






Efficient Token-Guided Image-Text Retrieval with Consistent Multimodal Contrastive Training利用一致的多模态对比训练进行高效的标记引导的图像-文本检索
Abstract:摘要部分指出了目前图文检索领域现有的方法大多仅仅采用了细粒度或者粗粒度,但是忽略了细粒度和粗粒度之间的密切关联,因此导致了一些检索精度差或者计算量大的问题。因此在本文中,提出了一种将粗粒度和细粒度结合到一个框架的方法,即Token-Guided Dual Transformer(TGDT);除此之外文章还提出了一种新的训练目标Consistent Multimodal Contrastive(CMC)损失
代码: TGDT
Introduction和Related work:引言和相关工作部分主要将先前的工作分为三个类别:粗粒度检索、细粒度检索和视觉语言预训练。(这里就不过多赘述了,后面可以整理一下文章引用的这些文章)
接下来就是重点!!!!自动分割线..........
Fig. 1:图一主要展示了现有的一些检索方法的性能(文本检索图像的recall@1和推理时间,这里的推理时间是指完成测试子集所有样本的图像检索文字任务的时间)对比
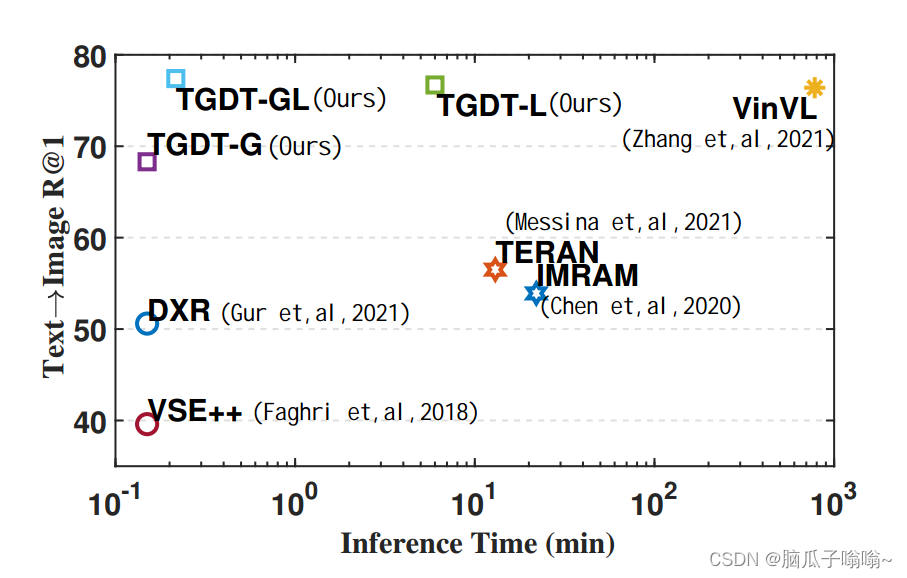
Fig. 2:Outline of the proposed framework for image-text retrieval. The global retrieval module captures holistic representations of the input image and text, while the local retrieval module aligns between image tokens and text tokens. During training, the proposed consistent multimodal contrastive loss jointly optimizes the two modules as well as network structures for both image and text modalities.
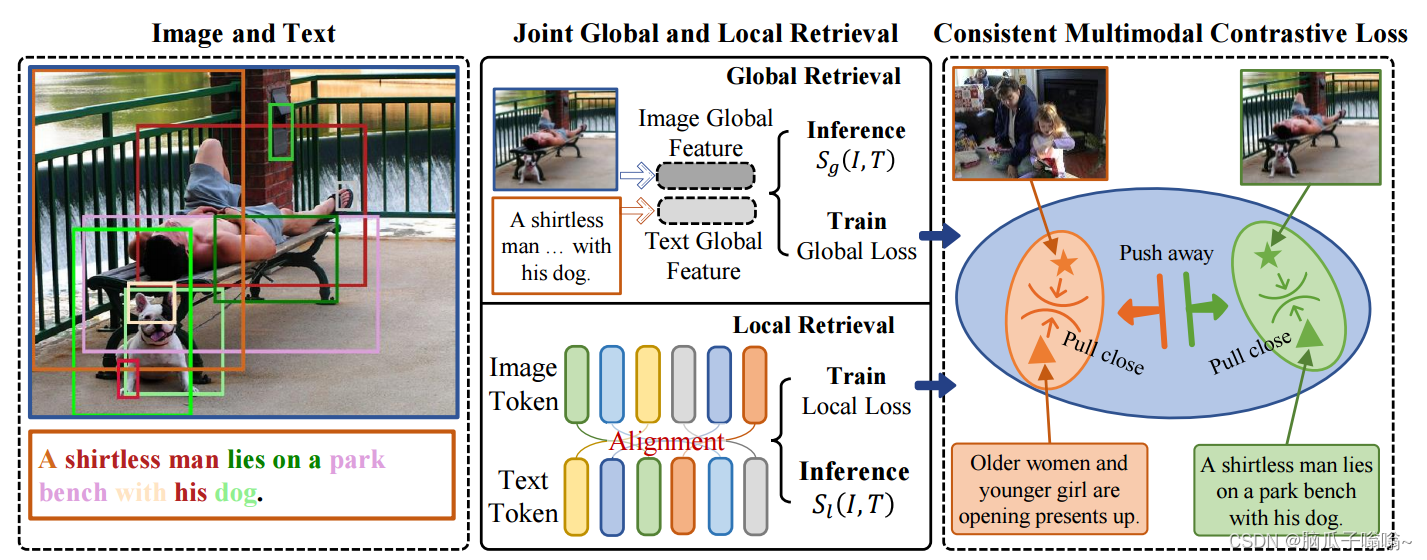
