









这部分使用jupyter notebook写的,输出语句简化了
文章目录
一、Numpy科学计算库
Numpy中单一数据类型的多维数组以ndarray的形式存储
二、创建ndarray数组
1.创建数组
import numpy as np
a = [1.1, 2.2, 3.3, 4.4]
arr = np.array(a)
arr
# out
array([1.1, 2.2, 3.3, 4.4])
2.shape函数
查看每个数组各维度的大小,返回结果是一个元祖对象
arr.shape
# out
(4,)
3.reshape函数
更改数组的结构,原数组的shape仍然保持不变
(1).更改数组结构
arr1 = np.array([[1,2,3,4],[5,6,7,8]])
arr1_reshape = arr1.reshape(4, 2)
arr1_reshape
#out
array([[1, 2],
[3, 4],
[5, 6],
[7, 8]])
(2).更改数组共享内存区域
arr1[0,0] = 10
arr1
arr1_reshape
#out
array([[10, 2, 3, 4],
[ 5, 6, 7, 8]])
array([[10, 2],
[ 3, 4],
[ 5, 6],
[ 7, 8]])
4.创建特殊数组
print('zero_array1: {}'.format(np.zeros(5))) # 创建都为0的一维数组
print('zero_array2: {}'.format(np.zeros((3,6)))) # 创建都为0的多维数组
print('one_array: {}'.format(np.ones((2,3)))) # 创建都为1的多维数组
print('arange_array: {}'.format(np.arange(10))) # 创建指定序列数组(常用)
print('eye_array: {}'.format(np.eye(3,3))) # 创建单位数组
# out
zero_array1: [0. 0. 0. 0. 0.]
zero_array2: [[0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0.]]
one_array: [[1. 1. 1.]
[1. 1. 1.]]
arange_array: [0 1 2 3 4 5 6 7 8 9]
eye_array: [[1. 0. 0.]
[0. 1. 0.]
[0. 0. 1.]]
5.创建随机数组
np.random.randn() # 服从正态分布的随机数 一维数组
np.random.rand() # 0~1之间的随机数 一维数组
a = np.random.randint(0, 10, [4,4]) # 随机整数,二维数组
三、数组的数据类型
数组的数据类型保存在dtype这个特殊的对象中,可以使用dtype函数查看
arr.dtype
arr1.dtype
# out
dtype('float64') # arr中的元素以浮点类型储存
dtype('int32') # arr1中的元素都为整形数值
| 类型 | 名称 |
|---|---|
| int8、unit8 | 有符号和无符号的8位整型(1个字节) |
| int16、unit16 | 有符号和无符号的16位整型(2个字节) |
| int32、unit32 | 有符号和无符号的32位整型(4个字节) |
| int64、unit64 | 有符号和无符号的64位整型(8个字节) |
| float16 | 半精度浮点数 |
| float32 | 标准的单精度浮点数 |
| float128 | 标准的双精度浮点数 |
| bool | 布尔类型,True和False |
| object | Python对象类型 |
| string_ | 固定长度的字符串类型(每个字符1个字节) |
| unicode_ | 固定长度的unicode类型 |
对于已经创建好的ndarray,可以使用astype函数转换其数据类型
arr2 = np.array([1,2,3,4,5], dtype=np.int32) # 创建时指定数据类型
arr2_float = arr2.astype(np.float32)
arr2_float
arr2_float.dtype
# out
array([1., 2., 3., 4., 5.], dtype=float32)
dtype('float32')
四、数组的索引与切片
1.一维数组索引
arr3 = np.arange(15)
arr3
arr3[8]
arr3[8:12]
# out
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])
8 # 索引为8位置的数为8
array([ 8, 9, 10, 11])
使用索引与切片可以对原Numpy数组进行修改,与列表不同之处在于,数组切片的操作对象是原数组,会改变其原始值,所以处理时,可以用copy函数对原数组保存
2.切片索引
arr4 = np.arange(25).reshape(5, 5)
arr4[1,2:4] # 取出索引为2:3对应得数字7、8
arr4[1:3, 2:4] # 取出行索引为1:2,列索引为2:3的二维数组
arr4[::, 2:] # 取出第三列之后的二维数组
arr4[::2, 2:] # 第三列之后各行取数的二维数组
# out
array([7, 8])
array([[ 7, 8],
[12, 13]])
array([[ 2, 3, 4],
[ 7, 8, 9],
[12, 13, 14],
[17, 18, 19],
[22, 23, 24]])
array([[ 2, 3, 4],
[12, 13, 14],
[22, 23, 24]])
3.布尔值索引
x = np.array([0,1,2,3,1])
print(x==1)
arr4[x==1]
# out
[False True False False True]
array([[ 5, 6, 7, 8, 9],
[20, 21, 22, 23, 24]])
注意:布尔型数组的长度必须与原索引数组的行数相同
布尔型索引可以与切片结合使用
还可以设置反向条件
- != 表示不等于
- ~ 表示条件否定
- logical_not函数用于设置反向条件
布尔运算符& | 可用于设置多个布尔条件
五、数组常用方法
1 数组的拼接
np.vstack((t1, t2)) # 竖直拼接
np.hstack((t1, t2)) # 水平拼接
2数组的行列交换
t[[1, 2],: ] = t[[2, 1], :] # 行交换
t[:, [0, 2]] = t[:, [2, 0]] # 列交换
3获取最大值和最小值的位置
np.argmax(t, axis=0)
np.argmin(t, axis=1)
4生成随机数
print(np.random.randint(10, 20, (4,5)))
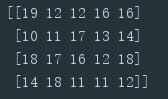
