







摘要
互联网上拥有相同名字的个体数量正在增加,这使得搜索特定个体的任务变得繁琐。用户必须在许多具有相同名字的个人资料中进行筛选,以找到实际感兴趣的个体。个体的在线存在形成了其个人资料。我们需要一种解决方案,通过提取网络上可用的事实信息来帮助用户整合这些个体的个人资料,并将其作为单一结果提供。我们提出了一种新颖的解决方案,通过端到端的流程检索具有相同全名的个体的网络个人资料。我们的解决方案涉及从网络中检索信息(提取)、基于大语言模型驱动的命名实体提取(检索),以及使用维基百科标准化事实,返回具有十四个多值属性的个人资料。之后,确定与同一现实世界个体相对应的个人资料。我们通过基于提取的事实识别个人资料之间的相似性,使用受前缀树启发的数据结构(验证),并利用ChatGPT的上下文理解力(重新验证)来实现这一目标。该系统在整合这些个人资料时提供了不同级别的严格性,即严格匹配、宽松匹配和松散匹配。我们解决方案的新颖之处在于创新性地使用GPT——一个强大但不可预测的工具,来处理如此复杂的任务。一项涉及二十名参与者的研究及其他结果发现,可以有效检索特定个体的信息。
1 引言
数字环境中存在大量具有相同或相似名字的个体,分布在各种网络平台上。1990年美国人口普查局的数据表明,在一亿人口中,仅有90,000个独特名字[13]。使用人名在网络上搜索个体信息大约占搜索引擎查询的30%[2, 13]。这在在线世界中提出了三个关键方面的挑战——虚假表现、隐私和安全,其后果范围从无意的关联到故意的在线个人资料误导。考虑这样一种情况:一位知名的大会主题演讲者与多个人分享相同的名字,其中一些人甚至具有相似的背景。如果没有基于网络上事实信息区分这些网络个人资料的方法,用户可能会意外选择错误的个人资料或不匹配的个人资料。先前的研究探索了类似领域,例如报纸文章中的个体姓名和已出版作品中的作者姓名消歧。这些研究提出了多种技术,包括向量空间模型、命名实体提取和图模型,作为潜在的解决方案[24]。使用向量空间模型尝试进行跨文档共指(CDC)[4, 5],而利用生平事实(出生日期、出生地)进行网页聚类的技术也有研究[19]。许多成功的最先进(SOTA)方法所采用的常见技术包括使用预训练模型提取命名实体(NE)和利用TF-IDF函数加权的词袋模型(BoW)[11]。
关于提取和整合具有相同名字的网络个人资料的研究相对较少。目前的方法包括需要广泛特定任务训练的机器学习技术,以实现基线结果。在在线身份管理中需要清晰度的背景下,我们提出了一种新颖的解决方案,不仅帮助消歧,而且整合共享相同全名(名字和姓氏)的不同个人资料。我们的方法基于提取有价值的事实信息的原则——这些信息可以通过证据或提取的个人资料中的直接陈述进行验证,采用大型语言模型(LLMs)[25]、提示工程[3]和提取事实的标准化。我们的系统为用户提供了一系列个人资料匹配选项,每个选项在确定个人资料相似性时具有不同的精度。这些选择从严格到宽松到松散,能够有效满足用户的多样化偏好。所提出的方法论提供了多种用例,例如收集特定个体的信息、管理和增强个人数字足迹,以及作为改进网络人物搜索结果的额外层。

2 相关工作
2.1 使用NLP技术进行实体提取
