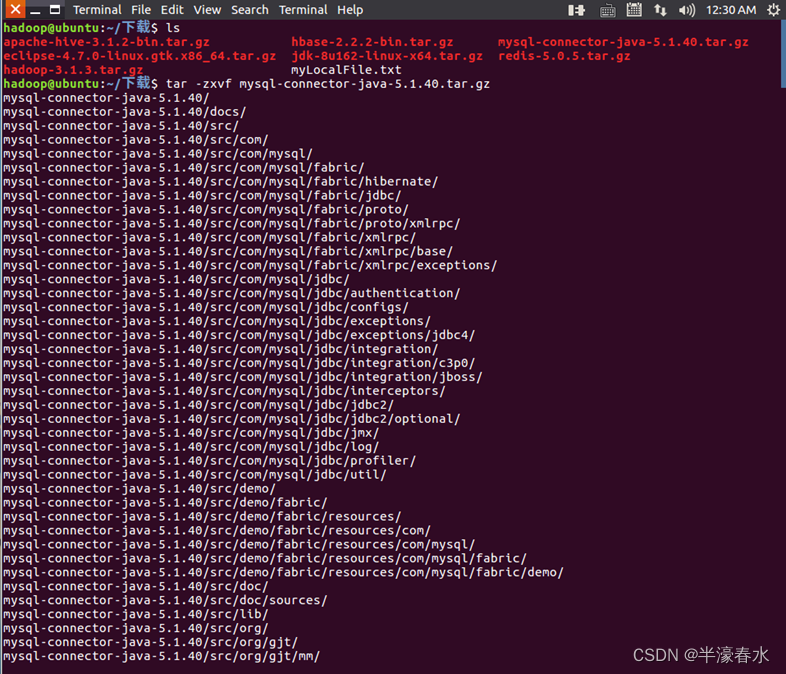
⑤压缩格式的文件mysql-connector-java-5.1.40.tar.gz已经下载并保存在“/home/hadoop/下载/”目录下,解压mysql jdbc包并将其拷贝到/usr/local/hive/lib目录下。
⑥启动并登陆mysql shell。
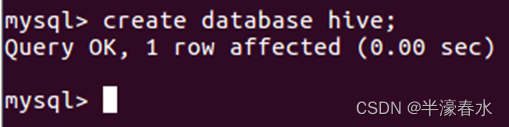
⑦新建hive数据库。
⑧配置mysql允许hive接入,将所有数据库的所有表的所有权限赋给hive用户,并刷新mysql系统权限关系表。
⑨启动hive(先启动hadoop集群)
a.若已经配置了PATH,可以使用如下命令启动hadoop集群和hive。



