






环境配置
-
Linux主机:8G运行内存

-
MySQL 8.0.20

前期准备
表设计
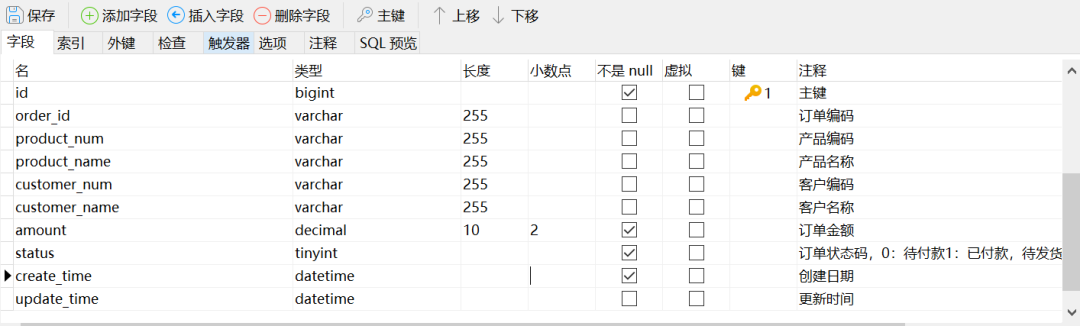
建表SQL
-- ----------------------------
-- Table structure for t_orders
-- ----------------------------
DROP TABLE IF EXISTS `t_orders`;
CREATE TABLE `t_orders` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键',
`order_id` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '订单编码',
`product_num` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '产品编码',
`product_name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '产品名称',
`customer_num` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '客户编码',
`customer_name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '客户名称',
`amount` decimal(10, 2) NOT NULL COMMENT '订单金额',
`status` tinyint NOT NULL COMMENT '订单状态码,0:待付款\r\n1:已付款,待发货\r\n2:已发货\r\n3:已完成\r\n4:已取消',
`create_time` datetime NOT NULL COMMENT '创建日期',
`update_time` datetime NULL DEFAULT NULL COMMENT '更新时间',
PRIMARY KEY (`id`) USING BTREE,
INDEX `idx_custnum_status_createtime`(`customer_num` ASC, `status` ASC, `create_time` ASC) USING BTREE,
INDEX `idx_order_id`(`order_id` ASC) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci COMMENT = '订单表' ROW_FORMAT = DYNAMIC;
测试数据:
INSERT INTO `t_orders` VALUES (1, '10000000000001', 'PDT2024060101', '智能运动手环', 'CUST202401', '张伟', 299.99, 1, '2024-06-22 15:49:11', '2024-06-22 15:49:11');
INSERT INTO `t_orders` VALUES (2, '10000000000002', 'PDT2024060102', '儿童玩具车', 'CUST202402', '王芳', 159.99, 2, '2024-06-22 15:49:11', '2024-06-22 15:49:11');
INSERT INTO `t_orders` VALUES (3, '10000000000003', 'PDT2024060103', '多功能电钻', 'CUST202403', '李娜', 399.99, 3, '2024-06-22 15:49:11', '2024-06-22 15:49:11');
INSERT INTO `t_orders` VALUES (4, '10000000000004', 'PDT2024060104', '女士时尚太阳镜', 'CUST202404', '刘强', 199.99, 0, '2024-06-22 15:49:11', '2024-06-22 15:49:11');
INSERT INTO `t_orders` VALUES (5, '10000000000005', 'PDT2024060105', '男士运动鞋', 'CUST202405', '陈敏', 249.99, 1, '2024-06-22 15:49:11', '2024-06-22 15:49:11');