在个体消歧的过程中,检索和分类文本中的实体或元素到不同类别是一个关键的数据处理任务。命名实体识别(NER)是实体提取中的一个重要子领域。Kamath和Wagh(2017)[16]讨论了各种监督、半监督和无监督的NER技术及其面临的挑战,这些挑战源于自然语言的固有复杂性,例如单词缩写、不同格式书写以及不常用的名字(地点/人)。NER方法在实体类型预定义且有大量高质量标注的场景中表现出色[17, 22]。然而,现实世界中的NER面临着实体类型的多样性、新实体类型的不断引入以及标注不足的问题[9]。
NER模型通常将文本识别和分类为四个类别——地点(LOC)、人(PER)、组织(ORG)和其他(MISC)。图1展示了一个使用预训练模型(bert-base-ner)的NER任务示例,该模型达到最先进的性能。它显示了有关主题的重要信息,例如出生日期(DOB:1961年8月4日)、任职年限(2009-2017)和以前的工作(民权律师和大学讲师)是如何被遗漏的。这些模型也缺乏上下文理解,使得实体解析变得具有挑战性,实体解析本质上是确定两个数据实例是否指向同一现实世界实体。例如,在短语“Clare,供职于JP Morgan Chase,有位朋友Jacob,在Google工作”中,如何确定“JP Morgan Chase”和“Google”哪个与我们的主题Clare相关?实体解析的最先进结果通常通过基于深度学习的方法实现,但这些方法通常需要大量标记(匹配/不匹配实体对)的训练数据[23]。当前NER技术的局限性在我们处理的多样和细致的数据范围内显得不足。这些技术常常忽视关键的信息,缺乏区分不同个人资料所需的上下文差异。
2.2 使用文本相似性进行实体消歧
在个体消歧任务中,比较实体传统上涉及利用文本相似性技术,例如Jaccard相似性比率[18]或使用余弦相似性和Jaro-Winkler相似性的混合相似性测量[1],这些方法主要关注文本模式和字符级相似性。加权的词频-逆文档频率(TF-IDF)是另一种表现良好的字符串比较技术[10]。它计算某个单词重复的频率(词频),并对稀有单词给予更大的重要性(权重)。然后根据这两个因素对单词进行评分。如果两段文本在多个单词上显示出可比的分数,则意味着它们具有相似性。尽管这些技术在各种上下文中被证明有效,例如跨文档共指[7],但对于我们的用例可能不足。提取的个人资料中的实体由于缩写、首字母缩写或不同的文本形式而表现出显著差异。例如,某人可能在“The Georgia Institute of Technology”学习,也可以将其教育经历提及为:1)“Georgia Tech”或2)“G.Tech”或3)“GT”,甚至4)“North Avenue Trade School”(这是一个很少有人知道的名字)。能够识别所有这些可能的表现形式并将其映射到不同属性的单一实体是使用文本相似性技术难以实现的。我们还发现,许多搜索引擎正在整合生成预训练变换器(GPT)技术,以提高搜索结果的质量[14]。
3 我们的方法论
图2展示了我们的端到端流程的图形表示,该流程可以分为三个垂直方向——从网络中检索信息、实体和事实提取、基于事实的个人资料整合。以下各节将详细解释这三个垂直方向。第3.1节讨论共享给定名字的个体的信息检索——图2(1,2),第4节深入探讨从抓取的文本数据中进行的实体和事实提取——图2(3,4)。最后,第5节讨论基于提取事实的个人资料整合——图2(5,6,7,8,9)。
3.1 从网络中检索信息
