







 该博客介绍了如何利用Scrapy框架构建爬虫,从起点中文网抓取小说的名称、作者、类型和形式等信息。首先,创建项目和爬虫源文件,设置请求头和解析函数,然后提取所需数据并存储到Item对象。接着,通过自定义的Item Pipeline处理重复数据,并将数据保存到CSV文件。进一步,将数据持久化到MySQL和MongoDB数据库中,分别实现数据库连接、插入操作及关闭连接。最后,提供了数据库配置和运行爬虫的方法。
该博客介绍了如何利用Scrapy框架构建爬虫,从起点中文网抓取小说的名称、作者、类型和形式等信息。首先,创建项目和爬虫源文件,设置请求头和解析函数,然后提取所需数据并存储到Item对象。接着,通过自定义的Item Pipeline处理重复数据,并将数据保存到CSV文件。进一步,将数据持久化到MySQL和MongoDB数据库中,分别实现数据库连接、插入操作及关闭连接。最后,提供了数据库配置和运行爬虫的方法。
爬取起点中文网小说
Scrapy框架结构
- 引擎(ENGINE)
- 调度器(SCHEDULER)
- 下载器(DOWNLOADER)
- 爬虫(SPIDERS)
- 项目管道(ITEM PIPELINES)
- 下载器中间件(Downloader Middlewares)
- 爬虫中间件(Spider Middlewares)
需求分析
目标网站 https://www.qidian.com/rank/hotsales?style=1&page=1
提取内容为:小说名称、作者、类型和形式

项目
创建项目,在命令行定位到放项目的目录
scrapy startproject qidian_hot
打开pycharm
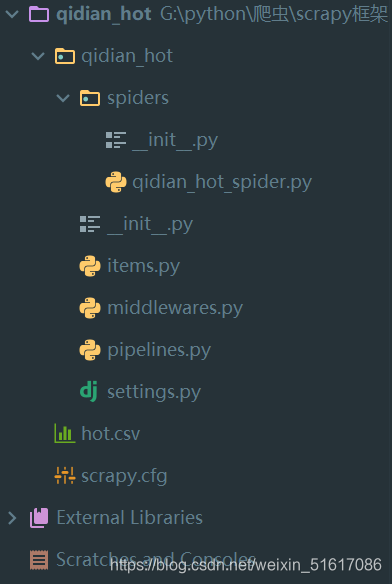
在spiders目录下新建爬虫源文件qidian_hot_spider.py,代码如下
# !/user/bin/env python
# -*- coding:utf-8 -*-
# author:Zfy date:2021/7/4 20:30
from scrapy import Request
from scrapy.spiders import Spider
from qidian_hot.items import QidianHotItem
class HotSalesSpider(Spider):
name = 'hot'
qidian_headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36"
}
current_page = 1
def start_requests(self):
url = "https://www.qidian.com/rank/hotsales?style=1&page=1"
yield Request(url, headers=self.qidian_headers, callback=self.parse)
def parse(self, response, **kwargs): # 数据解析
list_selector = response.xpath("//div[@class='book-mid-info']")
for one_selector in list_selector:
# 获取小说信息
name = one_selector.xpath("h4/a/text()").extract()[0]
# 获取作者
author = one_selector.xpath("p[1]/a[1]/text()").extract()[0]
# 获取类型
type = one_selector.xpath("p[1]/a[2]/text()").extract()[0]
# 获取形式
form = one_selector.xpath("p[1]/span/text()").extract()[0]
item = QidianHotItem()
item["name"] = name
item["author"] = author
item["type"] = type
item["form"] = form
yield item
# 获取下一页url
self.current_page += 1
if self.current_page <= 5:
new_url = "https://www.qidian.com/rank/hotsales?style=1&page=%d" % self.current_page
yield Request(new_url)
item.py
class QidianHotItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
author = scrapy.Field()
type = scrapy.Field()
form = scrapy.Field()
pipelines.py
先在setting.py中把管道的注释去掉,大概在67行
from itemadapter import ItemAdapter
from scrapy.exceptions import DropItem
class QidianHotPipeline:
def __init__(self):
self.author_set = set()
def process_item(self, item, spider):
if item["name"] in self.author_set:
raise DropItem("查找到重复姓名的项目:%s" % item)
return item
运行爬虫,命令行模式下输入,自动生成csv文件
scrapy crawl hot -o hot.csv