INSERT INTO `t_orders` VALUES (6, '10000000000006', 'PDT2024060106', '婴儿奶粉', 'CUST202406', '赵静', 129.99, 2, '2024-06-22 15:49:11', '2024-06-22 15:49:11');
INSERT INTO `t_orders` VALUES (7, '10000000000007', 'PDT2024060107', '智能手表', 'CUST202407', '黄丽', 499.99, 3, '2024-06-22 15:49:11', '2024-06-22 15:49:11');
INSERT INTO `t_orders` VALUES (8, '10000000000008', 'PDT2024060108', '女士连衣裙', 'CUST202408', '周杰', 99.99, 0, '2024-06-22 15:49:11', '2024-06-22 15:49:11');
INSERT INTO `t_orders` VALUES (9, '10000000000009', 'PDT2024060109', '无线蓝牙耳机', 'CUST202409', '吴鑫', 299.99, 4, '2024-06-22 15:49:11', '2024-06-22 15:49:11');
INSERT INTO `t_orders` VALUES (10, '10000000000010', 'PDT2024060110', '男士休闲裤', 'CUST2024010', '朱燕', 150.99, 1, '2024-06-22 15:49:11', '2024-06-22 15:49:11');
大数据量模拟(存储过程模拟:千万级)
-- 删除存储过程
DROP PROCEDURE IF EXISTS batchInsertBigData;
-- 创建存储过程
DELIMITER $$
CREATE PROCEDURE batchInsertBigData(IN args INT)
BEGIN
DECLARE i INT DEFAULT 1;
DECLARE order_id BIGINT DEFAULT 0;
-- 开启事务
START TRANSACTION;
WHILE i <= args DO
-- 生成唯一的订单编码,这里简单地使用当前时间戳和自增变量的组合
SET order_id = (UNIX_TIMESTAMP() * 1000) + i;
-- 插入数据
INSERT INTO t_orders_bigdata (
`order_id`,
`product_num`,
`product_name`,
`customer_num`,
`customer_name`,
`amount`,
`status`,
`create_time`,
`update_time`
) VALUES (
order_id, -- 使用生成的订单编码
CONCAT('PDT', LPAD(i, 6, '0')), -- 产品编号,左填充为6位数字
CONCAT('Product-', i), -- 产品名称
CONCAT('CUST', LPAD((i % 1000) + 1, 6, '0')), -- 假设有1000个客户编号循环使用
CONCAT('Customer-', (i % 1000) + 1), -- 客户名称
ROUND((RAND() * 100) + 100, 2), -- 随机生成100到200的订单金额
CASE WHEN i % 5 = 0 THEN 0 WHEN i % 3 = 0 THEN 1 ELSE 2 END, -- 随机分配几种状态
NOW(), -- 创建时间
NOW() -- 更新时间
);
SET i = i + 1;
END WHILE;
COMMIT;
END$$
DELIMITER ;
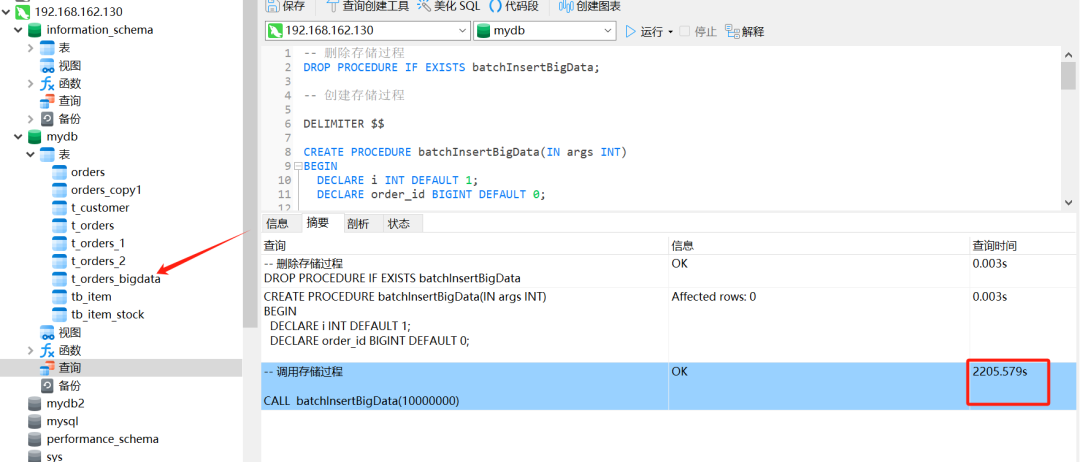
-- 调用存储过程
CALL batchInsertBigData(10000000);
备注:本机 8G 运行内存,插入1000W数据,执行相对耗时约:30多分钟。
MySQL 命令储备
-- 查看数据库里正在执行的sql语句
show processlist;
-- 登陆数据库现场抓(显示完整的进程列表)