信息检索或从网络中数据提取的过程始于提交“个人全名”作为查询。我们通过向多个搜索引擎(如Google、Bing、Yahoo等)发出查询,检索与此名字共享的个体的信息(图2(1))。为了确保与名字的精确匹配,使用了各种搜索引擎优化(SEO)技术。接下来,从每个搜索结果中抓取文本内容(图2(2))。在从网络检索数据时,系统每次都会通过消除在先前搜索中识别的常用词来精细化搜索查询,以提取多样化的个人资料。这种搜索查询的精细化有助于处理与名人同名的个体。
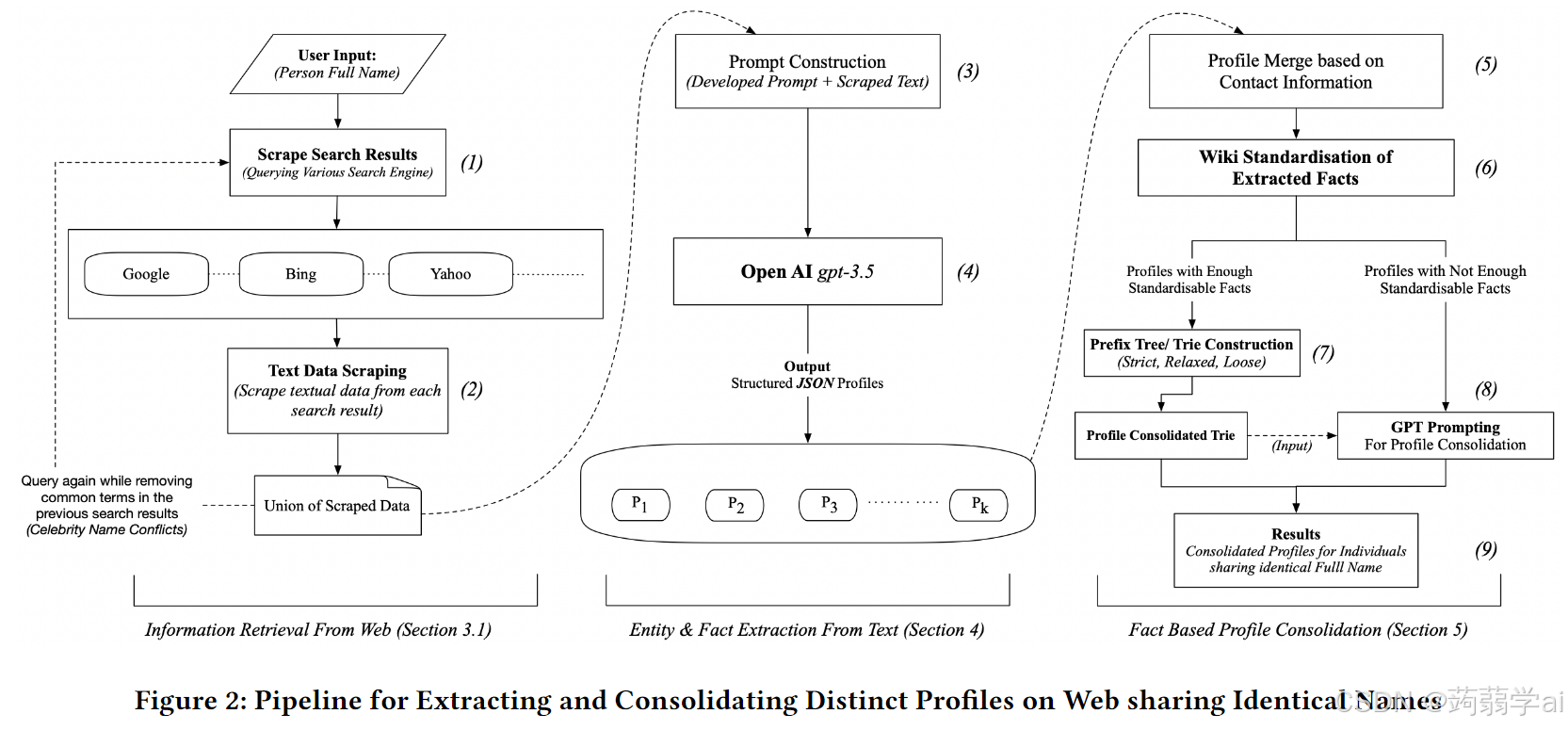
4 从文本中提取实体和事实
生成预训练变换器(GPT)以其深度神经网络架构和预训练的大型语言模型(LLMs),能够执行各种基于自然语言处理的任务,包括机器翻译[12]、问答[21]和命名实体提取[25]。其理解不同领域上下文信息的能力使其适用于各种语言任务[6]。在命名实体识别(NER)任务中,LLMs的表现显著优于监督模型[25],并且持续努力正在提升其能力,以提高效率和准确性[3, 25]。
4.1 提示构建
Wang等(2023)[25]和Ashok与Lipton(2023)[3]建议了多种技术,以微调GPT结果并开发用于命名实体识别(NER)的提示,而无需进行广泛的特定任务工程。我们使用了多种提示技术,例如(A)任务描述、(B)预定义要求、(C)边缘案例处理、(D)输出格式化、(E)自我验证与强化学习(图2(3)),以收敛到一个能够以结构化格式从给定文本中提取主题信息的提示。我们在我们的用例中使用了OpenAI提供的gpt-3.5-turbo(图2(4))。

在上述文本作为初始上下文的情况下,LLM作为语言助手发挥其专业知识,在从给定文本中提取信息的任务中。表1展示了一个简单的单行提示如何从给定文本中提取所有实体并为其分配相关属性。它还能够识别诸如出生日期(DOB)、任职年限和以前的工作等实体,这些实体在先前测试的最先进(SOTA)NER模型中被遗漏(图1)。我们还在提示中清晰地定义了主题,并指示模型仅提取与该主题相关的实体。
(B) 预定义要求:注意GPT如何自我分配提取实体的键(属性)。虽然GPT识别并分类文本中的所有实体,但生成的输出不适合直接处理。仅依赖自动分配的键可能会引入模糊性,因为GPT可能会对相似的实体类型分配不同的键,这可能会使后续涉及文本比较的阶段变得复杂。因此,为了精炼模型的输出,我们明确规定GPT在返回结果之前应考虑的要求。这包括指定实体应如何标记以及如何处理例外情况。为了解决这个问题,我们采用以下指令来指导模型:

我们将以下文本作为上述提示的测试输入:
Eric Wu is a dedicated and ambitious B.Tech student currently pursuing his degree in the field of CSE at NVS since 2019. Hailing from the vibrant city of Shanghai (China), Eric gained valuable work experience within renowned companies such as Oracle and Qualcomm. Eric has a friend Jim Lee, who works at Google.