保存到MySQL数据库
在本机MySQL添加数据库qidian,添加表hot(表名称和爬虫源文件qidian_hot_spider.py中的类HotSalesSpider的name属性要一致),然后添加字段

安装mysqlclient
pip install mysqlclient
先在配置文件settings.py添加数据库的变量
MYSQL_DB_NAME = 'qidian' # 对应数据库中的表名称
MYSQL_HOST = 'localhost'
MYSQL_USER = 'root'
MYSQL_PASSWORD = '123456'
然后在pipelines.py中添加代码
import MySQLdb
from itemadapter import ItemAdapter
from scrapy.exceptions import DropItem
class QidianHotPipeline:
def __init__(self):
self.author_set = set()
def process_item(self, item, spider):
if item["name"] in self.author_set:
raise DropItem("查找到重复姓名的项目:%s" % item)
return item
class MySQlPipeline(object):
def open_spider(self, spider): # 在spider开始之前,调用一次
db_name = spider.settings.get('MYSQL_DB_NAME', 'qidian')
host = spider.settings.get('MYSQL_HOST', 'localhost')
user = spider.settings.get('MYSQL_USER', 'root')
pwd = spider.settings.get('MYSQL_PASSWORD', '123456')
# 链接数据库
self.db_conn = MySQLdb.connect(
db=db_name,
host=host,
user=user,
password=pwd,
charset="utf8"
)
self.db_cursor = self.db_conn.cursor() # 得到游标
def process_item(self, item, spider): # 处理每一个item
values = (item["name"], item["author"], item["type"], item["form"])
# 确定sql
sql = "insert into hot(name,author,type,form) values(%s, %s, %s, %s)"
self.db_cursor.execute(sql, values)
return item
def close_spider(self, spider): # 在spider结束时,调用一次
self.db_conn.commit() # 提交数据
self.db_cursor.close()
self.db_conn.close()
在配置文件settings.py添加管道,67行
ITEM_PIPELINES = {