show full processlist;
-- 查看数据库的配置参数信息,例如:my.cnf里参数的生效情况
show variables;
-- MySQL服务器运行各种状态值,查询MySQL服务器配置信息语句
show variables like '%log_bin%';
-- 查看当前会话的数据库状态信息
show session status;
-- 查看整个数据库运行状态信息,分析并做好监控
show global status;
-- 显示innodb 引擎的性能状态
show engine innodb status;
-- explain语句检查索引执行情况,将上边抓到的慢语句,进行一个索引检查
explain select * from test_table where ***
性能分析
1、什么是慢查询?
慢查询日志,就是查询花费大量时间的日志,是指mysql记录所有执行超过long_query_time参数设定的时间阈值的SQL语句的日志。默认情况下,慢查询日志是关闭的,要使用慢查询日志功能,首先要开启慢查询日志功能。
2、如何定位慢SQL?
-
性能监控
1、简单版:show profile;
执行 SHOW PROFILE 命令时,它会显示关于服务器线程执行的详细信息,包括每个线程所执行的每个语句的执行时间、I/O 操作、上下文切换等。注意:通常在开发和问题诊断期间使用,而不是在生产环境中持续启用。
具体操作:
-- 启用性能监控
mysql> set profiling=1;
Query OK, 0 rows affected, 1 warning (0.00 sec)
-- 执行SQL
mysql> select * from mydb.t_orders limit 10;
-- 性能分析
mysql> show profiles;
2、详细版本:performance_schema
performance_schema 用于监控和分析数据库服务器的性能。它提供了详细的数据库活动信息,包括线程、锁、I/O 操作、内存使用情况等。
--查看performance_schema的属性
mysql> SHOW VARIABLES LIKE 'performance_schema';
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| performance_schema | ON |
+--------------------+-------+
1 row in set (0.01 sec)
--在配置文件中修改performance_schema的属性值,on表示开启,off表示关闭
[mysqld]
performance_schema=ON
--切换数据库
mysql> use performance_schema;
--查看当前数据库下的所有表,会看到有很多表存储着相关的信息
mysql> show tables;
默认情况下,performance_schema是启用的。如果需要禁用,可以在启动MySQL服务器时使用--skip-perf-schema选项。
3、查看SQL运行列表
mysql> show processlist;
请注意,频繁地运行 SHOW PROCESSLIST 尤其是在高负载的系统中,可能会对性能产生一定影响,因为它需要遍历当前所有活动线程的信息。谨慎使用。
-
开启慢查询日志
1、查看是否开启慢查询日志?
-- 默认关闭 OFF
mysql> show variables like '%slow_query_log%';
+---------------------+----------------------------------------------------+
| Variable_name | Value |
+---------------------+----------------------------------------------------+
| slow_query_log | OFF |
| slow_query_log_file | /usr/local/mysql/mysql-8.0/data/localhost-slow.log |
+---------------------+----------------------------------------------------+
2 rows in set (0.00 sec)
2、如何开启慢查询日志?