希望每次生成的随机数都一样在前面加一行
np.random.seed()
六、nan的注意点
1、nan为float类型
2、两个nan是不想等的
3、
np.nan != np.nan
# out
True
4、l利用以上性质,判断数组中nan的个数
5、由于3,通过np.isnan(a)判断一个数字是否为nan,返回bool类型
6、nan和任何数值计算都是nan
7、inf表示无穷
七、数学与统计函数
1.统计运算
arr6 = np.arange(25).reshape(5,5)
print('arr6.sum(): {}'.format(arr6.sum())) # 对所有元素求和
print('arr6.mean(): {}'.format(arr6.mean())) # 求所有元素的均值
print('arr6.std(): {}'.format(arr6.std())) # 求所有元素的标准差
print('arr6.var(): {}'.format(arr6.var())) # 求所有元素的方差
print('arr6.max(): {}'.format(arr6.max())) # 求所有元素的最大值
print('arr6.min(): {}'.format(arr6.min())) # 求所有元素的最小值
print('arr6.cumsum(): {}'.format(arr6.cumsum())) # 求所有元素的累计和
print('arr6.cumprod(): {}'.format(arr6.cumprod())) # 求所有元素的累计积
print('arr6.argmin(): {}'.format(arr6.argmin())) # 求最小元素的索引
print('arr6.argmax(): {}'.format(arr6.argmax())) # 求最大元素的索引
# out
arr6.sum(): 300
arr6.mean(): 12.0
arr6.std(): 7.211102550927978
arr6.var(): 52.0
arr6.max(): 24
arr6.min(): 0
arr6.cumsum(): [ 0 1 3 6 10 15 21 28 36 45 55 66 78 91 105 120 136 153
171 190 210 231 253 276 300]
arr6.cumprod(): [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
arr6.argmin(): 0
arr6.argmax(): 24
2.矩阵运算
(1)矩阵的转置
.T函数或者.transpose()或者.swapaxes()
arr7 = np.array([[1,2,3],[4,5,6],[7,8,9]])
arr7
arr7.T
# out
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
array([[1, 4, 7],
[2, 5, 8],
[3, 6, 9]])
(2)矩阵的逆
np.linalg.inv函数
(3)矩阵的加减法
直接用加减号,要保证亮两个矩阵的结构相同
(4)矩阵的乘法和点乘
点乘直接用乘号
点乘用.dot函数
(5)矩阵的迹
trace函数
(6)特征值、特征向量
eigvalue,eigvector = np.linalg.eig(arr7)
eigvalue # 特征值
eigvector # 特征向量
# out
array([ 1.61168440e+01, -1.11684397e+00, -1.30367773e-15])
array([[-0.23197069, -0.78583024, 0.40824829],
[-0.52532209, -0.08675134, -0.81649658],
[-0.8186735 , 0.61232756, 0.40824829]])
3.数据处理
(1)排序
sort函数对数组排序,当函数中的参数axis=0时,每一列上的元素按照行的方向排序,axis=1时,每一行上的元素按照列的方向排序
arr9 = np.array([[2,4,3],[5,4,2],[9,0,3]])
arr9.sort(axis=1)
print('arr9: {}'.format(arr9))
print('按行排序后的矩阵:{}'.format(arr9))
arr10 = np.array([[2,4,3],[5,4,2],[9,0,3]])
np.sort(arr10,axis=0) # np.sort函数返回的是已排序的副本,对原数组已做修改
print('按列排序后得矩阵:{}'.format(arr10))
print('排序后的arr10: {}'.format(np.sort(arr10,axis=0))) # 按列排序
# out
arr9: [[2 3 4]
[2 4 5]
[0 3 9]]
按行排序后的矩阵:[[2 3 4]
[2 4 5]
[0 3 9]]
按列排序后得矩阵:[[2 4 3]
[5 4 2]
[9 0 3]]
排序后的arr10: [[2 0 2]
[5 4 3]
[9 4 3]]
(2)去重
unique函数
arr11 = np.array([3,2,1,5,4,3,2,1])
np.unique(arr11)
# out
array([1, 2, 3, 4, 5])
(3)数值处理
# 三元运算符
np.where(t < 10, 0 , 10)
表示把数组t中小于10的数置为0,大于10的数置为10
t.clip(10, 18)
表示小于10的替换为10,大于18的替换为18
八、文件读入和读取
写入 savetxt
np.savetxt('arr.txt',arr)
读取 loadtxt
np.loadtxt('arr.txt',arr)
如果数据文件是以逗号分割的csv文件,则在loadtxt函数中,设置参数delimiter=’,’ 即可
np.load(frame, dtype=np.float, delimiter=None, skiprows=0, usecols=None, unpack=False)
| 参数 | 解释 |
|---|---|
| frame | 文件、字符串或产生器,可以是.gz或bz2压缩文件 |
| dtype | 数据类型,可选,默认为np.float |
| delimiter | 分割字符串,默认是空格,改为逗号 |
| skiprows | 跳过前x行,一般跳过第一行表头 |
| usecols | 读取指定的列,索引,元组类型 |
| unpack | 如果True,读入属性将分别写入不同数据变量,False读入数据只写入一个数据变量,默认False,其实就是做了一个转置,了解即可 |
总结
学习笔记
《Python3快速入门与实战》















 4057
4057











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