输出:
{Education: {Institute Name: NVS, Course Name: B.Tech, Branch: CSE, Duration: 2019 – Currently Pursuing}, Work Experience: [{Organization Name: Oracle}, {Organization Name: Qualcomm}]}

显式传递键确保模型不会自我分配实体的键。模型还会处理实体解析,并仅返回与主题“Eric Wu”相关的实体,而不是与他的朋友相关的实体,正如我们在上述提示(B)中严格指示的那样。
© 边缘案例:注意输出中缺少一些键,例如“等级”、“职位角色”、“职位描述”。这是因为所请求的信息在给定文本中不存在。我们指示模型处理此类情况如下:

(D) 输出格式化:GPT具有以多种格式提供生成输出的能力[25],这些格式包括XML、HTML、JSON或甚至纯文本。我们必须明确指示模型以对我们的用例有用的特定格式返回结果。我们决定以JSON格式从GPT中检索结果。

(E) 自我验证与强化学习:如之前的研究所强调,LLMs的另一个问题是幻觉现象。LLMs往往自信地将空或无输入识别为重要实体[8, 15, 28]。为了解决这个问题,Wang等(2023)[25]和JingCheng等(2023)[20]建议在实体提取阶段之后实施自我验证方法。这基本上是提示LLMs再次检查识别的实体是否与其标记的实体标签相对应,并确保所请求的任务已正确完成。在我们的案例中,我们使用以下一组指令来添加自我验证:

我们观察到基于自我验证(SV)和强化学习(RL)[20]的方法有效缓解了幻觉问题,并在提取实体时提高了准确性。我们在提示中添加了一些更多的属性,类似于之前描述的(B),这些属性需要被提取,以涵盖几乎所有构建在线个人资料的相关信息。我们现在有了我们的最终提示:[(A)+(B)+( C )+(D)+(E)],该提示从提供的文本中提取所有实体,根据指令为这些实体分配键,处理任何潜在的边缘案例,验证其输出并以所需的输出格式返回结果。表3(附录)是最终提示获得的所有不同属性(总计:14)的详尽列表,以及它们的描述。
5 基于事实的个人资料整合
在以结构化的JSON格式提取与主题相关的实体之后,管道中的下一个任务是个人资料整合。这项任务是识别和整合重复或冗余的数据实例。通过这一过程,我们旨在系统地比较提取的个人资料集中每对个人资料,基于它们各自的事实进行分组,如果它们对应于现实世界中的同一个体。整合个人资料的过程涉及多个步骤。子节5.1、5.2、5.3和5.4将详细讨论这些步骤。
5.1 基于联系信息的个人资料整合
联系信息(电子邮件ID/手机号码/网络链接)作为每个个体的唯一标识符。当两个个人资料共享联系信息时,这表明它们代表现实世界中的同一人,因此这两个个人资料可以合并。通过合并这些在所有属性上共享的个人资料,我们创建了一个增强的个人资料,包含两个个人资料的数据,从而消除冗余数据(图2(5))。
在合并共享联系信息的个人资料后,我们继续寻找个人资料之间基于事实信息的相似性。并非所有从所有个人资料中提取的实体都是事实。事实是可以通过证据验证的信息,例如教育详情、出生日期、工作经历,而非事实则是主观的、模糊的或不可验证的陈述。确定个人资料匹配的任务是检查两个个人资料是否对应于现实世界中的同一个体或两个不同个体。我们需要比较每个属性值中的所有提取事实信息,以决定个人资料的相似性,从而进行基于事实的网络个人资料整合。

5.2 事实标准化
标准化提取的事实过程解决了在提取的个人资料中对实体多样化表示进行同质化的需求。个人在提到自己的详细信息时可能会使用多种格式,这些格式受到目标受众的影响——例如缩写、全名、常用名(熟悉该实体的人所知)等。当比较这些文本变体时就会出现挑战。为了解决这一挑战,我们采用了使用维基百科进行事实标准化的做法。(图2(6))