注意:不同版本,这些配置稍有差异。出现设置错误时,可查官网获得正确的规则。这里
-- 持久性,通过配置文件设置
[mysqld]
log_output=FILE,TABLE
slow_query_log=ON
long_query_time=0.001
slow_query_log_file = /usr/local/mysql/mysql-8.0/logs/slow_query.log
#一次性的,通过命令设置, long_query_time 是时间阈值。为方便测试,此处认为超过0.001s的就属于慢查询
mysql> SET GLOBAL log_output = 'FILE,TABLE';
mysql> set GLOBAL slow_query_log=ON;
mysql> SET GLOBAL long_query_time = 0.001;
mysql> SET GLOBAL slow_query_log_file = '/usr/local/mysql/mysql-8.0/logs/slow_query.log';
3、如何分析慢查询日志?
3.1 查MySQL自带的数据库表进行分析
mysql> SELECT * from mysql.slow_log ;
3.2 慢查询日志文件分析
-- 查看慢日志位置
mysql> SHOW VARIABLES LIKE '%slow_query_log_file%';
+---------------------+------------------------------------------------+
| Variable_name | Value |
+---------------------+------------------------------------------------+
| slow_query_log_file | /usr/local/mysql/mysql-8.0/logs/slow_query.log |
+---------------------+------------------------------------------------+
1 row in set (0.00 sec)
-- 使用./mysqldumpslow 查看慢SQL日志
[root@localhost bin]# ./mysqldumpslow /usr/local/mysql/mysql-8.0/logs/slow_query.log
慢日志结果:
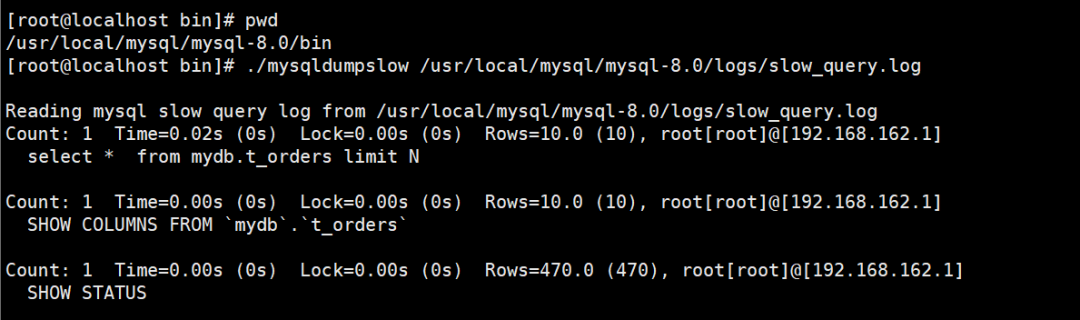
如图,可以查看具体的慢SQL列表和耗时等信息。
小结
综上,我们知道如何定位慢SQL。接下来通过各种实践案例尝试优化SQL性能。
SQL调优实战
explain + sql 执行计划
EXPLAIN 是一个用于获取 SQL 语句执行计划的命令,用于帮助理解查询的执行过程以及如何优化。这里主要是索引优化 ,关于索引原理暂不做详细介绍。本章主要以实操为主。
基本用法:
explain select ...
