






Shuffle 概念:
map阶段的输出经过shuffle(分区、排序、合并)后形成一定有规则的数据,按照分区分配给对应的reduce,它描述着数据从map阶段流入reduce阶段的过程
Shuffle 过程:
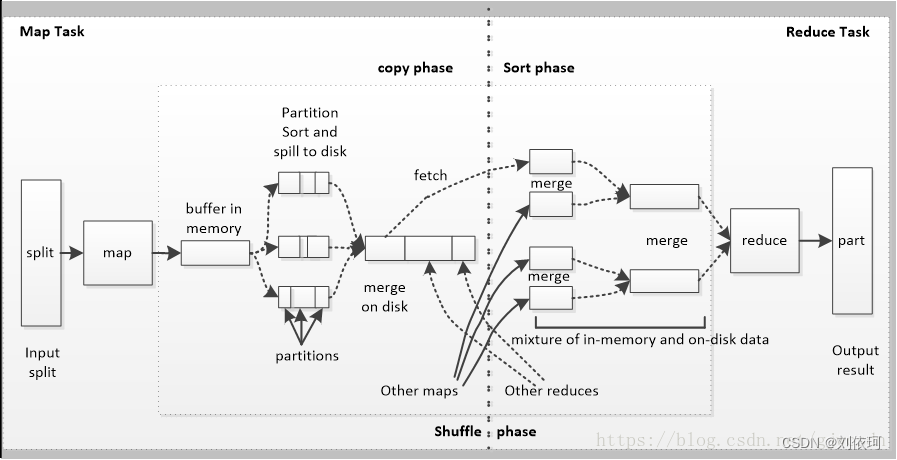
整体流程如下:
-
map结果写入环形内存缓冲区,当内存不足以存储所有数据时,将数据批量**溢写**到磁盘。为了尽量减少IO消耗,所以在数据写入磁盘之前会先写入缓冲区,待缓冲区达到==阈值(0.8)==后才批量将数据写入磁盘。
-
partition分区。在数据写入磁盘之前会先进行分区,一个分区对应一个reducer,期望数据在多个reducer之间达到均衡。
-
排序(sort)和合并(combine)。数据经过分区之后,先按照key进行排序,如果用户指定了Combiner,再进行combine操作。
-
溢写(spill)。经过排序和合并之后的数据会写入磁盘文件,每次spill都会产生一个文件。一个分区上的文件也叫一个segment。
-
归并(merge)。一个map最终会生成一个磁盘文件,由于多次spill会产生多个文件,所以需要将这些文件进行merge,最终形成一个有序的大文件。merge过程中有可能遇到相同key的数据,如果用户设置了Combiner,会执行combine操作。
以上1-5是map阶段的shuffle,以下是reduce阶段的shuffle步骤
-
拷贝(copy)。当某个map完成后,reduce不断拉取map生成的文件到ruduce。和map阶段一样先将数据写入环形内存缓冲区,当达到阈值时,将数据批量溢写到磁盘。
-
排序(sort)和归并(merge)。sort是伴随copy动作时执行的,由于map的输出是有序的,所以copy是进行sort消耗很低。当溢写数据到磁盘之前,如果用户设置了Combiner会先进行combine,然后将数据写入磁盘文件。当接受完map数据会生成多个溢写磁盘文件,将这些文件归并merge,合并成一个有序的大文件。
map阶段shuffle详细过程
map阶段shuffle过程就是将map结果进行分区、排序、合并,然后将同一分区数据归并到一起写入磁盘,最终生成一个分区有序的大文件。
1、写入内存环形缓冲区
map的运算结果会先写入内存缓冲区,当数据量不超过内存大小时,数据就一直在内存中保存,直到所有数据写入完毕,再一次性将数据写入磁盘文件。缓冲区默认100M,由参数mapreduce.task.io.sort.mb控制,当达到默认阈值0.8(80%)时,会触发溢写磁盘动作,阈值由参数mapreduce.map.sort.spill.percent控制。
注意:
- 如果单条记录超过缓冲区大小将直接触发溢写
- 缓冲区不是阻塞的。当达到阈值进行写入磁盘时,往缓冲区的写入也是正常进行的,写入磁盘完成后,缓冲区达到阈值时会再次进行写入。
2、Partition(分区)
在内存环形缓冲区达到阈值需要写入磁盘之前,会对数据按照key进行分区,每个分区数据对应一个reduce,从而达到数据均衡的目的。
分区可能会导致数据倾斜问题,即某个reduce可能会获取大量数据,某个reduce很少甚至没有数据。因此官方提供了几个分区器Partitioner,有默认的HashPartitioner,也有BinaryPartitioner、KeyFieldBasedPartitioner、TotalOrderPartitioner,用户也可以继承Partitioner基类自定义分区逻辑,通过job.setPartitionerClass()设置不同的Partitioner,避免数据倾斜问题。
官方内置HashPartitioner:
public class HashPartitioner<K2, V2> implements Partitioner<K2, V2> {
public void configure(JobConf job) {}
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K2 key, V2 value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
3、Sort & Combine(排序&合并)
当触发spill动作后,在写入磁盘文件之前按照partition和key进行排序,保证一个partition内的数据有序。如果用户通过job.setCombinerClass()设置了Combiner,则会将相同key的数据执行combine操作。
注意:
- 用户自定义Combiner需要继承Reducer类,重写reduce方法
- Combiner虽然会一定程度上将数据合并,减小IO消耗,但是由于相同key的数据合并后,可能会导致出现非预期计算结果
4、Spill(溢写)
当发生溢写时启动一个独立的spill线程,负责将数据按照分区逐个写入磁盘文件。写入文件时先按照一个分区数据顺序写入,写完一个分区数据再继续写入下一个分区数据,直到所有分区数据写入完成,最终所有分区数据都按照分区有序的存储在同一个文件中。