维基百科是一个庞大的结构化信息库。维基事实标准化指的是在文档或数据集中用其对应的维基百科URL替换文本信息(提取的事实)的做法。这个过程通过创建单一的参考点并用URL替换多样的文本表示,从而提升数据的清晰度。该过程涉及对给定个人资料中每个事实实体或属性发送不同的搜索引擎查询。一旦标准化,我们可以直接比较与实体对应的URL。以下示例描述了维基标准化个人资料中一个元素的结构。
示例:
{
"Education": {
"Institute Name": "MIT",
"Course Name": "B.Eng",
"Branch": "CSE",
"Institute Name Wikipedia Link": "https://en.wikipedia.org/wiki/Massachusetts_Institute_of_Technology",
"Course Name Wikipedia Link": "https://en.wikipedia.org/wiki/Bachelor_of_Engineering",
"Branch Wikipedia Link": "https://en.wikipedia.org/wiki/Computer_science_and_engineering"
}
}
为了确定两个个人资料是否对应于同一个体,需要将一个个人资料的每个属性类别与另一个个人资料进行比较。我们使用基于树的方法。
5.3 前缀树 | Trie
前缀树,也称为Trie,是一种树状数据结构,用于高效存储数据。我们利用Trie的基本属性,将共享相似属性的元素分组,以构建用于存储提取个人资料的数据结构。
Trie构建:个人资料一个一个地添加到Trie类似的数据结构中(图2(7)),每个属性类别位于离根节点的指定深度上。给定个人资料的属性插入Trie的顺序由所有个人资料中每个属性类别的数据出现频率决定,从出现频率最高的属性开始,逐渐到出现频率最低的属性。这个顺序减少了叶节点的数量,从而减少了不同个人资料的数量。每个个人资料的事实信息存储在节点中,这些节点通过边缘内部连接。
图4展示了上述四个个人资料使用前缀树启发的数据结构进行个人资料整合的情况。由于P1、P2和P3共享相同的教育背景(康奈尔大学的博士),因此它们被放置在同一个节点中,而P4则被单独放置在教育层级的另一个节点中(深度1)。进一步处理时,P1、P2和P3又在工作经历层级(深度2)中放置在同一个节点,因为发现了一个共同的链接(谷歌),而P4则在自己的分支中。最后,在项目层级(深度3)时,由于P1缺乏项目信息,P1与P2和P3分开。随着深度的增加,我们判断两个给定个人资料相似性的能力也得到了提升。可以确定地说,P2和P3在现实世界中对应于同一个个体,因为它们属于同一个叶节点(深度3)。同样,我们可以说P4对应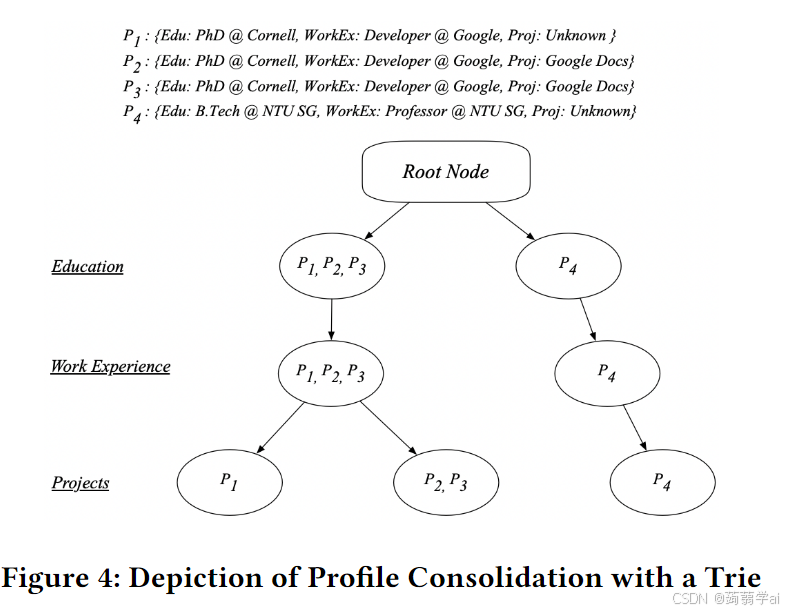
于现实世界中与其他三个个人资料不同的个体。
为了满足多样化的用户偏好,我们的解决方案在检查与其他个人资料的相似性时提供了三个级别的精确度——严格、放松和宽松。
-
严格个人资料匹配:考虑一个包含五个教育类别条目的个人资料P1,每个条目都有所有预定义的子属性。要称一个个人资料与P1严格匹配,P1必须包含其他个人资料中存在的所有条目(每个元素中的所有子属性),或反之亦然。
-
放松个人资料匹配:至少有一个完整条目的匹配(该元素中的所有子属性)对于该属性类别。举例来说,个人资料P1在教育类别中有五个元素。要称一个个人资料与P1放松匹配,它必须至少包含一个元素,与P1中存在的一个元素完全匹配(所有子属性)。
-