参数说明:
-
id: 选择查询中执行的顺序,从1开始递增。
-
select_type: 查询类型,如 SIMPLE、PRIMARY、SUBQUERY 等。
-
table: 涉及的表名。
-
partitions: 表分区信息。
-
type: 连接类型,如 ALL、index、range、ref、eq 等。
-
possible_keys: 可能用于查找的索引。
-
key: 实际使用的索引。
-
key_len: 使用的索引的长度。
-
ref: 与索引比较的列或常量。
-
rows: 估计需要检查的行数。
-
filtered: 根据 WHERE 子句过滤后剩余的行的比例。
-
Extra: 额外的信息,如是否使用临时表、是否排序等。
性能分析:
-- type 级别
system > const > eq_ref > ref > range > index > ALL
-
system: 表仅有一行,如 PRIMARY KEY 或 UNIQUE INDEX 约束下的唯一索引。
-
const: 针对主键或唯一索引的查找,通常因为条件完全匹配索引列。
-
eq_ref: 对于非唯一索引,当查找条件涉及多表的连接,并且使用主键或唯一索引列进行等值匹配。
-
ref: 使用非唯一索引进行查找,适用于非主键或唯一索引的列。
-
range: 索引范围扫描,适用于 BETWEEN, IN, WHERE 子句中的范围查询。
-
index: 索引全表扫描,比全表扫描 (ALL) 快,因为索引通常更紧凑。
备注:一般要求至少达到range 级别,最好达到ref
有了上述了解,我们进行案例实操。。。
案例实操
1、select * 查询不需要的列
例如:查看特定客户编号的所有订单详情,但只关心订单编号和金额。
如果查询所有字段,
mysql> select * from t_orders t where t.customer_num = 'CUST202401';
由于其它字段会带来额外的开销,尤其是使用二级索引,
使用select * 的方式会导致回表,导致性能低下。因此应当只获取需要的字段。
mysql> SELECT order_id, amount from t_orders t where t.customer_num = 'CUST202401';
因此,一些DBA是严格禁止SELECT *的写法的。
2、limit a,b 分页优化
例如,查询返回 t_orders_bigdata 表中的第 100001~100010 行数据。
mysql> SELECT * FROM t_orders_bigdata LIMIT 1000000, 10;
MySQL会查询出全部的结果集,客户端的应用程序会接收全部的结果集数据,然后抛弃其中大部分数据。在某些情况下,如果数据页不是顺序存储的,这可能会导致全表扫描。
优化后,
mysql> SELECT * from mydb.t_orders_bigdata t ORDER BY id LIMIT 1000000, 10;
如果 id 是索引列(主键通常是索引),MySQL 可以使用索引来快速定位到第 100001 行数据,而不需要扫描前面所有的行。
3、索引列上操作(使用函数、计算等)导致索引失效
例如,为了获取 2024 年的所有订单数据,可能会执行以下 SQL 查询:
SELECT * FROM t_orders WHERE YEAR(create_time) = 2024;
我们看到在 create_time 字段上有索引,
mysql> show index from t_orders;
+----------+------------+-----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+----------+------------+-----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| t_orders | 0 | PRIMARY | 1 | id | A | 0 | NULL | NULL | | BTREE | | | YES | NULL |
| t_orders | 1 | idx_create_time | 1 | create_time | A | 1 | NULL | NULL | | BTREE | | | YES | NULL |
+----------+------------+-----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
2 rows in set (0.00 sec)
查看执行计划
-- type = ALL,显然是全表扫描,查询未走索引。
mysql> explain SELECT * FROM t_orders WHERE YEAR(create_time) = 2024;
+----+-------------+----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | t_orders | NULL | ALL | NULL | NULL | NULL | NULL | 164571 | 100.00 | Using where |
+----+-------------+----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
优化:
-- 1、使用索引列的日期范围,type= range ,走索引
mysql> explain SELECT * FROM t_orders WHERE create_time >= '2024-01-01 00:00:00' AND create_time < '2025-01-01 00:00:00';
+----+-------------+----------+------------+-------+-----------------+-----------------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+-------+-----------------+-----------------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | t_orders | NULL | range | idx_create_time | idx_create_time | 5 | NULL | 10 | 100.00 | Using index condition |
+----+-------------+----------+------------+-------+-----------------+-----------------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
4、最佳左前缀法则
建立了联合索引列,如果搜索条件不够全值匹配怎么办?