start-dfs.sh #启动Hadoop的HDFS
hive #启动hive
b. 如果没有配置PATH,请加上路径才能运行命令。
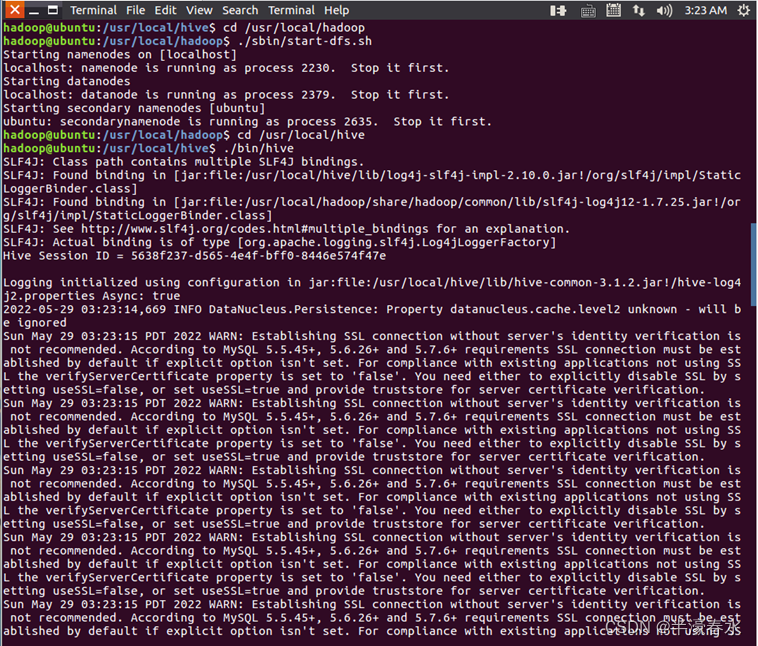
启动进入
Hive的交互式执行环境以后,会出现如下命令提示符。
(二)了解
Hive的基本数据类型。列出各种数据类型。Hive支持基本数据类型和复杂类型, 基本数据类型主要有数值类型(
INT、FLOAT、DOUBLE) 、布尔型和字符串, 复杂类型有三种:ARRAY、MAP和STRUCT。
a.基本数据类型
TINYINT1个字节
SMALLINT2个字节
INT4个字节
BIGINT8个字节
BOOLEANTRUE/FALSE
FLOAT4个字节,单精度浮点型
DOUBLE8个字节,双精度浮点型STRING字符串
b. 复杂数据类型
ARRAY有序字段
MAP无序字段
STRUCT一组命名的字段(三)完成
Hive的基本操作。(1)
Hive常用的HiveQL操作–数据定义
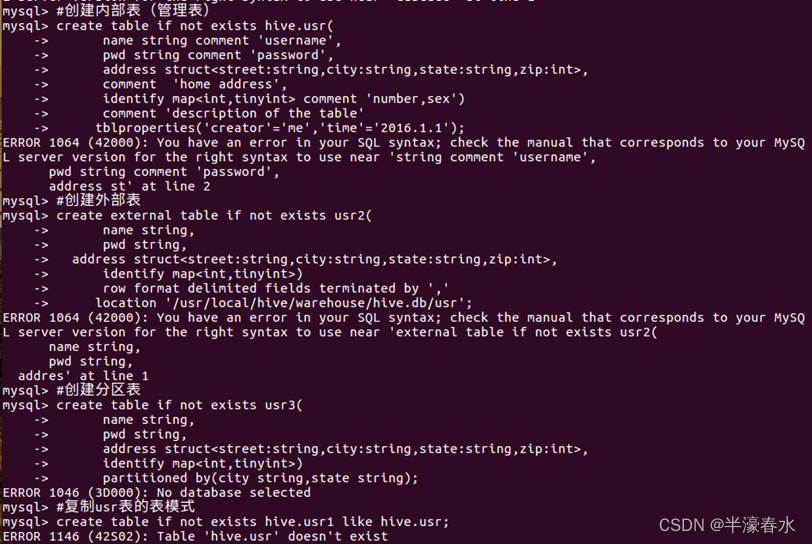
①创建、修改和删除数据库
a. 创建数据库。
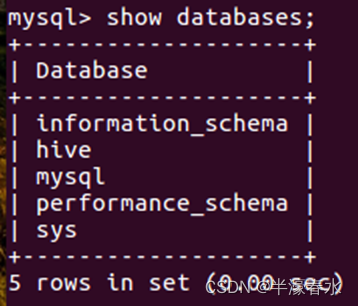
b. 查看Hive中包含数据库。
c. 查看Hive中以h开头数据库。
d. 切换到hive数据库下。
e. 删除不含表的数据库。
②创建、修改和删除表。
③视图和索引的创建、修改和删除。
a.创建和修改视图(因为视图是只读的,所以对于视图只允许改变元数据中的tblproperties属性。)




create view view_name as....; #创建视图
alter view view_name set tblproperties(…); #修改视图
b.删除视图和创建索引。
drop view if exists view_name; #删除视图
create index index_name on table table_name(partition_name/column_name)
as 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler' with deferred rebuild....; #创建索引
c.这里’
org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler’是一个索引处理器,即一个实现了索引接口的Java类,另外Hive还有其他的索引实现。
alter index index_name on table table_name partition(...) rebulid; #重建索引
d.如果使用
deferred rebuild,那么新索引成空白状态,任何时候可以进行第一次索引创建或重建。
show formatted index on table_name; #显示索引
drop index if exists index_name on table table_name; #删除索引
④用户自定义函数
a.show functions;显示Hive中所有的函数名称。
b. 查看具体函数使用方法可使用describe function函数名。
c. 编写自己的UDF前需要继承UDF类并实现evaluate()函数,或是继承GenericUDF类实现initialize()函数、evaluate()函数和getDisplayString()函数。
如果想在Hive中使用该UDF需要将我们编写的Java代码进行编译,然后将编译后的UDF二进制类文件(.class文件)打包成一个JAR文件,然后在Hive会话中将这个JAR文件加入到类路径下,在通过create function语句定义好使用这个Java类的函数。


add jar <jar文件的绝对路径>; #创建函数
create temporary function function_name;
drop temporary function if exists function_name; #删除函数
(2)
Hive常用的HiveQL操作–数据定义
数据操作主要实现的是将数据装载到表中(或是从表中导出),并进行相应查询操作,对熟悉SQL语言的用户应该不会陌生。
①向表中装载数据
这里以只有两个属性的简单表为例来介绍。首先创建表stu和course,stu有两个属性id与name,course有两个属性cid与sid。
向表中装载数据有两种方法:从文件中导入和通过查询语句插入。
a. 从文件中导入
假如这个表中的记录存储于文件stu.txt中,该文件的存储路径为/usr/local/hadoop/examples/stu.txt,内容如下。