'qidian_hot.pipelines.QidianHotPipeline': 300,
'qidian_hot.pipelines.MySQlPipeline': 400,
}
新建start.py,添加代码
from scrapy import cmdline
cmdline.execute("scrapy crawl hot".split())
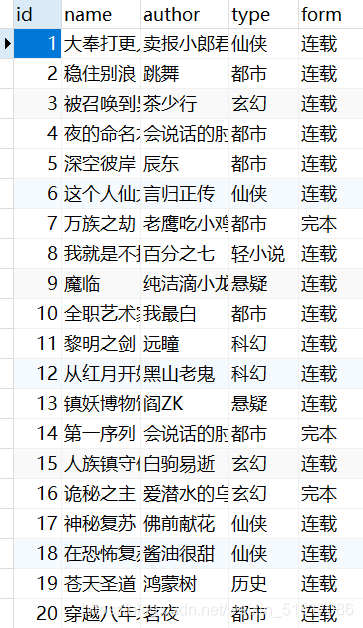
运行start.py,实现了数据的永久保存,打开数据表查看
保存到MongoDB数据库
安装 pymongo
settings.py中配置
ITEM_PIPELINES = {
'qidian_hot.pipelines.QidianHotPipeline': 300,
# 'qidian_hot.pipelines.MySQlPipeline': 400,
'qidian_hot.pipelines.MongoDBPipeline': 400,
}
# MongoDB
MONGODB_HOST = "localhost"
MONGODB_PORT = 27017
MONGODB_NAME = "qidian"
MONGODB_COLLECTION = "hot"
pipelines.py添加代码
import pymongo
class MongoDBPipeline(object):
def open_spider(self, spider): # 在spider开始之前,调用一次
host = spider.settings.get("MONGODB_HOST", "localhost")
port = spider.settings.get("MONGODB_PORT", 27017)
db_name = spider.settings.get("MONGODB_NAME", "qidian")
collection_name = spider.settings.get("MONGODB_COLLECTION", "hot")
self.db_client = pymongo.MongoClient(host=host, port=port) # 客户端对象
# 指定数据库
self.db = self.db_client[db_name]
# 指定集合
self.db_collection = self.db[collection_name]
def process_item(self, item, spider): # 处理每一个item
item_dict = dict(item)
self.db_collection.insert_one(item_dict)
def close_spider(self, spider): # 在spider结束时,调用一次
self.db_client.close()
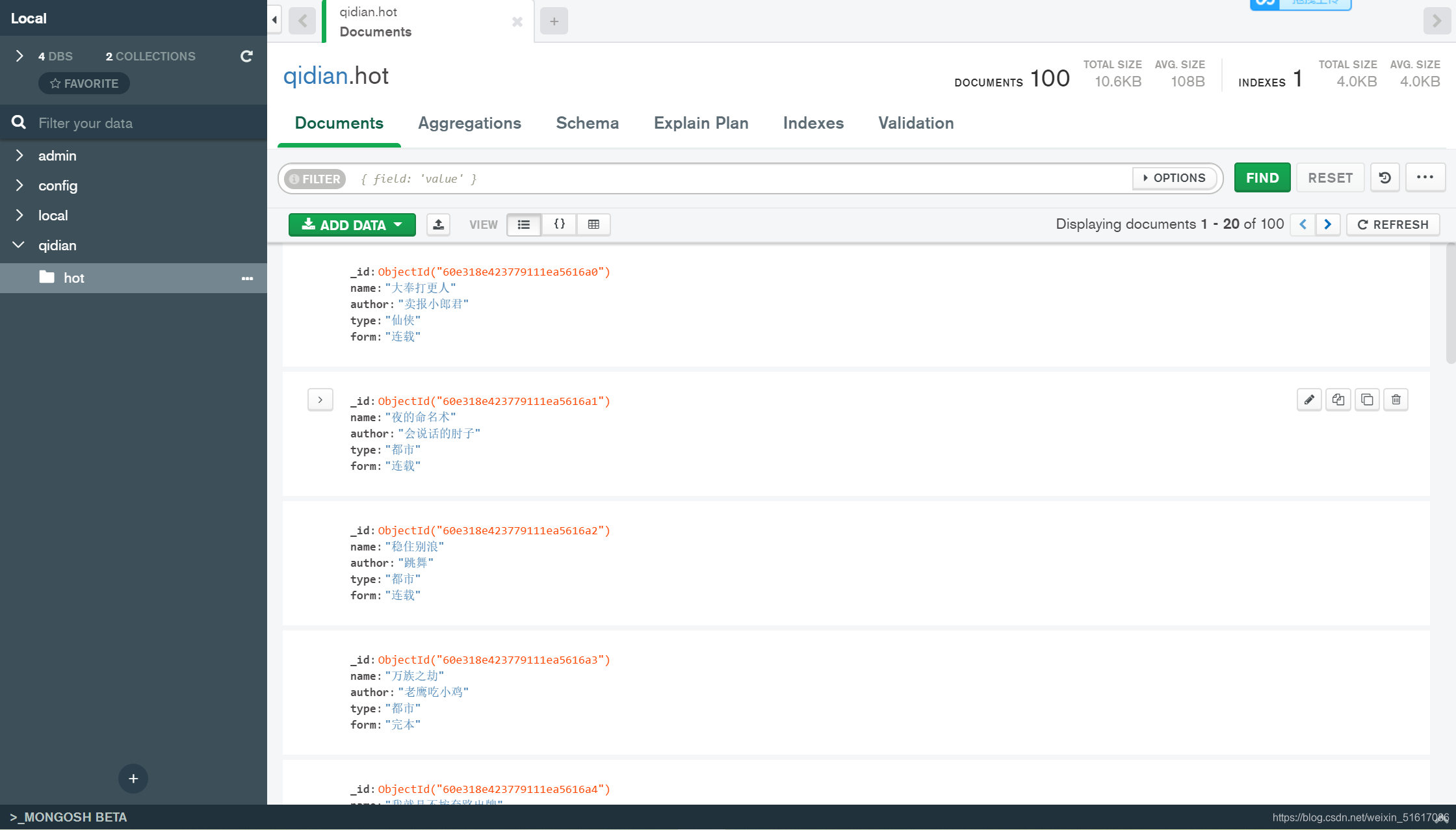
打开start.py,运行,打开 MongoDB compass 查看
《从零开始学Scrapy网络爬虫》,这本书挺不错的,有原理,有源码,有视频,还有ppt

















 3538
3538

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