在我们的搜索语句中也可以不用包含全部联合索引中的列,但要遵守最左前缀法则。指的是查询从索引的最左前列开始并且不跳过索引中的列。即搜索条件中必须出现左边的列才可以使用到这个B+树索引
如图已建立联合索引,

例如:统计某用户,在某个时间,待付款的订单。
案例说明:
1、跳过开头customer_num,查询联合索引中的部分字段 status,
-- 跳过开头customer_num,查询联合索引中的部分字段 status,
-- 结果:type=ALL, 全表扫描,未走索引
mysql> explain select * from mydb.t_orders t where t.status = '1' ;
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | t | NULL | ALL | NULL | NULL | NULL | NULL | 164571 | 10.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
2、 跳过开头customer_num,查询其它字段update_time;
-- 跳过开头customer_num,查询其它字段update_time;
-- 结果:type=ALL, 全表扫描,未走索引
mysql> explain select * from mydb.t_orders t where t.update_time = '2024-06-22 15:49:11' and t.`status` = '1' ;
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | t | NULL | ALL | NULL | NULL | NULL | NULL | 164571 | 1.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
3、全匹配,查询where条件索引字段
-- 全匹配场景:ref = const,const,const,代表联合索引生效
mysql> explain select * from mydb.t_orders t where t.customer_num = 'CUST202401' and t.create_time = '2024-06-22 15:49:11' and t.`status` = '1' ;
+----+-------------+-------+------------+------+-----------------------------------------------+-------------------------------+---------+-------------------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+-----------------------------------------------+-------------------------------+---------+-------------------+------+----------+-------+
| 1 | SIMPLE | t | NULL | ref | idx_create_time,idx_custnum_status_createtime | idx_custnum_status_createtime | 1028 | const,const,const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+-----------------------------------------------+-------------------------------+---------+-------------------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
4、全匹配,查询where条件非索引字段
-- 全匹配场景:ref = const,const,代表联合索引部分生效:customer_num,status
mysql> explain select * from mydb.t_orders t where t.customer_num = 'CUST202401' and t.`status` = '1' and t.update_time = '2024-06-22 15:49:11';
+----+-------------+-------+------------+------+-------------------------------+-------------------------------+---------+-------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+-------------------------------+-------------------------------+---------+-------------+------+----------+-------------+
| 1 | SIMPLE | t | NULL | ref | idx_custnum_status_createtime | idx_custnum_status_createtime | 1023 | const,const | 1 | 10.00 | Using where |
+----+-------------+-------+------------+------+-------------------------------+-------------------------------+---------+-------------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
左匹配原理
建立联合索引idx(customer_num,status,create_time) ,B+树的数据页和记录先是按照列customer_num的值排序的,在customer_num列的值相同的情况下才使用status列进行排序.
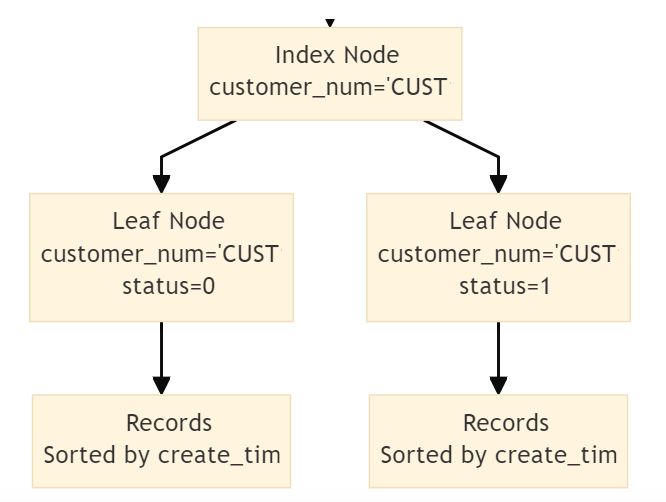
因此,我们想使用联合索引中尽可能多的列。一个原则,搜索条件中的各个列必须含有联合索引中从最左边索引列。
5、范围条件查询的先后原则
也是针对联合索引来说的,所有记录都是按照索引列的值从小到大的顺序排好序的,而联合索引则是按创建索引时的顺序进行分组排序。
为方便测试,现在只保留联合索引。

例如:统计创建时间:2024-05-22 15:49:11,未付款订单。
-- create_time 范围查询在前,不满足索引的顺序,导致失效
mysql> explain select * from mydb.t_orders t where t.create_time > '2024-05-22 15:49:11' and t.`status` = '1' ;
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | t | NULL | ALL | NULL | NULL | NULL | NULL | 164571 | 3.33 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
而中间有范围查询会导致后面的列全部失效,结果会怎样呢?