Fig. 3:Framework of the proposed Token-Guided Dual Transformer (TGDT) architecture. The image encoder first uses Faster R-CNN to generate locations of image instances as well as their corresponding features and the global image-level features for an input image. These token representations are then passed through the transformer encoder to obtain the cross-modal representations. The text encoder first uses BERT to generate word-level and sentence-level features for each text sample, and then generates the corresponding linguistic representations through another transformer encoder. The global retrieval directly matches the whole image features and the sentence-level text features, while the local retrieval obtains the cross-modal similarity after token-level alignment between image instance features and text word-level features. During training, the proposed Consistent Multimodal Contrastive Training (CMC) loss simultaneously trains the two networks. During inference, a two-stage method based on global and local similarity achieves both accuracy and efficiency.
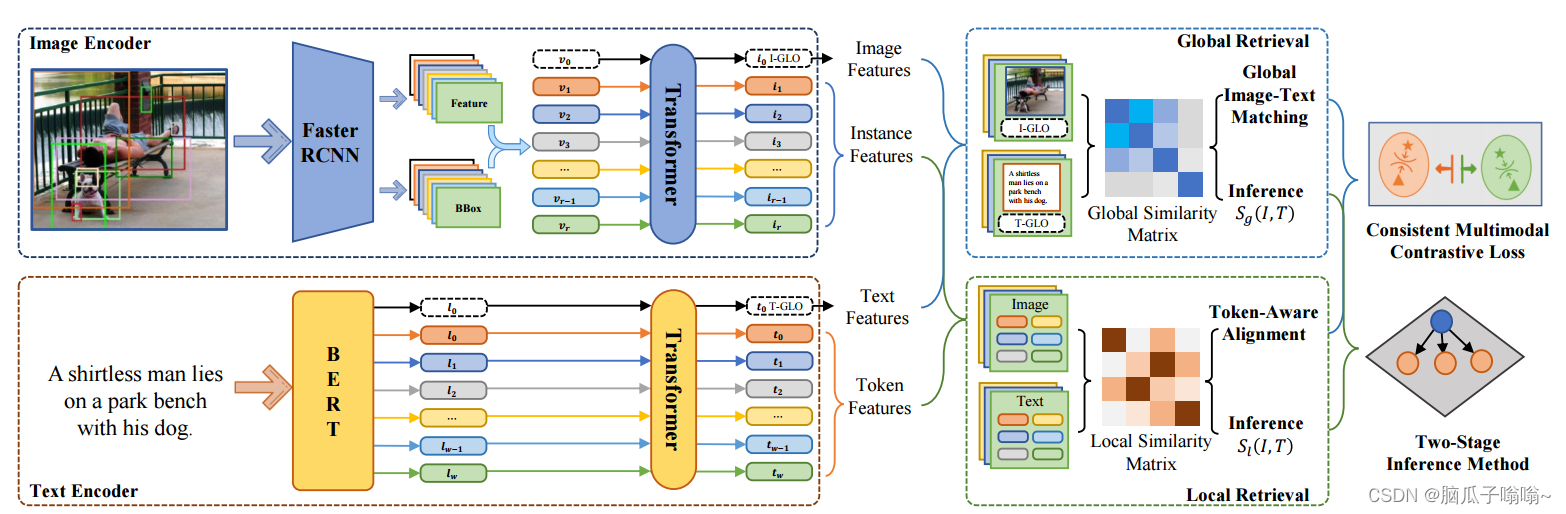
对于给定的图像image,送入到faster-rcnn网络中,会生成r个图像proposals来表示图像实例,也就是对应的特征向量,也就是从faster-rcnn中的得到的特征维度为d,以及边界框信息
,其中图像特征表示
,r代表了proposals的数量,
,相当于将proposals的特征和边界框拼接在一起,其中这个边界框
,其中这个w和h代表了图像的宽和高。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









