






先贴源码
public int compareTo(String anotherString) {
int len1 = value.length;
int len2 = anotherString.value.length;
int lim = Math.min(len1, len2);
char v1[] = value;
char v2[] = anotherString.value;
int k = 0;
while (k < lim) {
char c1 = v1[k];
char c2 = v2[k];
if (c1 != c2) {
return c1 - c2;
}
k++;
}
return len1 - len2;
}比较的思路是:将String数组转成char[]数组,然后依次比较字符的大小(实际比较的是字符编码值的大小);如果相同部分都相等就返回长度较大的字符串
下面来看一个中文字符串比较的例子
测试代码如下:
public class StringTest {
public static void main(String[] args) {
String s1 = "黄大仙";
String s2 = "黄大人";
s1.compareTo(s2);
}
}
进行断点调试:
第一个字符是“黄”
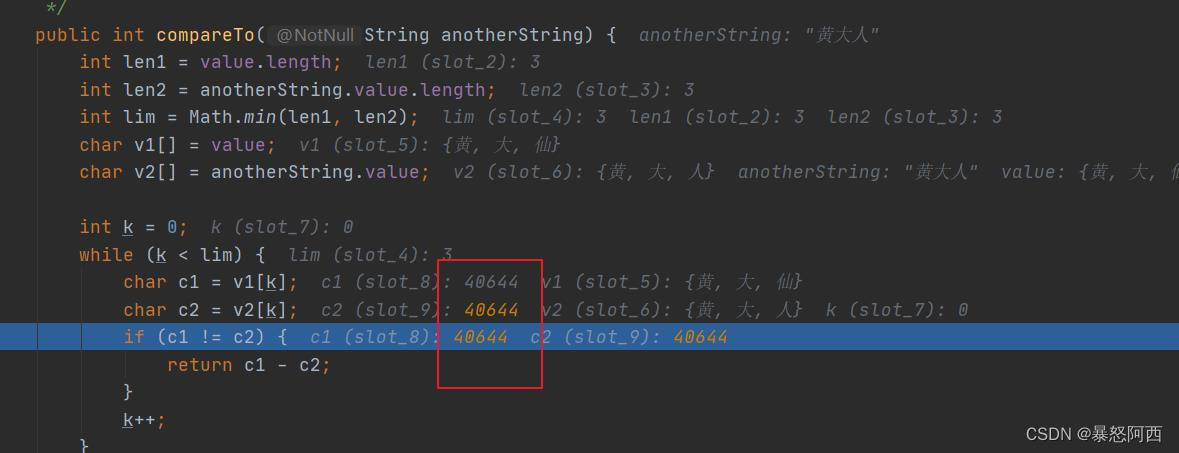
到了第三个就不一样了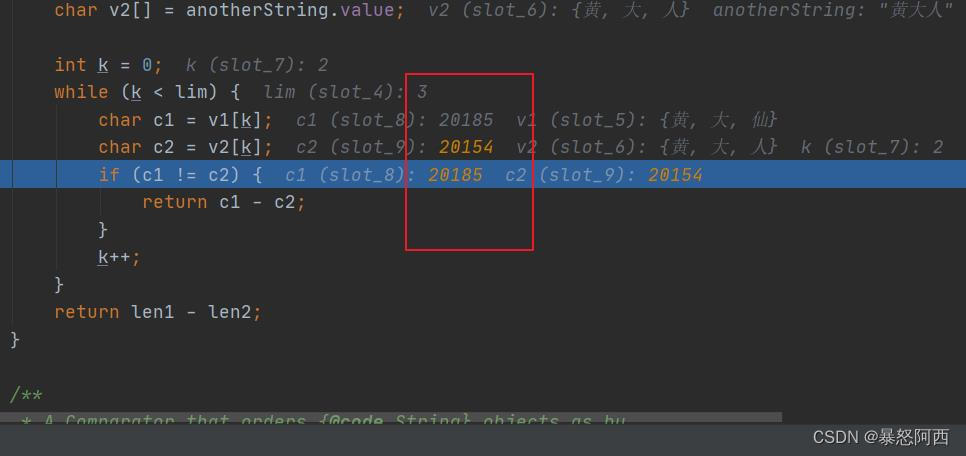
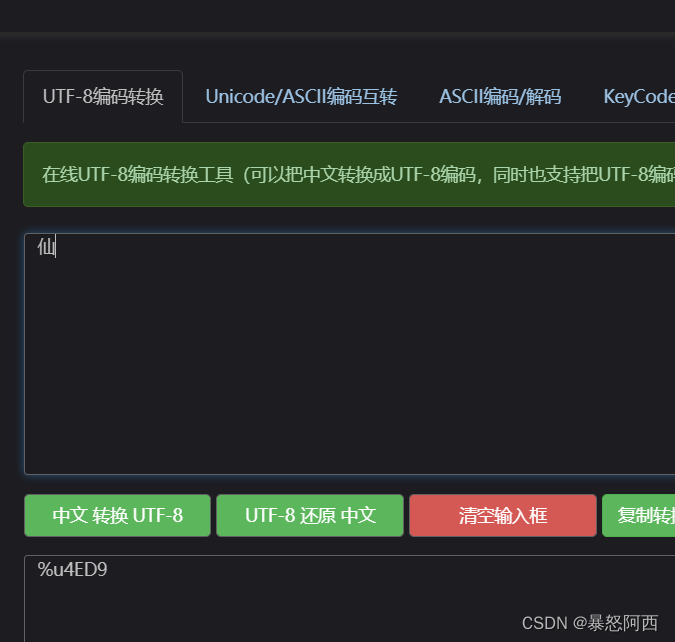
这里出现的20185和20154是什么?其实就是utf8编码的十进制,随意打开一个中文转utf-8的网站进行验证:
用计算器转换一下:
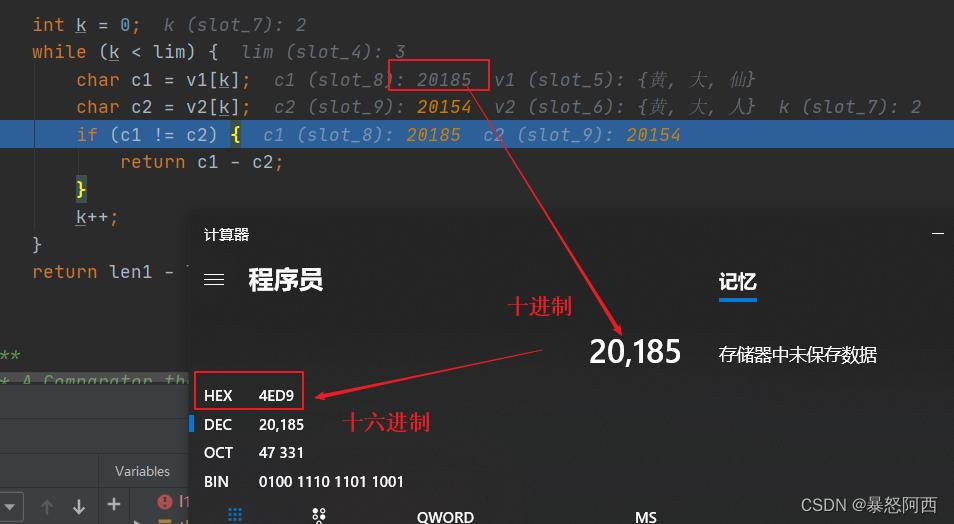
可以看到值是相同的
所以无论是中文还是英文字符串的比较,本质上比较的还是字符编码的大小;另外char类型占2个字节;ascill只能表示一个字节的大小,gbk最大能表示两个字节,utf-8表示一个字符所占的字节数为1~4















 3705
3705











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