-- 中间有范围查询会导致后面的列全部失效,无法充分利用这个联合索引
-- 例如,status 使用范围,导致create_time 索引失效
mysql> explain select * from mydb.t_orders t where t.customer_num= 'CUST202400' and t.status > '-1' and t.create_time = '2024-06-22 15:49:11';
+----+-------------+-------+------------+-------+-------------------------------+-------------------------------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+-------------------------------+-------------------------------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | t | NULL | range | idx_custnum_status_createtime | idx_custnum_status_createtime | 1023 | NULL | 1 | 10.00 | Using index condition |
+----+-------------+-------+------------+-------+-------------------------------+-------------------------------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
思考:怎么知道上述 SQL 走了那些索引,我们给一个对比的图。

显然,两个查询SQL对应len都是1023,代表status建立的索引都生效。
6、慎用 (!= 或者<>)
如果我们在order_id列上加索引
-- 使用(!= 或者<>)
-- 结果:全表扫描
mysql> explain SELECT * FROM mydb.t_orders t WHERE t.order_id <> '10001';
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | t | NULL | ALL | idx_order_id | NULL | NULL | NULL | 10 | 100.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
7、使用 Null/Not NULL
这里注意:order_id 为空和不为空不太一样。
-
情景1:order_id不可为空,使用(Null)
-- 情景1:order_id不可为空,使用(Null)
-- 结果:Impossible WHERE,(查询语句的WHERE子句永远为FALSE时将会提示该额外信息)
mysql> explain SELECT * FROM mydb.t_orders t WHERE order_id is null;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+------------------+
| 1 | SIMPLE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | Impossible WHERE |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+------------------+
1 row in set, 1 warning (0.00 sec)
-
情景2:order_id可为空,使用(Null)
-- order_id可为空,使用(Null)
-- is null会走ref类型的索引访问
mysql> explain SELECT * FROM mydb.t_orders t WHERE order_id is null;
+----+-------------+-------+------------+------+---------------+--------------+---------+-------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+--------------+---------+-------+------+----------+-----------------------+
| 1 | SIMPLE | t | NULL | ref | idx_order_id | idx_order_id | 9 | const | 1 | 100.00 | Using index condition |
+----+-------------+-------+------------+------+---------------+--------------+---------+-------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
-
情景3:order_id不可为空,使用(NOT Null)
-- 情景1:order_id不可为空,使用(NOT Null)
--
mysql> explain SELECT * FROM mydb.t_orders t WHERE order_id is not null;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+
| 1 | SIMPLE | t | NULL | ALL | NULL | NULL | NULL | NULL | 10 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
-
情景4:order_id可为空,使用(NOT Null)
-- 情景1:order_id 可为空,使用(NOT Null)
--
mysql> explain SELECT * FROM mydb.t_orders t WHERE order_id is not null;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+
| 1 | SIMPLE | t | NULL | ALL | NULL | NULL | NULL | NULL | 10 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
小结
is not null容易导致索引失效,is null则会区分被检索的列是否为null,如果是null则会走ref类型的索引访问,如果不为null,也是全表扫描。
思考:使用联合索引时,情况如何呢?