1 xiapi
2 xiaoxue
3 qingqing
下面我们把这个文件中的数据装载到表
stu中,操作语句如下。
load data local inpath '/usr/local/hadoop/examples/stu.txt' overwrite into table stu;
如果
stu.txt文件存储在HDFS上,则不需要local关键字。
b.通过查询语句插入
创建和stu表属性相同的表stu1,把从stu表中查询得到的数据插入到stu1中:
create table stu1 as select id,name from stu;
上面是创建表,并直接向新表插入数据;若表已经存在,向表中插入数据需执行以下命令:
insert overwrite table stu1 select id,name from stu where(条件);
这里关键字
overwrite的作用是替换掉表(或分区)中原有数据,换成into关键字,直接追加到原有内容后。
②从表中导出数据
a.简单拷贝文件或文件夹
hadoop fs -cp source_path target_path;
b.写入临时文件
insert overwrite local directory '/usr/local/hadoop/tmp/stu' select id,name from stu;
③查询操作和
SQL的查询完全一样,主要使用select…from…where…等语句,再结合关键字group by、having、like、rlike等操作。 例如case…when…then…句式和if条件语句类似,用于处理单个列的查询结果。
④连接
连接(join)是将两个表中在共同数据项上相互匹配的那些行合并起来,HiveQL的连接分为内连接、左向外连接、右向外连接、全外连接和半连接5种。
a. 内连接(等值连接)
内连接使用比较运算符根据每个表共有的列的值匹配两个表中的行。把以下内容插入到course表中。

1 3
2 1
3 1
查询stu和course表中学号相同的所有行
select stu.*, course.* from stu join course on(stu .id=course .sid);

b. 左连接 左连接的结果集包括“
LEFT OUTER”子句中指定的左表的所有行, 而不仅仅是连接列所匹配的行。如果左表的某行在右表中没有匹配行, 则在相关联的结果集中右表的所有选择列均为空值。
select stu.*, course.* from stu left outer join course on(stu .id=course .sid);

c. 右连接
右连接是左向外连接的反向连接,将返回右表的所有行。如果右表的某行在左表中没有匹配行,则将为左表返回空值。
select stu.*, course.* from stu right outer join course on(stu .id=course .sid);
d. 全连接
全连接返回左表和右表中的所有行。当某行在另一表中没有匹配行时,则另一个表的选择列表包含空值。如果表之间有匹配行,则整个结果集包含基表的数据值。
select stu.*, course.* from stu full outer join course on(stu .id=course .sid);
e. 半连接
半连接是Hive所特有的,Hive不支持in操作,但是拥有替代的方案;
left semi join, 称为半连接, 需要注意的是连接的表不能在查询的列中,只能出现在on子句中。

select stu.* from stu left semi join course on(stu .id=course .sid);
⑤子查询
标准SQL的子查询支持嵌套的select子句,HiveQL对子查询的支持很有限,只能在from引导的子句中出现子查询。(四)在
hive中实现wordcount。①
MapReduce实现词频统计的代码可以通过下载Hadoop源码后,在/usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar包中找到(wordcount类)。
②创建input目录,output目录会自动生成。其中input为输入目录,output目录为输出目录。
③在input文件夹中创建两个测试文件file1.txt和file2.txt。
④执行如下hadoop命令。
⑤可以到output文件夹中查看结果。
⑥通过HiveQL实现词频统计功能,不需要进行编译生成jar来执行。
执行后,用select语句查看结果。
(五)为什么要设计
Hive?①
hadoop学习难度大,成本高,坡度陡,设计Hive可以降使用hadoop的难度,降低学习成本。
②Hive提供了一种SQL(结构化查询语言)方言,可以查询存储在Hadoop分布式文件系统(HDFS)中的数据或其他和Hadoop集成的文件系统。
③大多数数据仓库应用程序都是使用关系数据库进行实现的,并使用SQL作为查询语言。Hive降低了将这些应用程序转移到Hadoop系统上的难度。
④Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。(六)在hive中实现
wordcount和直接写java程序有什么区别和相似?①区别:相比直接写
java程序,在hive中实现wordcount的最大优势是不用编写Java代码。
MapReduce代码了,只需使用HiveQL。
②相似:都是使用词频统计算法来统计单词出现的次数。





















 793
793











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