宽松个人资料匹配:在该属性类别的任何元素中至少匹配一个子属性。例如,个人资料P1在教育类别中有五个元素。要称一个个人资料与P1宽松匹配,它必须至少包含一个子属性,匹配P1中某个元素的对应子属性,如学院名称、课程名称或专业名称。
5.4 个人资料整合与提示
虽然维基百科提供了大量结构化信息,用于标准化大多数个人资料,但仍然有一些与个人资料相关的事实信息无法使用维基百科进行标准化。这包括需要上下文理解的信息,如职位描述、职业路径和背景。由于这个问题,我们留下了一小部分没有足够标准化数据的个人资料,无法插入Trie。GPT凭借其理解上下文的能力,成为整合这些个人资料与之前整合的个人资料的解决方案[6]。我们使用前面讨论的提示构建技术(4.1)准备提示,以确定两个个人资料是否属于同一个现实世界中的个体。我们设计了该提示,以小心谨慎的方式减少错误匹配的可能性。(图2(8))这些指令提示GPT在考虑各个属性出现的上下文时,评估输入个人资料之间的相似性。


考虑一个例子,其中三位个人共享“黄伟”作为全名:
个人资料1:黄伟是QC San Diego(加州)的一名动态软件开发人员,该公司是全球领先的科技公司之一。来自香港(中国)这个充满活力的城市,他在北京(清华大学)获得了学士学位。黄的职业生涯使他专注于DSP模拟器以及电信和无线技术。他对卓越的承诺和解决复杂技术挑战的才能使他成为团队和公司不可或缺的资产。
提取的个人资料1:
{
"Name": "黄伟",
"Locations": ["San Diego (CA)", "香港", "北京", "中国"],
"Education": [{
"Institute Name": "清华大学",
"Course Name": "学士学位",
"Branch Name": "未知",
"Duration": "未知"
}],
"Work Experience": [{
"Organization Name": "QC San Diego",
"Role": "软件开发人员",
"Job Description": ["DSP模拟器", "电信和无线技术"]
}]
}
个人资料2:在科技繁华的世界中,黄伟作为高通的SW工程师找到了自己的归属。最初来自香港,黄在北京的清华大学(B. Tech CSE)开始了他的教育之旅,培养了他与生俱来的技术才能。魏被赋予了一个关键角色,围绕着数字信号处理模拟器的开发,使他成为团队不可或缺的资产,也是高通技术进步的推动力。
提取的个人资料2:
{
"Name": "黄伟",
"Locations": ["香港", "北京"],
"Education": [{
"Institute Name": "清华大学",
"Course Name": "B. Tech",
"Branch Name": "CSE",
"Duration": "未知"
}],
"Work Experience": [{
"Organization Name": "高通",
"Role": "SW工程师",
"Job Description": ["数字信号处理模拟器"]
}]
}
我们将上述提取的个人资料与GPT提示(5.4)提供给GPT,以确定它们是否对应于同一个现实世界中的个体。GPT的输出如下:
个人资料1 & 个人资料2
- 这些个人资料是否对应于同一个个体?是的。
- 个人资料相似度评分:8/10
- 原因:[位置部分匹配(香港∼HK,北京),教育(清华大学的学士学位∼B. Tech),工作经历(QC San Diego∼高通,DSP∼数字信号处理)]
我们还添加了另一个个人资料与个人资料1和个人资料2进行比较,实际上对应于现实世界中的不同个体:
个人资料3:黄伟是一位经验丰富的记者,以其在犯罪报道方面的专业知识而闻名。黄在上海日报的主要分支担任高级记者,深入挖掘引人注目的叙述。他获得了清华大学新闻与传播学院的学士学位(中国)。黄对报道的奉献和调查能力巩固了他作为新闻界杰出人物的声誉。
提取的个人资料3:
{
"Name": "黄伟",
"Locations": ["上海", "中国"],
"Education": [{
"Institute Name": "清华大学新闻与传播学院",
"Course Name": "学士学位",
"Branch Name": "新闻学",
"Duration": "未知"
}],
"Work Experience": [{
"Organization Name": "上海日报",
"Role": "高级记者",
"Job Description": ["犯罪报道"]
}]
}
GPT的输出如下:
个人资料1 & 个人资料3
- 这些个人资料是否对应于同一个个体?不。
- 个人资料相似度评分:2/10
- 原因:[位置部分匹配(中国),教育与工作经历(尽管大学名称和课程名称部分匹配,但工作背景完全不同)]
个人资料2 & 个人资料3
- 这些个人资料是否对应于同一个个体?不。
- 个人资料相似度评分:1/10
- 原因:[尽管在学院名称上部分匹配,但上下文描述的工作背景完全不同]
请注意,在上述示例中,GPT凭借其上下文理解能力能够准确检测假阳性和真阴性,以识别个人资料匹配的任务。
我们使用上述两种技术(基于Trie和基于GPT提示)来最终整合共享相同姓名的个体的个人资料。我们采用维基标准化技术,然后进行Trie构建,以管理具有足够可以标准化内容的个人资料,而使用GPT提示技术来识别需要上下文理解的其余个人资料,以及已经通过Trie整合的个人资料。GPT凭借其自然语言处理能力,使得能够执行诸如消歧义提取的个人资料等任务。然而,随着输入提示的增加,其效果可能会减弱。因此,GPT幻觉并返回不准确结果的概率会增加。我们的方法是策略性的,明智地只对缺乏实质标准化内容的个人资料使用GPT,这代表了整个数据集的一小部分。这种选择性应用帮助我们减轻了大提示所带来的问题。.
6 结果
为了确保我们系统的鲁棒性,我们进行了全面的测试。该测试涵盖了广泛的场景:
6.1 常见姓名
我们对系统进行了处理超过500个不同姓名(常见和不常见)的挑战。姓名列表还包括美国最常见的姓名,依据fivethirtyeight的统计——“詹姆斯·史密斯”(James Smith)为最常见姓名。表2总结了这项测试的结果。正如预期的那样,在处理常见姓名的情况下,我们观察到与较少或不常见姓名相比,出现了更多的独特个人资料。
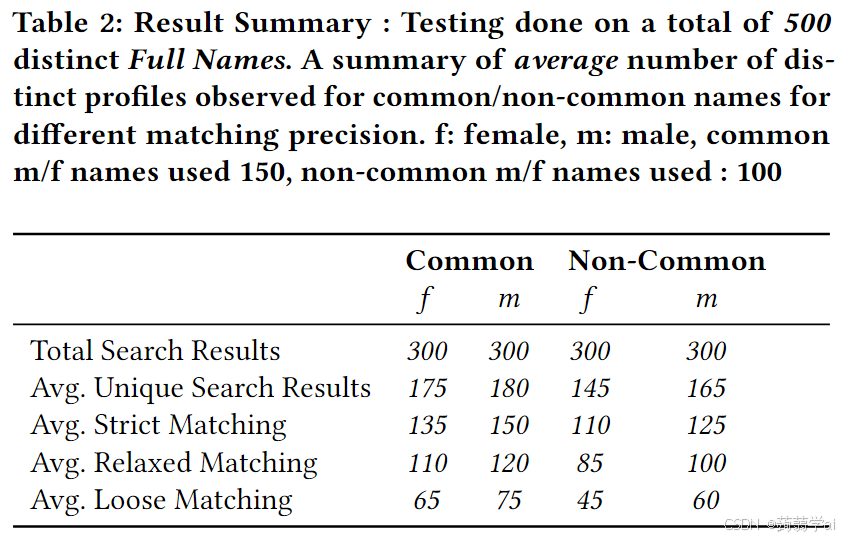
随着姓名的普遍性增加,与较少见的姓名相比,在抓取相同数量的搜索结果时观察到的独特个人资料数量增多。例如,在测试“詹姆斯·史密斯”(美国最常见姓名)时,我们从谷歌、雅虎和必应提取了总共300个结果。这导致在严格、放松和宽松匹配中分别获得了约160、135和105个独特个人资料。这些独特个人资料包括一位拳击手、一位演员、一位健身影响者、一位获奖作家、一位软件开发人员、一位商人等,所有人都以共享的姓名为联系。
而在测试相对不常见的姓名“简·涅”(Jian Nie)时,搜索结果分别为严格、放松和宽松匹配中约110、90和50个独特个人资料。
6.2 名人姓名冲突
系统成功识别出个体与名人同名的情况。在指定的结果数量之后,它会细化与名人相关的结果。这使得我们的系统能够检索与相同姓名的非名人相关的信息。考虑输入姓名为“迈克尔·乔丹”(Michael Jordan),这位著名的篮球运动员。对该姓名进行网络搜索几乎返回所有结果都指向这位著名运动员。为了搜索共享此姓名的个体,系统细化搜索查询:
- 查询1:“迈克尔·乔丹”
- 查询2:“迈克尔·乔丹” -篮球