8、字符类型加引号转化导致全表扫描
字符串不加单引号索引失效
-- 未加单引号,索引失效
mysql> explain SELECT * FROM mydb.t_orders t WHERE order_id = 10000000000001;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | t | NULL | ALL | idx_order_id | NULL | NULL | NULL | 10 | 10.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 3 warnings (0.00 sec)
-- 使用单引号,索引生效
mysql> explain SELECT * FROM mydb.t_orders t WHERE order_id = '10000000000001';
+----+-------------+-------+------------+------+---------------+--------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+--------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | t | NULL | ref | idx_order_id | idx_order_id | 1023 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+--------------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
9、使用or关键字时注意点
-
情境1. 在索引列上使用or
-- 在索引列上使用or, 索引生效
mysql> explain SELECT * FROM mydb.t_orders t WHERE order_id = '10000000000001' or order_id = '10000000000002' ;
+----+-------------+-------+------------+-------+---------------+--------------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+--------------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | t | NULL | range | idx_order_id | idx_order_id | 1023 | NULL | 2 | 100.00 | Using index condition |
+----+-------------+-------+------------+-------+---------------+--------------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
-
情境2. 在非索引列上使用or
-- 在非索引列上使用or, 索引失效。
mysql> explain SELECT * FROM mydb.t_orders t WHERE order_id = '10000000000001' or t.update_time = '2024-06-22 15:49:11' ;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | t | NULL | ALL | idx_order_id | NULL | NULL | NULL | 10 | 19.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
10、like以通配符开头('%abc...')导致索引失效
这是查询时常用的SQL: like以通配符开头('%abc...'),mysql索引失效会变成全表扫描的操作.
-- like以通配符开头('%abc...')导致索引失效, 导致全表扫描
mysql> explain SELECT * FROM mydb.t_orders t WHERE t.customer_num like '%CUST';
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | t | NULL | ALL | NULL | NULL | NULL | NULL | 10 | 11.11 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
11、使用索引扫描来做排序和分组
排序列包含非同一个索引的列
用来排序的多个列不是一个索引里的,这种情况也不能使用索引进行排序
mysql> explain SELECT t.order_id,t.customer_num FROM mydb.t_orders t order by t.order_id,t.customer_num;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+
| 1 | SIMPLE | t | NULL | ALL | NULL | NULL | NULL | NULL | 10 | 100.00 | Using filesort |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+
1 row in set, 1 warning (0.00 sec)
MySQL可以使用同一个索引既满足排序,又用于查找行。因此,如果可能,设计索引时应该尽可能地同时满足这两种任务,这样是最好的。
总结和思考
本章重点,对于一个假设的index(a, b, c)复合索引的使用情况:
WHERE 语句示例 | 索引使用情况 | 备注 |
|---|---|---|
where a = 3 | 使用到a | 只使用索引的第一个列a |
where a = 3 and b = 5 | 使用到a,b | 使用索引的前两列a和b |
where a = 3 and b = 5 and c = 4 | 使用到a, b, c | 完全使用索引的所有列a、b、c |
where b = 3 或 where b = 3 and c = 4 或 where c = 4 | 不使用索引 | 没有使用索引的第一个列a,索引不被使用 |
where a = 3 and c = 5 | 使用到a | b列缺失,但可以使用索引的a和c列 |
where a = 3 and b > 4 and c = 5 | 使用到a和b | 使用索引的a和b列,c列因为范围查询不能使用 |
where a = 3 and b like 'kk%' and c = 4 | 使用到a, b, c | 使用索引的a列和b列的模式匹配,以及c列 |
where a = 3 and b like '%kk' and c = 4 | 只用到a | 通配符在开头,b列的索引不能使用,c列同样 |
where a = 3 and b like '%kk%' and c = 4 | 只用到a | 通配符在两边,b列的索引不能使用,c列同样 |
where a = 3 and b like 'k%kk%' and c = 4 | 使用到a, b, c | 尽管有通配符,但b列的索引部分可用,可以使用整个索引 |















 42万+
42万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