一个partition中的数据也叫一个segment,这些分区和数据信息统一存由一个元数据索引维护。
5、Merge(归并)
如果map产生的结果数据量很大,会发生多次spill,生成多个磁盘文件,此时就需要将这些文件进行合并,最终生成一个有序的大文件。
合并时候是按照partition一个一个进行合并的,首先从索引中查出这个partition对应的segment,然后归并合并这些文件数据,当一个分区合并完后再执行下一个分区的合并。
mapreduce.task.io.soft.factor参数控制merge过程同时打开的segment数量。默认是10,可按照实际情况调整优化Job。
reduce阶段shuffle详细过程
当map彻底完成之后会通知NodeManager,NodeManager会向ApplicationMaster发送心跳汇报信息,reduce从ApplicationMaster获取map完成信息后,向对应的NodeManager发送请求,开始启动reduce的Shuffle,循环拉取map数据(copy),最后将多个文件合并成一个有序的大文件。
6、Copy
当reduce获知map输入文件所在节点后,建立HTTP连接,不断拉取数据到reduce的内存缓冲区中。reduce阶段shuflle中的内存缓冲区和map阶段的不同,缓冲区内存使用heap size通过参数mapreduce.reduce.shuffle.input.buffer.percent控制,它是相对于mapreduce.reduce.java.opts-参数值得百分比。
mapreduce.reduce.shuffle.parallelcopies参数控制copy的线程数量,用户可根据实际情况进行Job调优。
7、Sort & Merge
从map读取过来的数据先写入内存缓冲区中,reduce中shuffle的内存缓冲区通常比map阶段的大很多,它使用的heap size。当缓冲区达到一定阈值后,开始内存到磁盘的merge,触发参数由mapreduce.reduce.shuffle.merge.percent控制。sort是伴随copy执行的,由于map的输出结果是有序的,因此在copy时顺便将数据sort。在写入磁盘前,如果用户设置了Combiner会先执行combine操作。当map所有数据都读取到reduce中时,会在生成多个磁盘文件,此时需要将这多个文件合并成一个有序的大文件,叫做磁盘merge。
mapreduce.task.io.soft.factor参数控制文件句柄打开数量,影响merge的速度。
当reduce的shuffle执行完成后,才开始真正执行Reducer任务。由于shuffle完成后所有输入都写入了磁盘,所以reducer执行时需要从磁盘拉取数据进行计算。mapreduce.reduce.input.buffer.percent参数控制reducer是否使用内存计算,默认0不使用内存计算。可以通过调整此参数增加reducer计算速度
shuffle调整参数
| 参数 | 描述 | 默认值默认值 |
|---|---|---|
| mapreduce.task.io.sort.mb | map阶段缓冲区大小 | 100M |
| mapreduce.map.sort.spill.percent | map缓冲区溢写到磁盘的触发阈值 | 0.8 |
| mapreduce.task.io.sort.factor | merge时打开的文件句柄数,也叫文件流数 | 10 |
| mapreduce.map.output.compress | 是否开启map压缩 | false |
| mapreduce.map.output.compress.codec | 压缩格式 | org.apache.hadoop.io.compress.DefaultCodec |
| mapreduce.reduce.shuffle.parallelcopies | reduce阶段shuffle从map结果copy数据并行度 | 5 |
| mapreduce.reduce.shuffle.input.buffer.percent | reduce阶段shuffle的缓冲区大小,相对于mapreduce.reduce.java.opts参数值百分比 | 0.7 |
| mapreduce.reduce.shuffle.merge.percent | reduce缓冲区溢写到磁盘的触发阈值 | 0.66 |
| mapreduce.reduce.merge.inmem.thresholds | 从map读取多少条记录后触发内存到磁盘溢写 | int类型,0表示禁用 |
| mapreduce.reduce.input.buffer.percent | reduce期间用来缓存map结果大小,堆内存百分比。当shuflle结束后,内存中剩余数据必须小于此值才开始reduce计算 | 0.0 |















 3964
3964











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