- 查询3:“迈克尔·乔丹” -篮球 -芝加哥
- 查询4:“迈克尔·乔丹” -篮球 -芝加哥 -耐克
细化后的搜索查询现在返回仅与这位篮球运动员同名的个体的信息。我们的系统返回了多个迈克尔·乔丹的个人资料,其中一些列举如下:
迈克尔·乔丹:
[(i) 烹饪学院的厨师, (ii) 纽约的工程师, (iii) 塔夫茨大学的主治医师, (iv) Pehong Chen杰出教授, (v) 来自密歇根的作家, (vi) 新泽西的法律助理, (vii) 税务合伙人兼董事总经理, (viii) 私募股权投资银行家, (ix) 美国商人, (x) 犹他州客户成功副总裁]
6.3 其他实际用例
6.3.1 个人用户的在线存在管理。
我们的系统对寻求管理其在线存在和验证在线身份的个体具有实际用途。用户可以利用该系统编制个人资料信息被使用的链接列表,并审查其资料信息被使用的网站和来源。考虑到在6.2中发现的迈克尔·乔丹——教授(iv)的案例。通过我们的系统,我们成功获得了与该特定个体相关的80多个链接列表。该列表中的一些链接如下:
- 学术链接:[加州大学伯克利分校,麻省理工学院IDSS,耶鲁大学]
- 学术链接:[IEEE Xplore,WLA奖,谷歌学术]
- 非学术链接:[维基百科,领英,Crunchbase]
通过定期监控其在线资料的使用情况,用户可以快速识别任何未授权的表现或冒充实例。该功能使个体能够确保其在线存在的合法性,并保护自己免受潜在的冒充或身份滥用。
6.3.2 改善网络人名搜索算法。
我们的管道可以帮助增强人名的网络搜索。通过将我们的管道作为搜索引擎上的一层,用户将能够快速有效地识别他们正在搜索的个体,同时获得关于该人的更准确的信息。
6.4 用户研究
为了评估我们系统的实际可用性,我们进行了一个用户研究,涉及二十名参与者(大学生和在职专业人士)。每个参与者的任务是搜索他们个人所知的与其他个体同名的人,以评估我们的系统是否能够准确整理有关这些个体的信息。用户评估的结果令人鼓舞。参与者不仅成功找到了他们所关注个体的资料,而且还观察到这些资料全面聚合了所有相关链接的信息。在多次情况下,当人们查找自己的姓名时,他们惊讶于发现还有许多其他个体与他们的姓名完全相同。
6.5 用户监督
在区分和整合个人资料时,无法避免人类监督。“Venkatesh Reddy”在印度是一个相当常见的姓名。我们发现某些个体共享相同的教育背景(斯坦福大学)以及工作地点(谷歌)。我们发现总共有六位这样的个体,实际上是不同的。不同的地点以及这些个体的其他信息使得这些资料被分开。在这种情况下,Trie和GPT技术都产生了模糊的结果,突显出人类监督在个人资料消歧义中的不可替代价值。
7 结论
在数字环境中,区分共享同一姓名的个体的挑战是一个重要问题。寻求特定个体的用户通常面临大量的网络链接,这进一步需要进行广泛的处理和比较,以定位所需的资料。我们的方法通过为用户提供与同一姓名相关的多个网络资料的集成、整合视图来解决这个问题,从而促进快速和准确的识别。我们的解决方案利用GPT进行事实信息的提取和个人资料的整合,并结合维基百科等其他工具,简化选择正确的个人资料。我们工作的创新之处在于战略性地仅将GPT用于GPT在当前最先进技术中表现优越的任务[25]。各种提示经过精心设计,以确保输出的一致性——这是使用大型语言模型的主要挑战[27]。我们提出的解决方案有潜力发展成为一种付费网络服务,用于多种用例,使个人和机构能够提取有关特定个体的信息或监控自身资料在网络上的潜在滥用。这项研究不仅推动了我们对个人消歧义的理解,也提出了一个具有更广泛影响的信息检索和在线身份管理的实际解决方案。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











